- My Job : Front-End ⚡
- Tech : JS/TS、Vue2/React/NextJS、NestJS、MUI
- Hobbies : Reading, Basketball, Cooking
- Current learning : Web3
⭐️ From amandakelake
think more!learn more!
⭐️ From amandakelake






































































































































































































function Parent1() {
this.name = 'parent1'
}
function Child1() {
// 将父类的执行上下文指向子类,父类执行时的实例属性都会指向子类
Parent1.call(this);// apply
this.type = 'child1'
}子类没有继承父类的原型方法
只继承了父类构造函数中的属性和方法
Parent1.prototype.method = (arg) => console.log(arg);
console.log(new Child1().method); // undefinedfunction Parent2() {
this.name = 'parent2';
this.arr = [1, 2, 3];
this.method = (arg) => console.log(arg)
}
function Child2() {
this.type = 'child2'
}
Child2.prototype = new Parent2();原型图如下

引用类型的属性被所有实例共享,实例之间会互相影响
let c21 = new Child2();
let c22 = new Child2();
c21.arr.push(4);
console.log(c21.arr, c22.arr);
// 注意,下面是直接给实例添加method属性
// 只是修改了method指针,没有修改原型链上的method方法
// 只有修改引用对象才是真正的修改
c21.method = 'c21';
console.log(Parent2);
console.log(c21, c22);
function Parent3() {
this.name = 'parent3';
this.arr = [1, 2, 3]
}
function Child3() {
Parent3.call(this);
this.type = 'child3'
}
Child3.prototype = new Parent3();每个实例不会再互相影响
实例化时,父类被构造了两次,这没有必要
call一次,new一次
function Parent4() {
this.name = 'parent4';
this.arr = [1, 2, 3]
}
function Child4() {
Parent4.call(this);
this.type = 'child4'
}
Child4.prototype = Parent4.prototype;
无法判断实例的构造函数是父类还是子类
let c41 = new Child4();
let c42 = new Child4();
console.log(c41 instanceof Child4, c41 instanceof Parent4);
// true true但其实,构造函数就是父类本身
console.log(c41.constructor); // Parent4很难得才通过Parent4.call(this)改变了构造函数的指向,现在又改回去了?天……不想看下去了行不行,兄dei,坚持一会就是胜利,别打瞌睡
Child4.prototype = Parent4.prototype只是把Child4的prototype属性指针指向了Parent4.prototype这个引用对象而已,实际上Parent4.prototype.constructor = Parent4,这里说的有点绕,可以结合图好好理解一下

Object.create请先移步
Object.create() - JavaScript | MDN
function Parent5() {
this.name = 'parent5';
this.arr = [1, 2, 3]
}
function Child5() {
Parent5.call(this);
this.type = 'child5'
}
// 组成原型链
Child5.prototype = Object.create(Parent5.prototype);但是,这时候,实例对象的constructor依然是Parent5

所以需要重新指定实例对象的构造器
Child5.prototype.constructor = Child5;Good !
等下,还是验证一下吧
let c51 = new Child5();
let c52 = new Parent5();
console.log(c51 instanceof Child5, c51 instanceof Parent5);
console.log(c52 instanceof Child5, c52 instanceof Parent5);
console.log(c51.constructor, c52.constructor);
// true true
// false true
// Child5 Parent5So perfect !
感谢您耐心看到这里,希望有所收获!
如果不是很忙的话,麻烦点个star⭐【Github博客传送门】,举手之劳,却是对作者莫大的鼓励。
我在学习过程中喜欢做记录,分享的是自己在前端之路上的一些积累和思考,希望能跟大家一起交流与进步,更多文章请看【amandakelake的Github博客】
参考
继承与原型链 - JavaScript | MDN
JavaScript inheritance by example by Dr.Axel
Vjeux » Javascript – How Prototypal Inheritance really works
How To Work with Prototypes and Inheritance in JavaScript | DigitalOcean
本次分析的源码采用的是16.2.0的版本
目前网上现有的react源码分析文章基于的都是版本16以前的源码,入口和核心构造器不一样了,如下图所示
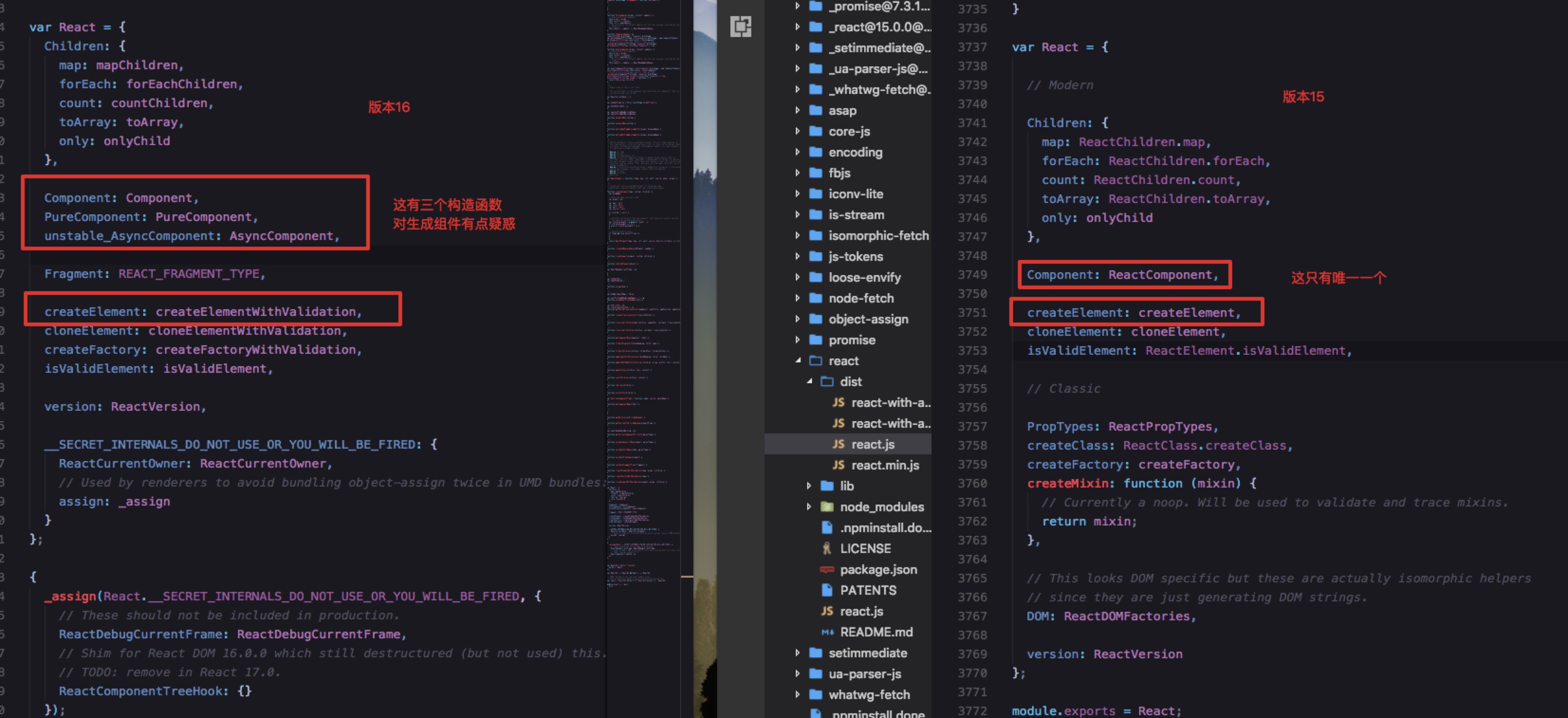
本想借鉴前人的源码分析成果,奈何完全对不上号,只好自己慢慢摸索
水平有限,如果有错误和疏忽的地方,还请指正。
mkdir [email protected]
cd [email protected]
npm init -y
npm i react --save
然后打开项目,进入node_nodules => react
先看入口文件index.js
'use strict';
if (process.env.NODE_ENV === 'production') {
module.exports = require('./cjs/react.production.min.js');
} else {
module.exports = require('./cjs/react.development.js');
}我们就看开发环境下的版本吧,压缩版本是打包到生产环境用的
打开图中文件即可
分析源码先找对外的暴露接口,当然就是react了,直接拉到最下面
var React = {
Children: {
map: mapChildren,
forEach: forEachChildren,
count: countChildren,
toArray: toArray,
only: onlyChild
},
Component: Component,
PureComponent: PureComponent,
unstable_AsyncComponent: AsyncComponent,
Fragment: REACT_FRAGMENT_TYPE,
createElement: createElementWithValidation,
cloneElement: cloneElementWithValidation,
createFactory: createFactoryWithValidation,
isValidElement: isValidElement,
version: ReactVersion,
__SECRET_INTERNALS_DO_NOT_USE_OR_YOU_WILL_BE_FIRED: {
ReactCurrentOwner: ReactCurrentOwner,
// Used by renderers to avoid bundling object-assign twice in UMD bundles:
assign: _assign
}
};ReactChildren提供了处理 this.props.children 的工具集,跟旧版本的一样
Children: {
map: mapChildren,
forEach: forEachChildren,
count: countChildren,
toArray: toArray,
only: onlyChild
},旧版本只有ReactComponent一种
新版本定义了三种不同类型的组件基类Component,PureComponent ,unstable_AsyncComponent
Component: Component,
PureComponent: PureComponent,
unstable_AsyncComponent: AsyncComponent,等下再具体看都是什么
createElement: createElementWithValidation,
cloneElement: cloneElementWithValidation,
createFactory: createFactoryWithValidation,校验是否是合法元素,只需要校验类型,重点是判断.$$typeof属性
function isValidElement(object) {
return typeof object === 'object' && object !== null && object.$$typeof === REACT_ELEMENT_TYPE;
}其实是object-assign,但文中有关键地方用到它,下文会讲
var _assign = require('object-assign');
不急着看代码,先通过例子看看组件是什么样子的
用creact-react-app生成一个最简单的react项目
在App.js文件加点东西,然后打印组件A看一下是什么
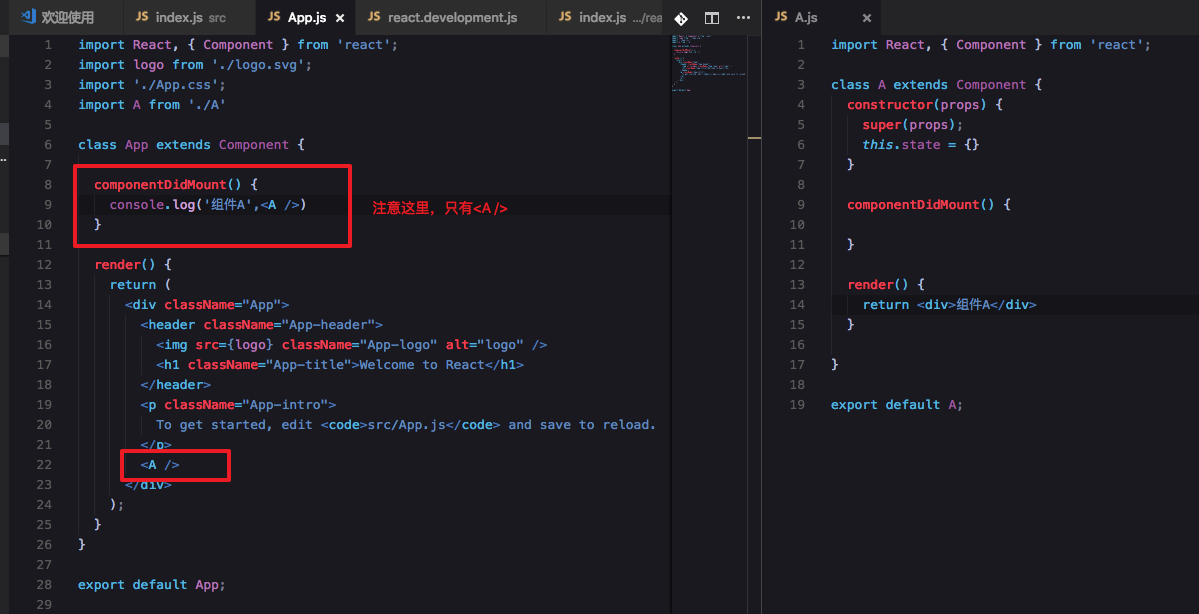
npm start启动项目看看

其实就是个对象,有很多属性,注意到props里面, 没有内容
给组件A里面包含一点内容
componentDidMount() {
console.log('组件A',<A><span>加点内容看看</span></A>)
}
可以看到,props.children里面开始嵌套内容了
那以我们聪明的程序员的逻辑来推理一下,其实不断的页面嵌套,就是不断的给这个对象嵌套props而已
不信再看一下
componentDidMount() {
console.log('组件A',<A><span>加点内容看看<a>不信再加多一点</a></span></A>)
}
所以到目前为止,我们知道了react的组件只是对象,而我们都知道真正的页面是由一个一个的DOM节点组成的,在比较原生的jQuery年代,通过JS来操纵DOM元素,而且都是真实的DOM元素,而且我们都知道复杂或频繁的DOM操作通常是性能瓶颈产生的原因
所以React引入了虚拟DOM(Virtual DOM)的概念
React虚拟DOM浅析 | AlloyTeam
总的说起来,无论多复杂的操作,都只是先进行虚拟DOM的JS计算,把这个组件对象计算好了以后,再一次性的通过Diff算法进行渲染或者更新,而不是每次都要直接操作真实的DOM。
在即时编译的时代,调用DOM的开销是很大的。而Virtual DOM的执行完全都在Javascript 引擎中,完全不会有这个开销。
知道了什么是虚拟DOM以及组件的本质后,我们还是来看一下代码吧
先从生成组件开始切入,因为要生成组件就肯定会去找组件是什么
createElement: createElementWithValidation,
知道了组件是对象后,我们去看看它的本源
摘取一些核心概念出来看就好
function createElementWithValidation(type, props, children) {
var element = createElement.apply(this, arguments);
return element;
}可以看到,返回了一个element ,这个元素又是由createElement方法生成的,顺着往下找
function createElement(type, config, children) {
var props = {};
var key = null;
var ref = null;
var self = null;
var source = null;
return ReactElement(type, key, ref, self, source, ReactCurrentOwner.current, props);
}返回的是ReactElement方法,感觉已经很近了,马上要触及本源了
var ReactElement = function (type, key, ref, self, source, owner, props) {
var element = {
$$typeof: REACT_ELEMENT_TYPE,
type: type,
key: key,
ref: ref,
props: props,
_owner: owner
};
return element;
};bingo,返回了一个对象,再看这个对象,是不是跟上面打印出来的对象格式很像?再看一眼
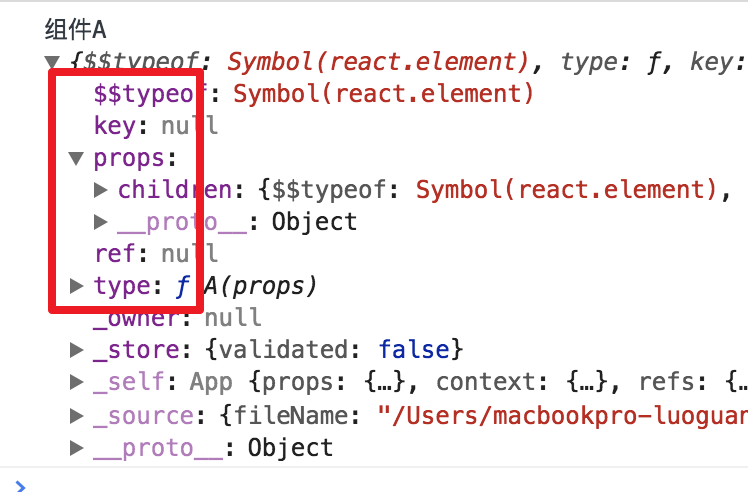
这就是组件的本源
前面说了,版本16以后,封装了三种组件基类:分别是组件、纯组件、异步组件
Component: Component,
PureComponent: PureComponent,
unstable_AsyncComponent: AsyncComponent,一个个去看一下区别在哪里,先看** Component**
function Component(props, context, updater) {
this.props = props;
this.context = context;
this.refs = emptyObject;
this.updater = updater || ReactNoopUpdateQueue;
}很简单,一个构造函数,通过它构造的实例对象有三个私有属性,refs 则是个emptyObject,看名字就知道是空对象
这个emptyObject也是引入的插件
var emptyObject = require('fbjs/lib/emptyObject');
再去看PureComponent,AsyncComponent,定义的时候居然跟Component 是一样的
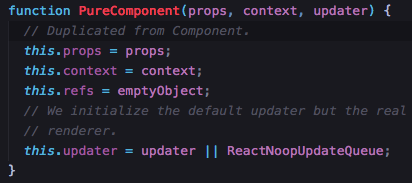
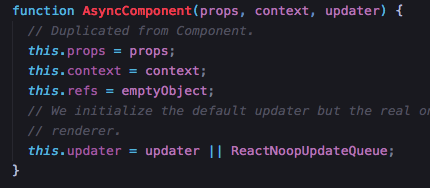
都是这四句话
this.props = props;
this.context = context;
this.refs = emptyObject;
this.updater = updater || ReactNoopUpdateQueue;区别呢?这里就要比较理解原型链方面的知识了
虽然原型和继承在日常项目和工作中用的不多,那是因为我们在面向过程编程,但想要进阶,就要去读别人的源码,去自己封装组件,这事它们就派上用场了,这就是为什么它们很重要的原因。
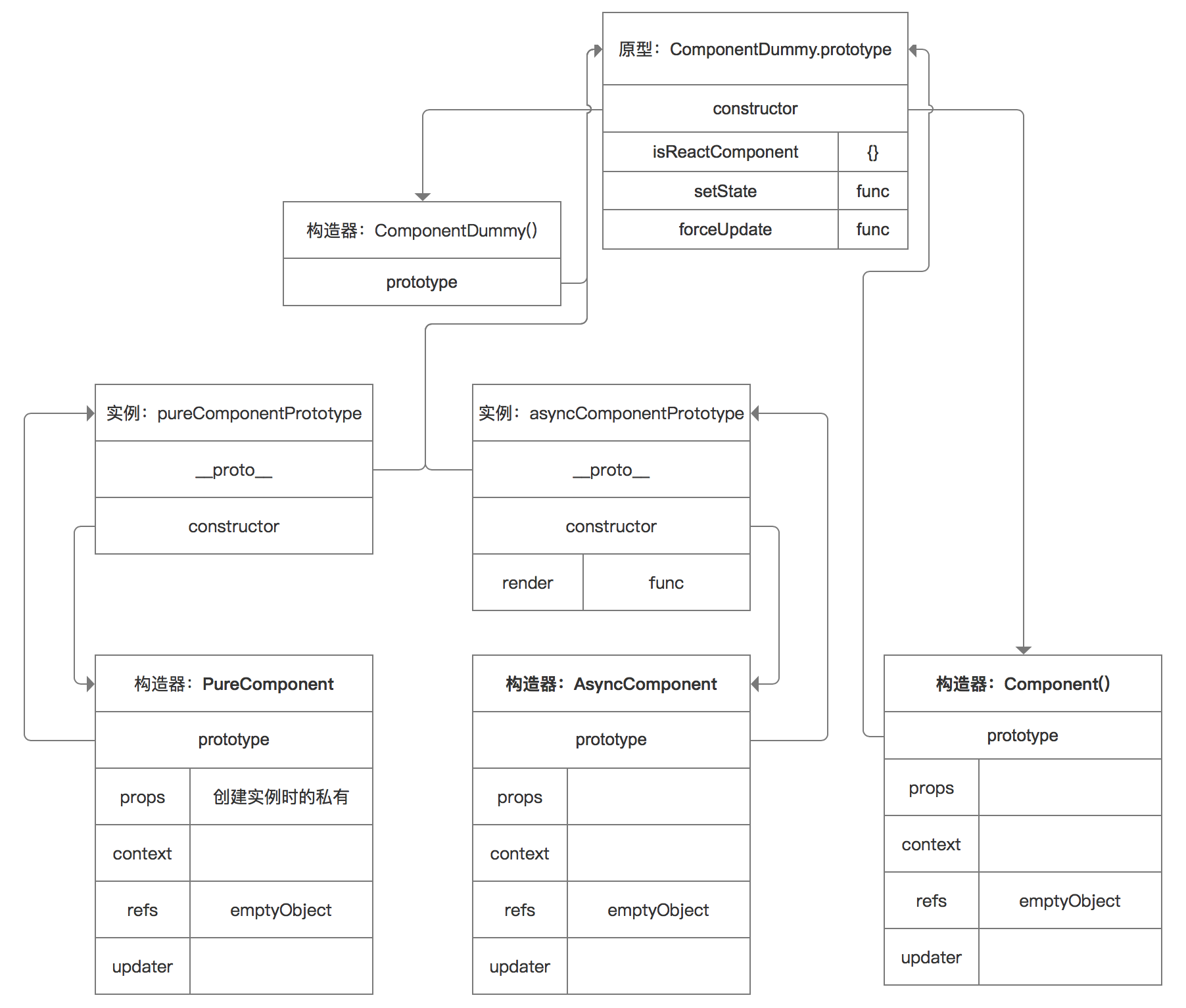
核心的方法,和属性,以及这三种组件直接的关系都是通过原型的知识联系起来的,关键代码如下,我画了个简图,希望能对看文章的各位有所帮助,如果有画错的,希望能指正我
先上核心代码
setState和forceUpdate这两个方法挂载Component(组件构造器)的原型上
Component.prototype.setState = function (partialState, callback) {
...
};
Component.prototype.forceUpdate = function (callback) {
...
};定义一个ComponentDummy,其实也是一个构造器,按照名字来理解就是“假组件”😂,它是当做辅助用的
让ComponentDummy的原型指向Component的原型,这样它也能访问原型上面的共有方法和属性了,比如setState和forceUpdate
function ComponentDummy() {}
ComponentDummy.prototype = Component.prototype;这句话,假组件构造器ComponentDummy实例化出来一个对象pureComponentPrototype,然后把这个对象的constructor属性又指向了PureComponent,因此PureComponent也成为了一个构造器,也就是上面的第二种组件基类
var pureComponentPrototype = PureComponent.prototype = new ComponentDummy();
pureComponentPrototype.constructor = PureComponent;AsyncComponent基类也是一样
var asyncComponentPrototype = AsyncComponent.prototype = new ComponentDummy();
asyncComponentPrototype.constructor = AsyncComponent;但是AsyncComponent的原型多了一个方法render,看到了吗,妈妈呀,这就是render的出处
asyncComponentPrototype.render = function () {
return this.props.children;
};所以到目前为止,可以得出一个原型图
但是,有个问题来了,render方法挂载在AsyncComponent的原型上,那通过Component构造器构造出来的实例岂不是读不到render方法,那为什么日常组件是这样写的?
还有两句代码,上面做了个小剧透的_assign
// Avoid an extra prototype jump for these methods.
_assign(pureComponentPrototype, Component.prototype);// Avoid an extra prototype jump for these methods.
_assign(asyncComponentPrototype, Component.prototype);每句话上面还特意有个注释,Avoid an extra prototype jump for these methods.,避免这些方法额外的原型跳转,先不管它,先看_assign做了什么,
把Component的原型跟AsyncComponent的原型合并,
那么这里答案就呼之欲出了,如此一来,AsyncComponent上面的render方法,不就相当于挂载到Component上面了吗?
以此类推,三种基类构造器最后都是基于同一个原型,共享所以方法,包括render、setState、forceUpdate等等,最后的原型图应该就变成了这样

到这里,有个问题要思考的是?
既然最后三个基类共用同一个原型,那为什么要分开来写?
中间还通过一个假组件构造器ComponentDummy来辅助构建两个实例
源码还没读完,这个地方我目前还没弄明白,应该是后面三个基类又分别挂载了不一样的方法,希望有大佬能提前回答一下
看了很多关于cookie与session的理论文章,项目中日常也经常用,但自己是前端er,对后端一直抱有好奇心,这次就拿cookie开到,跑一个全流程吧,也顺便作为巩固cookie知识的一个实践
通过node,我们可以很轻易的搭建出一个本地服务器,也为我们做各种项目试验带来了方便,再次推崇一发node大法
mkdir cookie-dome
cd cookie-dome
npm init
npm i express --save
touch main.js
这里使用了express框架快速搭建服务器,在新建的main.js文件输入以下代码
express中文官网
const experss = require('express');
const app = experss();
app.get('/',(req, res) => {
res.send('Hello cookie-demo')
});
app.listen(3000,() => {
console.log('Example app listening on port 3000!');
})
终端输入node main.js把服务器跑起来
浏览器输入http://localhost:3000即可看到如下界面

还可以看到,页面已经有了一个请求,但没有cookie相关的信息
忘了哪位伟人说过:大胆假设,小心验证,那我们就听一次话吧
先猜测大概流程如
main.js文件中加上res.cookie('cookie1', 'cookie1')
const experss = require('express');
const app = experss();
app.get('/',(req, res) => {
res.cookie('cookie1', 'cookie1')//这里加上
res.send('Hello cookie-demo')
});
app.listen(3000,() => {
console.log('Example app listening on port 3000!');
})
关闭服务器重启后,会发现第一次的请求响应中,带上了Set-Cookie:cookie1=cookie1; Path=/,但是请求头中并没有出现cookie

这时候刷新一下页面,再看看有什么不同?
请求也带上了cookie,也就是说,浏览器已经把cookie记下来了

多加个cookie试试
app.get('/',(req, res) => {
res.cookie('cookie1', 'cookie1')
res.cookie('cookie2', 'cookie2')
res.cookie('cookie3', 'cookie3')
res.send('Hello cookie-demo')
});
重启刷新两次页面,再看看?

**expires** : Cookie 失效日期
**max-age**:在 cookie 失效之前需要经过的秒数
**Domain**:指定 cookie 可以送达的主机名。
**Path**:指定一个 URL 路径,这个路径必须出现在要请求的资源的路径中才可以发送 Cookie 首部
**Secure**:一个带有安全属性的 cookie 只有在请求使用SSL和HTTPS协议的时候才会被发送到服务器。
**httpOnly**:设置了 HttpOnly 属性的 cookie 不能使用 JavaScript 经由 Document.cookie 属性、XMLHttpRequest 和 Request APIs 进行访问,以防范跨站脚本攻击(XSS)。
const experss = require('express');
const app = experss();
app.get('/', (req, res) => {
// 失效时间点
res.cookie('cookie1', 'cookie1', {
expires: new Date(Date.now() + 10000)
});
// 失效时长
res.cookie('cookie2', 'cookie2', {
maxAge: 10000
});
// httpOnly
res.cookie('cookie3', 'cookie3',{
httpOnly: true
});
res.send('Hello cookie-demo');
});
app.listen(3000, () => {
console.log('Example app listening on port 3000!');
});

由于设置了httpOnly,所以cookie3读不出来

过了十秒钟再刷新,cookie1和cookie2没有了

child1.parent.com 和child2.parent.com 是子域,parent.com 是父域。
当 Cookie 的 domain 为child1.parent.com时 ,那么只有访问child1.parent.com的时候就会带上 Cookie,访问child2.parent.com 的时候是不会带上的
当 Cookie 的 domain 为parent.com时,那么访问child1.parent.com和child2.parent.com 都会带上 Cookie
app.get('/parent', (req, res) => {
res.cookie('parent-name', 'parent-value', {
path: '/parent'
})
res.send('<h1>父路径!</h1>')
})
app.get('/parent/childA', (req, res) => {
res.cookie('child-name-A', 'child-value-A', {
path: '/parent/childA'
})
res.send('<h1>子路径A!</h1>')
})
app.get('/parent/childB', (req, res) => {
res.cookie('child-name-B', 'child-value-B', {
path: '/parent/childB'
})
res.send('<h1>子路径B!</h1>')
})

在子路径内可以访问访问到父路径的 Cookie,反过来就不行
父路径就访问不到子路径的cookie

document.cookie
document.cookie='name=value; expires=Thu, 26 Feb 2119 11:50:25 GMT; domain=sankuai.com; path=/';
domain根据需要设置
跟添加是一样的操作,如果name跟现有cookie一样,则改写,否则是添加
把max-age改为0即可
let removeCookie = (name, path, domain) => {
document.cookie = `${name}=; path=${path}; domain=${domain}; max-age=0`
}
上来先看官方文档中对setState()的定义
英文文档最佳
英文-React.Component - React
中文-React.Component - React
先看个最简单的问题,点击按钮后,count是加2吗?
class NextPage extends Component<Props> {
static navigatorStyle = {
tabBarHidden: true
};
constructor(props) {
super(props);
this.state = {
count: 0
};
}
add() {
this.setState({
count: this.state.count + 1
});
this.setState({
count: this.state.count + 1
});
}
render() {
return (
<View style={styles.container}>
<TouchableOpacity
style={styles.addBtn}
onPress={() => {
this.add();
}}
>
<Text style={styles.btnText}>点击+2</Text>
</TouchableOpacity>
<Text style={styles.commonText}>当前count {this.state.count}</Text>
</View>
);
}
}
为什么会只加1?
看官网这句话
setState() does not always immediately update the component. It may batch or defer the update until later. This makes reading this.state right after calling setState() a potential pitfall. Instead, use componentDidUpdate or a setState callback (setState(updater, callback)), either of which are guaranteed to fire after the update has been applied. If you need to set the state based on the previous state, read about the updater argument below.
重点是前两句,翻译过来就是
setState()并不总是立即更新组件,它可能会进行批处理或者推迟更新。这使得在调用setState()之后立即读取this.state成为一个潜在的隐患。
先直接抛出点击按钮加2的正确答案吧,下面两种方法都OK
this.setState(preState => {
return {
count: preState.count + 1
};
});
this.setState(preState => {
return {
count: preState.count + 1
};
});setTimeout(() => {
this.setState({
count: this.state.count + 1
});
this.setState({
count: this.state.count + 1
});
}, 0);
相信能到这里的同学都知道了setState()是个既能同步又能异步的方法了,那具体什么时候是同步的,什么时候是异步的?只有去源码里面看实现是最靠谱的方式。
注:这里说的同步和异步只是“实现上看起来像同步还是异步,比如上面答案二setTimeout里面,看起来就是同步的”,实质上setState()是异步的
不管这里看不看得懂都没关系了,马上进入源码的世界。
上react的github仓库,直接clone下来
GitHub - facebook/react: A declarative, efficient, and flexible JavaScript library for building user interfaces.
git clone https://github.com/facebook/react.git
到目前我看为止,最新的版本是16.2.0,我选了15.6.0的代码
一是为了参考前辈们的分析成果
二来,我水平有限,如果写的实在不清晰,同学们还可以参考着其他人的分析文章一起读,而不至于完全理解不了
如何切换版本?
1、找到对应版本号
2、复制15.6.0的历史记录号
3、回滚
git reset --hard 911603b
如图,成功回滚到15.6.0版本

核心原则:既然是看源码,那当然就不是一行一行的读代码,而是看核心的**,所以接下来的代码都只会放核心代码,旁枝末节只提一下或者忽略
setState()的入口文件在src/isomorphic/modern/class/ReactBaseClasses.js
React组件继承自React.Component,而setState是React.Component的方法,因此对于组件来讲setState属于其原型方法
ReactComponent.prototype.setState = function(partialState, callback) {
this.updater.enqueueSetState(this, partialState);
if (callback) {
this.updater.enqueueCallback(this, callback, 'setState');
}
};partialState顾名思义-“部分state”,这取名,意思大概就是不影响原来的state的意思吧
当调用setState()时实际上是调用了enqueueSetState方法,我们顺藤摸瓜(我用的是vscode的全局搜索),找到了这个文件src/renderers/shared/stack/reconciler/ReactUpdateQueue.js

