The most popular clustering method, implemented in python
These instructions will get you a copy of the project up and running on your local machine for testing purposes.
It is an unsupervised learning algorithm (meaning there are no target labels) that allows you to identify similar groups or clusters of data points within your data. Watch the full tutorial here.
Install Matplotlib with the following commands:
python -m pip install -U pip
python -m pip install -U matplotlib
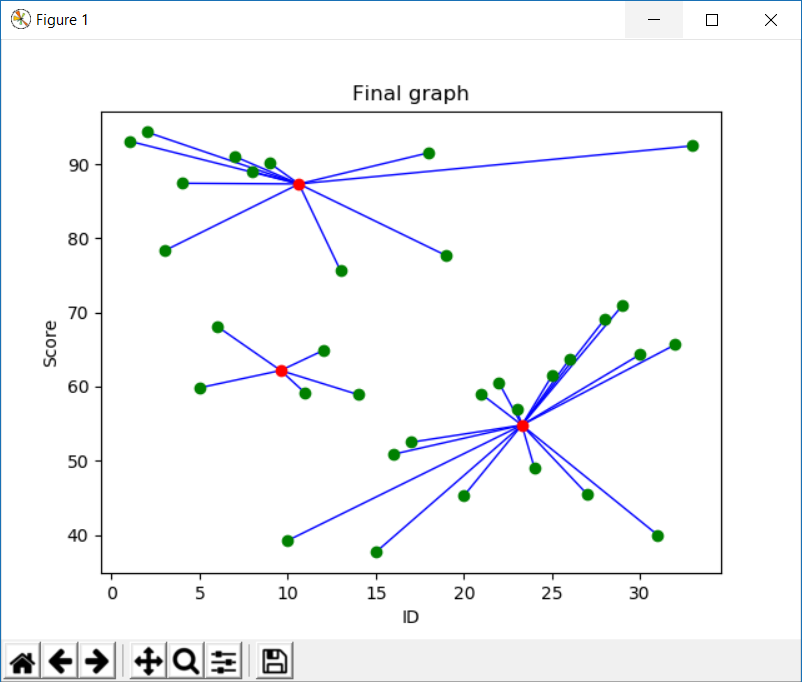
The algorithm will categorize the items into k groups of similarity. To calculate that similarity, we will use the euclidean distance as measurement. The algorithm works as follows:
- First we initialize k points, called means, randomly.
- We categorize each item to its closest mean and we update the mean’s coordinates, which are the averages of the items categorized in that mean so far.
- We repeat the process for a given number of iterations and at the end, we have our clusters.
Euclidean distance:

Average(calculating new centroid for each cluster):

- Arman - Initial work
See also the list of contributors who participated in this project.
This project is licensed under the MIT License - see the LICENSE.md file for details