这个文件导出了一个ReactUpdateQueue对象,“react更新队列”,代码名字起的好可以自带注释,说的就是这种大作吧,在这里注册了enqueueSetState方法
先看enqueueSetState的定义
enqueueSetState: function(publicInstance, partialState) {
var internalInstance = getInternalInstanceReadyForUpdate(
publicInstance,
'setState',
);
var queue =
internalInstance._pendingStateQueue ||
(internalInstance._pendingStateQueue = []);
queue.push(partialState);
enqueueUpdate(internalInstance);
},这里只需要关注internalInstance的两个属性
_pendingStateQueue:待更新队列
_pendingCallbacks: 更新回调队列
如果_pendingStateQueue的值为null,将其赋值为空数组[],并将partialState放入待更新state队列_pendingStateQueue。最后执行enqueueUpdate(internalInstance);
接下来看enqueueUpdate
function enqueueUpdate(internalInstance) {
ReactUpdates.enqueueUpdate(internalInstance);
}它执行的是ReactUpdates的enqueueUpdate方法
var ReactUpdates = require('ReactUpdates');这个文件刚好就在旁边,不用找了src/renderers/shared/stack/reconciler/ReactUpdates.js

找到enqueueUpdate方法
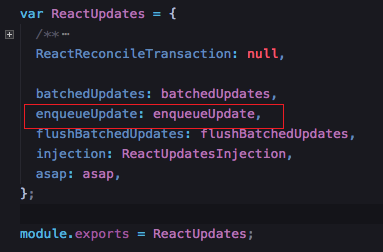
enqueueUpdate方法定义
function enqueueUpdate(component) {
ensureInjected();
if (!batchingStrategy.isBatchingUpdates) {
batchingStrategy.batchedUpdates(enqueueUpdate, component);
return;
}
dirtyComponents.push(component);
if (component._updateBatchNumber == null) {
component._updateBatchNumber = updateBatchNumber + 1;
}
}这段话对于理解setState非常重要
if (!batchingStrategy.isBatchingUpdates) {
batchingStrategy.batchedUpdates(enqueueUpdate, component);
return;
}
dirtyComponents.push(component);判断batchingStrategy.isBatchingUpdates
batchingStrategy是批量更新策略,isBatchingUpdates表示是否处于批量更新过程,开始默认值为false
上面这句话的意思是:
如果处于批量更新模式,也就是isBatchingUpdates为true时,不进行state的更新操作,而是将需要更新的component添加到dirtyComponents数组中
如果不处于批量更新模式,对所有队列中的更新执行batchedUpdates方法,往下看下去就知道是用事务的方式批量的进行component的更新,事务在下面。
借用《深入React技术栈》Page167中一图

那batchingStrategy.isBatchingUpdates又是怎么回事呢?看来它才是关键
但是,batchingStrategy 对象并不好找,它是通过 injection 方法注入的,一番寻找,发现了 batchingStrategy 就是 ReactDefaultBatchingStrategy。
src/renderers/shared/stack/reconciler/ReactDefaultBatchingStrategy.js
具体怎么找文件,又属于另一个范畴了,我们今天只专注 setState,其他的容后再说吧
相信部分同学在这里已经有些迷糊了,没关系,再坚持一下,旁枝末节先不管,只知道我们找到了核心方法batchedUpdates,马上要胜利了,别放弃(我第一次看也是这样熬过来的,一遍不行就两遍,大不了看多几遍)
先看批量更新策略-batchingStrategy,它到底是什么
var ReactDefaultBatchingStrategy = {
isBatchingUpdates: false,
batchedUpdates: function(callback, a, b, c, d, e) {
var alreadyBatchingUpdates = ReactDefaultBatchingStrategy.isBatchingUpdates;
ReactDefaultBatchingStrategy.isBatchingUpdates = true;
if (alreadyBatchingUpdates) {
return callback(a, b, c, d, e);
} else {
return transaction.perform(callback, null, a, b, c, d, e);
}
},
};
module.exports = ReactDefaultBatchingStrategy;终于找到了,isBatchingUpdates属性和batchedUpdates方法
如果isBatchingUpdates为true,当前正处于更新事务状态中,则将Component存入dirtyComponent中,
否则调用batchedUpdates处理,发起一个transaction.perform()
所有的 batchUpdate 功能都是通过执行各种 transaction 实现的
这是事务的概念,先了解一下事务吧
这一段就直接引用书本里面的概念吧,《深入React技术栈》Page169
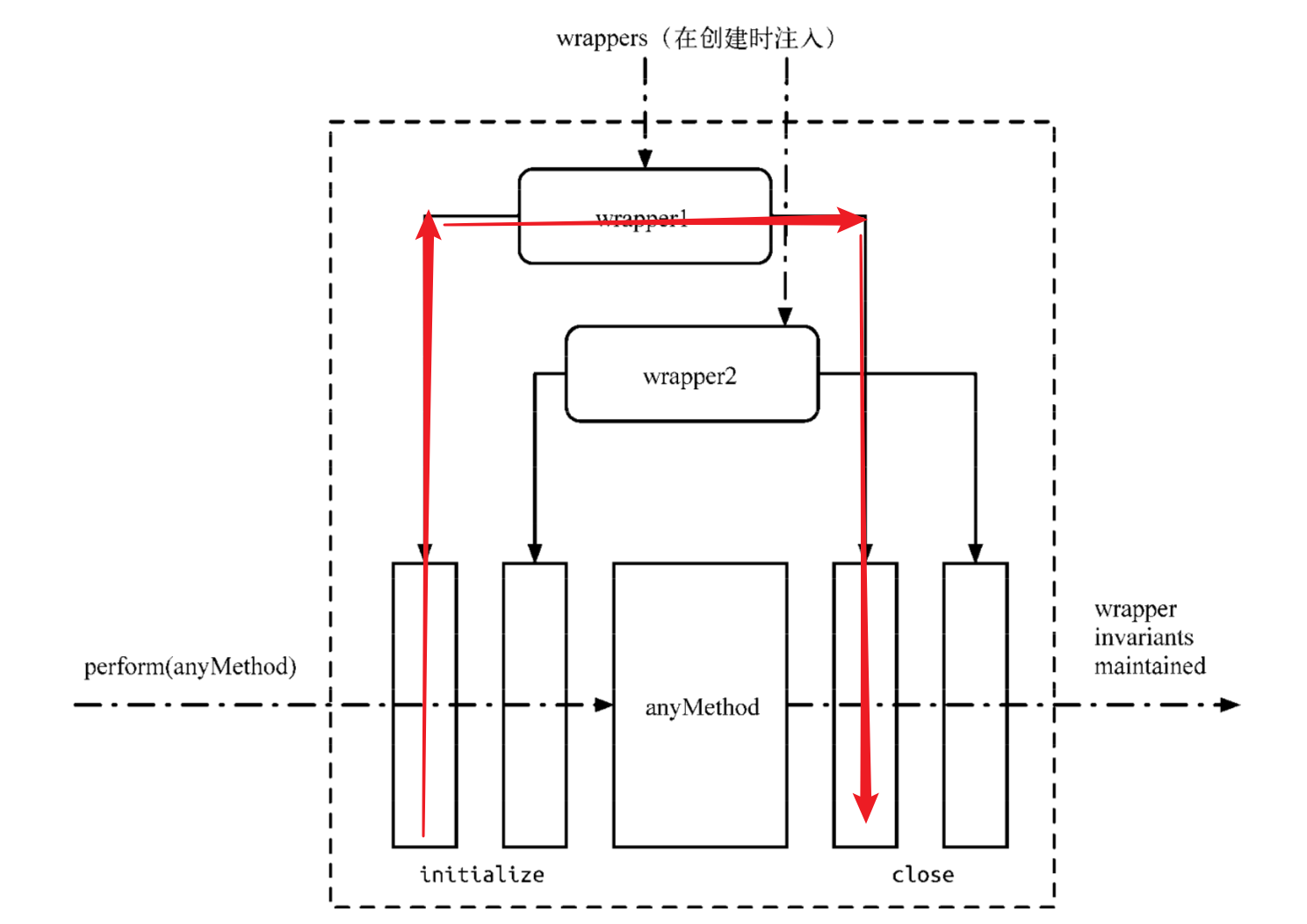
简单地说,一个所谓的 Transaction 就是将需要执行的 method 使用 wrapper 封装起来,再通过 Transaction 提供的 perform 方法执行。而在 perform 之前,先执行所有 wrapper 中的 initialize 方法;perform 完成之后(即 method 执行后)再执行所有的 close 方法。一组 initialize 及 close 方法称为一个 wrapper,从上面的示例图中可以看出 Transaction 支持多个 wrapper 叠加。
具体到实现上,React 中的 Transaction 提供了一个 Mixin 方便其它模块实现自己需要的事务。而要使用 Transaction 的模块,除了需要把 Transaction 的 Mixin 混入自己的事务实现中外,还需要额外实现一个抽象的 getTransactionWrappers 接口。这个接口是 Transaction 用来获取所有需要封装的前置方法(initialize)和收尾方法(close)的,因此它需要返回一个数组的对象,每个对象分别有 key 为 initialize 和 close 的方法。
下面这段代码应该能帮助理解
var Transaction = require('./Transaction');
// 我们自己定义的 Transaction
var MyTransaction = function() {
// do sth.
};
Object.assign(MyTransaction.prototype, Transaction.Mixin, {
getTransactionWrappers: function() {
return [{
initialize: function() {
console.log('before method perform');
},
close: function() {
console.log('after method perform');
}
}];
};
});
var transaction = new MyTransaction();
var testMethod = function() {
console.log('test');
}
transaction.perform(testMethod);
// before method perform
// test
// after method perform回到batchingStrategy:批量更新策略,再看看它的代码实现
var ReactDefaultBatchingStrategy = {
isBatchingUpdates: false,
batchedUpdates: function(callback, a, b, c, d, e) {
var alreadyBatchingUpdates = ReactDefaultBatchingStrategy.isBatchingUpdates;
ReactDefaultBatchingStrategy.isBatchingUpdates = true;
if (alreadyBatchingUpdates) {
return callback(a, b, c, d, e);
} else {
return transaction.perform(callback, null, a, b, c, d, e);
}
},
};可以看到isBatchingUpdates的初始值是false的,在调用batchedUpdates方法的时候会将isBatchingUpdates变量设置为true。然后根据设置之前的isBatchingUpdates的值来执行不同的流程
还记得上面说的很重要的那段代码吗
if (!batchingStrategy.isBatchingUpdates) {
batchingStrategy.batchedUpdates(enqueueUpdate, component);
return;
}
dirtyComponents.push(component);首先,点击事件的处理本身就是在一个大的事务中(这个记着就好),isBatchingUpdates已经是true了
调用setState()时,调用了ReactUpdates.batchedUpdates用事务的方式进行事件的处理
在setState执行的时候isBatchingUpdates已经是true了,setState做的就是将更新都统一push到dirtyComponents数组中;
在事务结束的时候才通过 ReactUpdates.flushBatchedUpdates 方法将所有的临时 state merge 并计算出最新的 props 及 state,然后将批量执行关闭结束事务。
到这里我并没有顺着ReactUpdates.flushBatchedUpdates方法讲下去,这部分涉及到渲染和Virtual Dom的内容,反正你知道它是拿来执行渲染的就行了。
到这里为止,setState的核心概念已经比较清楚了,再往下的内容,暂时先知道就行了,不然展开来讲一环扣一环太杂了,我们做事情要把握核心。
到这里不知道有没有同学想起一个问题
isBatchingUpdates 标志位在 batchedUpdates 发起的时候被置为 true ,那什么时候被复位为false的呢?
还记得上面的事务的close方法吗,同一个文件
src/renderers/shared/stack/reconciler/ReactDefaultBatchingStrategy.js
// 定义复位 wrapper
var RESET_BATCHED_UPDATES = {
initialize: emptyFunction,
close: function () {
ReactDefaultBatchingStrategy.isBatchingUpdates = false;
}
};
// 定义批更新 wrapper
var FLUSH_BATCHED_UPDATES = {
initialize: emptyFunction,
close: ReactUpdates.flushBatchedUpdates.bind(ReactUpdates)
};
var TRANSACTION_WRAPPERS = [FLUSH_BATCHED_UPDATES, RESET_BATCHED_UPDATES];
function ReactDefaultBatchingStrategyTransaction() {
this.reinitializeTransaction();
}
_assign(ReactDefaultBatchingStrategyTransaction.prototype, Transaction, {
getTransactionWrappers: function () {
return TRANSACTION_WRAPPERS;
}
});相信眼尖的同学已经看到了,close的时候复位,把isBatchingUpdates设置为false。

Object.assign(ReactDefaultBatchingStrategyTransaction.prototype, Transaction, {
getTransactionWrappers: function() {
return TRANSACTION_WRAPPERS;
},
});
var transaction = new ReactDefaultBatchingStrategyTransaction();通过原型合并,事务的close 方法,将在 enqueueUpdate 执行结束后,先把 isBatchingUpdates 复位,再发起一个 DOM 的批更新
到这里,我们会发现,前面所有的队列、batchUpdate等等都是为了来到事务的这一步,前面都只是批收集的工作,到这里才真正的完成了批更新的操作。
add() {
this.setState({
count: this.state.count + 1
});
this.setState({
count: this.state.count + 1
});
}setTimeout(() => {
this.setState({
count: this.state.count + 1
});
this.setState({
count: this.state.count + 1
});
}, 0);这两段代码
第一种情况,在执行第一个setState时,本身已经处于一个点击事件触发的这个大事务中,已经触发了一个batchedUpdates,isBatchingUpdates为true,所以两个setState都会被批量更新,这时候属于异步过程,this.state并没有立即改变,执行setState只是相当于把partialState(前面说的部分state)传入dirtyComponents,最后在事务的close阶段执行flushBatchedUpdates去重新渲染。
第二种情况,有了setTimeout,两次setState都会在点击事件触发的大事务中的批量更新batchedUpdates结束之后再执行,所以他们会触发两次批量更新batchedUpdates,也就会执行两个事务和函数flushBatchedUpdates,就相当于同步更新的过程了。
参考
React技术内幕 setState的秘密 - 掘金
React源码分析 - 组件更新与事务 - 掘金
源码看React setState漫谈(一) - 前端成长之路 - SegmentFault 思否
源码看React setState漫谈(二) - 前端成长之路 - SegmentFault 思否
最近在进行RN项目重构,通过查阅各种资料,从RN底层出发,思考总结了一些从react到react-native的性能优化相关问题
Performance · React Native
请先认真查看官方文档(英文文档)这一章节
前方高能请注意:Unbundling + inline requires这一节,中文文档木有!!!
先看看可能会导致产生性能问题的常见原因

这里先给出我自己的结论,然后会从底层原理开始理解为何要这样做,最后是每项方法的具体展开(未完待续)

这部分都不是死知识,可能哪天我又会有更广阔的思路与解决办法,或许会推翻现在的结论,所以本文会持续保持更新。。。
谈性能之前,我们先了解一下RN的工作原理
通过RN我们可以用JS实现跨平台App,也就是FB说的write once, run everywhere

RN为我们提供了JS的运行环境,所以前端开发者们只需要关心如何编写JS代码,画UI只需要画到virtual DOM 中,不需要特别关心具体的平台
至于如何把JS代码转成native代码的脏活累活,RN底层全干了

RN的本质是把中间的这个桥Bridge给搭好,让JS和native可以互相调用
RN的加载流程主要为几个阶段
Dive into React Native performance | Engineering Blog | Facebook Code | Facebook

通过对FaceBook的ios版进行性能测试,得到上面的耗时图
可以看到,绿色的JS Init + Require占据了一大半的时间,这部分主要的操作是初始化JS环境:下载JS Bundle、运行JS Bundle
JS Bundle 是由 RN 开发工具打包出来的 JS 文件,其中不仅仅包含了RN 页面组件的 JS 代码,还有 react、react-native 的JS代码,还有我们经常会用上的redux、react-navigation等的代码,RN 非常简单的 demo 页面minify 之后的 JS Bundle 文件有接近 700KB,所以 JS Bundle文件大小是性能优化的瓶颈
假设我们有一个大型App,它囊括了非常多的页面,但是在常规使用中,很多页面甚至都不会被打开,还有一些复杂的配置文件以及很少使用的功能,这些相关的代码,在App启动的时候都是不需要的,那么,我们就可以考虑通过Unbundling拆包来优化性能
关于如何减少Bundle包的大小,目前主流的方法是拆分Bundle包,把框架代码和业务代码单独出来,框架代码非常大,因此要分离出来单独前置加载,而业务代码则变成很小的JS代码单独发布,下面提供一些前人的经验链接
但在拆包之前,FB官方还提了几条在此之前更应该做好的优化点
Doing less
Scheduling
React-Native通用化建设与性能优化 - Web前端 腾讯IVWeb 团队社区
不愧是腾讯,主要讲了通用化建设、bundle本地分包、项目线上性能分析几项
RN分包之Bundle改造
RN 打包那些事儿 | YMFE
React Native拆包及热更新方案 · Solartisan
说到unbundling,官方文档还把 inline requires 一并合起来分析了
Inline requires delay the requiring of a module or file until that file is actually needed.
inline requires延迟加载模块或者文件,直到真的需要它们
看个小例子就很容易明白了
import React, { Component } from 'react';
import { Text } from 'react-native';
// ... import some very expensive modules
// You may want to log at the file level to verify when this is happening
console.log('VeryExpensive component loaded');
export default class VeryExpensive extends Component {
// lots and lots of code
render() {
return <Text>Very Expensive Component</Text>;
}
}import React, { Component } from 'react';
import { TouchableOpacity, View, Text } from 'react-native';
// 先把这个组件赋值为null
let VeryExpensive = null;
export default class Optimized extends Component {
state = { needsExpensive: false };
didPress = () => {
if (VeryExpensive == null) {
// 真正需要这个组件的时候才加载
VeryExpensive = require('./VeryExpensive').default;
}
this.setState(() => ({
needsExpensive: true,
}));
};
render() {
return (
<View style={{ marginTop: 20 }}>
<TouchableOpacity onPress={this.didPress}>
<Text>Load</Text>
</TouchableOpacity>
// 根据需要判断是否渲染该组件
{this.state.needsExpensive ? <VeryExpensive /> : null}
</View>
);
}
}Even without unbundling inline requires can lead to startup time improvements, because the code within VeryExpensive.js will only execute once it is required for the first time
上面的内容主要是关于首屏渲染速度的性能优化
那么进入App后的性能点又在哪里呢?还是回到Bridge
首先,在苹果和谷歌两位大佬的光环下,native代码在设备上的运行速度毋容置疑,而JS作为脚本语言,本来就是以快著称,也就是说两边的独立运行都很快,如此看来,性能瓶颈只会出现在两端的通信上,但两边其实不是直接通信的,而是通过Bridge做中间人,查找、调用模块、接口等操作逻辑,会产生到能让UI层明显可感知的卡顿,那么性能控制就变成了如何尽量减少Bridge所需要的逻辑。
总结起来,核心的RN性能优化点就比较清晰明朗了
每个小点主要会按照容易实施执行的顺序来写
生命周期请看官方文档React.Component - React
react应用中的state和props的改变都会引起re-render
考虑下面这种情况
class Home extends Component<Props> {
constructor(props) {
super(props);
this.state = {
a: '点我看看会不会re-render',
}
}
render() {
console.log('重新渲染 re-render------------------');
return (
<View style={styles.container}>
<TouchableOpacity style={styles.addBtn} onPress={() => this.setState({ a: this.state.a })}>
<Text>{this.state.a}</Text>
</TouchableOpacity>
</View>
);
}
}核心代码是this.setState({ a: this.state.a })

明明没有改变a,只是setState了一下而已,就直接触发了重新渲染,试想一下,如果页面有大型数据,这会造成多大的性能浪费
加上shouldComponentUpdate钩子看看如何
shouldComponentUpdate(nextProps, nextState) {
return nextState.a !== this.state.a
}
嗯,这下好了点,不会无脑渲染了
那么假如是个引用对象呢?
const obj = { num: 1 };
class Home extends Component<Props> {
constructor(props) {
super(props);
this.state = {
b: null
}
}
componentWillMount() {
this.setState({
b: obj
})
}
render() {
console.log('重新渲染 re-render------------------');
return (
<View style={styles.container}>
<TouchableOpacity style={styles.addBtn} onPress={() => {
obj.num++;
this.setState({
b: obj
})
}}>
<Text>{this.state.b.num}</Text>
</TouchableOpacity>
</View>
);
}
}给b永远指向同一个引用对象obj,虽然每次点击的时候,obj.num都会被改变
但是,页面会不会重新渲染呢?
继续看图

很好,对象的内容变了,页面也重新渲染
那么加上shouldComponentUpdate比较一下呢?
shouldComponentUpdate(nextProps, nextState) {
return nextState.b !== this.state.b
}
页面毫无变化
原因:b每次都指向了同一个引用对象obj,引用地址没变,shouldComponentUpdate只会做浅比较,自然会返回false,页面不会重新渲染
到这里应该能很好的解释了shouldComponentUpdate的特点
那么如何处理引用对象的情况呢?目前最推崇的做法是使用不可变对象immutablejs,facebook自家出的
GitHub - facebook/immutable-js
好了,研究去吧
另外,还有个pureComponent,看下官方介绍就好了
React Top-Level API - React
React.PureComponent
React.PureComponent is similar to React.Component. The difference between them is that React.Component doesn’t implement shouldComponentUpdate(), but React.PureComponent implements it with a shallow prop and state comparison.If your React component’s render() function renders the same result given the same props and state, you can use React.PureComponent for a performance boost in some cases.
Note
React.PureComponent’s shouldComponentUpdate() only shallowly compares the objects. If these contain complex data structures, it may produce false-negatives for deeper differences. Only extend PureComponent when you expect to have simple props and state, or use forceUpdate() when you know deep data structures have changed. Or, consider using immutable objects to facilitate fast comparisons of nested data.
Furthermore, React.PureComponent’s shouldComponentUpdate() skips prop updates for the whole component subtree. Make sure all the children components are also “pure”.
说到底,也只是会自动使用shouldComponentUpdate钩子的普通Component而已,没什么特殊的

InteractionManager和requestAnimationFrame(fn)的作用类似,都是为了避免动画卡顿,具体的原因是边渲染边执行动画,或者有大量的code计算阻塞页面进程。
InteractionManager.runAfterInteractions是在动画或者操作结束后执行
InteractionManager.runAfterInteractions(() => {
// ...long-running synchronous task...
});window.requestAnimationFrame - Web API 接口 | MDN
使用requestAnimationFrame(fn)在下一帧就立即执行回调,这样就可以异步来提高组件的响应速度;
OnPress() {
this.requestAnimationFrame(() => {
// ...setState操作
});
}还有setImmediate/setTimeout(): 这个是比较原始的奔方法,很有可能影响动画的流畅度
Direct Manipulation · React Native
通过Direct Manipulation的方式直接在底层更新了Native组件的属性,从而避免渲染组件结构和同步太多视图变化所带来的大量开销。
这样的确会带来一定的性能提升,同时也会使代码逻辑难以理清,而且并没有解决从JS侧到Native侧的数据同步开销问题。
因此这个方式官方都不再推荐,更推荐的做法是合理使用setState()和shouldComponentUpdate()方法解决这类问题。
Use setNativeProps when frequent re-rendering creates a performance bottleneck
Direct manipulation will not be a tool that you reach for frequently; you will typically only be using it for creating continuous animations to avoid the overhead of rendering the component hierarchy and reconciling many views. setNativeProps is imperative and stores state in the native layer (DOM, UIView, etc.) and not within your React components, which makes your code more difficult to reason about. Before you use it, try to solve your problem with setState and shouldComponentUpdate.
Animated的前提是尽量减少不必要的动画,具体的使用方式请看官方文档Animated · React Native
如果觉得Animated的计算很麻烦,比如一些折叠、增加减少view、改变大小等简单的操作,可以使用LayoutAnimation来流畅的完成一次性动画
看下直接setState和使用LayoutAnimation后的效果对比
直接setState

LayoutAnimation效果1

LayoutAnimation效果2

使用很简单,分为两种情况
componentWillUpdate钩子里面,让整个组件所有动画都应该该效果,或者在单独需要动画的setState方法前面使用LayoutAnimation.spring();componentWillUpdate() {
// spring, easeInEaseOut, linear
LayoutAnimation.linear();
}componentWillUpdate() {
LayoutAnimation.configureNext(config)
}const config = {
duration: 500, // 动画时间
create: {
// spring,linear,easeInEaseOut,easeIn,easeOut,keyboard
type: LayoutAnimation.Types.linear,
// opacity,scaleXY 透明度,位移
property: LayoutAnimation.Properties.opacity,
},
update: {
// 更新时显示的动画
type: LayoutAnimation.Types.easeInEaseOut,
}
};(未完待续。。。)
感谢您耐心看到这里,希望有所收获!
如果不是很忙的话,麻烦点个star⭐【Github博客传送门】,举手之劳,却是对作者莫大的鼓励。
我在学习过程中喜欢做记录,分享的是自己在前端之路上的一些积累和思考,希望能跟大家一起交流与进步。
#Front-End/JS/基础
参考资料
从一道题说JavaScript的事件循环
这一次,彻底弄懂 JavaScript 执行机制 - 掘金 这篇真的讲的特别通俗易懂
【朴灵评注】JavaScript 运行机制详解:再谈Event Loop - CSDN博客
event loop英文版 有动画
Node 定时器详解-阮一峰 - 后端 - 掘金
从event loop规范探究javaScript异步及浏览器更新渲染时机 · Issue #5 · aooy/blog · GitHub 本篇文章用了实验测试
JS是单线程的,这个线程中拥有唯一的一个事件循环,一切javascript版的"多线程"都是用单线程模拟出来的
事件循环是js实现异步的一种方法,也是js的执行机制
事件循环的顺序,决定js代码的执行顺序。进入整体代码(宏任务)后,开始第一次循环。接着执行所有的微任务。然后再次从宏任务开始,找到其中一个任务队列执行完毕,再执行所有的微任务。
setTimeout、setInterval,这二者同源,旗下微任务会进入相同的任务队列setImmediate(Node.js 环境)PromiseMutaionObserver(HTML5 新特性)process.nextTick(Node.js 环境)
JavaScript引擎的内部运行机制跟Event loop没有半毛钱的关系
引擎指的是虚拟机,对于Node来说是V8、对Chrome来说是V8、对Safari来说JavaScript Core,对Firefox来说是SpiderMonkey
JavaScript的执行环境就是上面所说的浏览器、node、Ringo
与用途有关,JavaScript的主要用途是与用户互动,以及操作DOM
假定JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准?
为了利用多核CPU的计算能力,HTML5提出Web Worker标准,允许JavaScript脚本创建多个线程,但是子线程完全受主线程控制,且不得操作DOM。所以,这个新标准并没有改变JavaScript单线程的本质。
只要主线程空了,就会去读取"任务队列",这就是JavaScript的运行机制。这个过程会不断重复。
【JavaScript运行环境的运行机制,不是JavaScript的运行机制。】
朴灵大佬怼阮老师的原文

【上面这段初步地在说event loop。但是异步跟event loop其实没有关系。准确的讲,event loop是实现异步的一种机制】
【一般而言,操作分为:发出调用和得到结果两步。发出调用,立即得到结果是为同步。发出调用,但无法立即得到结果,需要额外的操作才能得到预期的结果是为异步。同步就是调用之后一直等待,直到返回结果。异步则是调用之后,不能直接拿到结果,通过一系列的手段才最终拿到结果(调用之后,拿到结果中间的时间可以介入其他任务)。】
【上面提到的一系列的手段其实就是实现异步的方法,其中就包括event loop。以及轮询、事件等。】
【所谓轮询:就是你在收银台付钱之后,坐到位置上不停的问服务员你的菜做好了没。】
【所谓(事件):就是你在收银台付钱之后,你不用不停的问,饭菜做好了服务员会自己告诉你。】

不要混淆nodejs和浏览器中的event loop
每一轮的事件循环,分成六个阶段。这些阶段会依次执行。
setTimeout、setInterval
除了以下操作的回调函数,其他的回调函数都在这个阶段执行。
该阶段只供 libuv 内部调用,这里可以忽略
这个阶段是轮询时间,用于等待还未返回的 I/O 事件,比如服务器的回应、用户移动鼠标等等。
这个阶段的时间会比较长。如果没有其他异步任务要处理(比如到期的定时器),会一直停留在这个阶段,等待 I/O 请求返回结果。
setImmediate
该阶段执行关闭请求的回调函数,比如socket.on('close', ...)。

由于setTimeout在 timers 阶段执行,而setImmediate在 check 阶段执行。所以,setTimeout会早于setImmediate完成。
实际执行的时候,结果却是不确定
setTimeout(() => console.log(1));
setImmediate(() => console.log(2));
实际执行的时候,进入事件循环以后,有可能到了1毫秒,也可能还没到1毫秒,取决于系统当时的状况。如果没到1毫秒,那么 timers 阶段就会跳过,进入 check 阶段,先执行setImmediate的回调函数
但是,这个代码却setImmediate优先于setTimeout执行
const fs = require('fs');
fs.readFile('test.js', () => {
setTimeout(() => console.log(1));
setImmediate(() => console.log(2));
});
上面代码会先进入 I/O callbacks 阶段,然后是 check 阶段,最后才是 timers 阶段。因此,setImmediate才会早于setTimeout执行。
有两种event loops,一种在浏览器上下文,一种在workers中。
浏览器上下文是一个将 Document 对象呈现给用户的环境。在一个 Web 浏览器内,一个标签页或窗口常包含一个浏览上下文,如一个 iframe 或一个 frameset 内的若干 frame。
每个线程都有自己的event loop。
浏览器可以有多个event loop,browsing contexts和web workers就是相互独立的。
所有同源的browsing contexts可以共用event loop,这样它们之间就可以相互通信。
从event loop规范探究javaScript异步及浏览器更新渲染时机 · Issue #5 · aooy/blog · GitHub 这里用了实验测试
渲染的基本流程

Note: 可以看到渲染树的一个重要组成部分是CSSOM树,绘制会等待css样式全部加载完成才进行,所以css样式加载的快慢是首屏呈现快慢的关键点。
结论
在一轮event loop中多次修改同一dom,只有最后一次会进行绘制。
渲染更新(Update the rendering)会在event loop中的tasks和microtasks完成后进行,但并不是每轮event loop都会更新渲染,这取决于是否修改了dom和浏览器觉得是否有必要在此时立即将新状态呈现给用户。如果在一帧的时间内(时间并不确定,因为浏览器每秒的帧数总在波动,16.7ms只是估算并不准确)修改了多处dom,浏览器可能将变动积攒起来,只进行一次绘制,这是合理的。
如果希望在每轮event loop都即时呈现变动,可以使用requestAnimationFrame。
具体浏览器的工作原理参考这里新式网络浏览器幕后揭秘
当用户输入URL后

第一步就是DNS预解析
域名系统 - 维基百科,自由的百科全书
Domain Name System 将域名和IP地址相互映射的一个分布式数据库
DNS 预读取是一项使浏览器主动去执行域名解析的功能,其范围包括文档的所有链接,无论是图片的,CSS 的,还是 JavaScript 等其他用户能够点击的 URL,减少用户点击链接时的延迟。
当浏览器访问一个域名的时候,需要解析一次DNS,获得对应域名的ip地址。
浏览器缓存 => 系统缓存 => 路由器缓存 =>ISP(运营商)DNS缓存 => 根域名服务器 => 顶级域名服务器 => 主域名服务器的顺序
逐步读取缓存,直到拿到IP地址
作用:根据浏览器定义的规则,提前解析之后可能会用到的域名,使解析结果缓存到系统缓存中,缩短DNS解析时间,来提高网站的访问速度
希望在HTTPS页面开启自动解析功能时,添加如下标记
<meta http-equiv="x-dns-prefetch-control" content="on">
// off 则是关闭也可以通过在服务器端发送 X-DNS-Prefetch-Control 报头
Chromium会自动解析href属性(a标签),该行为与用户浏览网页是并行的。但为了确保安全,HTTPS页面不会自动解析
DNS Prefetching - Chromium官方文档
Chromium不使用浏览器的网络堆栈,直接使用操作系统的缓存。通过8个异步线程执行预解析,每个线程处理一个队列,来等待域名的响应,最终操作系统会响应一个DNS结果给线程,然后线程丢弃它,等待下一个预解析请求。
<link rel="dns-prefetch" href="http://www.google.com">一般来说并不需要去管理预读取,但是可能会有用户希望关闭预读取功能。这时只需要设置 network.dns.disablePrefetch preference 值为 true 就可以了
默认情况下,通过 HTTPS 加载的页面上内嵌链接的域名并不会执行预加载。在 Firefox 浏览器中,可以通过设置 network.dns.disablePrefetchFromHTTPS 值为 false 来改变这一默认行为。
DNS Prefetch 的原理就是在 HTTP 建立之前,将 DNS 查询的结果缓存到系统/浏览器中,提升网页的加载效率
让我们来实际看一下淘宝的DNS预解析是怎么做的
进WebPagetest输入https://www.taobao.com
找到结果中的下面内容,看DNS Lookup一项
那些结果比较大的,就是没有预解析的

打开淘宝,看它的link标签,带rel='dns-prefetch'的那些
然后应该可以发现,上面那些解析时间比较长的域名没有在这个列表中

1、新用户访问,后端可以通过 Cookie 判断是否为首次进入站点,对于这类用户,DNS Prefetch 可以比较明显地提升访问速度
2、登录页,提前在页面上进行下一跳页用到资源的 DNS Prefetch
2、上面说到chrome使用了8个异步线程来处理DNS预解析,所以过多的prefetch并不一定能提高网页加载效率
1、静态资源域名
2、JS里会发起跳转的域名
3、会重定向的域名
实际上还是会增加html的代码量的,特别是域名多的情况下
可以通过js初始化一个iframe异步加载一个页面,而这个页面里包含本站所有的需要手动dns prefetching的域名

在PC上,为了突破浏览器的单域名多线程并发限制,大家会采用域名发散:http 静态资源采用多个子域名,以提供最大并行度,让客户端加载静态资源更为迅速
为什么浏览器要做并发限制?
1、以前的服务器负载能力差,流量大容易奔溃,所以为了保护服务器,浏览器做了单域名最大并发限制
2、防止DDOS攻击,最基本的 DoS 攻击就是利用合理的服务请求来占用过多的服务资源,从而使合法用户无法得到服务的响应。如果不限制并发请求数量…
顾名思义:尽量将静态资源只放在一个域名下面
既然域名发散优点这么明显,那么域名收敛怎么来的?
上面说了是PC下使用域名发散,那么现在是移动互联网时代,无线设备占多(写这个文章的时候是2018年末,5G都快来了,地域和网速限制马上不会再成为瓶颈,但还是要究其根本)
首先,HTTP请求需要经历这么个过程
DNS域名解析 -> TCP 3次握手 -> 发起HTTP请求 -> 服务器响应HTTP请求 -> …… -> 浏览器解析渲染页面
第一个DNS解析是一个很复杂的过程,此处略过…
PC上DNS解析消耗相对较小
但移动端(假设信号不够强)的DNS消耗是比较可观的(相对而言)
所以,在增加域名的同时,会带来一定的DNS解析消耗,所以域名收敛能降低这个成本。
但是,单纯的靠域名收敛降低这个成本,貌似对性能提升是个鸡肋
那么单域名的并发问题还是存在,怎么处理,核心是解除最大连接数的限制,那么SPDY/HTTP2的多路复用功能就派上用场了
这两新协议对HTTP1.1做了不少的优化,核心是减少连接数,还有头部压缩、服务器推送,强制SSL安全协议等等
总的来说,尽快拥抱新技术吧
前端无法向原生App那样直接操作本地文件,不然一个网页就能偷光用户电脑上的文件,用户想要触发文件操作,主要有三种
1、<input type='file' />选择本地文件
2、通过拖拽,利用drop事件
3、在编辑框里面复制粘贴(这里不讲,有兴趣的同学可当做延伸题目自己去了解)
<input type='file' /><input id="file1" type="file">// 监听input的change事件,通过e拿到文件
$('#file1').change(e => {
const files = e.target.files || e.dataTransfer.files;
});可以打印files看一下是什么,可以看到是一个对象,以files[0]表示具体的文件,还有一个长度属性是1
(如果同时导入多个文件,估计就是files[1]、files[2]的读法了,长度就是对应的文件数量,这里纯靠猜,本人没实践过,有兴趣的同学可以自己研究)

这里要注意的是,这个files在很多时候都是不可用的,还需要转换成base64格式或者其他格式才能使用,怎么转换等下就讲,总之就是目前拿到的files没*用
// 一个空的div就可以了,样式自己写吧
<div id="dropbox" />const dropbox = $('#dropbox');
// jQuery的监听事件用on,不用addEventListener
dropbox.on({
// 阻止dragenter和dragover事件的默认行为
dragenter: dragenter,
dragover: dragover,
drop: drop
})
function dragenter(e) {
e.stopPropagation();
e.preventDefault();
}
function dragover(e) {
e.stopPropagation();
e.preventDefault();
}
function drop(e) {
e.stopPropagation();
e.preventDefault();
// 在jQuery里面,得来originalEvent才拿得到
const files = e.originalEvent.dataTransfer.files;
}在jQuery里面,需要去originalEvent的dataTransfer里面才拿得到文件;
拖拽事件,还需要处理掉默认行为
到目前为主,我们只是拿到了两类没*用的files,还需要转换为能在页面上预览的格式以及可以上传到服务器的格式才行,传说中的base64。
图片的 base64 编码就是可以将一副图片数据编码成一串字符串,使用该字符串代替图像地址。(省去了一次HTTP请求,但只针对于小图片,大图片转码后可能占用的内存更大)
转换文件,目前有两种常用的方式:FileReader、ObjectURL
老惯例,先上MDN
FileReader - Web API 接口 | MDN
FileReader 对象允许Web应用程序异步读取存储在用户计算机上的文件(或原始数据缓冲区)的内容,使用 File 或 Blob 对象指定要读取的文件或数据。
其中File对象可以是来自用户在一个元素上选择文件后返回的FileList对象,也可以来自拖放操作生成的 DataTransfer对象,还可以是来自在一个HTMLCanvasElement上执行mozGetAsFile()方法后返回结果。
FileReader 包括四个异步读取文件的选项(具体请查阅)
FileReader.readAsArrayBuffer()、FileReader.readAsBinaryString()、FileReader.readAsDataURL()、FileReader.readAsText()
对FileReader 对象调用其中某一种读取方法后,可使用 onloadstart、onprogress、onload、onabort、onerror 和 onloadend 跟踪其进度
具体步骤:
1、实例化FileReader对象
2、FileReader.readAsDataURL() 开始读取内容
2、事件处理,通过onload事件读取文件(注意,是个异步过程,如果想要拿到数据,需要注册回调事件callback)
我这里封装好了一个转换函数
function transferImgToBase64(files, cb) {
// 先判断浏览器是否支持,一般都支持的啦,求个心安而已
if (typeof FileReader === 'undefined') {
alert('您的浏览器不支持图片上传,请升级您的浏览器');
return false;
}
// 实例化实例化`FileReader`对象
let reader = new FileReader();
// 读取内容
reader.readAsDataURL(files[0]);
// 通过onload事件拿到文件,并注册一个回调事件cb,这个回调事件就是拿来上传文件、预览文件等等的操作,回调的参数就是处理好的base64格式文件
reader.onload = e => {
cb ? cb(e.target.result) : null;
};
}预览就比较简单了
$('#file1').change(e => {
const files = e.target.files || e.dataTransfer.files;
$('#img').attr('src', objectURL)
// 这里的res就是传入的base64数据,上面的e.target.result
transferImgToBase64(files, res => {
console.log('转码后', res);
$('#img').attr('src', res);
});
});在input上面放个空的img标签,通过DOM操作,用attr对src属性进行操作即可看到页面上的预览效果(样式就不写了)
<img id="img" src="">
<input id="file1" type="file">最后一起看看效果

ObjectURL相当于文件的一个临时路径,此临时路径可随时生成、随时释放,在本地浏览器使用起来时,与普通的url无异
URL.createObjectURL() - Web API 接口 | MDN
// blog是用来创建 URL 的 File 对象或者 Blob 对象
objectURL = URL.createObjectURL(blob);在每次调用 createObjectURL() 方法时,都会创建一个新的 URL 对象,即使你已经用相同的对象作为参数创建过。当不再需要这些 URL 对象时,每个对象必须通过调用 URL.revokeObjectURL() 方法来释放。浏览器会在文档退出的时候自动释放它们,但是为了获得最佳性能和内存使用状况,你应该在安全的时机主动释放掉它们。
通过window.URL.createObjectURL(files[0])拿到URL对象,方式比FileReader更简单一点
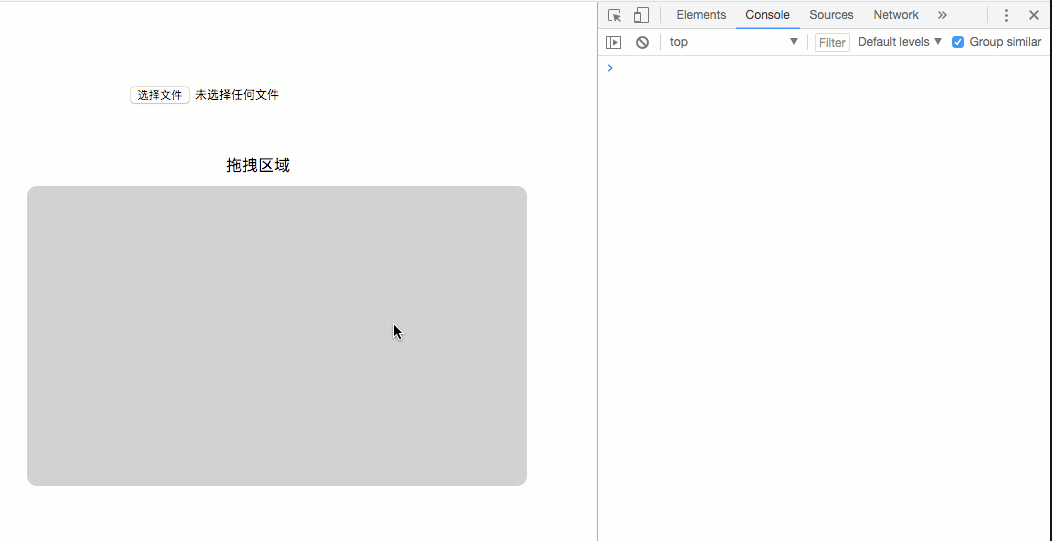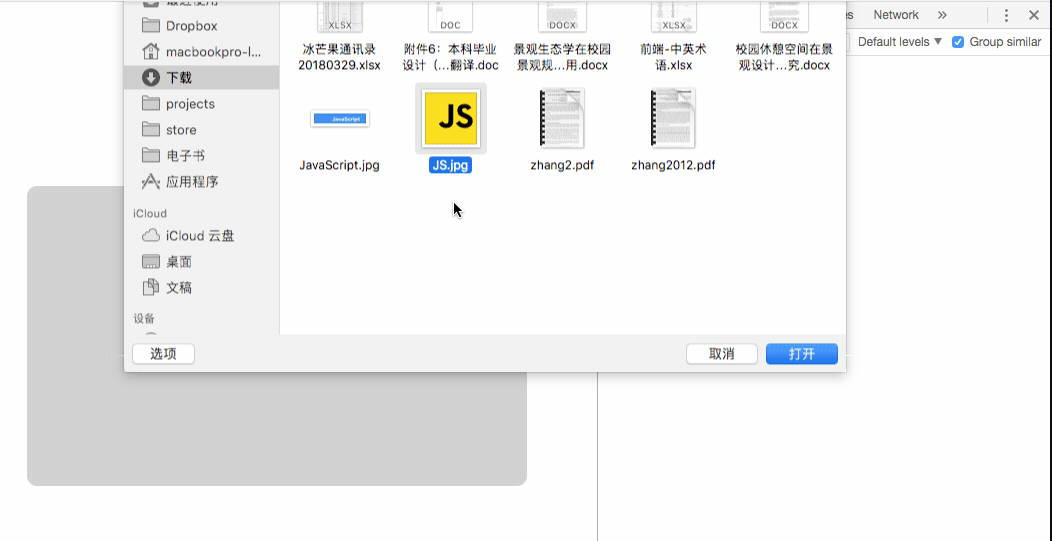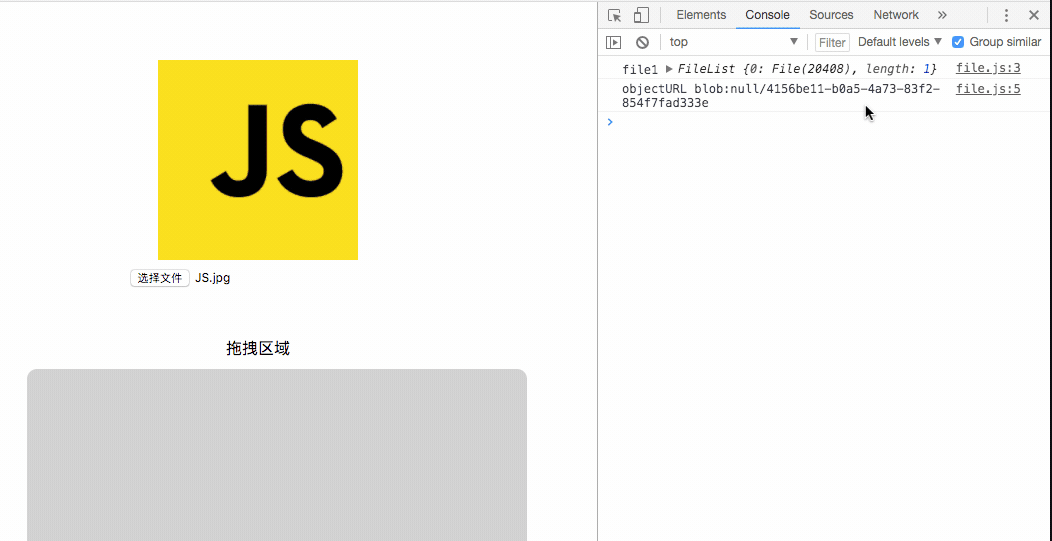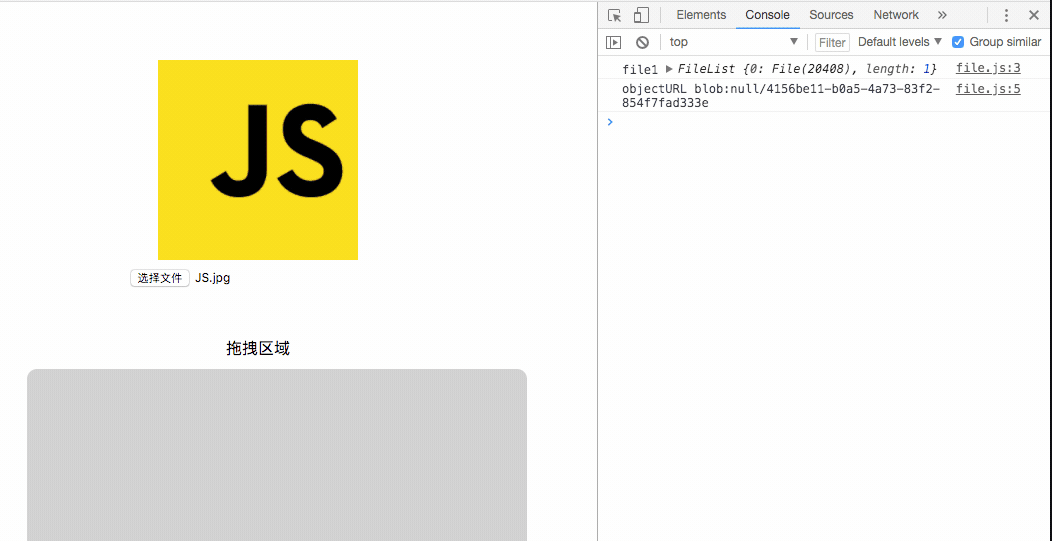
$('#file1').change(e => {
const files = e.target.files || e.dataTransfer.files;
console.log('file1',files)
const objectURL = window.URL.createObjectURL(files[0]);
$('#img').attr('src', objectURL)
});可以打印看下是什么格式的东西
console.log('objectURL',objectURL);控制台可以看到如下输出
objectURL blob:null/bfefecc5-6c63-4465-84a2-8dc6c2ac48fd
直接赋值给图片的src属性,即可实现预览,但是,它没有事件处理钩子,实现不了上传进度等业务功能,也没有完成转换base64格式,但如果只是单纯的想要实现预览,倒也足够了。
另外,要记得在合适的时候释放浏览器记忆
window.URL.revokeObjectURL($('#img').src);<span href="" class="uploadBtn">
{{uploadText}}
<input type="file" name='file' @change="onFileChange" class="file-input">
</span>通过一个span把input隐藏起来,加以美化
.uploadBtn {
position: relative;
display: inline-block;
width: 80px;
text-align: center;
line-height: 30px;
border: 1px solid #e7e7eb;
border-radius: 5px;
padding: 2px 20px;
color: #fff;
background: #08cc6a;
margin-right: 10px;
&:hover {
background: #07b35d;
}
input {
position: absolute;
left: 0;
top: 0;
width: 130px;
height: 45px;
opacity: 0;
cursor: pointer;
}
}通过opacity: 0;把真正的input控件隐藏起来
然后让整个span的大小覆盖到input的范围大小
从丑丑的

变成了

上面的@change="onFileChange"是vue的写法,用jQuery的同学直接加个监听事件就好了
vm.sendRequest是我自己封装的网络请求方法,$.ajax()的方法也写在下面的注释中了
onFileChange(e) {
const vm = this;
const files = e.target.files || e.dataTransfer.files;
let formData = new FormData();
console.log('文件', files, files[0].name);
formData.append(files[0].name, files[0]);
// const settings = {
// "async": true,
// "crossDomain": true,
// "url": "/shop/reseller/order/upload",
// "method": "POST",
// "headers": {
// "Content-Type": "application/x-www-form-urlencoded",
// "Cache-Control": "no-cache",
// // "Postman-Token": "cd09edb9-13ea-e249-9efb-aa7d9027b441"
// },
// "processData": false,
// "contentType": false,
// "mimeType": "multipart/form-data",
// "data": formData,
// }
// $.ajax(settings).done(function (response) {
// console.log('看看回调',response);
// });
vm.uploadText = '上传中...';
vm.sendRequest({
url: `/shop/reseller/order/upload`,
data: formData,
success(d) {
toast('文件上传成功', true);
vm.uploadText = '上传订单';
vm.wrap = true;
vm.showResultBtn = true;
vm.orderCheckResult = d.data;
console.log('看看回调',d);
},
failed(err) {
toast('文件上传失败', false);
vm.uploadText = '上传订单';
toast(err.cnmsg, false);
}
});
},有几点要注意的
processData: false设置为false,data值是FormData对象,不需要对数据做处理。mimeType: "multipart/form-data",文件类型cache:false,上传文件不需要缓存contentType: false,上面已经注明了文件类型,而是是formdata对象直接上文档(相信很多同学都不会点开看,但我任性,就是要贴官方文档,原因不想说)
如何上传base64编码图片到七牛云 - 七牛开发者中心
FAQ 常见问题 - 七牛开发者中心
// key和token是向后端请求,后端向七牛请求回来的验证,七牛说:兄dei,拿好key和token,我帮你留了个坑,等会你上传文件的时候带上它们,我帮你把文件填坑里去
// 前端向七牛上传文件,带上key和token,说:牛哥,刚刚后端那兄弟帮我申请了个坑,就是这文件,你帮我存好哈
// 最后两个参数是成功与失败的回调
function uploadToQiniu(key, token, files, sucCB = () => {}, errCB = () => {}) {
// 判断https还是http,encode64方法是把key进行Base64编码,自己可以查一下
// 这个请求链接,上面两个链接中有,不然就找你们后端同学要
const url =
document.location.protocol === 'https:'
? `https://upload.qbox.me/putb64/-1/key/${encode64(key)}`
: `http://upload.qbox.me/putb64/-1/key/${encode64(key)}`
const header = {
'Content-Type': 'application/x-www-form-urlencoded',
Authorization: 'UpToken ' + token,
Host: 'upload.qbox.me'
};
// 转换files到base64格式,跟上面的大同小异,区别看下面
transferImgToBase64WithoutHead(files, (r) => {
const body = r;
// fetch ,网络请求API,不会?同学,就此别过了😀
fetch(url, {
method: 'POST',
headers: header,
body: body
})
.then(res => {
// 上传成功后拿到回调,你自己定义的处理办法
...yourOwnMethod(res)
})
});
}注意,这个方法多了WithoutHead几个字母
export function transferImgToBase64WithoutHead(files, cb) {
if (typeof FileReader === 'undefined') {
alert('您的浏览器不支持图片上传,请升级您的浏览器');
return false;
}
let reader = new FileReader();
reader.readAsDataURL(files[0]);
reader.onload = e => {
// 这里是唯一的区别,把转换后的base64编码的前面那一部分字符串去掉,参见下图,七牛只接受这样的格式作为body
let result = e.target.result.replace(/^data:image\/\w+;base64,/, '');
cb ? cb(result) : null;
};
}
function onFileChange(e) {
// 如何生成预览图,相信不用再说了吧
// 如何生成`files`,也不用我说了吧
// `sendRequest`是我们自己封的请求API,向后端请求key和token
this.sendRequest({
url: '********',
success(d) {
vm.token = d.data.data.token;
vm.key = d.data.data.key;
vm.productAdd.preview = d.data.data.token;
// 上传图片到七牛
uploadToQiniu(
d.data.data.key,
d.data.data.token,
files,
res => {
console.log('成功回调', res);
toast('图片上传成功', true)
},
err => {
console.log('失败回调', err);
toast('图片上传失败',false)
}
);
}
});
}利用Blob的slice方法进行分割,大概思路如下:
代码?
不存在的……延伸思考题
哈哈哈,我是不是很坑……
*年,自己动手,丰衣足食……
感谢您耐心看到这里,希望有所收获!
如果不是很忙的话,麻烦右上角点个star⭐,举手之劳,却是对作者莫大的鼓励。
我在学习过程中喜欢做记录,分享的是自己在前端之路上的一些积累和思考,希望能跟大家一起交流与进步,更多文章请看【amandakelake的Github博客】
参考
前端本地文件操作与上传 – 人人网FED博客
阅读以 JavaScript 编写的本地文件 - HTML5 Rocks
【前端攻略】:玩转图片Base64编码 - ChokCoco - 博客园
基于JS的大文件分片 - CSDN博客

插个图,来自于《JavaScript语言精髓与编程实践》第三章P184页,后来想想有点多而杂,所以就自己画了些重点内容如上图,有需要的同学可以直接看下面这图

null用typeof来检查上述七种类型时,返回的是对应的类型字符串值
但,有一个例外
typeof null === 'object' // truenull是唯一一个用typeof检测会返回object的基本类型值(注意‘基本’两字)
具体的原因,当面试官问到,可以这样吹一波
不同的对象在底层都表示为二进制
在JavaScript中二进制前三位为0的话都会被判断为object类型
null的二进制表示全是0,自然前三位也是0
所以 typeof null === “object”
上面的图中虽然列出了七种引用类型,但是
typeof ‘引用类型’ === ‘object’ 一定成立吗?
不,还有一种情况:typeof ‘某些引用类型’ === ‘function’
还是先直接看一些测试吧,看下答案跟你预想的是不是一回事?
如果全都胸有成竹,那下面这一小节你可以跳过了
typeof Function; // 'function'
typeof new Function(); // 'function'
typeof function() {}; // 'function'
typeof Array; // 'function'
typeof Array(); // 'object'
typeof new Array(); // 'object'
typeof []; // 'object'
typeof Boolean; // "function"
typeof Boolean(); // "boolean"
typeof new Boolean(); // "object"
typeof Math; // 'object'
typeof Math(); // Math is not a function
typeof new Math(); // Math is not a constructor先看前三句,原来typeof除了能判断基本类型和object之外,还能判断function类型,函数也属于对象
拿Array举例子
typeof Array; // 'function'
typeof Array(); // 'object'
typeof new Array(); // 'object'
typeof []; // 'object'Array是个构造函数,所以直接打印出function
但构造出来的Array()却又是另一回事了,构造出来的结果是个数组,自然属于引用类型,所以也就打印出了‘object’
构造函数 Array(..) 不要求必须带 new 关键字。不带时,它会被自动补上。 因此 Array(1,2,3) 和 new Array(1,2,3) 的效果是一样的
typeof Boolean; // "function"
typeof Boolean(); // "boolean"
typeof new Boolean(); // "object"Boolean是个构造函数,第一句没问题
Boolean()直接执行,得出了布尔值,所以得到了‘boolean’
而new出来的是个Boolean对象,具体来说就是:通过构造函数创建出来的是封装了基本类型值的封装对象,好好理解一下这句话
这里用String来举个例子吧,看到了吗,一个封装对象

但是,这里不推荐使用这种封装对象,看个例子
var a = new Boolean(false);
if (!a) {
console.log('Oops'); // 执行不到这里
}a是个对象,对象永远是真,所以……你懂了
个人建议不要轻易去碰包装类型,日常开发直接用字面量就好了(大牛自动忽略这段话)
Math和Global(浏览器中替代为window)都是内置的对象,并不是引用类型的一种
typeof Math; // 'object'
typeof Math(); // Math is not a function
typeof new Math(); // Math is not a constructor不是函数,不是构造器,这个应该能理解了吧。
首先,我们需要知道underfined和undeclared的区别
未定义与未声明
但是,对于typeof来说,这两者都一样,返回的都是underfined
var a;
typeof a; // 'underfined'
typeof b; // 'underfined'很明显,我们知道b就是undeclared(未声明的),但在typeof看来都是一样
这个特性,可以拿来做些什么呢?
举个简单的例子,在程序中使用全局变量 DEBUG 作为“调试模式”的开关。在输出调试信 息到控制台之前,我们会检查 DEBUG 变量是否已被声明。顶层的全局变量声明 var DEBUG = true 只在 debug.js 文件中才有,而该文件只在开发和测试时才被加载到浏览器,在生产环 境中不予加载。
问题是如何在程序中检查全局变量 DEBUG 才不会出现 ReferenceError 错误。这时 typeof 的 安全防范机制就成了我们的好帮手:
// 这样会抛出错误
if (DEBUG) {
console.log('Debugging is starting');
}
// 这样是安全的
if (typeof DEBUG !== 'undefined') {
console.log('Debugging is starting');
}这不仅对用户定义的变量(比如 DEBUG)有用,对内建的 API 也有帮助:
if (typeof atob === "undefined") {
atob = function() { /*..*/ };
}这样的安全防范机制在各式源码中非常常见,可见,大作们早已经把一些基础的东西弄得非常透彻并运用到实践中,所以说,看源码是我们快速提高的一个方式,应该错不了。
这一part引用自一、内存空间详解 · Sample GitBook
JS的执行上下文生成之后,会创建一个叫做变量对象的特殊对象(关于变量对象在我的其他文章中有讲到),JS的基础类型都保存在变量对象中
严格意义上来说,变量对象也是存放于堆内存中,但是由于变量对象的特殊职能,我们在理解时仍然需要将其于堆内存区分开来。
但引用数据类型的值是保存在堆内存中的对象。JavaScript不允许直接访问堆内存中的位置,因此我们不能直接操作对象的堆内存空间。
在操作对象时,实际上是在操作对象的引用而不是实际的对象。因此,引用类型的值都是按引用访问的。
这里的引用,我们可以理解为保存在变量对象中的一个地址,该地址与堆内存的实际值相关联。

看到这里,应该就能比较好的理解引用传参的相关问题了,这属于延伸思考,google去吧,学会自我思考和搜索也是一种技能。
《you don’t know JS》中 第一部分第4章
类型转换发生在静态类型语言的编译阶段,而强制类型转换则发生在动态类型语言的运行时(runtime)。
然而在 JavaScript 中通常将它们统称为强制类型转换,我个人则倾向于用“隐式强制类型转换”(implicit coercion)和“显式强制类型转换”(explicit coercion)来区分。
介绍显式和隐式强制类型转换之前,我们需要先掌握字符串、数字和布尔值之间类型转换的基本规则
1️⃣ToString
toString() 可以被显式调用,或者在需要字符串化时自动调用
null 转换为 "null",undefined 转换为 "undefined",true 转换为 "true"。
数字的字符串化则遵循通用规则
极小和极大的 数字使用指数形式:
// 1.07 连续乘以七个 1000
var a = 1.07 * 1000 * 1000 * 1000 * 1000 * 1000 * 1000 * 1000;
// 七个1000一共21位数字
a.toString(); // "1.07e21"数组的默认 toString() 方法经过了重新定义,将所有单元字符串化以后再用 "," 连接起 来
var a = [1,2,3];
a.toString(); // "1,2,3"2️⃣ ToNumber
其中 true 转换为 1,false 转换为 0。undefined 转换为 NaN,null 转换为 0。
处理失败 时返回 NaN(处理数字常量失败时会产生语法错误)
3️⃣ ToBoolean
先看什么是假值
• undefined
• null
• false
• +0、-0 和 NaN
• ""
假值的布尔强制类型转换结果为 false。
从逻辑上说,假值列表以外的都应该是真值(truthy)
再看下假值对象(这东西太有意思了😂)
不是说规定所有的对象都是真值,怎么还会有假值对象呢?
var a = new Boolean(false);
var b = new Number(0);
var c = new String('');
var d1 = Boolean( a && b && c );
var d2 = a && b && c;看看d1和d2有什么不同?是不是特有意思?

如果假值对象并非封装了假值的对象,那它究竟是什么?
值得注意的是,虽然 JavaScript 代码中会出现假值对象,但它实际上并不属于 JavaScript 语 言的范畴。
浏览器在某些特定情况下,在常规 JavaScript 语法基础上自己创建了一些外来(exotic) 值,这些就是“假值对象”。
假值对象看起来和普通对象并无二致(都有属性,等等),但将它们强制类型转换为布尔 值时结果为 false。
最后再看真值是什么
真值就是假值列表之外的值
再来看一段有意思的代码
var a = 'false';
var b = '0';
var c = "''";
var d1 = Boolean(a && b && c);
var d2 = a && b && c
到目前为止,我们得出的一个结论是:[]、{} 和 function(){} 都不在假值列表中,因此它们都 是真值
看几个常用的吧
var a = "0";
var b = [];
var c = {};
var d = "";
var e = 0;
var f = null;
var g;
Boolean( a ); // true 特别注意这个,字符串0和空字符串不一样
Boolean( b ); // true
Boolean( c ); // true
Boolean( d ); // false 和第一个比,空字符串是false
Boolean( e ); // false
Boolean( f ); // false
Boolean( g ); // false那是不是记住假值,就知道哪些是真值了?
理论上是的……
那实际上是什么?
真正掌握类型转换!
这个其实很好理解
// 字符串转换
var a = 42;
var b = String(a);
// 数字转换
var c = '3.14';
var d = Number(c);
// 布尔值转换
var e = [];
var f = Boolean(e)1️⃣字符串和数字之间的隐式转换
多的不谈了,简单来说就是,如果 + 的其中一个操作数是字符串(或者通过以上步骤可以得到字符串), 则执行字符串拼接;否则执行数字加法。
var a = '42';
var b = '0';
var c = 42;
var d = 0;
a + b; // "420" 这个地方,注意一下
c + d; // 42有个小坑,可以当做程序员饭后趣谈
console.log([] + {}); // [object object]
console.log({} + []); // ?这会是多少呢?《you don’t know JS 》中5.1.3章节是这样说的
还有一个坑常被提到(涉及强制类型转换,参见第 4 章)
[] + {}; // "[object Object]"
{} + []; // 0
表面上看 + 运算符根据第一个操作数([] 或 {})的不同会产生不同的结果,实则不然。 第一行代码中,{} 出现在 + 运算符表达式中,因此它被当作一个值(空对象)来处理。第
4 章讲过 [] 会被强制类型转换为 "",而 {} 会被强制类型转换为 "[object Object]"。
但在第二行代码中,{} 被当作一个独立的空代码块(不执行任何操作)。代码块结尾不需 要分号,所以这里不存在语法上的问题。最后 + [] 将 [] 显式强制类型转换(参见第 4 章) 为 0。
但目前的chrome浏览器控制台是这样的

对此,你怎么看?😏
{} 其实应该当成一个代码块,而不是一个 Object,当你在console.log使用的时候,{} 被当成了一个 Object

这下是不是印象更深刻了?
2️⃣ 隐式强制类型转换为布尔值
下面的情况会发生 布尔值隐式强制类型转换。
3️⃣ || 与 &&
就一句话,理解了就**,称之为“操作数选择器”
a || b;
// 大致相当于(roughly equivalent to): a ? a : b;
a && b;
// 大致相当于(roughly equivalent to): a ? b : a;只选择其中一个
常见的误区是“== 检查值是否相等,=== 检查值和类型是否相等”
正确的解释是:“== 允许在相等比较中进行强制类型转换,而 === 不允许。”
两个完全截然不同的理解方向,果然,看书还是要看权威的书好
这一段,看完后我只想总结一句,放弃 == ,拥抱 ===,其他的不谈了
高度100px,左右各宽100px,中间部分可自适应宽度

<div class="float">
<div class="left">left</div>
<div class="right">right</div>
<div class="main">浮动</div>
</div>.float {
.left {
height: 100px;
background-color: #e65;
width: 100px;
float: left;
}
.right {
height: 100px;
background-color: #ccc;
width: 100px;
float: right;
}
.main {
// 不能给宽度
height: 100px;
background-color: bisque;
margin: 0 100px;
}
}<div class="position">
<div class="left">left</div>
<div class="right">right</div>
<div class="main">绝对定位</div>
</div>.position {
margin: 10px 0;
position: relative;
.left {
height: 100px;
background-color: #e65;
width: 100px;
position: absolute;
left: 0;
}
.right {
height: 100px;
background-color: #ccc;
width: 100px;
position: absolute;
right: 0;
}
.main {
// padding或者margin都可以
margin: 0 100px;
height: 100px;
background-color: bisque;
}
}<div class="BFC">
<div class="left">left</div>
<div class="right">right</div>
<div class="main">BFC</div>
</div>.BFC {
margin: 10px 0;
.left {
height: 100px;
background-color: #e65;
width: 100px;
float: left;
}
.right {
height: 100px;
background-color: #ccc;
width: 100px;
float: right
}
.main {
height: 100px;
background-color: bisque; // 触发BFC
overflow: hidden;
}
}<div class="flexBox">
<div class="left">left</div>
<div class="main">flexBox</div>
<div class="right">right</div>
</div>.flexBox {
margin: 10px 0;
display: flex;
.left {
height: 100px;
background-color: #e65;
width: 100px;
}
.main {
flex: 1;
height: 100px;
background-color: bisque;
}
.right {
height: 100px;
background-color: #ccc;
width: 100px;
}
}<div class="tableCell">
<div class="left">left</div>
<div class="main">tableCell</div>
<div class="right">right</div>
</div>.tableCell {
margin: 10px 0; // 要设置父元素宽度
width: 100%;
display: table; // 每一个子元素都要设置display:table-cell
.left {
height: 100px;
background-color: #e65;
width: 100px;
display: table-cell;
}
.main {
height: 100px;
background-color: bisque;
display: table-cell;
width: auto
}
.right {
height: 100px;
background-color: #ccc;
width: 100px;
display: table-cell;
}
}<div class="grid">
<div class="left">left</div>
<div class="main">grid</div>
<div class="right">right</div>
</div>.grid {
margin: 10px 0; // 只需要父元素设置即可
display: grid;
grid-template-rows: 100px;
grid-template-columns: 100px auto 100px;
.left {
height: 100px;
background-color: #e65;
width: 100px;
}
.main {
height: 100px;
background-color: bisque;
width: auto
}
.right {
height: 100px;
background-color: #ccc;
width: 100px;
}
}<div class="doubleFly">
<div class="container">
<div class="main">doubleFly</div>
</div>
<div class="left">left</div>
<div class="right">right</div>
</div>.doubleFly {
margin: 10px 0; // 此处 ,缩进了100px的高度
margin-bottom: 120px;
.container {
width: 100%; // 全都是浮动
float: left;
.main {
// 空出两边间隔
margin: 0 100px;
height: 100px;
background-color: bisque;
}
}
.left {
float: left; // 关键地方,这个100是整个父元素的宽度
margin-left: -100%;
height: 100px;
background-color: #e65;
width: 100px;
}
.right {
float: right; // 关键地方
margin-left: -100px;
height: 100px;
background-color: #ccc;
width: 100px;
}
}<div class="hollyCup">
<div class="main">hollyCup</div>
<div class="left">left</div>
<div class="right">right</div>
</div>.hollyCup {
// 父元素也需要两边空出100px
margin: 10px 100px;
.main {
float: left;
width: 100%;
height: 100px;
background-color: bisque;
}
.left {
float: left;
margin-left: -100%;
position: relative;
left: -100px;
height: 100px;
background-color: #e65;
width: 100px;
}
.right {
float: left;
margin-left: -100px;
position: relative;
right: -100px;
height: 100px;
background-color: #ccc;
width: 100px;
}
}这五种方案各自的优缺点?
浮动:脱离文档流,需要清除浮动;但兼容性比较好
绝对定位:快;但是需要处理下面元素的位置
Flex:目前比较完美的方案,特别是移动端
表格布局:有历史上的问题(不深究),会同时增高
网格布局:新技术,比较潮一点(这能展示学习能力)
如果高度也要考虑呢,或者去掉高度呢?
目前只有flex、table布局是自适应的
这五种方案的兼容性,目前业务中的最优解?
function Foo() {
getName = function () { alert (1); };
return this;
}
Foo.getName = function () { alert (2);};
Foo.prototype.getName = function () { alert (3);};
var getName = function () { alert (4);};
function getName() { alert (5);}
//请写出以下输出结果:
Foo.getName();
getName();
Foo().getName();
getName();
new Foo.getName();
new Foo().getName();
new new Foo().getName();function Foo() {
getName = function () { alert (1); };
return this;
}
// 为Foo创建了一个叫getName的静态属性存储了一个匿名函数
Foo.getName = function () { alert (2);};
// 为Foo的原型对象新创建了一个叫getName的匿名函数
Foo.prototype.getName = function () { alert (3);};
// 通过函数变量表达式创建了一个getName的函数
var getName = function () { alert (4);};
// 通过函数声明一个getName函数,注意提升,所以getName最后应该是上一行的4
function getName() { alert (5);}//提升
//请写出以下输出结果:
Foo.getName(); //2 Foo上面的静态属性
getName(); // 4 当前上文作用域内的叫getName的函数,所以跟1 2 3都没什么关系,但函数声明被提升了 所以函数表达式在后
Foo().getName(); // 1
// Foo函数的第一句 getName = function () { alert (1); }; 是一句函数赋值语句,注意它没有var声明
// 所以先向当前Foo函数作用域内寻找getName变量,没有。再向当前函数作用域上层,找到了,这时候是4,然后赋值为1
// 此处实际上是将外层作用域内的getName函数修改了
// 此处若依然没有找到会一直向上查找到window对象,若window对象中也没有getName属性,就在window对象中创建一个getName变量
// 此时,Foo返回了this,如果函数独立调用,那么严格模式下该函数内部的this,则指向undefined,现在是非严格模式,所以指向window
// Foo函数返回的是window对象,相当于执行 window.getName() ,而window中的getName已经被修改为alert(1),
getName(); // 与上一问相同,已经被改为1了
new Foo.getName(); //2
// 这里考察运算符优先级
// 圆括号 > (成员访问.号 > new) > 函数调用 > 其他(具体再看)
// 这里成员访问.号优先级高于new 相当于 new (Foo.getName)() 相当于将getName()函数当做构造函数,这个构造函数现在是foo的静态属性2
new Foo().getName(); //3
// 相当于 (new Foo()).getName()
// 这里构造函数Foo返回了实例化的对象,然后去原型对象中找到的getName, (Foo.prototype.getName = function () { alert (3);};)
new new Foo().getName(); // 3
// new ((new Foo()).getName)();
// 先初始化Foo的实例化对象,然后将其原型上的getName函数作为构造函数再次new。构造函数可以有返回值也可以没有
如果返回this,而this在构造函数中本来就代表当前实例化对象,遂最终Foo函数返回实例化对象
最基础的原则就是见到yield就暂停,next()就继续到下一个yield……以此知道函数执行完毕。
先不上理论,直接看一段代码,这里的step()是一个辅助函数,用来控制迭代器,替代手动next()
var a = 1;
var b = 2;
function* foo() {
a++;
yield;
b = b * a;
a = (yield b) + 3;
}
function* bar() {
b--;
yield;
a = (yield 8) + b;
b = a * (yield 2);
}
function step(gen) {
var it = gen();
var last;
return function() {
// 不管yield出来的是什么,下一次都把它原样传回去!
last = it.next(last).value;
};
}
a = 1;
b = 2;
var s1 = step(foo);
var s2 = step(bar);yield和next()调用有一个不匹配,就是说,想要完整跑完一个生成器函数,next()调用总是比yield的数量多一次
为什么会有这个不匹配?
因为第一个 next(..) 总是启动一个生成器,并运行到第一个 yield 处。不过,是第二个 next(..) 调用完成第一个被暂停的 yield 表达式,第三个 next(..) 调用完成第二个 yield, 以此类推。
所以上面的代码中,foo有两个yield,bar有三个yield
所以接下来要跑三次s1(),四次s2()
我们在控制台看每一步的输出,一步一步来分析

分析到这里,对generator的基础工作原理应该就有了大概的认知了。
如果想加深一点理解(皮一下),可以随意调换一下s1和s2的执行顺序,总之就是三个s1和四个s2,对于理解多个生成器如何在共享的作用域上并 发运行也有指导意义。
这一段,我们来理解一下生成器与异步编程之间的问题,最直接的就是网络请求了
let data = ajax(url);
console.log(data)这段代码,大家都知道不能正常工作吧,data是underfined
ajax是一个异步操作,它并没有停下来等到拿到数据之后再赋值给data
而是在发出请求之后,直接就执行了下一句console
既然知道了问题核心在于“没有停下来”
那刚好生成器又有“yield”停下来这个操作,那么二者是不是刚好合拍了呢
看一段代码
function foo() {
ajax(url, (err, data) => {
if (err) {
// 向*main()抛出一个错误 it.throw( err );
} else {
// 用收到的data恢复*main()
it.next(data);
}
});
}
function* main() {
try {
let data = yield foo();
console.log(data);
} catch (err) {
console.error(err);
}
}这段代码使用了生成器,其实跟上一段代码干的是一样的事情,虽然更长更复杂,但实际上更好用,具体原因慢慢分析
两段代码的核心区别在于生成器中使用了yield
在yield foo()的时候,调用了foo(),没有返回值(underfined),所以发出了一个ajax请求,虽然依然是yield underfined,但是没关系,因为这段代码不依赖yield的值来做什么事情,大不了就打印underfined嘛对不对
这里并不是在消息传递的意义上使用 yield,而只是将其用于流程控制实现暂停 / 阻塞。实 际上,它还是会有消息传递,但只是生成器恢复运行之后的单向消息传递。
所以,生成器在 yield 处暂停,本质上是在提出一个问题:“我应该返回什么值来赋给变量 data ?”谁来回答这个问题呢?
看foo,如果ajax请求成功,调用
it.next( data )会用响应数据恢复生成器,意味着我们暂停的 yield 表达式直接接收到了这个值。然后 随着生成器代码继续运行,这个值被赋给局部变量 data
在生成器内部有了看似完全同步的代码
(除了 yield 关键字本身),但隐藏在背后的是,在 foo(..) 内的运行可以完全异步
这一部分对于理解生成器与异步编程之间扎下了最核心的内容,万望深刻理解为什么
接下来来点高级货吧,总不能一直停留在理论上
request是假设封装好的基于Promise的实现方法
run也是假设封装好的能实现重复迭代的驱动Promise链的方法
function *foo() {
let r1 = yield request(url1);
let r2 = yield request(url2);
let r3 = yield request(`${url3}/${r1}/${r2}`);
console.log(r3)
}
run(foo)这段代码里,r3是依赖于r1和r2的,同时r1和r2是串行的,但这两个请求是相对独立的,那是不是应该考虑并发执行呢?
但yield 只是代码中一个单独 的暂停点,并不可能同时在两个点上暂停
这样试一下
function *foo() {
let p1 = request(url1);
let p2 = request(url2);
let r1 = yield p1;
let r2 = yield p2;
let r3 = yield request(`${url3}/${r1}/${r2}`);
console.log(r3)
}
run(foo)看一下yield的位置,p1和p2是并发同时执行的用于 Ajax 请求的 promise,哪一个先完成都无所谓,因为 promise 会按照需要 在决议状态保持任意长时间
然后使用接下来的两个 yield 语句等待并取得 promise 的决议(分别写入 r1 和 r2)。
如果p1先决议,那么yield p1就会先恢复执行,然后等待yield p2恢复。
如果p2先决 议,它就会耐心保持其决议值等待请求,但是 yield p1 将会先等待,直到 p1 决议。
不管哪种情况,p1 和 p2 都会并发执行,无论完成顺序如何,两者都要全部完成,然后才 会发出 r3 = yield request..Ajax 请求。
这种流程控制模型和Promise.all([ .. ]) 工具实现的 gate 模式相同
function *foo() {
let rs = yield Promise.all([
request(url1),
request(url2)
]);
let r1 = rs[0];
let r2 = rs[1];
let r3 = yield request(`${url3}/${r1}/${r2}`);
console.log(r3)
}
run(foo)到目前位置,Promise都是直接暴露在生成器内部的,但生成器实现异步的要点在于:创建简单、顺序、看似同步的代码,将异步的 细节尽可能隐藏起来。
能不能考虑一下把多余的信息都藏起来,特别是看起来比较复杂的Promise代码呢?
function bar(url1, url2) {
return Promise.all([request(url1), request(url2)]);
}
function* foo() {
// 隐藏bar(..)内部基于Promise的并发细节
let rs = yield bar(url1, url2);
let r1 = rs[0];
let r2 = rs[1];
let r3 = yield request(`${url3}/${r1}/${r2}`);
console.log(r3);
}
run(foo);把Promise的实现细节都封装在bar里面,对bar的要求就是给我们一下rs结果而已,我们也不需要关系底层是用什么来实现的
异步,实际上是把Promise,作为一个实现细节看待。
具体到实际生产中,一系列的异步流程控制有可能就是下面的实现方式
function bar() {
Promise.all([
bax(...).then(...),
Promise.race([...])
])
.then(...)
}这些代码可能非常复杂,如果把实现直接放到生成器内部的话,那几乎就失去了使用生成器的理由了
好好记一下这句话:创建简单、顺序、看似同步的代码,将异步的 细节尽可能隐藏起来。
网上关于缓存的文章非常多,但大都比较片面,或者只对某块进行了深入,没有把它们联系起来,本着系统学习的态度,笔者进行了整理,写成一个小系列,方便自己也方便他人共同学习,有写的不对的地方欢迎指正。
缓存(一)——缓存总览:从性能优化的角度看缓存
缓存(二)——浏览器缓存机制:强缓存、协商缓存
缓存(三)——数据存储:cookie、Storage、indexedDB
缓存(四)——离线应用缓存:App Cache => Manifest
缓存(五)——离线应用缓存:Service Worker(还没写,先占坑)
请注意:该特性已经从 Web 标准中删除,本文只是作为了解所用
Manifest 是 H5提供的一种应用缓存机制, 基于它web应用可以实现离线访问(offline cache)
浏览器还提供了应用缓存的API:applicationCache
manifest是一个后缀名为minifest的文件,在文件中定义那些需要缓存的文件,支持manifest的浏览器将会按照manifest文件的规则,像文件保存在本地,从而在没有网络链接的情况下,也能访问页面。
当第一次正确配置app cache后,再次访问该应用时,浏览器会首先检查manifest文件是否有变动,如果有变动就会把相应的变得更新下来,同时改变浏览器里面的app cache,如果没有变动,就会直接把app cache的资源返回,基本流程如下:

在html标签中指定manifest文件, 便表示该网页使用manifest进行离线缓存.
该网页内需要缓存的文件列表需要在 demo.appcache 文本文件中指定.
<!DOCTYPE HTML>
<html manifest="demo.appcache">
...
</html>首行必须以CACHE MANIFEST开头,标准的三段式
// 需要缓存的文件,无论是否有网络连接,都从缓存读取
CACHE MANIFEST
/theme.css
/logo.gif
/main.js
// 文件 "login.asp" 永远不会被缓存,且离线时是不可用的
NETWORK:
login.asp
// 如果无法建立因特网连接,则用 "offline.html" 替代 /html5/ 目录中的所有文件
FALLBACK:
/html5/ /404.html1、更新manifest文件
2、通过javascript操作
window.applicationCache.update();3、清除浏览器缓存
感谢您耐心看到这里,希望有所收获!
如果不是很忙的话,麻烦点个star⭐【Github博客传送门】,举手之劳,却是对作者莫大的鼓励。
我在学习过程中喜欢做记录,分享的是自己在前端之路上的一些积累和思考,希望能跟大家一起交流与进步,更多文章请看【amandakelake的Github博客】
#前端/Javascript/个人理解总结
当前栈顶的执行上下文包括了:变量对象、作用域链、this

当一个函数被激活时,一个新的执行上下文就会被创建(这个执行上下文在栈顶),一个执行上下文的生命周期分为两个阶段
1、创建阶段:在这个阶段中,执行上下文会分别创建变量对象,建立作用域链,以及确定this的指向
2、代码执行阶段: 变量赋值,函数引用、以及执行其他代码

函数名的属性已经存在,那么该属性将会被新的引用所覆盖。这里要清楚理解,函数声明才会被提升,函数表达式不会被提升,函数表达式就相当于变量声明直接跳过,原属性值不会被修改。也就是同一个执行上下文中,变量对象是唯一的,但有可能在下个阶段(代码执行阶段)被修改赋值VO = {
arguments: {...},
foo: <foo reference>, //这个地方,优先函数声明,碰到变量foo不会被覆盖,因为var声明的变量当遇到同名的属性时,会跳过而不会覆盖
bar: underfined //虽然bar是函数表达式,但也只当做变量来处理
}VO => AO
VO = {
arguments: {...},
foo: 'Hello', //要理解这里为什么是变量,而不再是函数了,因为在执行阶段会按顺序进行赋值或者引用
bar: <bar reference>,
this: Window
}预编辑
function test() {
//创建变量对象阶段
var foo;
//一等公民函数,优先声明,并指向函数的引用地址
// foo => function foo() {
// return 'hello';
// }
var bar : underfined
// 代码执行阶段:变量赋值,函数引用, 全部按照顺序来
console.log(foo); //函数引用
console.log(bar); // underfined
// 这里按顺序执行到这里,重新给变量foo赋值
foo = 'Hello';
console.log(foo); // 'Hello'
bar = function () {
return 'world';
}
}再看一个例子
function testOrder(arg) {
console.log(arg); // arg是形参,不会被重新定义
console.log(a); // 因为函数声明比变量声明优先级高,所以这里a是函数
var arg = 'hello'; // var arg;变量声明被忽略, arg = 'hello'被执行
var a = 10; // var a;被忽视; a = 10被执行,a变成number
function a() {
console.log('fun');
} // 被提升到作用域顶部
console.log(a); // 输出10
console.log(arg); // 输出hello
};
testOrder('hi');输出
hi
function a() {
console.log('fun');
}
10
hello var t = function() {
var n = 99;
var t2 = function() {
n++
console.log(n)
}
return t2;
};
var a1 = t();
var a2 = t();
//这里理解的关键是: n 在 a1() 和 a2() 并不是公用的
a1(); // 100
a1(); // 101
a2(); // 100
a2(); // 101var nAdd;
var t = function() {
var n = 99;
nAdd = function() {
n++;
}
var t2 = function() {
console.log(n)
}
return t2;
};
//var a1 = t()的时候,变量 nAdd 被赋值为一个函数 ,这个函数是function (){n++},命名为fn1吧
var a1 = t();
//变量 nAdd 又被重写了,这个函数跟以前的函数长得一模一样,也是function (){n++},但是这已经是一个新的函数了,我们就命名为 fn2
var a2 = t();
//所以这时候执行的事fn2
nAdd();
a1(); //99
a2(); //100先给出最终版,后面会解析难点
function newF() {
// 创建一个新的对象
let obj = {};
// 取出第一个参数,该参数就是我们将会传入的构造函数,比如在调用new(P)的时候,Constructor就是P本身
// arguments会被shift去除第一个参数,剩余的就是构造器P的参数
let Constructor = [].shift.call(arguments);
// 将obj的原型指向构造函数,此时obj可以访问构造函数原型中的属性
obj.__proto__ = Constructor.prototype;
// 改变构造函数的this的指向,使其指向obj, 此时obj也可以访问构造函数中的属性了
let result = Constructor.apply(obj, arguments);
// 确保 new 出来的是个对象 返回的值是什么就return什么
return typeof result === 'object' ? result : obj
}其实这短短的几行代码里面,浓缩了几个知识点,请先自行查阅
这两行代码,很多同学会在这里懵逼
let Constructor = [].shift.call(arguments);
let result = Constructor.apply(obj, arguments);
复制如下代码到控制台打印一下
function P(firstName, lastName) {
this.age = 10;
this.getName = function() {
return `${firstName} ${lastName}`;
};
}
function newF() {
let obj = new Object();
console.log('刚开始时的arguments', arguments);
let Constructor = [].shift.call(arguments);
console.log('被shift后的arguments', arguments);
console.log('- - - - -- - - -- -- - - ');
console.log('Constructor', Constructor);
console.log('- - - - -- - - -- -- - - ');
obj.__proto__ = Constructor.prototype;
let result = Constructor.apply(obj, arguments);
console.log('绑定this时的arguments', arguments)
}
let p = newF(P, 'amanda', 'kelake');
如图,刚开始时传入的arguments代表的是传入newF的参数,第一个参数arguments[0]自然就是传入的构造器P
let Constructor = [].shift.call(arguments);在shift后(直接从数组里面删除元素),构造器P被拿出,arguments这时候代表的就是构造器P所需要的传入参数firstName, lastName
然后把构造器P的this指向将要return的新实例对象,并把剩余参数传入
let result = Constructor.apply(obj, arguments);function P(firstName, lastName) {
this.age = 10;
this.getName = function() {
return `${firstName} ${lastName}`;
};
}
function newF() {
let obj = new Object();
let Constructor = [].shift.call(arguments);
obj.__proto__ = Constructor.prototype;
let result = Constructor.apply(obj, arguments);
return typeof result === 'object' ? result : obj
}
let p = newF(P, 'amanda', 'kelake');
p.getName();
// "amanda kelake"感谢您耐心看到这里,希望有所收获!
如果不是很忙的话,麻烦点个star⭐【Github博客传送门】,举手之劳,却是对作者莫大的鼓励。
我在学习过程中喜欢做记录,分享的是自己在前端之路上的一些积累和思考,希望能跟大家一起交流与进步,更多文章请看【amandakelake的Github博客】
初次看到这张图,直接被笑哭 😂 炒鸡形象有木有

map:让数组通过某种计算产生一个新数组,返回修改后的数组
forEach:让数组中的每一项做一件事,返回underfined
filter:筛选出数组中符合条件的项,组成新数组,过滤后的数组
reduce:让数组中的前项和后项做某种计算,并累计最终值,返回值
forEach用于看,map用于改,filter用于删,reduce用于统计
every:检测数组中的每一项是否符合条件,全部满足则返回true
Some:检测数组中是否有某些项符合条件,只要有一个满足则返回true
MDN -reduce
arr.reduce(callback[, initialValue])
reduce(callback, initialValue)会传入两个变量。回调函数callback和初始值initialValue。
官方写法如下
callback 有四个参数:prev、next、index、array
一般来讲prev是从数组中第一个元素开始的,next是第二个元素。
但是当你传入初始值initialValue后,第一个prev将是initivalValue,next将是数组中的第一个元素。
以下例子都是MDN上面的,我稍微改造成了函数形式,可以直接用
function countSum(arr) {
return arr.reduce((a, b) => {
return a + b;
}, 0);
}
var result = countSum([1, 3, 5, 6]);
console.log(result);
// 15function combineArr(doubleDimensionArr) {
return doubleDimensionArr.reduce((prev, next) => {
return prev.concat(next);
}, []);
}
var arr = [[0, 1], [2, 3], [4, 5]];
var result = combineArr(arr);
console.log(result);
// [0, 1, 2, 3, 4, 5]function countedNames(arr) {
return arr.reduce((allnames, name) => {
// 如果指定的属性在指定的对象或其原型链中,则in 运算符返回true
if (name in allnames) {
allnames[name]++;
} else {
allnames[name] = 1;
}
return allnames;
}, {});
}
var names = ['Alice', 'Bob', 'Tiff', 'Bruce', 'Alice'];
var result = countedNames(names);
console.log(result);
// {Alice: 2, Bob: 1, Tiff: 1, Bruce: 1}function combineProperty(arr, property) {
return arr.reduce((prev, next) => {
return [...prev, ...next[property]];
}, []);
}
var friends = [
{
name: 'Anna',
books: ['Bible', 'Harry Potter'],
age: 21
},
{
name: 'Bob',
books: ['War and peace', 'Romeo and Juliet'],
age: 26
},
{
name: 'Alice',
books: ['The Lord of the Rings', 'The Shining'],
age: 18
}
];
var result = combineProperty(friends, 'books');
console.log(result);
// ["Bible", "Harry Potter", "War and peace", "Romeo and Juliet", "The Lord of the Rings", "The Shining"]function initArr(arr) {
// sort()是不稳定排序,默认排序顺序是根据字符串Unicode码点,如要按照数值大小,则需要compareFunction
return arr.sort((a, b) => a - b).reduce((init, currentValue) => {
// 判断新数组的最后一个值是否等于正在判断的当前值currentValue
if (init.length === 0 || init[init.length - 1] !== currentValue) {
init.push(currentValue);
}
return init;
}, []);
}
var arr = [1, 2, 10, 20, 3, 5, 4, 5, 3, 4, 4, 4, 4];
var result = initArr(arr);
console.log(result);
// [1, 2, 3, 4, 5, 10, 20]call 和 apply 都是为了改变某个函数运行时的上下文(context)而存在的,换句话说,就是为了改变函数体内部 this 的指向
先看个常用例子
var foo = {
value: 1
};
function bar() {
console.log(this.value);
}
bar.call(foo); // 1试想下,是不是可以先把bar变成foo对象的属性,执行完后再删除它呢?
var foo = {
value: 1,
bar: function() {
console.log(this.value);
}
};
foo.bar(); // 1
delete foo.bar;总结一下步骤
Function.prototype.myCall = function(context) {
// 取得传入的对象(执行上下文),比如上文的foo对象
// 不传第一个参数,默认是window,
var context = context || window;
// 给context添加一个属性,这时的this指向调用call的函数,比如上文的bar
context.fn = this;
// 通过展开运算符和解构赋值取出context后面的参数
var args = [...arguments].slice(1);
// 执行函数
var result = context.fn(...args);
// 删除函数
delete context.fn;
return result;
};思路跟call一样,只是在处理参数的时候有点不一样
Function.prototype.myApply = function(context) {
var context = context || window;
context.fn = this;
var result;
// 判断第二个参数是否存在,是一个数组
// 如果存在,则需要展开第二个参数
if (arguments[1]) {
result = context.fn(...arguments[1]);
} else {
result = context.fn();
}
delete context.fn;
return result;
}思路和作用基本一致,区别在于返回一个函数,并且可以通过bind实现柯里化
Function.prototype.myBind = function(context) {
if (typeof this !== 'function') {
throw new TypeError('Error');
}
var _this = this;
var args = [...arguments].slice(1);
// 返回函数
return function Fn() {
// bind有个特点 一个绑定函数也能使用new操作符创建对象
if (this instanceof Fn) {
return new _this(args, ...arguments);
}
return _this.apply(context, args.concat(arguments));
}
}var arr1 = [1, 2, { id: 1, id: 2 }, [1, 2]];
var arr2 = ['ds', 1, 9, { name: 'jack' }];
// var arr = arr1.concat(arr2);
Array.prototype.push.apply(arr1,arr2)
var numbers = [ 5, 458 , 120 , -215 ];
var maxInNumbers = Math .max .apply (Math , numbers), //458
maxInNumbers = Math. max. call( Math, 5, 458 , 120 , -215 ); //458
function isArray(obj) {
return Object.prototype.toString.call(obj) == '[object Array]'
}
isArray([]) //true
var toString = Object.prototype.toString;
toString.call(new Date); // [object Date]
toString.call(new String); // [object String]
toString.call(Math); // [object Math]
//Since JavaScript 1.8.5
toString.call(undefined); // [object Undefined]
toString.call(null); // [object Null]
首先,何为类数组?
1、拥有length属性,其它属性(索引)为非负整数(对象中的索引会被当做字符串来处理,这里你可以当做是个非负整数串来理解)
2、不具有数组所具有的方法
常见类数组
1、arguments
2、DOM 对象列表(比如通过 document.getElementsByTags 得到的列表),jQuery 对象(比如 $("div"))
通过call/apply,使用数组原生方法操作类数组
先定义一个类数组
var anArrayLikeObj = {0:"Martin", 1:78, 2:67, 3:["Letta", "Marieta", "Pauline"], length:4 };
操作
var newArray = Array.prototype.slice.call(anArrayLikeObj, 0);
console.log(newArray); // ["Martin", 78, 67, Array[3]]
// Search for "Martin" in the array-like object
console.log(Array.prototype.indexOf.call(anArrayLikeObj, "Martin") === -1 ? false : true); // true
// Try using an Array method without the call () or apply ()
console.log(anArrayLikeObj.indexOf("Martin") === -1 ? false : true); // Error: Object has no method 'indexOf'
// Reverse the object:
console.log(Array.prototype.reverse.call(anArrayLikeObj));
// {0: Array[3], 1: 67, 2: 78, 3: "Martin", length: 4}
// Sweet. We can pop too:
console.log(Array.prototype.pop.call(anArrayLikeObj));
console.log(anArrayLikeObj); // {0: Array[3], 1: 67, 2: 78, length: 3}
// What about push?
console.log(Array.prototype.push.call(anArrayLikeObj, "Jackie"));
console.log(anArrayLikeObj); // {0: Array[3], 1: 67, 2: 78, 3: "Jackie", length: 4}slice:提取字符串的某个部分,并以新的字符串返回被提取的部分
function transitionTo(name) {
var args = Array.prototype.slice.call(arguments, 1, 3);
return args;
}
transitionTo("contact", "Today", "20","hh","ghh");
//["Today", "20"]感谢您耐心看到这里,希望有所收获!
如果不是很忙的话,麻烦右上角点个star⭐,举手之劳,却是对作者莫大的鼓励。
我在学习过程中喜欢做记录,分享的是自己在前端之路上的一些积累和思考,希望能跟大家一起交流与进步,更多文章请看【amandakelake的Github博客】
基础定义和API方面,这里就不说了,请自行学习
前面的理论部分基于《你不知道的JS》中卷第二部分第三章,可以结合前人的一些博客认真理解一下。 后面的代码实例非常有助于理解,并且我都做了注释,有基础的同学可以跳过理论部分直接参阅。
1、顺序不确定性
回调表达异步流程是非线性、非顺序的
2、可信任性
回调会受到控制反转的影响,因为回调暗中把控制权交给了第三方(通常是不受控制的第三方工具)来调用代码中的continuation
先直接在控制台打印看一下它是什么

展开后可以看到 Promise构造器上定义了resolve和reject方法,then()方法定义在其原型上。
这就解释了为什么下面两种写法都可以了
Promise.resolve().then(() => {
...
}) let p = new Promise((resolve, reject) => {
...
resolve(someValue)
})
p.then(() => {
...
})Promise 所说的异步执行,只是将 Promise 构造函数中 resolve,reject 方法和注册的 callback 转化为 eventLoop的 microtask/Promise Job,并放到 Event Loop 队列中等待执行,也就是 Javascript 单线程中的“异步执行”
根据规范,microtask 存在的意义是:在当前 task 执行完,准备进行 I/O,repaint,redraw 等原生操作之前,需要执行一些低延迟的异步操作,使得浏览器渲染和原生运算变得更加流畅。这里的低延迟异步操作就是 microtask。原生的 setTimeout 就算是将延迟设置为 0 也会有 4 ms 的延迟,会将一个完整的 task 放进队列延迟执行,而且每个 task 之间会进行渲染等原生操作。假如每执行一个异步操作都要重新生成一个 task,将提高宿主平台的负担和响应时间。所以,需要有一个概念,在进行下一个 task 之前,将当前 task 生成的低延迟的,与下一个 task 无关的异步操作执行完,这就是 microtask。
new Promise((resolve) => {
console.log('a')
resolve('b')
console.log('c')
}).then((data) => {
console.log(data)
})
// a, c, b构造函数中的输出执行是同步的,输出 a, 执行 resolve 函数,将 Promise 对象状态置为 resolved,输出 c。
同时注册这个 Promise 对象的回调 then 函数。整个脚本执行完,stack 清空。
event loop 检查到 stack 为空,再检查 microtask 队列中是否有任务,发现了 Promise 对象的 then 回调函数产生的 microtask,推入 stack,执行。输出 b,event loop的列队为空,stack 为空,脚本执行完毕。
识别 Promise(或者行为类似于 Promise 的东西)就是定义某种称为 thenable 的东 西,将其定义为任何具有 then(..) 方法的对象和函数。我们认为,任何这样的值就是 Promise 一致的 thenable
根据一个值的形态(具有哪些属性)对这个值的类型做出一些假定。这种类型检查(type check)一般用术语鸭子类型(duck typing)来表示
function checkThenable(p) {
if (p !== null && ( typeof p === 'object' || typeof p === 'function') && typeof p.then === 'function') {
// 假设这是一个thenable
return true
} else {
// 不是thenable
return false
}
}第一个参数是Promise执行成功时的回调,第二个参数是Promise执行失败时的回调。两个函数只会有一个被调用,函数的返回值将被用作创建then返回的Promise对象。
1、return 一个同步的值 ,或者 undefined(当没有返回一个有效值时,默认返回undefined),then方法将返回一个resolved状态的Promise对象,Promise对象的值就是这个返回值。
2、return 另一个 Promise,then方法将根据这个Promise的状态和值创建一个新的Promise对象返回。
3、throw 一个同步异常,then方法将返回一个rejected状态的Promise, 值是该异常。
太啰嗦了,总结一下then()方法的看家本领
Promise/A+规范中解释:实践中要确保onFulfilled 和 onRejected 方法异步执行,且应该在 then 方法被调用的那一轮事件循环之后的新执行栈中执行。这个事件队列可以采用宏任务 macro-task机制或微任务 micro-task机制来实现
Promise的两个固有行为:
1、每次对 Promise 调用 then(..),它都会创建并返回一个新的 Promise,我们可以将其 链接起来;
2、不管从 then(..) 调用的完成回调(第一个参数)返回的值是什么,它都会被自动设置 为被链接 Promise(第一点中的)的完成。
使 Promise 序列真正能够在每一步有异步能力的关键是:Promise. resolve(..) 会直接返回接收到的真正 Promise,或展开接收到的 thenable 值,并在持续展 开 thenable 的同时递归地前进。
尝试去理解一下下面这段代码
let p = Promise.resolve(1);
p
.then(v => {
console.log(v);
// 创建一个promise并返回
return new Promise((resolve, reject) => {
// 引入异步,一样正常工作
setTimeout(() => {
resolve(v * 2);
}, 4);
});
})
.then(v => {
// 猜猜拿到了多少?
console.log(v);
});会发现:不管我们想要多少个异步步 骤,每一步都能够根据需要等待下一步(或者不等!)
一个错误/异常是基于每个Promise的,意味着在链条的任意一点捕获这些错误是可能的,而且这些捕获操作在那一点上将链条“重置”,使它回到正常的操作上来
let p = new Promise((resolve, reject) => {
reject('error')
});
let p2 = p.then(() => {
// 永远到达不了这里
console.log('这句话不会出现')
})再看一段代码
let p = Promise.resolve(1);
p.then((v) => {
console.log(v * 2);
foo();//这一步,underfined出错
// 再也到不了这里了
return Promise.resolve(3);
}).then((v) => {
console.log('到不了这里',v)
},(err) => {
console.log('错误来这了',err);
return 4
}).then((v) => {
console.log(v)
})第 2 步出错后,第 3 步的拒绝处理函数会捕捉到这个错误。拒绝处理函数的返回值(这段代码中是4),如果有的话,会用来完成交给下一个步骤(第 4 步)的 promise,这样,这 个链现在就回到了完成状态。

注意这句话,解释了为什么最后会出现4,这里要好好理解透彻
拒绝处理函数的返回值(这段代码中是 3),如果有的话,会用来完成交给下一个步骤(第 4 步)的 promise
总结起来,Promise的步骤
• 调用 Promise 的 then(..) 会自动创建一个新的 Promise 从调用返回。
• 在完成或拒绝处理函数内部,如果返回一个值或抛出一个异常,新返回的可链接的)Promise 就相应地决议。
• 如果完成或拒绝处理函数返回一个 Promise,它将会被展开,这样一来,不管它的决议值是什么,都会成为当前 then(..) 返回的链接 Promise 的决议值。
另外,记住这条结论,对于理解后面的例子有帮助
当使用then(resolveHandler, rejectHandler),rejectHandler不会捕获在resolveHandler中抛出的错误。
个人习惯是从不使用then方法的第二个参数,转而使用catch()方法
但后面的例子是为了更清晰的讲述promise,所以几乎都用了第二个参数
下面这段代码先自己想一下,再去控制台打印
Promise.resolve(1).then(Promise.resolve(2)).then((v) => {
console.log(v)
})
Promise.resolve(1).then(return Promise.resolve(2)).then((v) => {
console.log(v)
})
Promise.resolve(1).then(null).then((v) => {
console.log(v)
})
Promise.resolve(1).then(return 2).then((v) => {
console.log(v)
})
Promise.resolve(1).then(() => {
return 2
}).then((v) => {
console.log(v)
})答案是
1;
Uncaught SyntaxError: Unexpected token return;
1
Uncaught SyntaxError: Unexpected token return;
2
当then()受非函数的参数时,会解释为then(null),这就导致前一个Promise的结果穿透到下面一个Promise。
所以要提醒你自己:永远给then()传递一个函数参数。
1、顺序错误处理
Promise 链中的错误很容易被 无意中默默忽略掉
2、单一值
Promise 只能有一个完成值或一个拒绝理由
Promise 进行的动作要多一些,这自然意味着它也会稍慢一些
更多的工作,更多的保护。这些意味着 Promise 与不可信任的裸回调相比会更慢一些
Promise 使所有一切都成为异步的了,即有一些立即(同步)完 成的步骤仍然会延迟到任务的下一步。这意味着一个 Promise 任务序列可能 比完全通过回调连接的同样的任务序列运行得稍慢一点
Promise 稍慢一些,但是作为交换,你得到的是大量内建的可信任性、对 Zalgo 的避免以及 可组合性
var p1 = new Promise(function(resolve,reject){
resolve(1);
});
var p2 = new Promise(function(resolve,reject){
setTimeout(function(){
resolve(2);
}, 500);
});
var p3 = new Promise(function(resolve,reject){
setTimeout(function(){
reject(3);
}, 500);
});
// 直接返回1
console.log(p1);
// 由于加入了异步,而且是事件循环中的宏任务,所以暂时处于pending状态,underfined
console.log(p2);
// 同理,pending状态
console.log(p3);
// 直接加到下一个事件循环,暂时没输出,最后会输出resolve 2
setTimeout(function(){
console.log(p2);
}, 1000);
// 同理,在下一个事件循环,最后会输出reject 3
setTimeout(function(){
console.log(p3);
}, 1000);
// promise属于事件循环中的微任务,所以要比上两个setTimeout输出的快,1
p1.then(function(value){
console.log(value);
});
// 同理,2
p2.then(function(value){
console.log(value);
});
// 这里注意是catch,所以输出3
p3.catch(function(err){
console.log(err);
});
var p = new Promise(function(resolve, reject){
resolve(1);
});
p.then(function(value){ //第一个then
console.log(value); // 1
return value*2;
}).then(function(value){ //第二个then
console.log(value); // 2
}).then(function(value){ //第三个then
console.log(value); // underfined
return Promise.resolve('resolve');
}).then(function(value){ //第四个then
console.log(value); // 'resolve'
return Promise.reject('reject');
}).then(function(value){ //第五个then
console.log('resolve: '+ value); // 不到这里,没有值
}, function(err){
console.log('reject: ' + err); // 'reject'
})上面说的 then()接收两个函数作为参数,返回值有三种情况,可以返回上面看看
let p1 = new Promise((resolve, reject) => {
foo();
resolve(1)
})
p1.then((v) => {
console.log('1不会到这里')
},(err) => {
console.log('p1的第一次错误来了这里',err)
}).then((v) => {
console.log('p1第二次,在这里拿到了underfined',v)
},(err) => {
console.log('第二次,没有错误,这里不会出现',err)
})
let p2 = new Promise((resolve,reject) => {
resolve(2);
})
p2.then((v) => {
console.log('p2第一次的值2来这里了',2);
foo()
},(err) => {
console.log('p2这里不会拿到第一次的错误',err)
}).then((v) => {
console.log('p2上面第一次有错误,这里不会有值',v)
},(err) => {
console.log('这里拿到了p2上一次的错误',err);
return '即使错误,也能继续传值'
}).then((v) => {
console.log('到这里应该很清晰了吧',v)
},(err) => {
console.log('这里已经没有错误了',err)
})Promise中的异常由then参数中第二个回调函数(Promise执行失败的回调)处理,异常信息将作为Promise的值。异常一旦得到处理,then返回的后续Promise对象将恢复正常,并会被Promise执行成功的回调函数处理。
需要注意p1、p2 多级then的回调函数是交替执行的 ,这正是由Promise then回调的异步性决定的。
var p1 = new Promise(function(resolve, reject){
resolve(Promise.resolve('resolve'));
});
p1.then(
function fulfilled(value){
console.log('fulfilled: ' + value);
},
function rejected(err){
console.log('rejected: ' + err);
}
);这段毫无疑问,resolve直通车
var p2 = new Promise(function(resolve, reject){
resolve(Promise.reject('reject'));
});
p2.then(
function fulfilled(value){
console.log('fulfilled: ' + value);
},
function rejected(err){
console.log('rejected: ' + err);
}
);
这段可能会有点疑问,主要在于理解这句代码resolve(Promise.reject('reject'));
再回想一下上面的错误处理以及thenable对象的展开功能,是不是就好理解一点了,其实可以理解为与运算(&&),有一个reject,传下去的也会是reject
但是!!!并不是一直链式的传下去的全都是reject,只是紧跟着的下一个then会收到reject而已,万望好好理解这句话(我这里不展开讲了)
var p3 = new Promise(function(resolve, reject){
reject(Promise.resolve('resolve'));
});
p3.then(
function fulfilled(value){
console.log('fulfilled: ' + value);
},
function rejected(err){
console.log('rejected: ' + err);
}
);有了第二段的基础,这一段应该就非常好理解了
如果上述内容,如果看的不是很懂,建议多看几遍(不一定看我这篇,看看前人的也好),正所谓“读书百遍其义自见”
参考资料
深入理解Promise运行原理 - 掘金 自己动手实现简易版promise
转promises 很酷,但很多人并没有理解就在用了 | SHANG Blog讲了很多例子和一些坑,建议先看完基础再看它
写一个符合 Promises/A+ 规范并可配合 ES7 async/await 使用的 Promise
八段代码彻底掌握 Promise - 掘金
原文
先看下两段代码的不同,再来分析执行上下文的不同
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f();
}
checkscope();var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f;
}
checkscope()();第一段代码的执行上下文栈
ECStack.push(globalContext);//先推入全局上下文
ECStack.push(checkscope);//checkscope上下文
ECStack.push(f);//f上下文
ECStack.pop();
ECStack.pop();
ECStack.pop();第二段的
ECStack.push(globalContext);//先推入全局上下文
ECStack.push(checkscope);//checkscope上下文
ECStack.pop();
ECStack.push(f);//f上下文
ECStack.pop();
ECStack.pop();/**
* Composes single-argument functions from right to left. The rightmost
* function can take multiple arguments as it provides the signature for
* the resulting composite function.
*
* @param {...Function} funcs The functions to compose.
* @returns {Function} A function obtained by composing the argument functions
* from right to left. For example, compose(f, g, h) is identical to doing
* (...args) => f(g(h(...args))).
*/
export default function compose(...funcs) {
if (funcs.length === 0) {
return arg => arg;
}
if (funcs.length === 1) {
return funcs[0];
}
return funcs.reduce((a, b) => (...args) => a(b(...args)))
}这是一个高阶函数,返回函数的函数被称为高阶函数
它的作用是通过传入函数引用的方式,从右到左依次调用函数,并把上一个函数的值作为下一个函数的参数
文档里面的注释写的很清楚
For example, compose(f, g, h) is identical to doing
(...args) => f(g(h(...args))).再看被编译成ES5的写法,其中b.apply(underfined, arguments)是因为b()这里代表的是全局,所以要绑定underfined
return funcs.reduce(function (a, b) {
return function () {
return a(b.apply(undefined, arguments));
};
});主要实现的就是将ActionCreator与dispatch进行绑定,官方的注释里面这么写的
Turns an object whose values are action creators, into an object with the same keys, but with every action creator wrapped into a dispatch call so they may be invoked directly.
翻译过来就是bindActionCreators将值为actionCreator的对象转化成具有相同键值的对象,但是每一个actionCreator都会被dispatch所包裹调用,因此可以直接使用
先看bindActionCreator,看清楚了,没有s的
function bindActionCreator(actionCreator, dispatch) {
return (...args) => dispatch(actionCreator(...args))
}返回一个新的函数,该函数调用时会将actionCreator返回的纯对象进行dispatch
接下来看bindActionCreators
代码的作用是对对象actionCreators中的所有值调用bindActionCreator,然后返回新的对象
export default function bindActionCreators(actionCreators, dispatch) {
// 先判断是不是能返回想要的对象的函数,是就直接返回
if (typeof actionCreators === 'function') {
return bindActionCreator(actionCreators, dispatch)
}
// 如果不是对象,直接抛出错误
if (typeof actionCreators !== 'object' || actionCreators === null) {
throw new Error(
`bindActionCreators expected an object or a function, instead received ${actionCreators === null ? 'null' : typeof actionCreators}. ` +
`Did you write "import ActionCreators from" instead of "import * as ActionCreators from"?`
)
}
// 这段代码的作用是,遍历actionCreators,对其中的值全部调用bindActionCreator方法
// 再由bindActionCreator对返回的纯对象进行dispatch
const keys = Object.keys(actionCreators)
const boundActionCreators = {}
for (let i = 0; i < keys.length; i++) {
const key = keys[i]
const actionCreator = actionCreators[key]
if (typeof actionCreator === 'function') {
boundActionCreators[key] = bindActionCreator(actionCreator, dispatch)
}
}
return boundActionCreators
}官方文档
combineReducers辅助函数的作用是,把一个由多个不同reducer函数作为 value 的 object,合并成一个最终的reducer函数,然后就可以对这个reducer调用createStore。
combineReducers函数总的来说是比较简单的,将大的reducer函数拆分成一个个小的reducer分别处理,
先看代码
// 传入一个object
export default function combineReducers(reducers) {
// 获取该object的key值
const reducerKeys = Object.keys(reducers)
// 这里拿来放过滤后的reducers
const finalReducers = {}
// 这个循环的作用是过滤reducers
for (let i = 0; i < reducerKeys.length; i++) {
const key = reducerKeys[i]
// 在开发环境下是否为underfined
if (process.env.NODE_ENV !== 'production') {
if (typeof reducers[key] === 'undefined') {
warning(`No reducer provided for key "${key}"`)
}
}
// 将值类型是函数的值放进finalReducers
if (typeof reducers[key] === 'function') {
finalReducers[key] = reducers[key]
}
}
// 很好,拿到了过滤后的reducers的key值
const finalReducerKeys = Object.keys(finalReducers)
// 在开发环境下判断,保存不期望 key 的缓存用以下面做警告,初始化为{}
let unexpectedKeyCache
if (process.env.NODE_ENV !== 'production') {
unexpectedKeyCache = {}
}
// 如果抛出异常会将错误信息存储在shapeAssertionError,下面讲
let shapeAssertionError
try {
assertReducerShape(finalReducers)
} catch (e) {
shapeAssertionError = e
}
return function combination(state = {}, action) {
if (shapeAssertionError) {
throw shapeAssertionError
}
if (process.env.NODE_ENV !== 'production') {
const warningMessage = getUnexpectedStateShapeWarningMessage(state, finalReducers, action, unexpectedKeyCache)
if (warningMessage) {
warning(warningMessage)
}
}
// state 是否改变
let hasChanged = false
const nextState = {}
for (let i = 0; i < finalReducerKeys.length; i++) {
// 拿到相应的 key
const key = finalReducerKeys[i]
// 拿到key对应的reducer函数
const reducer = finalReducers[key]
// state 树下的 key 是与 finalReducers 下的 key 相同的
// 所以在 combineReducers 中传入的参数的 key 即代表了 各个 reducer 也代表了各个 state
const previousStateForKey = state[key]
// 执行对应的reducer函数获得 对应的state
const nextStateForKey = reducer(previousStateForKey, action)
// 判断 state 的值,undefined 的话就报错
if (typeof nextStateForKey === 'undefined') {
const errorMessage = getUndefinedStateErrorMessage(key, action)
throw new Error(errorMessage)
}
// 将state的值放进去
nextState[key] = nextStateForKey
// 判断state是否有改变
hasChanged = hasChanged || nextStateForKey !== previousStateForKey
}
// 根据判断返回新的state
return hasChanged ? nextState : state
}
}使用变量nextState记录本次执行reducer返回的state。
hasChanged用来记录前后state是否发生改变。
循环遍历reducers,将对应的store的部分交给相关的reducer处理,当然对应各个reducer返回的新的state仍然不可以是undefined。
最后根据hasChanged是否改变来决定返回nextState还是state,这样就保证了在不变的情况下仍然返回的是同一个对象。
总结来说就是接收一个对象reducers,将参数过滤后返回一个函数。该函数里有一个过滤参数后的对象 finalReducers,遍历该对象,然后执行对象中的每一个 reducer 函数,最后将新的 state 返回。
再看一个使用到的辅助函数assertReducerShape
function assertReducerShape(reducers) {
Object.keys(reducers).forEach(key => {
const reducer = reducers[key]
// 接下来要判断action为{ type: ActionTypes.INIT }时是否有初始值
const initialState = reducer(undefined, { type: ActionTypes.INIT })
if (typeof initialState === 'undefined') {
throw new Error(
`Reducer "${key}" returned undefined during initialization. ` +
`If the state passed to the reducer is undefined, you must ` +
`explicitly return the initial state. The initial state may ` +
`not be undefined. If you don't want to set a value for this reducer, ` +
`you can use null instead of undefined.`
)
}
// 对reduer执行一次随机的action,如果没有返回,则抛出错误,
// 告知你不要处理redux中的私有的action,对于未知的action应当返回当前的state
// The initial state may not be undefined, but can be null 初始值可以为null,但不能为underfined
const type = '@@redux/PROBE_UNKNOWN_ACTION_' + Math.random().toString(36).substring(7).split('').join('.')
if (typeof reducer(undefined, { type }) === 'undefined') {
throw new Error(
`Reducer "${key}" returned undefined when probed with a random type. ` +
`Don't try to handle ${ActionTypes.INIT} or other actions in "redux/*" ` +
`namespace. They are considered private. Instead, you must return the ` +
`current state for any unknown actions, unless it is undefined, ` +
`in which case you must return the initial state, regardless of the ` +
`action type. The initial state may not be undefined, but can be null.`
)
}
})
}1、判断reducers中的每一个reducer在action为{ type: ActionTypes.INIT }时是否有初始值,如果没有则会抛出异常。
2、对reduer执行一次随机的action,如果没有返回,则抛出错误,告知你不要处理redux中的私有的action,对于未知的action应当返回当前的state。并且初始值不能为undefined,但是可以是null
官方文档
function createStore(reducer, preloadedState, enhancer) {}创建一个 Redux store 来以存放应用中所有的 state。
应用中应有且仅有一个 store。
有三个参数,reducer是处理后的reducer纯函数,preloadedState是初始状态,而enhancer使用相对较少,enhancer是一个高阶函数,用来对原始的createStore的功能进行增强。
先看它的核心代码
export default function createStore(reducer, preloadedState, enhancer) {
// 如果没有传入参数enhancer,并且preloadedState的值又是一个函数的话
// createStore会认为你省略了preloadedState,因此第二个参数就是enhancer
if (typeof preloadedState === 'function' && typeof enhancer === 'undefined') {
enhancer = preloadedState
preloadedState = undefined
}
if (typeof enhancer !== 'undefined') {
// 传入了enhancer但是却又不是函数类型。会抛出错误
if (typeof enhancer !== 'function') {
throw new Error('Expected the enhancer to be a function.')
}
// 一切都符合预期的话,那就先执行enhancer,再执行createStore
return enhancer(createStore)(reducer, preloadedState)
}
// 如果传入的reducer也不是函数,抛出相关错误
if (typeof reducer !== 'function') {
throw new Error('Expected the reducer to be a function.')
}
// 当前reducer
let currentReducer = reducer
// 当前state
// 在同构应用中,你可以决定是否把服务端传来的 state 水合(hydrate)后传给它,或者从之前保存的用户会话中恢复一个传给它
let currentState = preloadedState
// 当前监听函数数组
let currentListeners = []
// 这里按照某大神的说法
// 这是一个很重要的设计,为的就是每次在遍历监听器的时候保证 currentListeners 数组不变
// 可以考虑下只存在 currentListeners 的情况,如果我在某个 subscribe 中再次执行 subscribe
// 或者 unsubscribe,这样会导致当前的 currentListeners 数组大小发生改变,从而可能导致
// 索引出错
let nextListeners = currentListeners
let isDispatching = false
function ensureCanMutateNextListeners() {
// 如果 currentListeners 和 nextListeners 相同,就赋值回去
if (nextListeners === currentListeners) {
nextListeners = currentListeners.slice()
}
}
...其他代码省略了
// 返回的就是一整个store,store里面包含了下面几个方法
return {
dispatch,
subscribe,
getState,
replaceReducer,
[$$observable]: observable
}
}接下来再看看它里面封装的几个方法
function dispatch(action) {
// 首先检查传入的action是不是纯对象,如果不是则抛出异常
if (!isPlainObject(action)) {
throw new Error(
'Actions must be plain objects. ' +
'Use custom middleware for async actions.'
)
}
// action中是否存在type,不存在也抛出异常
if (typeof action.type === 'undefined') {
throw new Error(
'Actions may not have an undefined "type" property. ' +
'Have you misspelled a constant?'
)
}
// 这里主要是防止循环调用
// 如果在reduder中做了dispatch,而dispatch又必然会导致reducer的调用,就会造成死循环
if (isDispatching) {
throw new Error('Reducers may not dispatch actions.')
}
// 将isDispatching置为true,调用当前的reducer函数,并且返回新的state存入currentState,并将isDispatching置回去
try {
isDispatching = true
currentState = currentReducer(currentState, action)
} finally {
isDispatching = false
}
// 依次调用监听者,但并不需要把新的state传给监听者,因为这里还有一个store.getState()方法可以获取最新的store
const listeners = currentListeners = nextListeners
for (let i = 0; i < listeners.length; i++) {
const listener = listeners[i]
listener()
}
return action
}subscribe用来订阅store的变化
function subscribe(listener) {
// 首先判断传入的listener是否是函数
if (typeof listener !== 'function') {
throw new Error('Expected listener to be a function.')
}
let isSubscribed = true
// 该函数在下面
// 用来判断nextListeners和currentListeners是否是完全相同
// 如果相同(===),将nextListeners赋值为currentListeners的拷贝(值相同,但不是同一个数组)
// 然后将当前的监听函数传入nextListeners
ensureCanMutateNextListeners()
nextListeners.push(listener)
// isSubscribed是以闭包的形式判断当前监听者函数是否在监听,从而保证只有第一次调用unsubscribe才是有效的
return function unsubscribe() {
if (!isSubscribed) {
return
}
isSubscribed = false
ensureCanMutateNextListeners()
const index = nextListeners.indexOf(listener)
nextListeners.splice(index, 1)
}
} function ensureCanMutateNextListeners() {
// 如果 currentListeners 和 nextListeners 相同,就赋值(快照)
if (nextListeners === currentListeners) {
nextListeners = currentListeners.slice()
}
}为什么会存在
nextListeners呢?
首先可以在任何时间点添加listener。无论是dispatch action时,还是state值正在发生改变的时候。但是需要注意的,在每一次调用dispatch之前,订阅者仅仅只是一份快照(snapshot),如果是在listeners被调用期间发生订阅(subscribe)或者解除订阅(unsubscribe),在本次通知中并不会立即生效,而是在下次中生效。因此添加的过程是在nextListeners中添加的订阅者,而不是直接添加到currentListeners,然后在每一次调用dispatch的时候都会做下面的赋值行为来同步currentListeners和nextListeners
const listeners = currentListeners = nextListeners这个……emm👶
function getState() {
return currentState
}热更新reducer用的,用的比较少
function replaceReducer(nextReducer) {
if (typeof nextReducer !== 'function') {
throw new Error('Expected the nextReducer to be a function.')
}
currentReducer = nextReducer
dispatch({ type: ActionTypes.INIT })
}看它的代码之前,先加一点预备知识:柯里化函数,通常也称部分求值
在计算机科学中,柯里化(Currying)是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数且返回结果的新函数的技术。
举个例子
function add(a, b) {
return a + b;
}
// 执行 add 函数,一次传入两个参数即可
add(1, 2) // 3
// 假设有一个 curry 函数可以做到柯里化
var addCurry = curry(add);
addCurry(1)(2) // 3还不知道的同学可以先去稍微补一下,大概知道柯里化函数干嘛的就行了
由于采用了ES6的结构赋值和箭头函数,applyMiddleware代码很短
// 整个applyMiddleware就是一个柯里化函数
// 所以正确的用法是applyMiddleware(...middlewares)(createStore)(...args)
export default function applyMiddleware(...middlewares) {
return (createStore) => (reducer, preloadedState, enhancer) => {
const store = createStore(reducer, preloadedState, enhancer)
let dispatch = store.dispatch
let chain = []
// 每个中间件都有这两个函数
// 还记得上面的createStore吗,它生成的store有五个函数,其中就包括这两
const middlewareAPI = {
getState: store.getState,
// 注意,这个dispatch并不是那个传进来的dispatch,而是重新定义了一个匿名函数
// (action) => dispatch(action),其实就是原来的dispatch的镜像
// 如果所有的Middleware引用的都是原来的同一个dispatch(闭包),万一有一个不知名的中间件改写了dispatch呢?boom,链式爆炸……
dispatch: (action) => dispatch(action)
}
// 每个中间件都应该传入middlewareAPI
chain = middlewares.map(middleware => middleware(middlewareAPI))
// 从右到左依次调用每个中间件,传入store.dispatch
dispatch = compose(...chain)(store.dispatch)
// 返回对应的store和dispatch
return {
...store,
dispatch
}
}
}事件流描述的是从页面中接收事件的顺序
IE 的事件流是事件冒泡流
而 Netscape Communicator 的事件流是事件捕获流
DOM2级事件规定的事件流包括三个阶段:

画重点(这部分内容可以先跳过,看完下面的内容再回头消化)
1、当处于目标阶段,没有捕获与冒泡之分,执行顺序会按照addEventListener的添加顺序决定,先添加先执行
2、使用stopPropagation()取消事件传播时,事件不会被传播给下一个节点,但是,同一节点上的其他listener还是会被执行
// list 的捕获
$list.addEventListener('click', (e) => {
console.log('list capturing');
e.stopPropagation();
}, true)
// list 捕获 2
$list.addEventListener('click', (e) => {
console.log('list capturing2');
}, true)
// list capturing
// list capturing2如果想要同一层级的listener也不执行,可以使用stopImmediatePropagation()
3、preventDefault()只是阻止默认行为,跟JS的事件传播一点关系都没有
4、一旦发起了preventDefault(),在之后传递下去的事件里面也會有效果
共有三种事件处理程序:DOM0、DOM2、IE
var btn = document.getElementById('btn');
btn.onClick = () => {
console.log('我是DOM0级事件处理程序');
}
btn.onClick = null;
btn.addEventListener('click', () => {
console.log('我是DOM2级事件处理程序');
}, false);
btn.removeEventListener('click', handler, false)
btn.attachEvent('onclick', () => {
console.log('我是IE事件处理程序')
})
btn.detachEvent('onclicn', handler);画重点:
DOM2级的好处是可以添加多个事件处理程序;DOM0对每个事件只支持一个事件处理程序
通过DOM2添加的匿名函数无法移除,上面写的例子就移除不了,addEventListener和removeEventListener的handler必须同名
作用域:DOM0的handler会在所属元素的作用域内运行,IE的handler会在全局作用域运行,this === window
触发顺序:添加多个事件时,DOM2会按照添加顺序执行,IE会以相反的顺序执行,请谨记
跨浏览器的事件处理程序
var EventUtil = {
// element是当前元素,可以通过getElementById(id)获取
// type 是事件类型,一般是click ,也有可能是鼠标、焦点、滚轮事件等等
// handle 事件处理函数
addHandler: (element, type, handler) => {
// 先检测是否存在DOM2级方法,再检测IE的方法,最后是DOM0级方法(一般不会到这)
if (element.addEventListener) {
// 第三个参数false表示冒泡阶段
element.addEventListener(type, handler, false);
} else if (element.attachEvent) {
element.attachEvent(`on${type}`, handler)
} else {
element[`on${type}`] = handler;
}
},
removeHandler: (element, type, handler) => {
if (element.removeEventListener) {
// 第三个参数false表示冒泡阶段
element.removeEventListener(type, handler, false);
} else if (element.detachEvent) {
element.detachEvent(`on${type}`, handler)
} else {
element[`on${type}`] = null;
}
}
}
// 获取元素
var btn = document.getElementById('btn');
// 定义handler
var handler = function(e) {
console.log('我被点击了');
}
// 监听事件
EventUtil.addHandler(btn, 'click', handler);
// 移除事件监听
// EventUtil.removeHandler(button1, 'click', clickEvent);DOM0和DOM2的事件处理程序都会自动传入event对象
IE中的event对象取决于指定的事件处理程序的方法(上面说过)
IE的
handler会在全局作用域运行,this === window
所以在IE中会有window.event、event两种情况
只有在事件处理程序期间,event对象才会存在,一旦事件处理程序执行完成,event对象就会被销毁
event对象里需要关心的几个属性
this、currentTarget、target这三个属性跟冒泡和捕获有关
target永远是被添加了事件的那个元素,this和currentTarget就不一定了(延伸思考:事件处理程序在父节点中的情况)
调用事件处理程序的阶段,有三个值
1:捕获阶段
2:处于目标
3:冒泡阶段
preventDefault与传播stopPropagationpreventDefault:比如链接被点击会导航到其href指定的URL,这个就是默认行为
stopPropagation:立即停止事件在DOM层次中的传播,包括捕获和冒泡事件
srcElement => target
returnValue => preventDefaukt()
cancelBubble => stopPropagation()
IE 不支持事件捕获,因而只能取消事件冒泡,但stopPropagation可以同时取消事件捕获和冒泡
根据上面对不同类型的事件以及属性区分
var EventUtil = {
addHandler: (element, type, handler) => {},
removeHandler: (element, type, handler) => {},
// 获取event对象
getEvent: (event) => {
return event ? event : window.event
},
// 获取当前目标
getTarget: (event) => {
return event.target ? event.target : event.srcElement
},
// 阻止默认行为
preventDefault: (event) => {
if (event.preventDefault) {
event.preventDefault()
} else {
event.returnValue = false
}
},
// 停止传播事件
stopPropagation: (event) => {
if (event,stopPropagation) {
event.stopPropagation()
} else {
event.cancelBubble = true
}
}
}这一小节在《高程》P403
我自认不能写的比它更精简更好,有些地方就直接搬过来了
事件委托用来解决事件处理程序过多的问题
页面结构如下
<ul id="myLinks">
<li id="goSomewhere">Go somewhere</li>
<li id="doSomething">Do something</li>
<li id="sayHi">Say hi</li>
</ul>按照传统的做法,需要像下面这样为它们添加 3 个事 件处理程序。
var item1 = document.getElementById("goSomewhere");
var item2 = document.getElementById("doSomething");
var item3 = document.getElementById("sayHi");
EventUtil.addHandler(item1, "click", function(event){
location.href = "http://www.wrox.com";
});
EventUtil.addHandler(item2, "click", function(event){
document.title = "I changed the document's title";
});
EventUtil.addHandler(item3, "click", function(event){
alert("hi");
});如果在一个复杂的 Web 应用程序中,对所有可单击的元素都采用这种方式,那么结果就会有数不 清的代码用于添加事件处理程序。此时,可以利用事件委托技术解决这个问题。使用事件委托,只需在 DOM 树中尽量最高的层次上添加一个事件处理程序,如下面的例子所示
var list = document.getElementById("myLinks");
EventUtil.addHandler(list, "click", function(event) {
event = EventUtil.getEvent(event);
var target = EventUtil.getTarget(event);
switch(target.id) {
case "doSomething":
document.title = "I changed the document's title";
break;
case "goSomewhere":
location.href = "http://www.wrox.com";
break;
case "sayHi": 9 alert("hi");
break;
}
}子节点的点击事件会冒泡到父节点,并被这个注册事件处理
最适合采用事件委托技术的事件包括 click、mousedown、mouseup、keydown、keyup 和 keypress。 虽然 mouseover 和 mouseout 事件也冒泡,但要适当处理它们并不容易,而且经常需要计算元素的位置。
可以考虑为 document 对象添加一个事件处理程序,用以处理页面上发生的某种特定类型的事件,需要跟踪的事件处理程序越少,移除它们就越容易(移除事件处理程序关乎内存和性能)。
只要是通过 onload 事件处理程序添加的东西,最后都要通过 onunload 事件处理程序将它们移除
在事件处理程序中删除按钮也能阻止事件冒泡。目标元素在文档中是事件冒泡的前提。
感谢您耐心看到这里,希望有所收获!
如果不是很忙的话,麻烦右上角点个star⭐,举手之劳,却是对作者莫大的鼓励。
我在学习过程中喜欢做记录,分享的是自己在前端之路上的一些积累和思考,希望能跟大家一起交流与进步,更多文章请看【amandakelake的Github博客】
DOM 的事件傳遞機制:捕獲與冒泡 | TechBridge 技術共筆部落格
What Is Event Bubbling in JavaScript? Event Propagation Explained
#Front-End/HTML+CSS
BFC(Block formatting context)直译为"块级格式化上下文"。它是一个独立的渲染区域,只有Block-level box参与(在下面有解释), 它规定了内部的Block-level Box如何布局,并且与这个区域外部毫不相干。
文档流其实分为定位流、浮动流和普通流三种。而普通流其实就是指BFC中的FC。
FC是formatting context的首字母缩写,直译过来是格式化上下文,它是页面中的一块渲染区域,有一套渲染规则,决定了其子元素如何布局,以及和其他元素之间的关系和作用。
BFC 对布局的影响主要体现在对 float 和 margin 两个属性的处理。BFC 让 float 和 margin 这两个属性的表现更加符合我们的直觉。
根据 BFC 对其内部元素和外部元素的表现特性,将 BFC 的特性总结为对内部元素的包裹性及对外部元素的独立性。
满足下列条件之一就可触发BFC
【1】根元素,即HTML元素
【2】float的值不为none
【3】overflow的值不为visible
【4】display的值为inline-block、table-cell、table-caption
【5】position的值为absolute或fixed
1.内部的Box会在垂直方向,一个接一个地放置。
2.Box垂直方向的距离由margin决定。属于同一个BFC的两个相邻Box的margin会发生重叠
3.每个元素的margin box的左边, 与包含块border box的左边相接触(对于从左往右的格式化,否则相反)。即使存在浮动也是如此。
4.BFC的区域不会与float box重叠。
5.BFC就是页面上的一个隔离的独立容器,容器里面的子元素不会影响到外面的元素。反之也如此。
6.计算BFC的高度时,浮动元素也参与计算
<style>
body {
width: 300px;
position: relative;
}
.aside {
width: 100px;
height: 150px;
float: left;
background: #f66;
}
.main {
height: 200px;
background: #fcc;
}
</style>
<body>
<div class="aside"></div>
<div class="main"></div>
</body>

上面的代码中,虽然存在浮动的元素aslide,但main的左边依然会与包含块的左边相接触
每个元素的margin box的左边, 与包含块border box的左边相接触(对于从左往右的格式化,否则相反)。即使存在浮动也是如此。
但通过
BFC的区域不会与float box重叠。
可以通过通过触发main生成BFC, 来实现自适应两栏布局
.main {
overflow: hidden;
}

<style>
.par {
border: 5px solid #fcc;
width: 300px;
}
.child {
border: 5px solid #f66;
width:100px;
height: 100px;
float: left;
}
</style>
<body>
<div class="par">
<div class="child"></div>
<div class="child"></div>
</div>
</body>

计算BFC的高度时,浮动元素也参与计算
为达到清除内部浮动,我们可以触发par生成BFC,那么par在计算高度时,par内部的浮动元素child也会参与计算。
.par {
overflow: hidden;
}

属于同一个BFC的两个相邻Box的margin会发生重叠
我们可以在p外面包裹一层容器,并触发该容器生成一个BFC。那么两个P便不属于同一个BFC,就不会发生margin重叠了。
function foo() {
var a = 2;
function bar() {
console.log(a); // 2
}
bar();
}
foo();这段代码,严格意义上来说并不属于闭包
虽然bar劫持了foo作用域中的a变量,但是它在foo执行时也同时执行了,并没有把foo的作用域告诉foo之外的兄弟们。
当foo执行完毕后,JS的自动垃圾回收机制,会把a变量回收,因为已经没有其他的函数或者什么地方保持对a的引用了,说白了,就是没有把bar所引用的函数对象当做返回值返回
其他地方的引用
JavaScript拥有自动的垃圾回收机制,关于垃圾回收机制,有一个重要的行为,那就是,
当一个值,在内存中失去引用时,垃圾回收机制会根据特殊的算法找到它,并将其回收,释放内存。
再来看一段代码
function foo() {
var a = 2;
function bar() {
console.log(a);
}
return bar;
}
var baz = foo();
baz(); // 2 —— 朋友,这就是闭包的效果。看到了吗,foo()执行后,返回值(内部的bar()函数)赋值给了变量baz,这个时候,变量baz就保持了对foo内部的a变量的引用,按照上面说的垃圾回收机制,foo的作用域就没办法被销毁了,因为a卡在内存中,也就说闭包的存在,阻止了foo的内部作用域被回收这一过程
其他地方的引用
函数的执行上下文,在执行完毕之后,生命周期结束,那么该函数的执行上下文就会失去引用。其占用的内存空间很快就会被垃圾回收器释放,闭包的存在,会阻止这一过程。
到这里,我自己的理解就是:当一个函数所定义的内部作用域,可以在外部被访问到,就产生了闭包
再看书里面的定义,这些话就好理解多了
bar() 依然持有对该作用域的引用,而这个引用就叫作闭包。
无论通过何种手段将内部函数传递到所在的词法作用域以外,它都会持有对原始定义作用 域的引用,无论在何处执行这个函数都会使用闭包
再来看一段代码
var fn;
function foo() {
var a = 2;
function baz() {
console.log(a);
}
fn = baz; // 将 baz 分配给全局变量
}
function bar() {
fn();// 妈妈快看呀,这就是闭包!
}
foo();
bar(); //2上面把内部函数baz传递了出来,全局变量fn保持了对baz的引用,当执行bar()的时候,间接调用了baz,也就是调用了foo中的a变量,闭包就形成了
举一反三来想,我们平时使用回调函数的时候,不正是将内部函数传递到所在的词法作用域以外么?
说明了什么?
说明调用回调函数的过程,就是使用了闭包呀,开心
什么定时器、事件监听、网络请求、异步操作、跨窗口通信、web worker、service worker等等,不都是在使用闭包么
现在回到一道经典的循环题
for (var i = 1; i <= 5; i++) {
setTimeout(function timer() {
console.log(i);
}, i * 1000);
}稍微有点基础的都知道,会输出五个6
因为循环结束时,i = 6
这里循环时的每个i都共享同一个全局作用域,同时因为setTimeout是延迟执行的,所以输出全是最后的那个i
那么每次的时长间隔又是多少呢?
有同学可能会以为
先是1s后输出6,然后间隔2s后再输出一个6,然后3s、4s、5s
我告诉你,这样是错的
你先打印这个东西看一下

每次的i是不是不一样
对,是不一样
但是,这个时延,其实是相对与开始执行这个for循环时开始,并不是相对于上一个循环开始,这里要好好区分一下
也就是说从开始执行for循环时,1s后输出6,2s后输出6,……
所以每次输出的间隔都是1s
这样说,应该明白了吧
然后,下一个问题
怎么依次输出1,2,3,4,5呢?
先加个IIFE试一下
for (var i = 1; i <= 5; i++) {
(function() {
setTimeout(function timer() {
console.log(i);
}, i * 1000);
})();
}答案还是5个6,为什么呢?
如果作用域是空的,那么仅仅将它们进行封闭是不够的。仔细看一下,我们的 IIFE 只是一 个什么都没有的空作用域。它需要包含一点实质内容才能为我们所用。
它需要有自己的变量,用来在每个迭代中储存 i 的值:
那就把i传进去吧
for (var i = 1; i <= 5; i++) {
(function(j) {
setTimeout(function timer() {
console.log(j);
}, j * 1000);
})(i);
}这次终于对了
大兄弟,闭包在哪呢?前面不是说IIFE跟闭包不太像么
IIFE是在函数本身所定义时的作用域内(),并不是在作用域之外被执行的
尽管 IIFE 本身并不是观察闭包的恰当例子,但它的确创建了闭包,并且也是最常用来创建 可以被封闭起来的闭包的工具。因此 IIFE 的确同闭包息息相关,即使本身并不会真的使用 闭包。
那就用个闭包
for (var i = 1; i <= 5; i++) {
let j = i; //这里就是闭包的快作用域
setTimeout(function timer() {
console.log(j);
}, j * 1000);
}再来个酷点的
for (let i = 1; i <= 5; i++) {
setTimeout(function timer() {
console.log(i);
}, i * 1000);
}闭包写到这里,基本概念就已经写完了
书里还有关于模块的高级用法,就留给大伙(包括我自己)去慢慢研读吧。
网上关于缓存的文章非常多,但大都比较片面,或者只对某块进行了深入,没有把它们联系起来,本着系统学习的态度,笔者进行了整理,写成一个小系列,方便自己也方便他人共同学习。
本篇文章不会讲细讲各种缓存的详细用法,笔者试图站在宏观的角度去分析各类缓存技术的优缺点、应用场景,力图寻找比较好的实践搭配。
本篇文章是总览,最好是先对下面的缓存技术有基础理解再来看
详细缓存介绍可参考下面链接
缓存(二)——浏览器缓存机制:强缓存、协商缓存
缓存(三)——数据存储:cookie、Storage、indexedDB
缓存(四)——离线应用缓存:App Cache => Manifest
缓存(五)——离线应用缓存:Service Worker(还没写,先占坑)
重用已获取的资源,减少延迟与网络阻塞,进而减少显示某个资源所用的时间,借助 HTTP 缓存,Web 站点变得更具有响应性。
其实我们对于页面静态资源的要求就两点
1、静态资源加载速度
2、页面渲染速度
页面渲染速度建立在资源加载速度之上,但不同资源类型的加载顺序和时机也会对其产生影响,所以缓存的可操作空间非常大
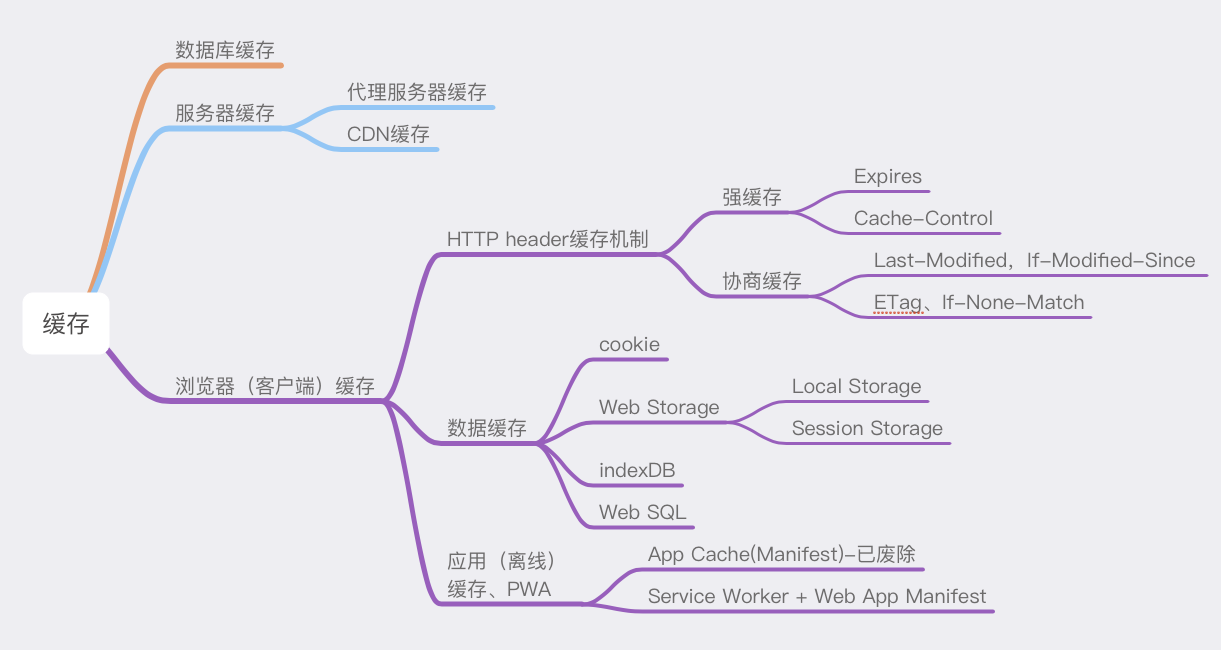
整个系列只讨论浏览器(客户端)方面的缓存
在 Web 应用中使用缓存是一种改善响应时间和减少 CPU 使用的绝佳方式,但是,缓存应该放置在架构的哪个环节中呢?
这里不直接给答案(我不会告诉你是我给不出答案😂),通过分析的方式来引导大家,分析自己的项目的性能问题,性能瓶颈在哪?
是文件太大,还是请求数量太多?
重复的无效请求是否太多?
数据或者结果可以缓存吗?
这些数据、结果、文件的刷新率如何,容易失效吗?
这些问题,一千个项目有一千个答案,只有弄明白了缓存的核心原理,才能以不变应万变,信手沾来。
1、每次都加载某个同样的静态文件 => 浪费带宽,重复请求 => 让浏览器使用本地缓存(协商缓存,返回304)
2、协商缓存还是要和服务器通信啊 => 有网络请求,不太舒服,感觉很low => 强制浏览器使用本地强缓存(返回200)
3、缓存要更新啊,兄弟,网络请求都没了,我咋知道啥时候要更新?=> 让请求(header加上ETag)或者url的修改与文件内容关联(文件名加哈希值)=> 开心,感觉自己很牛逼
4、CTO大佬说,我们买了阿里还是腾讯的CDN,几百G呢,用起来啊 => 把静态资源和动态网页分集群部署,静态资源部署到CDN节点上,网页中引用的资源变成对应的部署路径 => html中的资源引用和CDN上的静态资源对应的url地址联系起来了 => 问题来了,更新的时候先上线页面,还是先上线静态资源?(蠢,等到半天三四点啊,用户都睡了,随便你先上哪个)
5、老板说:我们的产品将来是国际化的,不存在所谓的半夜三点 => GG,咋办?=> 用非覆盖式发布啊,用文件的摘要信息来对资源文件进行重命名,把摘要信息放到资源文件发布路径中,这样,内容有修改的资源就变成了一个新的文件发布到线上,不会覆盖已有的资源文件。上线过程中,先全量部署静态资源,再灰度部署页面
优点:对于传输部分少量不敏感数据,非常简明有效
缺点:容量小(4K),不安全(cookie被拦截,很可能暴露session);原生接口不够友好,需要自己封装;需要指定作用域,不可以跨域调用
容量稍大一点(5M),localStorage可做持久化数据存储
支持事件通知机制,可以将数据更新的通知发送给监听者
缺点:本地储存数据都容易被篡改,容易受到XSS攻击
缓存读取需要依靠js的执行,所以前提条件就是能够读取到html及js代码段,其次文件的版本更新控制会带来更多的代码层面的维护成本,所以LocalStorage更适合关键的业务数据而非静态资源
Cookie的作用是与服务器进行交互,作为HTTP规范的一部分而存在 ,而Web Storage仅仅是为了在本地“存储”数据而生
IndexedDb提供了一个结构化的、事务型的、高性能的NoSQL类型的数据库,包含了一组同步/异步API,这部分不好判断优缺点,主要看使用者。
优点
缺点
Manifest被移除是技术发展的必然,请拥抱Service Worker吧
这位目前是最炙手可热的缓存明星,是官方建议替代Application Cache(Manifest)的方案
作为一个独立的线程,是一段在后台运行的脚本,可使web app也具有类似原生App的离线使用、消息推送、后台自动更新等能力
目前有三个限制(不能明说是缺点)
感谢您耐心看到这里,希望有所收获!
如果不是很忙的话,麻烦点个star⭐【Github博客传送门】,举手之劳,却是对作者莫大的鼓励。
我在学习过程中喜欢做记录,分享的是自己在前端之路上的一些积累和思考,希望能跟大家一起交流与进步,更多文章请看【amandakelake的Github博客】
参考
浏览器缓存、CacheStorage、Web Worker 与 Service Worker · Issue #113 · youngwind/blog · GitHub
关于前端缓存优化,为什么没人用manifest? - 知乎
变态的静态资源缓存与更新 - Div.IO
大话WEB前端性能优化基本套路
先占坑
之前看了这一篇文章
99%的人都理解错了HTTP中GET与POST的区别
得出了两个简明意赅的结论,一度也以为自己把握了get和post的精髓
GET产生一个TCP数据包;POST产生两个TCP数据包。
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);
而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
后来又看到了一篇怼上一篇文章的文章
听说『99% 的人都理解错了 HTTP 中 GET 与 POST 的区别』??
文章对原文的结论提出了一些疑问
主要关于首部Expect: 100-continue的区别
赶紧回去翻了下《HTTP权威指南》寻找官方解释,第62页和附录C的解释
100 Continue的目的是对
HTTP客户端应用程序有一个实体的主体部分要发送服务器,但希望在发送之前查看一下服务器是否会接受这个实体这种情况进行优化
如果客户端在向服务器发送一个实体,并愿意在发送实体之前等待100 Continue响应,那么客户端就要发送一个携带了值为100 Continue的Expect请求首部。如果客户端没有发送实体,就不应该发送100 Continue Expect首部,因为这样会使服务器误以为客户端要发送一个实体
认真看这个地方,就会发现跟第一篇文章中的区别,这里是客户端愿意发100 continue才会有响应,并不是每次都会有100 continue响应,再对比下第一篇文章的结论
而对于POST,浏览器先发送header,
服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
区别就在这里
如果服务器收到一条带有值为100 Continue的Expect首部的请求,它会用100 Continue响应或一条错误码来进行响应。
服务器永远也不应该向没有发送100 Continue期望的客户端发送100 Continue状态码。
如果服务器在有机会发送100 Continue响应之前就收到了部分(或者全部)的实体,说明服务器已经打算继续发送数据了,这样服务器就不需要发送这个状态码了,但是服务器完成请求之后,还是应该为请求发送一个最终状态码
看到了吗,没收到客户端的100 Continue就不会有响应
第二篇文章中得出的结论是
通过抓包发现,尽管会分两次,body 就是紧随在 header 后面发送的,根本不存在『等待服务器响应』这一说
其实,从理论上来说,这些知识最好都应该自己去实践去查阅RFC文档,辩证看待前人作者的结论,就像我们怀疑了第一篇文章的结论,那凭什么不能继续怀疑第二篇文章的结论呢,那当然是应该的!有兴趣深入的可以继续怀疑《HTTP权威指南》
首先掰正了一个100 continue概念,
然后再根据一些目前大家都认可的答案去辩证看一下
这里是w3c的对比 HTTP 方法:GET 对比 POST

首先,GET和POST是由HTTP协议定义的,Method和Data(URL, Body, Header)这两个概念没有必然的联系,使用哪个Method与应用层的数据如何传输是没有相互关系的
HTTP没有要求,如果Method是POST数据就要放在BODY中。也没有要求,如果Method是GET,数据(参数)就一定要放在URL中而不能放在BODY中
HTTP协议明确地指出了,HTTP头和Body都没有长度的要求,URL长度上的限制主要是由服务器或者浏览器造成的
到目前为止,纠正了几个概念,到最后,问起来,get和post的最核心区别是什么?我可能会回答:
在用法上,一个用于获取数据,一个用于修改数据;
在根本上,没有啥区别
在细节上,有一些区别,需要展开讲嘛?
既然说到HTTP请求了,那自然就要聊一下TCP,请看下一篇
#前端/Javascript/个人理解总结
当我们直接使用$('#test')创建一个对象时,实际上是创建了一个init的实例,这里的真正构造函数是原型中的init方法
每当我们执行$()时,就会重新生成一个init的实例对象,对于内存的消耗是非常大的
正确的做法是既然是同一个对象,那么就用一个变量保存起来后续使用即可
var $test = $('#test');
实现了两个扩展方法
jQuery.extend = jQuery.fn.extend = function(options) {
// 在jquery源码中会根据参数不同进行很多判断,我们这里就直接走一种方式,所以就不用判断了
var target = this;
var copy;
for(name in options) {
copy = options[name];
target[name] = copy;
}
return target;
}
首先要清楚this的指向(搞清楚是指向实例jQuery还是原型对象jQuery.fn)
通过jQuery.extend扩展jQuery时,方法被添加到了jQuery构造函数中
通过jQuery.fn.extend扩展jQuery时,方法被添加到了jQuery原型
$.ajax()
$.isFunction()
$.each()
原型中的方法,在使用时必须创建一个新的实例对象才能访问$('#test').css()
$('#test').attr()
$('div').each()
(function ($) {
$.fn.extend({
becomeDrag: function () {
new Drag(this[0]);
return this; // 注意:为了保证jQuery所有的方法都能够链式访问,每一个方法的最后都需要返回this,即返回jQuery实例
}
})
})(jQuery);
for (var key in arr){
console.log(arr[key]);
}
for (var value of arr){
console.log(value);
}
在一个函数上下文中,this由调用者提供,由调用函数的方式来决定。
如果调用者函数,被某一个对象所拥有,那么该函数在调用时,内部的this指向该对象。
如果函数独立调用,那么该函数内部的this,则指向undefined。
但是在非严格模式中,当this指向undefined时,它会被自动指向全局对象。
function fn() {
'use strict';
console.log(this);
}
fn(); // fn是调用者,独立调用,undefined
window.fn(); // window调用,window'use strict';
var a = 20;
function foo () {
var a = 1;
var obj = {
a: 10,
c: this.a + 20,
fn: function () {
return this.a;
}
}
return obj.c;
}
console.log(window.foo()); //c里面的那个this,这时候因为是window调用,所以指向this,this.a = 20
console.log(foo()); // foo()独立调用,所以是this是undefined,这里要记住,{}并不能形成单独的作用域,并不会产生新的this在函数执行过程中,this一旦被确定,就不可更改了
var a = 10;
var obj = {
a: 20
}
function fn () {
this = obj; // 这句话试图修改this,运行后会报错
console.log(this.a);
}
fn();作用:自行手动设置this的指向,它们的第一个参数都为this将要指向的对象
它们除了参数略有不同,其功能完全一样
【Javascript】apply和call的区别 - 笔记 - 前端网(QDFuns)
通过new操作符调用构造函数,会经历以下4个阶段。
直接看代码
function Person(name, age) {
// 这里的this指向了谁?
console.log('Person',this);
this.name = name;
this.age = age;
}
Person.prototype.getName = function() {
// 这里的this又指向了谁?
console.log('prototype',this);
return this.name;
}
// 上面的2个this,是同一个吗,他们是否指向了原型对象?
var p1 = new Person('Nick', 20);
p1.getName();// 先指向new出来的新对象,上面第二步
Person Person {}// 第三步,指向构造函数的代码,为新对象添加属性和方法
prototype Person {name: "Nick", age: 20}export与export default均可用于导出常量、函数、文件、模块
在一个文件或模块中,export、import可以有多个,export default仅有一个
使用export default命令,为模块指定默认输出,这样就不需要知道所要加载模块的变量名
Node里面的模块系统遵循的是CommonJS规范:CommonJS定义的模块分为: 模块标识(module)、模块定义(exports) 、模块引用(require)
require方能看到的只有module.exports这个对象,它是看不到exports对象的,而我们在编写模块时用到的exports对象只是对module.exports的引用
Node.js模块里exports与module.exports的区别? - 知乎
//demo1.js
export const str = 'hello world'
export function f(a){
return a+1
}//demo2.js
import { str, f } from 'demo1' //也可以分开写两次,导入的时候带花括号//demo1.js
export default const str = 'hello world'//demo2.js
import str from 'demo1' //导入的时候没有花括号先简单看下MDN上的介绍
Object.defineProperty() - JavaScript | MDN
Object.defineProperty(obj, prop, descriptor)Obj:要在其上定义属性的对象
prop:要定义或修改的属性的名称
Descriptor:将被定义或修改的属性描述符,返回被传递给函数的对象
example
var obj = {};
Object.defineProperty(obj, 'name', {
value: 'mike'
});
console.log(obj); // mike
ECMAScript有两种属性:数据属性和访问器属性
[configurable]总开关,一旦为false,就不能再设置他的其他属性(value,writable,configurable)
[enumerable]决定了能否被for(prop in obj)和Object.keys()枚举
Object.defineProperty(dream, 'a', {
value: 1,
enumerable: false // 不可枚举
});
Object.defineProperty(dream, 'b', {
value: 2,
enumerable: true // 可枚举
});
// 只会输出 b
for(prop in dream) {
console.log(prop);
}[writable]当且仅当仅当该属性的writable为true时,该属性才能被赋值运算符改变,默认值为false
[Value]value和get,set是不可以共存的,定义了value后就不能够再定义get,set特性了
访问器属性不包含数据值,没有[value]
它们包含一对儿getter和setter函数(但都不是必须的)
[configurable]同上
[enumerable]同上
[Get]读取属性时调用的函数,默认underfined
[Set]写入属性时调用的函数,默认underfined
看个例子
let a = {};
Object.defineProperty(a, 'p', {
get: () => {
return 1
},
set: (newValue) => {
console.log(newValue)
}
})
a.p = 2;
console.log(a.p);
// 2
// 1给a定义了一个访问器属性p
a.p = 2时调用set方法,但这里什么都没做,只是打印了想要设置的值2
console.log(a.p);调用get方法,但也只是固定返回1而已
从这个简单的例子,相信你能举一反三
看个最简单的vue例子,只是数据和dom节点的绑定
html
<div>
<p>你好,<span id='nickName'></span></p>
<div id="introduce"></div>
</div> Js
//视图控制器
var userInfo = {};
Object.defineProperty(userInfo, "nickName", {
get: function(){
return document.getElementById('nickName').innerHTML;
},
set: function(nick){
document.getElementById('nickName').innerHTML = nick;
}
});
Object.defineProperty(userInfo, "introduce", {
get: function(){
return document.getElementById('introduce').innerHTML;
},
set: function(introduce){
document.getElementById('introduce').innerHTML = introduce;
}
})愉快地绑定数据交互
userInfo.nickName = "xxx";
userInfo.introduce = "我是xxx,我来自云南,..."
async是ES7提出的函数,被誉为目前为止JS在异步操作方面的最优解
async 函数是 Generator 的语法糖。
而await命令就是内部then命令的语法糖。
使用 关键字 async 来表示,在函数内部使用 await 来表示异步。
Generator 函数的执行必须依靠执行器,而 Aysnc 函数自带执行器,调用方式跟普通函数的调用一样
co 模块约定,yield 命令后面只能是 Thunk 函数或 Promise对象。
而 async 函数的 await 命令后面则可以是 Promise 或者 原始类型的值(Number,string,boolean,但这时等同于同步操作)
async 函数返回值是 Promise 对象,比 Generator 函数返回的 Iterator 对象方便,可以直接使用 then() 方法进行调用
这一部分实在想不出要写些什么
对于会Promise和Generator的同学来说,这一部分那就是五秒钟就能解决的事
await可以直接获取到后面Promise成功状态传递的参数,但是却捕捉不到失败状态
but,Promise的运行结果可能是reject,所以最好把await命令放在try…catch代码块中
async function foo() {
try {
return await dosomething()
} catch (err) {
console.log(err)
}
}当 async 函数中只要一个 await 出现 reject 状态,则后面的 await 都不会被执行。
async function foo() {
let a = await request(url1);
let b = await request(url2);
let c = await request(url3);
return a + b + c
}a、b、c三者的获取没有任何联系,这时候就应该用Promise.all()并发执行
async function foo() {
let results = await Promise.all([request(url1),request(url2),request(url3)])
return results.reduce((total,item) => total * item)
}毕竟是ES7的语法,目前来说还是比较新的,还是需要以下babel的支持
只需要设置 presets 为 stage-3 即可
npm install babel-preset-es2015 babel-preset-stage-3 babel-runtime babel-plugin-transform-runtime
修改.babelrc文件
"presets": ["es2015", "stage-3"],
"plugins": ["transform-runtime"]
概览如图(保留一大串英文,是为了鼓励大家好好学英语😀)

下面会尽量保持精简,能用图和代码的地方,就尽量不写文字,保留最直观的感受,简单的API会直接给官方文档
Array.prototype.includes() - JavaScript | MDN
const arr = [1, 2, 3, NaN];
if (arr.indexOf(3) >= 0) {
console.log(true)
}
// true
if (arr.includes(3)) {
console.log(true)
}
// true
arr.indexOf(NaN)
// -1 无法识别NaN
arr.includes(NaN);
// true 可以识别NaNMath.pow(2, 3)
// 8
2 ** 3
// 8Object.values() - JavaScript | MDN
const obj = { foo: "bar", baz: 42 };
console.log(Object.values(obj)); // ['bar', 42]Object.entries() - JavaScript | MDN
const obj = { foo: 'bar', baz: 42 };
console.log(Object.entries(obj)); // [ ['foo', 'bar'], ['baz', 42] ]
// array like object
const obj = { 0: 'a', 1: 'b', 2: 'c' };
console.log(Object.entries(obj)); // [ ['0', 'a'], ['1', 'b'], ['2', 'c'] ]String.prototype.padStart() - JavaScript | MDN
String.prototype.padEnd() - JavaScript | MDN
'abc'.padStart(10); // " abc"
'abc'.padStart(10, "foo"); // "foofoofabc"
'abc'.padStart(6,"123465"); // "123abc"
'abc'.padStart(8, "0"); // "00000abc"
'abc'.padStart(1); // "abc"
'abc'.padEnd(10); // "abc "
'abc'.padEnd(10, "foo"); // "abcfoofoof"
'abc'.padEnd(6, "123456"); // "abc123"
'abc'.padEnd(1); // "abc"注意,Emojis和双字节字符会占据两位
'heart'.padStart(10, "❤️"); // prints.. '❤️❤️❤heart'Object.getOwnPropertyDescriptor() - JavaScript | MDN
Object.getOwnPropertyDescriptor(obj, prop)Object.getOwnPropertyDescriptor() 方法返回指定对象上一个自有属性对应的属性描述符。(自有属性指的是直接赋予该对象的属性,不需要从原型链上进行查找的属性)
function fn(a, b,) {}
// 注意,参数b后面多了个逗号,不会报语法错误async function - JavaScript | MDN
个人认为所有更新里这是最爆炸,最强的新特性
即使有event loop的”伪多线程“和Service Worker的强力增援,但依然掩盖不了JS是单线程的事实。
共享内存与原子操作,给JS带来了多线程的功能,允许开发人员自行管理内存来开发高性能高并发的程序。
核心是SharedArrayBuffer对象
SharedArrayBuffer - JavaScript | MDN
The SharedArrayBuffer object is used to represent a generic, fixed-length raw binary data buffer, similar to the ArrayBuffer object, but in a way that they can be used to create views on shared memory. Unlike an ArrayBuffer, a SharedArrayBuffer cannot become detached.
关键词:shared memory
直到目前为止,我们只能通过postMessage在JS主线程和web worker之间通信,传输数据。
SharedArrayBuffer允许共享内存,必然会带来竞态关系,后端语言会通过锁解决这个问题,这里引入了Atomics全局对象
The Atomics object provides atomic operations as static methods. They are used with SharedArrayBuffer objects.
Atomics对象提供了一些方法来处理这种关系,包括读取与更新
感兴趣的可以参与以下资料(全英文,为部分同学感到蛋蛋的忧伤)
A cartoon intro to SharedArrayBuffers – Mozilla Hacks – the Web developer blog
ES proposal: Shared memory and atomics
本部分可直接查看下面链接
非转义序列的模板字符串 | esnext | es6 es7 es2017 es2018 es2019
let { firstName, age, ...rest } = {
firstName: 'a',
age: 18,
a: 1,
b: 2
};
firstName; // 'a',
age; // 18
rest;
// 重点看这里 { a: 1, b: 2 }一个新的API而已,promise相信大家都会用了
Promise.prototype.finally() - JavaScript | MDN
提供了for-await-of,异步迭代,等待每个promise被resolve再执行下一个
const promises = [
new Promise(resolve => resolve(1)),
new Promise(resolve => resolve(2)),
new Promise(resolve => resolve(3))
];// old
async function test1() {
for (const obj of promises) {
console.log(obj);
}
}
test1(); //
// Promise {<resolved>: 1}
// Promise {<resolved>: 2}
// Promise {<resolved>: 3}// new
async function test2() {
for await (const obj of promises) {
console.log(obj);
}
}
test2();
// 1, 2, 3本部分内容,同学们可自行查阅
dotAll 模式,使 . 可以匹配任意字符const regex = /(\d{4})-(\d{2})-(\d{2})/;
const matchers = regex.exec('2015-01-02');
matchers[0]; // 2015-01-02
matchers[1]; // 2015
matchers[2]; // 01
matchers[3]; // 02感谢您耐心看到这里,希望有所收获!
如果不是很忙的话,麻烦点个star⭐【Github博客传送门】,举手之劳,却是对作者莫大的鼓励。
我在学习过程中喜欢做记录,分享的是自己在前端之路上的一些积累和思考,希望能跟大家一起交流与进步,更多文章请看【amandakelake的Github博客】
参考链接
Here are examples of everything new in ECMAScript 2016, 2017, and 2018
HTTP/2的出现,无疑对Web性能的提升带来了巨大的助力,改变了Web开发者优化网站的方式,但之前一直对它处于模糊的状态,只知道一些零零碎碎的知识,周末终于静下心来,从HTTP1开始,找到HTTP/2的存在及其存在必然性,整理了一些内容如下,希望能对有需要的同学产生一点点帮助。
分析之前,先来点直观好玩的吧
这个网站做了一个测试:分别利用HTTP/1和HTTP/2协议来下载一张大图(该大图由多张小图组成),HTTP/2完胜
HTTP/2 is the future of the Web, and it is here!
点进去看看?
有个成语叫“事出有因”,每个事物都有其存在的意义(原因),而HTTP/2的诞生自然来自于HTTP/1的一些痛点
HTTP(应用层)建立在TCP(传输层)之上,HTTP协议的一些瓶颈以及性能优化都是建立在TCP协议本身的特性之上。
所以谈HTTP之前还是得对TCP有一点点的了解(比如对三次握手、四次挥手、慢启动、往返时延RTT、拥塞窗口cwnd……)
起码得知道三次握手和四次挥手是为了防止了服务器端的一直等待而浪费资源;知道慢启动是为了避免拥塞;知道RTT和cwnd的概念是什么
传送门:TCP慢启动、拥塞避免、快速重传、快速恢复 - CSDN博客
影响网络请求的主要因素有两个:带宽和延迟
带宽跟网络基础建设相关暂不谈,所以延迟成了web工程师们的头号公敌。
http1.0被抱怨最多的两个问题
理解下面两个问题有一个十分重要的前提:客户端是依据域名来向服务器建立连接,一般PC端浏览器会针对单个域名的server同时建立6~8个连接,手机端的连接数则一般控制在4~6个。显然连接数并不是越多越好,资源开销和整体延迟都会随之增大。
连接无法复用会导致每次请求都经历三次握手和慢启动。三次握手在高延迟的场景下影响较明显,慢启动则对文件类大请求影响较大。
解决方案:
①HTTP持久连接:Connection:Keep-Alive HTTP持久连接,痛点在于当前请求必须彻底完成后,下一请求才能正确发送。
②http long-polling:长轮询
③http streaming:建立起一个tcp连接后,服务器不会结束streaming请求,持续的通过这个通道返回最新的业务数据,数据通道也是单向的,除非客户端自动断开,否则一直保持连接
④websocket:也是基于tcp协议,提供双向的数据通道,优势在于提供了message的概念,同时又提供了传统的http所缺少的长连接功能
head of line blocking会导致带宽无法被充分利用,以及后续健康请求被阻塞,健康的请求会被不健康的请求影响,而且这种体验的损耗受网络环境影响,出现随机且难以监控
解决方案:HTTP管线化
基于HTTP/1的其他优化手段
1、Spriting(图片合并):但有时候只需要其中一张小图,就会浪费流量
2、Inlining(内容内嵌):比如把图片转化为base64编码后内嵌到总文件中,问题同上
3、Concatenation(文件合并):粒度变大,一个小的js代码改动会导致整个js文件被下载
4、Domain Sharding(域名分片):浏览器或者客户端是根据domain(域名)来建立连接,多建立几个sub domain(子域名),那么同时可以建立的http请求就会更多,连接数变多之后,受限制的请求就不需要等待前面的请求完成才能发出了;只有在请求数非常之多的场景下才有明显的效果,移动端建议不要使用
Why Domain Sharding is Bad News for Mobile Performance and Users
HTTP/1存在不少问题,2012年google提出了SPDY的方案,直击HTTP/1痛点
多路复用通过多个请求stream共享一个tcp连接的方式,解决了http1.x holb(head of line blocking)的问题,降低了延迟同时提高了带宽的利用率
SPDY允许给每个request设置优先级,这样重要的请求就会优先得到响应
SPDY对header的压缩率可以达到80%以上
开启server push之后,server通过X-Associated-Content header(X-开头的header都属于非标准的,自定义header)告知客户端会有新的内容推送过来。在用户第一次打开网站首页的时候,server将资源主动推送过来可以极大的提升用户体验。
和server push不同的是,server hint并不会主动推送内容,只是告诉有新的内容产生,内容的下载还是需要客户端主动发起请求。server hint通过X-Subresources header来通知
HTTP/1.x是一个文本协议,这注定它是非常冗余的协议,HTTP/2改变了这一点,在HTTP/1.x的语义上,将文本数据封装在帧里,并采用二进制编码
http2.0的格式定义更接近tcp层的方式,虽然看上去协议的格式和http1.x完全不同了,实际上http2.0并没有改变http1.x的语义,只是把原来http1.x的header和body部分用frame重新封装了一层而已。调试的时候浏览器甚至会把http2.0的frame自动还原成http1.x的格式
理解HTTP/2之前,要先理解两个概念
帧(frame)和流(stream)HTTP/2中多路复用:帧(frame)和流(stream)
HTTP/2和SPDY不同的地方在于,它是业界标准,而SPDY是chrome自家的孩子,马虎不得,一言一行都得考虑明星效应
所以它有几个设计前提
基于以上原则,HTTP/2继承了SPDY的部分特性,并基于自己的明星定位做了一些扩展,下面介绍HTTP/2的基本概念及其如何优化Web性能的一些实践。
把HTTP/1.x每个请求都当作一个“流”,那么请求化成多个流,请求响应数据切成多个帧,不同流中的帧交错地发送给对方,这就是HTTP/2中的多路复用
1、消除了多种通过捆绑相关资产以削减连接数量的长期解决思路的存在必要性,比如(上面的优化手段):
2、请求优先级和请求依赖
一个request对应一个stream并分配一个id,这样一个连接上可以有多个stream,每个stream的frame可以随机的混杂在一起,接收方可以根据stream id将frame再归属到各自不同的request里面
所以,HTTP/2里的每个stream都可以设置优先级(Priority)和依赖(Dependency),真正解决了关键请求被阻塞的问题
SPDY/2使用的是gzip压缩算法
HTTP/2采用的是一种叫HPACK的压缩算法
比如说客户端请求一个 html, html 里面含有 css 和图片,按照正常来讲,解析 html 之后要分别发出 CSS 的请求和图片的请求,但是如果服务端得知页面支持 server push,客户端便只需要发出 http 请求,而服务器直接将 css 和图片一起发出去,以致请求多个响应未发先至。这就是 server push 的作用,和 inlining 有点类似,但是相比 inlining 有两个好处,inlining 会影响缓存,会增大 html 的体积,包括后台模板的维护,这也便增加开发和维护成本,对于客户而言仅仅是多个请求。
对于HTTP/1来说,是通过设置tcp segment里的reset flag来通知对端关闭连接的。这种方式会直接断开连接,下次再发请求就必须重新建立连接。
HTTP/2引入RST_STREAM类型的frame,可以在不断开连接的前提下取消某个request的stream,表现更好。
在HTTP/1下,大家的关注点都在减少向服务器发起的HTTP请求数,将尽可能多的资源塞进一个连接中,并寻找其他办法来避免浏览器出现线头阻塞。
在HTTP/2下,Web开发者应该专注于网站的缓存调优,而不是担心如何减少HTTP请求数。通用的法则是,传输轻量、细粒度的资源,以便独立缓存和并行传输。
这种转变的出现是因为HTTP/2的多路复用和头部压缩特性。
多路复用使得不同的请求共用一个TCP连接,允许多个资源并行下载,避免建立多个连接带来不必要的额外开销。它消除了HTTP/1.1中的线头阻塞问题。
头部压缩进一步减少了多个HTTP请求的开销,因为每个请求开销都小于未压缩的等价HTTP/1.1请求。
HTTP/2还有两个改变会影响到你的Web优化:流优先级和服务端推送。前者允许浏览器指定接受资源的顺序,后者允许服务端主动发送额外的资源。
如此一来,上面HTTP/1的几种优化手段就应该被历史抛弃了:合并文件(webpack怎么办?思考题)、内联资源、雪碧图、细分域名
DNS查询需要一个RTT时间,在浏览器级别,系统级别都会有层DNS缓存,之前解析过的可以直接从本机缓存获取,以减少延迟。
Web标准提供了一种DNS预解析技术,因为服务器是知道页面即将会发生哪些请求的,那我们可以在页面顶部,插入 <link rel="dns-prefetch" href="//host/">,让浏览器先解析一下这个域名。那么,后续扫到同域的请求,就可以直接从DNS缓存获取了。
此外,Web标准也提供prefetch,prerender的预加载技术。prefectch会在浏览器空闲的时候,向所提供的链接发起请求,而prerender不仅会请求,还会帮你在后台渲染页面。如果在一个页面中,你知道用户有很大概率去点某个链接,可以尝试把这个链接加到prefetch或prerender,那么用户就会秒开这个页面了。
将Web资源通过CDN放在地理上更靠近来访者的服务器节点上
进一步利用内容分发网络,将资源存储在用户的本地浏览器缓存中,除了产生一个304 Not Modified响应之外,这避免了任何形式的数据在网络上传输
重定向意味着要重新发起请求
这里要说的一种重定向是,访问HTTP站点,跳转到HTTPS,并不是指资源缓存的重定向获取
避免这种跳转,我们可以用HSTS策略
告诉浏览器,以后访问我这个站点,必须用HTTPS协议来访问,让浏览器帮忙做转换,而不是请求到了服务器后,才知道要转换
在响应头部加上 Strict-Transport-Security: max-age=31536000 即可
1、HTTP2.0最大的亮点在于多路复用,而多路复用的好处只有在http请求量大的场景下才明显,所以目前来说,可能更适用于浏览器浏览大型站点的时候。
2、HTTP2.0对于ssl的依赖比较强
虽然HTTP2.0也可以不走ssl,有些场景确实可能不适合https,比如对代理服务器的cache依赖,对于内容安全性不敏感的get请求可以通过代理服务器缓存来优化体验
3、移动端iOS9+自动支持HTTP/2,Android理论上来说需要5.0以上才支持(这个理论上非绝对,这里不说了)
参考
HTTP/2.0 相比1.0有哪些重大改进? - 知乎
从TCP、HTTP/1的问题上分析了为何会诞生HTTP/2
排名第二的那篇文章更加详细
Web 开发者的 HTTP/2 性能优化指南
与HTTP/1做了对比,容易理解和记忆
Web 的现状:网页性能提升指南 - 前端郭高工 - SegmentFault 思否 在HTTP/1的基础上,讲的比较详细有条理
【网络协议】Web协议未来优化指南对TCP、HTTP1、HTTPS、SPDY、HTTP2等几种协议做了对比区分
网上关于缓存的文章非常多,但大都比较片面,或者只对某块进行了深入,没有把它们联系起来,本着系统学习的态度,笔者进行了整理,写成一个小系列,方便自己也方便他人共同学习,有写的不对的地方欢迎指正。
缓存(一)——缓存总览:从性能优化的角度看缓存
缓存(二)——浏览器缓存机制:强缓存、协商缓存
缓存(三)——数据存储:cookie、Storage、indexedDB
缓存(四)——离线应用缓存:App Cache => Manifest
缓存(五)——离线应用缓存:Service Worker(还没写,先占坑)
有经验的同学可以直接去看第四部分的流程图,如果你能完全理解那个图,那这篇文章你可以不看了,当然,看看当复习也好
良好的缓存策略可以降低资源的重复加载提高网页的整体加载速度
通常浏览器缓存策略分为两种:强缓存和协商缓存
expires和cache-control判断是否命中强缓存,是则直接从缓存读取资源,不会发请求到服务器。last-modified和etag验证资源是否命中协商缓存,如果命中,服务器会将这个请求返回,但是不会返回这个资源的数据,依然是从缓存中读取资源如果命中,都是从客户端缓存中加载资源,而不是从服务器加载资源数据;
强缓存不发请求到服务器,协商缓存会发请求到服务器。
强缓存通过Expires和Cache-Control两种响应头实现
Expires是http1.0提出的一个表示资源过期时间的header,它描述的是一个绝对时间,由服务器返回。
Expires 受限于本地时间,如果修改了本地时间,可能会造成缓存失效
Expires: Wed, 11 May 2018 07:20:00 GMT
Cache-Control 出现于 HTTP / 1.1,优先级高于 Expires ,表示的是相对时间
Cache-Control: max-age=315360000
题外tips
Cache-Control: no-cache不会缓存数据到本地的说法是错误的,详情《HTTP权威指南》P182

Cache-Control: no-store才是真正的不缓存数据到本地
Cache-Control: public可以被所有用户缓存(多用户共享),包括终端和CDN等中间代理服务器
Cache-Control: private只能被终端浏览器缓存(而且是私有缓存),不允许中继缓存服务器进行缓存

当浏览器对某个资源的请求没有命中强缓存,就会发一个请求到服务器,验证协商缓存是否命中,如果协商缓存命中,请求响应返回的http状态为304并且会显示一个Not Modified的字符串
协商缓存是利用的是【Last-Modified,If-Modified-Since】和【ETag、If-None-Match】这两对Header来管理的
Last-Modified 表示本地文件最后修改日期,浏览器会在request header加上If-Modified-Since(上次返回的Last-Modified的值),询问服务器在该日期后资源是否有更新,有更新的话就会将新的资源发送回来
但是如果在本地打开缓存文件,就会造成 Last-Modified 被修改,所以在 HTTP / 1.1 出现了 ETag
Etag就像一个指纹,资源变化都会导致ETag变化,跟最后修改时间没有关系,ETag可以保证每一个资源是唯一的
If-None-Match的header会将上次返回的Etag发送给服务器,询问该资源的Etag是否有更新,有变动就会发送新的资源回来

ETag的优先级比Last-Modified更高
具体为什么要用ETag,主要出于下面几种情况考虑:

200:强缓Expires/Cache-Control存失效时,返回新的资源文件200(from cache): 强缓Expires/Cache-Control两者都存在,未过期,Cache-Control优先Expires时,浏览器从本地获取资源成功304(Not Modified ):协商缓存Last-modified/Etag没有过期时,服务端返回状态码304但是!但是!
现在的200(from cache)已经变成了from disk cache(磁盘缓存)和from memory cache(内存缓存)两种
打开chrome控制台看一下网络请求就知道了
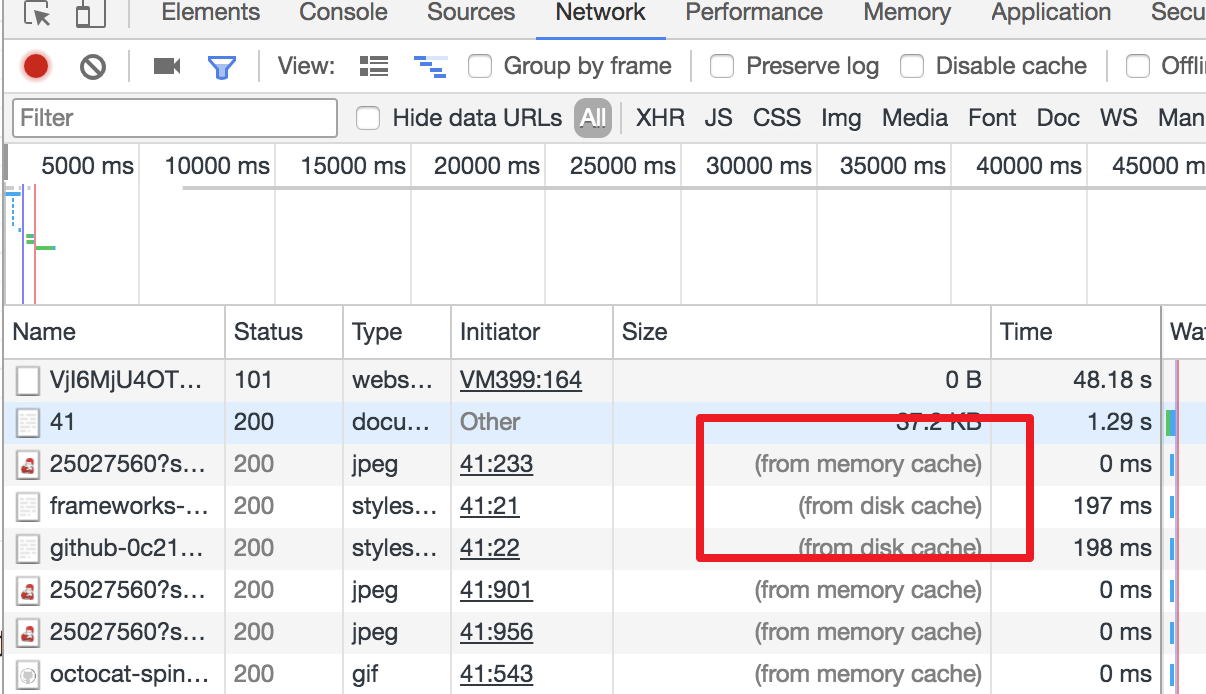
具体两者的区别,暂时没有去深究,有兴趣的同学可以自己去研究
大致的顺序
协商缓存需要配合强缓存使用,如果不启用强缓存的话,协商缓存根本没有意义
大部分web服务器都默认开启协商缓存,而且是同时启用【Last-Modified,If-Modified-Since】和【ETag、If-None-Match】
但是下面的场景需要注意:
感谢您耐心看到这里,希望有所收获!
如果不是很忙的话,麻烦右上角点个star⭐【Github博客传送门】,举手之劳,却是对作者莫大的鼓励。
我在学习过程中喜欢做记录,分享的是自己在前端之路上的一些积累和思考,希望能跟大家一起交流与进步,更多文章请看【amandakelake的Github博客】
浅谈Web缓存 | AlloyTeam
浏览器缓存知识小结及应用 - 流云诸葛 - 博客园
HTTP 缓存 | Web | Google Developers
大公司里怎样开发和部署前端代码? - 知乎
HTTP强缓存和协商缓存 - JavaScript学习笔记 - SegmentFault 思否
能用图解决的问题,就不用字了

本文以懒加载为主,先看看懒加载和预加载两者的概念对比

对页面加载速度影响最大的就是图片
当页面图片比较多,加载速度慢,非常影响用户体验
思考一下,页面有可能有几百张图片,但是首屏上需要展示的可能就一张而已,其他的那些图片能不能晚一点再加载,比如用户往下滚动的时候……
这是为什么要用懒加载的原因
那预加载呢?
这个非常语义化,预备,提前……
就是让用户感觉到你加载图片非常快,甚至用户没有感受到你在加载图片
图片先用占位符表示,不要将图片地址放到src属性中,而是放到其它属性(data-original)中
页面加载完成后,监听窗口滚动,当图片出现在视窗中时再给它赋予真实的图片地址,也就是将data-original中的属性拿出来放到src属性中
在滚动页面的过程中,通过给scroll事件绑定lazyload函数,不断的加载出需要的图片
注意:请对lazyload函数使用防抖与节流,不懂这两的可以自己去查
这种方式,本质上不算懒加载
加载完首屏内容后,隔一段时间,去加载全部内容
但这个时间差已经完成了用户对首屏加载速度的期待
用户点击或者执行其他操作再加载
其实也包括的滚动可视区域,但大部分情况下,大家说的懒加载都是只可视区域的图片懒加载,所以就拿出来说了
这里也分为两种情况
1、页面滚动的时候计算图片的位置与滚动的位置
2、通过新的API: IntersectionObserver API(可以自动"观察"元素是否可见)Intersection Observer API - Web API 接口 | MDN
提前加载图片,当用户需要查看时可直接从本地缓存中渲染
加载方式目前主要有两种
先通过CSS将图片加载到不可见区域
#preload-01 { background: url(http://domain.tld/image-01.png) no-repeat -9999px -9999px; }待到满足触发条件后,再通过JS渲染
通过new Image()把图片下载到本地,让浏览器缓存起来,设置其src来实现加载,再使用onload方法回调加载完成事件
其实两者的概念是相反的
一个是延迟加载,一个是提前加载
一个是减低服务器压力,一个是增加服务器压力(换取用户体验)
将非首屏的图片的src属性设置一个默认值,监听事件scroll resize``orientationchange,判断元素进入视口viewport时则把真实地址赋予到src上
<img class="lazy" src="[占位图]" data-src="[真实url地址]" data-srcset="[不同屏幕密度下,不同的url地址]" alt="I'm an image!">如上,data-*属于自定义属性, ele.dataset.* 可以读取自定义属性集合
img.srcset 属性用于设置不同屏幕密度下,image自动加载不同的图片,比如<img src="image-128.png" srcset="image-256.png 2x" />
imgEle.offsetTop < window.innerHeight + document.body.scrollTopElement.getBoundingClientRect()方法返回元素的大小及其相对于视口的位置,具体参考文档Element.getBoundingClientRect() - Web API 接口 | MDN
function isInViewport(ele) {
// 元素顶部 距离 视口左上角 的距离top <= 窗口高度 (反例:元素在屏幕下方的情况)
// 元素底部 距离 视口左上角 的距离bottom > 0 (反例:元素在屏幕上方的情况)
// 元素display样式不为none
const notBelow = ele.getBoundingClientRect().top <= window.innerHeight ? true : false;
const notAbove = ele.getBoundingClientRect().bottom >= 0 ? true : false;
const visable = getComputedStyle(ele).display !== "none" ? true : false;
return notBelow && notAbove && visable ? true : false;
}由于兼容性问题,暂时不写,具体可参考文档
Intersection Observer - Web API 接口 | MDN
【更新】可参考这篇文章Intersection Observer + Vue指令 优雅实现图片懒加载
注意DOMContentLoaded,在DOM解析完之后立马执行,不适合前后端分离的单页应用,因为SPA应用一般来说图片数据是异步请求的,在DOMContentLoaded的时候,页面上未必完全解析完JS和CSS,这时候let lazyImages = [].slice.call(document.querySelectorAll("img.lazy"));拿到的不是真正首屏的所有图片标签
document.addEventListener("DOMContentLoaded", () => {
// 获取所有class为lazy的img标签
let lazyImages = [].slice.call(document.querySelectorAll("img.lazy"));
// 这个active是节流throttle所用的标志位,这里用到了闭包知识
let active = false;
const lazyLoad = () => {
// throttle相关:200ms内只会执行一次lazyLoad方法
if (active) return;
active = true;
setTimeout(() => {
lazyImages.forEach(lazyImage => {
// 判断元素是否进入viewport
if (isInViewport(lazyImage)) {
// <img class="lazy" src="[占位图]" data-src="[真实url地址]" data-srcset="[不同屏幕密度下,不同的url地址]" alt="I'm an image!">
// ele.dataset.* 可以读取自定义属性集合,比如data-*
// img.srcset 属性用于设置不同屏幕密度下,image自动加载不同的图片 比如<img src="image-128.png" srcset="image-256.png 2x" />
lazyImage.src = lazyImage.dataset.src;
lazyImage.srcset = lazyImage.dataset.srcset;
// 删除class 防止下次重复查找到改img标签
lazyImage.classList.remove("lazy");
}
// 更新lazyImages数组,把还没处理过的元素拿出来
lazyImages = lazyImages.filter(image => {
return image !== lazyImage;
});
// 当全部处理完了,移除监听
if (lazyImages.length === 0) {
document.removeEventListener("scroll", lazyLoad);
window.removeEventListener("resize", lazyLoad);
window.removeEventListener("orientationchange", lazyLoad);
}
})
active = false;
}, 200);
}
document.addEventListener("scroll", lazyLoad);
document.addEventListener("resize", lazyLoad);
document.addEventListener("orientationchange", lazyLoad);
})let lazyImages = [].slice.call(document.querySelectorAll("img.lazy"));的获取时机放在了定时器里面,不是一开始就拿到全局的lazyImages,而是每次刷新时才拿到还没处理过的function LazyLoad() {
// 这个active是节流throttle所用的标志位,这里用到了闭包知识
let active = false;
const lazyLoad = () => {
// throttle相关:200ms内只会执行一次lazyLoad方法
if (active) return;
active = true;
setTimeout(() => {
// 获取所有class为lazy的img标签,这里由于之前已经把处理过的img标签的class删掉了 所以不会重复查找
let lazyImages = [].slice.call(document.querySelectorAll("img.lazy"));
lazyImages.forEach(lazyImage => {
// 判断元素是否进入viewport
if (isInViewport(lazyImage)) {
// <img class="lazy" src="[占位图]" data-src="[真实url地址]" data-srcset="[不同屏幕密度下,不同的url地址]" alt="I'm an image!">
// ele.dataset.* 可以读取自定义属性集合,比如data-*
// img.srcset 属性用于设置不同屏幕密度下,image自动加载不同的图片 比如<img src="image-128.png" srcset="image-256.png 2x" />
lazyImage.src = lazyImage.dataset.src;
lazyImage.srcset = lazyImage.dataset.srcset;
// 删除class 防止下次重复查找到改img标签
lazyImage.classList.remove("lazy");
}
// 当全部处理完了,移除监听
if (lazyImages.length === 0) {
document.removeEventListener("scroll", lazyLoad);
window.removeEventListener("resize", lazyLoad);
window.removeEventListener("orientationchange", lazyLoad);
}
})
active = false;
}, 200);
}
document.addEventListener("scroll", lazyLoad);
document.addEventListener("resize", lazyLoad);
document.addEventListener("orientationchange", lazyLoad);
}mounted钩子中执行const vm = new Vue({
el: '.wrap',
store,
mounted: function () {
LazyLoad();
}
});img-lazy组件<template>
<img :class="['lazy', className]" :src="defaultImg" :data-src="url" :data-srcset="`${url} 1x`" alt="fordeal">
</template>
<script>
export default {
props: {
url: {
type: String
},
defaultImg: {
type: String,
default: [默认图片]
className: {
type: String,
default: ''
}
}
}
</script><img-lazy className="image" :url="item.display_image" />主要参考《图解HTTP》
TCP/IP协议族:互联网相关联的协议集合
TCP/IP协议族的分层分为四层

作用是把各种数据包传送给对方
提供面向连接的、可靠的字节流服务
字节流服务
为了方便传输,将大块数据分割成报文段为单位的数据包进行管理
TCP 并不能保证数据一定会被对方接收到,因为这是不可能的。TCP 能够做到的是,如果有可能,就把数据递送到接收方,否则就(通过放弃重传并且中断连接这一手段)通知用户。因此准确说 TCP 也不是 100% 可靠的协议,它所能提供的是数据的可靠递送或故障的可靠通知。
确保数据能到达目标:三次握手,客户端和服务器总共发送3个包
连接断开:四次挥手,客户端和服务器总共发送4个包
关于三次握手和四次挥手,目前看到觉得最通俗易懂的一篇文章
通俗大白话来理解TCP协议的三次握手和四次分手 · Issue #14 · jawil/blog · GitHub
都是为了
防止服务器端的一直等待而浪费资源
跨域是浏览器的限制,服务器之间的请求是没有跨域限制的
所以本地node起的服务器或者nginx服务器有两个作用
1、充当静态文件服务器,可以查看本地页面,以及监测文件改动
2、充当代理服务器,比如node的proxyTable用的是http-proxy-middleware中间件,原理是浏览器发给自己的服务端,然后由自己的服务端再转发给要跨域的服务端,做一层代理
在浏览器端跨域,可能导致获取到其他网站的敏感信息或者越权操作,比如拿到银行的登录状态或者执行转账操作,所以应当禁止。
服务端跨域没有这个问题,因为用户的这些状态信息都是在浏览器端保存的,服务器只能有自己网站的状态信息
到目前为止,常见的跨域方法有以下几种
还有这些老生常谈的,但不经常用的,就忽略而过吧
只需要后端同学支持就ok,前端不需要做很多额外工作(除了携带cookie)。
只要服务器返回的相应中包含头部信息Access-Control-Allow-Origin: domain-name,domain-name为允许跨域的域名,也可以设置成*,浏览器就会允许本次跨域请求
后端允许CROS跨域,前端设置代理链接和允许带上cookie
Access-Control-Allow-Origin不可以为 *,因为 *会和 Access-Control-Allow-Credentials:true 冲突,需配置指定的地址
access-control-allow-credentials: true
access-control-allow-origin: http://localhost:9123
// 此处是允许带上cookie
axios.defaults.withCredentials = true;代理的话,现在前后端分离的潮流,都是node服务器起的代理proxyTable
proxy: {
"/fd": {
target:
process.env.NODE_ENV === "production"
? "http://m.domian1.com"
: "http://test.domain.com",
ws: true,
changeOrigin: true,
pathRewrite: {
"/fd": "/"
}
}
},otherWindow.postMessage(message, targetOrigin, [transfer]);
MDN-postMessage
发送者和接收者都可以通过message事件,监听对方的消息
message事件的事件对象event包含三个属性
发送方 http://domain-a.com/a.html
<script>
var newWindow = window.open('http://domain-b.com/b.html');
/* 向b.html发送消息 */
newWindow.postMessage('Hello', 'http://domain-b.com/b.html');
/* 双向通信,接收b.html的回复消息 */
var onmessage = function (event) {
var data = event.data;
var origin = event.origin;
var source = event.source;
if (origin == 'http://domain-b.com/b.html') {
console.log(data); //Nice to see you!
}
};
window.addEventListener('message', onmessage, false);
</scirpt>接收方 http://domain-b.com/b.html
<script>
var onmessage = function (event) {
var data = event.data;
var origin = event.origin;
var source = event.source;
if (origin == 'http://domain-a.com/a.html') {
console.log(data); //Hello
/* 回复a.html的消息 */
source.postMessage('Nice to see you!', 'http://domain-a.com/a.html');
}
};
window.addEventListener('message', onmessage, false);
</script> /* websocket协议为ws/wss, 类似http/https的区别 */
wsUrl = 'wss://127.0.0.1:8090/ws/';
/* 发送 */
ws = new WebSocket(wsUrl);
/* 连接成功建立时调用 */
ws.onopen = function (event) {
console.log("websocket command onopen");
var msg = {
username: 'YeaseonZhang'
}
/* 通过 send() 方法向服务端发送消息,参数必须为字符串 */
ws.send(JSON.stringify(msg));
};
/* 服务端向客户端发送消息时调用 */
ws.onmessage = function (event) {
/* event.data包含了服务端发送过来的消息 */
console.log("websocket command onmessage: " + event.data);
if (event.data === 'success') {
/* 通过 close() 方法断开websocket连接 */
ws.close();
}
};
/* 连接被关闭时调用 */
ws.onclose = function (event) {
console.log("websocket command onclose: " + event.data);
};
/* 出现错误时调用 */
ws.onerror = function (event) {
console.log("websocket command onerror: " + event.data);
};其实就是我们日常前后端分离中,node起的最多服务器设置,但一些脚手架,比如vue cli ,create-react-app都帮我们配置好了
var express = require('express');
var proxy = require('http-proxy-middleware');
var app = express();
app.use('/api', proxy({target: 'http://www.example.org', changeOrigin: true}));
app.listen(3000);#前端/Node
2009年Node诞生,是Ryan Dahl基于chrome V8引擎创建,起初是一个Web服务器,后来变成了构建网络应用的一个基础框架,高大上一点说就是提供高度可伸缩服务器
会因为阻塞I/O导致硬件资源得不到更优的使用
会因为编程中的死锁、状态同步问题让开发者头疼
利用单线程,远离多线程死锁、状态同步问题;
利用异步I/O ,让单线程远离阻塞,以更好的利用CPU
同时,为了弥补无法利用多核CPU的缺点,提供了类似前端浏览器中Web Workers的子进程child_process
网上关于缓存的文章非常多,但大都比较片面,或者只对某块进行了深入,没有把它们联系起来,本着系统学习的态度,笔者进行了整理,写成一个小系列,方便自己也方便他人共同学习,有写的不对的地方欢迎指正。
缓存(一)——缓存总览:从性能优化的角度看缓存
缓存(二)——浏览器缓存机制:强缓存、协商缓存
缓存(三)——数据存储:cookie、Storage、indexedDB
缓存(四)——离线应用缓存:App Cache => Manifest
缓存(五)——离线应用缓存:Service Worker(还没写,先占坑)
储存的数据可能是从服务器端获取到的数据,也可能是在多个页面中需要频繁使用到的数据
1、cookie:4K,可以手动设置失效期
2、localStorage:5M,除非手动清除,否则一直存在
3、sessionStorage:5M,不可以跨标签访问,页面关闭就清理
4、indexedDB:浏览器端数据库,无限容量,除非手动清除,否则一直存在
5、Web SQL:关系数据库,通过SQL语句访问(已经被抛弃)
本文只涉及前端部分,Web SQL部分有兴趣的同学可自行了解
Cookie通过在客户端记录信息确定用户身份
Session通过在服务器端记录信息确定用户身份
一个用户的所有请求操作都应该属于同一个会话,而另一个用户的所有请求操作则应该属于另一个会话
HTTP协议是无状态的协议。一旦数据交换完毕,客户端与服务器端的连接就会关闭,再次交换数据需要建立新的连接。这就意味着服务器无法从连接上跟踪会话
Cookie实际上是一小段的文本信息。客户端请求服务器,如果服务器需要记录该用户状态,就使用response向客户端浏览器颁发一个Cookie。客户端浏览器会把Cookie保存起来。当浏览器再请求该网站时,浏览器把请求的网址连同该Cookie一同提交给服务器。服务器检查该Cookie,以此来辨认用户状态。服务器还可以根据需要修改Cookie的内容。
cookie的内容主要包括:名字,值,过期时间,路径和域。路径与域一起构成cookie的作用范围
Session是另一种记录客户状态的机制,不同的是Cookie保存在客户端浏览器中,而Session保存在服务器上。客户端浏览器访问服务器的时候,服务器把客户端信息以某种形式记录在服务器上。这就是Session。客户端浏览器再次访问时只需要从该Session中查找该客户的状态就可以了。
如果说Cookie机制是通过检查客户身上的“通行证”来确定客户身份的话,那么Session机制就是通过检查服务器上的“客户明细表”来确认客户身份。Session相当于程序在服务器上建立的一份客户档案,客户来访的时候只需要查询客户档案表就可以了。
当程序需要为某个客户端的请求创建一个session时,
可以用document.cookie获取cookie,得到一个字符串,形式如 key1=value1; key2=value2,需要用正则匹配需要的值,其他库已经封装的比较好,具体可以自己去搜索
cookie可以设置路径path,所有他要比另外两个多了一层访问限制
cookie可以通过设置domain属性值,可以不同二级域名下共享cookie,而Storage不可以,比如http://image.baidu.com的cookie http://map.baidu.com是可以访问的,前提是Cookie的domain设置为.http://baidu.com,而Storage是不可以的
缺点:在请求头上带着数据,大小是4k之内,主Domain污染。
常用的配置属性有以下几个
Expires :cookie最长有效期
Max-Age:在 cookie 失效之前需要经过的秒数。(当Expires和Max-Age同时存在时,文档中给出的是已Max-Age为准,可是我自己用Chrome实验的结果是取二者中最长有效期的值)
Domain:指定 cookie 可以送达的主机名。
Path:指定一个 URL 路径,这个路径必须出现在要请求的资源的路径中才可以发送 Cookie 首部
Secure:一个带有安全属性的 cookie 只有在请求使用SSL和HTTPS协议的时候才会被发送到服务器。
HttpOnly:设置了 HttpOnly 属性的 cookie 不能使用 JavaScript 经由 Document.cookie 属性、XMLHttpRequest 和 Request APIs 进行访问,以防范跨站脚本攻击(XSS)。
大小:官方建议是5M存储空间
类型:只能操作字符串,在存储之前应该使用JSON.stringfy()方法先进行一步安全转换字符串,取值时再用JSON.parse()方法再转换一次
存储的内容: 数组,图片,json,样式,脚本。。。(只要是能序列化成字符串的内容都可以存储)
注意:数据是明文存储,毫无隐私性可言,绝对不能用于存储重要信息
区别:sessionStorage将数据临时存储在session中,浏览器关闭,数据随之消失,localStorage将数据存储在本地,理论上来说数据永远不会消失,除非人为删除
另外,不同浏览器无法共享localStorage和sessionStorage中的信息。同一浏览器的相同域名和端口的不同页面间可以共享相同的 localStorage,但是不同页面间无法共享sessionStorage的信息
保存数据
localStorage.setItem( key, value );
sessionStorage.setItem( key, value );
读取数据
localStorage.getItem( key );
sessionStorage.getItem( key );
删除单个数据
localStorage.removeItem( key );
sessionStorage.removeItem( key );
删除全部数据
localStorage.clear( );
sessionStorage.clear( );
获取索引的key
localStorage.key( index );
sessionStorage.key( index );
可以通过监听 window 对象的 storage 事件并指定其事件处理函数,当页面中对 localStorage 或 sessionStorage 进行修改时,则会触发对应的处理函数
window.addEventListener('storage',function(e){
console.log('key='+e.key+',oldValue='+e.oldValue+',newValue='+e.newValue);
})触发事件的时间对象(e 参数值)有几个属性:
key : 键值。
oldValue : 被修改前的值。
newValue : 被修改后的值。
url : 页面url。
storageArea : 被修改的 storage 对象。
要想系统学习indexedDB相关知识,可以去MDN文档啃API,假以时日就可以成为前端indexedDB方面的专家
大概流程
var DBOpenRequest = window.indexedDB.open(dbName, version);
dbName是数据库名称,version是数据库版本
打开数据库的结果是,有可能触发4种事件
var openRequest = indexedDB.open("test",1);
var db;
openRequest.onupgradeneeded = function(e) {
console.log("Upgrading...");
}
openRequest.onsuccess = function(e) {
console.log("Success!");
db = e.target.result;
}
openRequest.onerror = function(e) {
console.log("Error");
console.dir(e);
}
open返回的是一个对象
回调函数定义在这个对象上面
回调函数接受一个事件对象event作为参数,它的target.result属性就指向打开的IndexedDB数据库,也就是说db = e.target.result才算我们真正拿到的数据库
var objectStore = db.createObjectStore(dbName, {
keyPath: 'id',
autoIncrement: true
});
objectStore是一个重要的对象,可以理解为存储对象
objectStore.add()可以向数据库添加数据,objectStore.delete()可以删除数据,objectStore.clear()可以清空数据库,objectStore.put()可以替换数据
使用objectStore来创建数据库的主键和普通字段
objectStore.createIndex('id', 'id', {
unique: true
});
数据库的操作都是基于事务(transaction)来进行,于是,无论是添加编辑还是删除数据库,我们都要先建立一个事务(transaction),然后才能继续下面的操作
var transaction = db.transaction(dbName, "readwrite");
dbName就是数据库的名称
// 新建一个事务
var transaction = db.transaction('project', "readwrite");
// 打开存储对象
var objectStore = transaction.objectStore('project');
// 添加到数据对象中
objectStore.add(newItem);indexedDB数据库的获取使用Cursor APIs和Key Range APIs。也就是使用“游标API”和“范围API”,具体使用可以去看文档
如果是浏览器主窗体线程开发,同时存储数据结构简单,localStorage比较好;
如果数据结构比较复杂,同时对浏览器兼容性没什么要求,可以考虑使用indexedDB;
如果是在Service Workers中开发应用,只能使用indexedDB数据存储。
indexedDB数据库的使用目前可以直接在http协议下使用,这个和cacheStorage缓存存储必须使用https协议不一样
cacheStorage缓存页面,indexedDB数据库缓存数据,两者一结合而就可以实现百分百的离线开发
共同点:都是保存在浏览器端、且同源的
区别:
cookie数据始终在同源的http请求中携带(即使不需要),即cookie在浏览器和服务器间来回传递,而sessionStorage和localStorage不会自动把数据发送给服务器,仅在本地保存。cookie数据还有路径(path)的概念,可以限制cookie只属于某个路径下
存储大小限制也不同,cookie数据不能超过4K,同时因为每次http请求都会携带cookie、所以cookie只适合保存很小的数据,如会话标识。sessionStorage和localStorage虽然也有存储大小的限制,但比cookie大得多,可以达到5M或更大
数据有效期不同,sessionStorage:仅在当前浏览器窗口关闭之前有效;localStorage:始终有效,窗口或浏览器关闭也一直保存,因此用作持久数据;cookie:只在设置的cookie过期时间之前有效,即使窗口关闭或浏览器关闭
作用域不同,sessionStorage不在不同的浏览器窗口**享,即使是同一个页面;localstorage在所有同源窗口中都是共享的;cookie也是在所有同源窗口中都是共享的
web Storage支持事件通知机制,可以将数据更新的通知发送给监听者
web Storage的api接口使用更方便
感谢您耐心看到这里,希望有所收获!
如果不是很忙的话,麻烦点个star⭐【Github博客传送门】,举手之劳,却是对作者莫大的鼓励。
我在学习过程中喜欢做记录,分享的是自己在前端之路上的一些积累和思考,希望能跟大家一起交流与进步,更多文章请看【amandakelake的Github博客】
#前端/react
import { createStore } from 'redux';
import combinedReducer from '../reducer';
const store = createStore(combinedReducer);
export default store;
只引入一个thunk中间件
import { createStore,applyMiddleware } from 'redux';
import combinedReducer from '../reducer';
import thunk from 'redux-thunk';
const store = createStore(combinedReducer,applyMiddleware(thunk));
export default store;
换成redux-saga和logger中间件
import { createStore,applyMiddleware } from 'redux';
import createSagaMiddleware from 'redux-saga';
import logger from 'redux-logger';
import combinedReducer from '../reducer';
import rootSaga from '../saga';
// 生成saga中间件
const sagaMiddleware = createSagaMiddleware(rootSaga);
const store = createStore(combinedReducer,applyMiddleware(sagaMiddleware,logger));
export default store;
import { createStore,applyMiddleware } from 'redux';
import createSagaMiddleware from 'redux-saga';
import logger from 'redux-logger';
import { persistStore, persistCombineReducers } from 'redux-persist';
import storage from 'redux-persist/es/storage';
import combinedReducer from '../reducer';
import rootSaga from '../saga';
// 先定义persistConfig
const persistConfig = {
key: 'root',
storage,
whitelist: [
'user',
'root',
'cache',
],
};
// 合并后的总reducers
const persistReducer = persistCombineReducers(persistConfig,combinedReducer);
// saga中间件,如果在这里把rootSaga初始化,会出现点问题
const sagaMiddleware = createSagaMiddleware();
const store = createStore(persistReducer,applyMiddleware(sagaMiddleware,logger));
const persistor = persistStore(store);
// const configuerStore = {persistor, store};
const configuerStore = () => {
//在这里初始化
sagaMiddleware.run(rootSaga);
return { persistor, store };
};
export default configuerStore;
var obj = {
value: 1
};
function foo(o) {
o.value = 2;
console.log(o.value); //2
}
foo(obj);
console.log(obj.value) // 2var obj = {
value: 1
};
function foo(o) {
o = 2;
console.log(o); //2
}
foo(obj);
console.log(obj.value) // 1具体分析上面两个例子的不同,为什么都是“引用传递”,结果却不一样
引用传递,就是传递对象的引用,函数内部对参数的任何改变都会影响该对象的值,因为两者引用的是同一个对象
引用数据类型的值是保存在堆内存中的对象,JavaScript不允许直接访问堆内存中的位置,因此我们不能直接操作对象的堆内存空间。在操作对象时,实际上是在操作对象的引用而不是实际的对象。因此,引用类型的值都是按引用访问的。这里的引用,我们可以理解为保存在变量对象中的一个地址,该地址与堆内存的实际值相关联;
这样一来就好理解了,如果修改了这个“地址”,o = 2那么引用就完全被改写了
如果修改的是“地址”下面的属性,o.value = 2,那么更改的就是原来的引用数据本身

这图很经典,希望先试着解读每个箭头的含义
对象都是通过函数创建的,函数是对象(剪不断,理还乱,是离愁,别是一番滋味在心头)
Prototype每个函数都有这属性,有且仅有函数才拥有该属性
但有个例外:
// 用这个方法创建的函数是不具备prototype属性的
let fun = Function.prototype.bind()Prototype属性里面默认有一个属性constructor,对应着构造函数
constructor是一个公有的而且不可枚举的属性,一旦改写了函数的Prototype,新对象就没有这个属性了

__proto__每个对象都有一个隐藏属性__proto__,这个属性引用了创建这个对象的构造函数的原型
fn.__proto__ === Fn.prototype
__proto__ 将对象和原型连接起来组成了原型链
有三个要注意的地方
Object.prototype.__proto__ === null对象的原型的__proto__属性是null
Object.__proto__ === Function.prototype既然对象是函数创建的,那么对象的__proto__要指向创建它的构造函数的原型
Function的特殊性Function.__proto__ === Function.prototype函数也是被Function创建的,那么函数的__proto__也应该指向Function的原型,这是一个环形结构,函数的prototype和__proto__属性指向同一个对象
Function.prototype 和 Object.prototype 是两个特殊的对象,他们由引擎来创建
new除了以上Function.prototype 和 Object.prototype两个特殊对象,其他对象都是通过构造器 new 出来的
先看看new的实现过程
function create() {
// 创建一个新的对象
let obj = new Object();
// 取出第一个参数,该参数就是我们将会传入的构造函数
// arguments会被shift去除第一个参数
let Constructor = [].shift.call(arguments);
// 将obj的原型指向构造函数,此时obj可以访问构造函数原型中的属性
obj.__proto__ = Constructor.prototype;
// 改变构造函数的this的指向,使其指向obj
// 此时obj也可以访问构造函数中的属性了
let result = Constructor.apply(obj, arguments);
// 确保 new 出来的是个对象
// 返回的值是什么就return什么出来
return typeof result === 'object' ? result : obj
}所以平时更推荐使用字面量的方式创建对象,因为使用new Object()需要通过作用域链往上层层寻找Object
因为存在我们创建了一个同名的构造函数
Object()的可能,当调用Object()的时候,解析器需要顺着作用域链从当前作用域开始查找,如果在当前作用域找到了名为Object()的函数就执行,如果没找到,就继续顺着作用域链往上照,直到找到全局Object()构造函数为止
上面说__proto__ 将对象和原型连接起来组成了原型链
具体起来说就是:访问一个对象的属性时,先在基本属性中查找,如果没有,再沿着__proto__这条链向上找,这就是原型链
来看个例子
function Foo() {};
let f1 = new Foo();
f1.a = 1;
Foo.prototype.a = 10;
Foo.prototype.b = 20;
// 打印自身属性和原型属性
for(const item in f1) {
console.log(item)
}
// 打印自身属性
for (const item1 in f1) {
if (f1.hasOwnProperty(item1)) {
console.log(item1);
}
}
稍等一下,hasOwnProperty这个方法从哪找的?
f1和Foo.prototype都没有啊
很好,它从Object.prototype继承而来的,由于__proto__的存在,可以查找下面这条链条
f1 => Foo.prototype => Object.prototype
最终找到了Object.prototype上定义的各种原生方法

那我们平时看见的call、apply,还有数组的一些方法呢?
它们分别在Function.prototype,Array.prototype上面,我们日常使用的原生方法都继承于这几个对象,可以尝试去浏览器控制台打印这两看看
console.dir(Function.prototype);
console.dir(Array.prototype)原型、原型链我说清楚了吗?
参考资料
深入理解javascript原型和闭包(1)——一切都是对象 - 王福朋 - 博客园
深度解析原型中的各个难点 · Issue #2 · KieSun/Blog · GitHub
整篇promise的实现不是我原创,是我研究了群里某位大佬以及一些前人的实现,在自己理解的基础上,记录下来,本篇文章更多是为自己服务
注释我写成英文了(具体缘由暂时不说了)
相信有能力理解promise的程序员都有阅读英文的能力(暂时没有也建议掌握这项能力)
// three states
const PENGING = 'pending';
const RESOLVED = 'resolved';
const REJECTED = 'rejected';
// promise accepts a function argument that will execute immediately.
function MyPromise(fn) {
const _this = this;
_this.currentState = PENDING;
// the value of Promise
_this.value = undefined;
// To save the callback of `then`,only cached when the state of the promise is pending,
// for the new instance returned by `then`, at most one will be cached
_this.resolvedCallbacks = [];
_this.rejectedCallbacks = [];
_this.resolve = (value) => {
if (value instanceof MyPromise)
// If value is a Promise, execute recursively
return value.then(_this.resolve, _this.reject)
}
// execute asynchronously to guarantee the execution order
setTimeout(() => {
if (_this.currentState === PENDING) {
_this.currentState = RESOLVED;
_this.value = value;
_this.resolvedCallbacks.forEach(cb => cb());
}
})
}
_this.reject = (reason) => {
setTimeout(() => {
if (_this.currentState === PENGING) {
_this.currentState = REJECTED;
_this.value = reason;
_this.rejectedCallbacks.forEach(cb => cb());
}
})
}
// to solve the following problem
// new Promise(() => throw Error('error))
try {
fn(_this.resolve, _this.reject);
} catch (e) {
_this.reject(e);
}
}
MyPromise.prototype.then = function(onResolved, onRejected) {
const self = this;
// specification 2.2.7, `then` must return a new promise
let promise2;
// specification 2.2, both `onResolved` and `onRejected` are optional arguments
// it should be ignored if `onResolved` or `onRjected` is not a function, which implements the penetrate pass of it's value
// Promise.resolve(4).then().then((value) => console.log(value))
onResolved = typeof onResolved === 'function' ? onResolved : v => v;
onRejected = typeof onRejected === 'function' ? onRejected : r => throw r;
if (self.currentState === RESOLVED) {
return (promise2 = new MyPromise((resolve, reject) => {
// specification 2.2.4, wrap them with `setTimeout`, in order to insure that `onFulfilled` and `onRjected` execute asynchronously,
setTimeout(() => {
try {
let x = onResolved(self.value);
resolutionProcedure(promise2, x, resolve, reject);
} catch (reason) {
reject(reason);
}
});
}));
}
if (self.currentState === REJECTED) {
return (promise2 = new MyPromise((resolve, reject) => {
// execute `onRejected` asynchronously
setTimeout(() => {
try {
let x = onRejected(self.value);
resolutionProcedure(promise2, x, resolve, reject);
} catch (reason) {
reject(reason);
}
});
}))
}
if (self.currentState === PENDING) {
return (promise2 = new MyPromise((resolve, reject) => {
self.resolvedCallbacks.push(() => {
// Considering that it may throw error, wrap them with `try/catch`
try {
let x = onResolved(self.value);
resolutionProcedure(promise2, x, resolve, reject);
} catch (r) {
reject(r);
}
});
self.rejectedCallbacks.push(() => {
try {
let x = onRejected(self.value);
resolutionProcedure(promise2, x, resolve, reject);
} catch (r) {
reject(r);
}
})
}))
}
}
// specification 2.3
function resolutionProcedure(promise2, x, resolve, reject) {
// specification 2.3.1,`x` and `promise2` can't refer to the same object, avoiding the circular references
if (promise2 === x) {
return reject(new TypeError('Error'));
}
// specification 2.3.2, if `x` is a Promise and the state is `pending`, the promise must remain, If not, it should execute.
if (x instanceof MyPromise) {
if (x.currentState === PENDING) {
// call the function `resolutionProcedure` again to confirm the type of the argument that x resolves
// If it's a primitive type, it will be resolved again to pass the value to next `then`.
x.then((value) => {
resolutionProcedure(promise2, value, resolve, reject);
}, reject)
} else {
x.then(resolve, reject);
}
return;
}
// specification 2.3.3.3.3
// if both `reject` and `resolve` are executed, the first successful execution takes precedence, and any further executions are ignored
let called = false;
// specification 2.3.3, determine whether `x` is an object or a function
if (x !== null && (typeof x === 'object' || typeof x === 'function')) {
// specification 2.3.3.2, if can't get `then`, execute the `reject`
try {
// specification 2.3.3.1
let then = x.then;
// if `then` is a function, call the `x.then`
if (typeof then === 'function') {
// specification 2.3.3.3
then.call(x, y => {
if (called) return;
called = true;
// specification 2.3.3.3.1
resolutionProcedure(promise2, y, resolve, reject);
}, e => {
if (called) return;
called = true;
reject(e);
});
} else {
// specification 2.3.3.4
resolve(x);
}
} catch (e) {
if (called) return;
called = true;
reject(e);
}
} else {
// specification 2.3.4, `x` belongs to primitive data type
resolve(x);
}
}#前端/Javascript/个人理解总结
每个函数都是Function类的对象,而且都与其他引用类型一样具有属性和方法
由于函数是对象,所以函数名实际上也只是一个指向函数对象的指针而已;
所以使用不带圆括号的函数名是访问函数指针,而非调用函数
函数内部有两个特殊的对象
arguments和this
每个函数都包含两个属性
length和prototype
每个函数都包含两个非继承而来的方法
call和apply
Arguments是一个类数组对象,包含着所有传入函数中的形参,它还有一个名叫callee的属性,该属性是一个指针,指向拥有这个arguments对象的函数,也就是代指函数本身
先看一个递归函数(阶乘)
function factorial(num) {
if (num <= 1) {
return 1
} else {
return num * factorial(num-1)
}
}但函数的执行与函数名factorial紧紧的联系在了一起
比如说,由于factorial被绑定,func1()返回的就是0
var func1 = factorial;
func1()那么,如何解耦,就要用到callee了
function factorial(num) {
if (num <= 1) {
return 1
} else {
return num * arguments.callee(num-1)
}
}这样就完成了函数体代码与函数名的耦合
表示函数希望接收的命名参数的个数
不可枚举,用for-in无法发现
设置函数体内this对象的值
在JS中,用typeof来判断基本类型,instanceof判断引用类型
这是大家通常的解释
但是,你真的了解instanceof吗?
先看几个例子热一下身
console.log('aa' instanceof String) // 都说了判断引用类型,拿个基本类型出来坑爹么
let obj_string = new String('aa');
console.log(obj_string instanceof String)// 大家伙们都属于object
console.log({} instanceof Object)
console.log([] instanceof Array)
console.log([] instanceof Object)
console.log(function() {} instanceof Function)
console.log(function() {} instanceof Object)function Foo(){}
function BFoo(){}
Foo.prototype = new BFoo();//JavaScript 原型继承
let foo = new Foo();
console.log(foo instanceof Foo);
console.log(foo instanceof BFoo);其实上面三个例子都比较基础,相信都难不倒大家,再看几个复杂点的
console.log(String instanceof String);
console.log(Object instanceof Object);
console.log(Function instanceof Function);
console.log(Function instanceof Object);
function Foo(){}
function BFoo(){}
Foo.prototype = new BFoo();
console.log(Foo instanceof Function);
console.log(Foo instanceof Foo);打印看看,你全答对了吗?
是的话就不用看下去了,大神请回吧;
如果不是,那可以往下翻一翻
object instanceof constructor
instanceof 运算符用来测试一个对象在其原型链中是否存在一个构造函数的 prototype 属性。
先看MDN里面的解释,左边是要测试的对象,右边是构造函数
是否能在对象的原型链上(顺着__proto__一直往上找)找到构造函数的原型属性([constructor].prototype)
直接看实现代码吧
function instance_of(L, R) {//L 表示左边的object,R 表示右边的constructor
const R_P = R.prototype;// 取 R 的显式原型
L = L.__proto__;// 取 L 的隐式原型,并且可能会顺着原型链重新赋值
while (true) {
if (L === null)
return false;
if (R_P === L)// 这里重点:严格比较 true
return true;
L = L.__proto__;
}
}再祭出我们的原型链大杀器

划个重点
__proto__ 属性,指向了创建该对象的构造函数的原型__proto__ 属性,除了Object.prototype.__proto__ === nullObject(),它是由function生成的,所以它的__proto__属性指向了function的构造器Function的原型Function.prototypeFunction,它是唯一一个prototype和__proto__指向相同的对象Foo的__proto__属性指向function的构造器Function的原型Function.prototype,但是构造器的原型对象Foo.prototype的__proto__属性是直接指向Object.prototype对象的直接找一个例子来讲解,相信聪明的你们一定能够融会贯通,举一反三
console.log(Object instanceof Object); // true再看instanceof的实现代码
function instance_of(L, R) {//L 表示左边的object,R 表示右边的constructor
const R_P = R.prototype;// 取 R 的显式原型
L = L.__proto__;// 取 L 的隐式原型,并且可能会顺着原型链重新赋值
while (true) {
if (L === null)
return false;
if (R_P === L)// 这里重点:严格比较 true
return true;
L = L.__proto__;
}
}首先,左右表达式赋值
L = Object
R = Object
R_P = Object.prototype = Object.prototype
L = Object.__proto__ = Function.prototypeL !== null => R_P !== L
判断不为true
继续寻找L的原型链,准备下一轮赋值
L = Function.prototype.__proto__ = Object.prototypeL !== null => R_P === L
return true完美结束!
好了,其他的例子,请同学们自己去分析吧,你现在可以出去跟别人说:我真滴了解instanceof!
感谢您耐心看到这里,希望有所收获!
如果不是很忙的话,麻烦右上角点个star⭐,举手之劳,却是对作者莫大的鼓励。
我在学习过程中喜欢做记录,分享的是自己在前端之路上的一些积累和思考,希望能跟大家一起交流与进步,更多文章请看【amandakelake的Github博客】

function ArrayList() {
let array = [];
this.insert = (item) => {
array.push(item);
}
this.toString = () => {
return array.join();
}
// 先定义一个内部swap方法 用于交换数组中的两个值
// 注意,只能用在ArrayList内部
const swap = function(index1, index2) {
const aux = array[index1];
array[index1] = array[index2];
array[index2] = aux;
}
}比较任意两个相邻的项,如果第一个比第二个大,则交换顺序
this.bubbleSort = function() {
const len = array.length;
for (let i = 0; i < len; i++) {
for (let j = 0; j < len - 1; j++) {
if (array[j] > array[j + 1]) {
swap(j, j + 1);
}
}
}
}改进一下,从内循环中减去外循环中已跑过的轮数
this.modifiedBubbleSort = function () {
const len = array.length;
for (let i = 0; i < len; i++) {
// 看这里j < len - 1 - i
for (let j = 0; j < len - 1 - i; j++) {
if (array[j] > array[j + 1]) {
swap(j, j + 1);
}
}
}
}找到数组中最小的项并将其放到第一位,找到第二小的值,并将其放到第二位,依次……
this.selectionSort = function() {
const len = array.length;
let indexMin; // 最小值下标
for(let i = 0; i < len - 1; i++) {
// 假设当前遍历的是最小值
indexMin = i;
// 前面已经拍过序的不用再循环了
for(let j = i; j < len; j++) {
// 依次比较,交换最小值下标
if(array[indexMin] > array[j]) {
indexMin = j;
}
}
// 如果找到的最小值跟原来设定的最小值不一样,交换其值
if (i !== indexMin) {
swap(i, indexMin);
}
}
}每次只排序一个数组项,确定它应该插入到哪个位置
this.insertionSort = function () {
let j, temp;
// 默认第一项已经排序,所以从第二项开始
for (let i = 1; i < a.length; i++) {
// 辅助变量和值,存储当前下标和值
j = i;
temp = a[i];
// 一直跟前一项比较,直到找到正确的位置插入
while (j > 0 && a[j - 1] > temp) {
// 移到当前位置
a[j] = a[j - 1];
j--;
}
a[j] = temp;
}
} this.mergeSort = function () {
// 递归的停止条件
if (array.length == 1) {
return array;
}
// 中间值取整,分成两个小组
var middle = Math.floor(array.length / 2),
left = array.slice(0, middle),
right = array.slice(middle);
// 递归,对左右两部分数据进行合并排序
return merge(mergeSort(left), mergeSort(right));
}
function merge(left, right) {
var result = [];
while (left.length > 0 && right.length > 0) {
// 比较左边的数组的值是否被右边的小
if (left[0] < right[0]) {
result.push(left.shift());
} else {
result.push(right.shift());
}
}
return result.concat(left).concat(right);
}this.quickSort = function () {
if (array.length <= 1) {
return array;
}
// 取中间数作为基准索引,浮点数向下取整
var index = Math.floor(array.length / 2);
// 取得该值
var pivot = array.splice(index, 1);
// 分别建立左右空数组,作为push所用
var left = [];
var right = [];
for (var i = 0; i < array.length; i++) {
// 基准左边的传到左数组,右边的传到右数组
if (array[i] < pivot) {
left.push(array[i]);
} else {
right.push(array[i]);
}
}
// 不断递归重复比较
return quickSort(left).concat(pivot, quickSort(right));
}将每一个数据结构中的元素和我们要找的元素做比较
最低效的一种搜索算法
this.sequentialSearch = function(item) {
for(let i = 0; i < array.length; i++) {
if (item === array[i]) {
return i;
}
}
return -1;
}选择数组的中间值
如果选中值是待搜索值,那么算法执行完毕(值找到了)
如果待搜索值比选中值要小,则返回步骤1并在选中值左边的子数组中寻找
如果待搜索值比选中值要大,则返回步骤1并在选种值右边的子数组中寻找
this.binarySearch = function (item) {
// 先将数组进行排序
this.quickSort();
let low = 0, hight = array.length - 1, mid, element;
while (low <= high) {
// 取中间值
mid = Math.floor((low + high) / 2);
element = array[mid];
if (element < item) {
low = mid + 1;
} else if (element > item) {
high = mid - 1;
} else {
return mid;
}
}
return -1;
}A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.

