- OpenResty 简介
- Lua 简介
- Lua 环境搭建
- Lua编辑器选择
- OpenResty环境搭建
- 代码覆盖率
- Lua异常处理
- Emmy注解编写指南
- 如何篡改请求体
- 关于cjson如何处理空数组
- 协程
- Lua怎么异步调用自定义动态库
- 火焰图
OpenResty(也称为 ngx_openresty)是一个全功能的 Web 应用服务器。它打包了标准的 Nginx 核心,很 多的常用的第三方模块,以及它们的大多数依赖项。
通过揉和众多设计良好的 Nginx 模块,OpenResty 有效地把 Nginx 服务器转变为一个强大的 Web 应用服务 器,基于它开发人员可以使用 Lua 编程语言对 Nginx 核心以及现有的各种 Nginx C 模块进行脚本编程,构 建出可以处理一万以上并发请求的极端高性能的 Web 应用。
OpenResty 致力于将你的服务器端应用完全运行于 Nginx 服务器中,充分利用 Nginx 的事件模型来进行非 阻塞 I/O 通信。不仅仅是和 HTTP 客户端间的网络通信是非阻塞的,与MySQL、PostgreSQL、Memcached 以 及 Redis 等众多远方后端之间的网络通信也是非阻塞的。
因为 OpenResty 软件包的维护者也是其中打包的许多 Nginx 模块的作者,所以 OpenResty 可以确保所包含 的所有组件可以可靠地协同工作。
OpenResty 最早是雅虎**的一个公司项目,起步于 2007 年 10 月。当时兴起了 OpenAPI 的热潮,用于满 足各种 Web Service 的需求,就诞生了 OpenResty。在公司领导的支持下,最早的 OpenResty 实现从一开始 就开源了。最初的定位是服务于公司外的开发者,像其他的 OpenAPI 那样,但后来越来越多地是为雅虎** 的搜索产品提供内部服务。这是第一代的 OpenResty,当时的想法是,提供一套抽象的 web service,能够让 用户利用这些 web service 构造出新的符合他们具体业务需求的 Web Service 出来, 所以有些“meta web service”的意味,包括数据模型、查询、安全策略都可以通过这种 meta web service 来表达和配置。同时这种 web service 也有意保持 REST 风格。与这种概念相对应的是纯 AJAX 的 web 应用, 即 web 应用几乎都使用客户端 JavaScript 来编写,然后完全由 web service 让 web 应用“活”起来。用 户把 .html, .js, .css, .jpg 等静态文件下载到 web browser 中,然后 js 开始运行,跨域请求雅虎提供的 经过站长定制过的 web service,然后应用就可以运行起来。不过随着后来的发展,公司外的用户毕竟还是少数, 于是应用的重点是为公司内部的其他团队提供 web service,比如雅虎**的全能搜索产品,及其外围的一些 产品。从那以后,开发的重点便放在了性能优化上面。章亦春在加入淘宝数据部门的量子团队之后,决定对 OpenResty 进行重新设计和彻底重写,并把应用重点放在支持像量子统计这样的 web 产品上面,所以量子统计 3.0 开始也几乎完全是 web service 驱动的纯 AJAX 应用。
这是第二代的 OpenResty,一般称之为 ngx_openresty,以便和第一代基于 Perl 和 Haskell 实现的 OpenResty 加以区别。章亦春和他的同事王晓哲一起设计了第二代的 OpenResty。在王晓哲的提议下,选择基于 nginx 和 lua 进行开发。
为什么要取 OpenResty 这个名字呢?OpenResty 最早是顺应 OpenAPI 的潮流做的,所以 Open 取自“开放”之意, 而Resty便是 REST 风格的意思。虽然后来也可以基于 ngx_openresty 实现任何形式的 web service 或者传统的 web 应用。
也就是说 Nginx 不再是一个简单的静态网页服务器,也不再是一个简单的反向代理了。第二代的 openresty 致力于 通过一系列 nginx 模块,把nginx扩展为全功能的 web 应用服务器。
ngx_openresty 是用户驱动的项目,后来也有不少国内用户的参与,从 openresty.org 的点击量分布上看,国内和 国外的点击量基本持平。
ngx_openresty 目前有两大应用目标:
- 通用目的的 web 应用服务器。在这个目标下,现有的 web 应用技术都可以算是和 OpenResty 或多或少 有些类似,比如 Nodejs, PHP 等等。ngx_openresty 的性能(包括内存使用和 CPU 效率)算是最大的卖点之一。
- Nginx 的脚本扩展编程,用于构建灵活的 Web 应用网关和 Web 应用防火墙。有些类似的是 NetScaler。 其优势在于 Lua 编程带来的巨大灵活性。
ngx_openresty 从一开始就是公司实际的业务需求的产物。在过去的几年中的大部分开发工作也是由国内外 许多公司和个人的实际业务需求驱动的。这种模型在实践中工作得非常好,可以确保我们做的就是大家最迫 切需要的。在此过程中,慢慢形成了 ngx_openresty 的两大应用方向,也就是前面提到的那两大方向。是 我们的用户帮助我们确认了这两个方向,事实上,这并不等同于第一代 OpenResty 的方向,而是变得更加 底层和更加通用了。
开源精神的核心是分享而非追求流行。毕竟开源界不是娱乐圈,也不是时尚圈。如果我们的开源项目有越来 越多的人开始使用,只是一个“happy accident”,我们自然会很高兴,但这并不是我们真正追求的。
开放源码只是开源项目生命周期中的“万里长征第一步”,国内的许多开源项目止步于开放源码,而没有后 续投入长期的时间和精力去跟进响应用户的各种需求和反馈,但不免夭折。这种现象在国外的不少开源项目中也很常见。
国外成功的开源项目比较多,或许跟许多发达国家的程序员们的精神状态有关系。比如我认识的一些国外的 黑客都非常心思单纯,热情似火。他们在精神上的束缚非常少,做起事来多是不拘一格。有的人即便长期没 有工作单纯靠抵押和捐赠过活,也会不遗余力地投身于开源项目。而我接触到的国内许多程序员的精神负担 一般比较重,经济上的压力也比较大,自然难有“玩开源”的心思。
不过,国内也是有一些程序员拥有国外优秀黑客的素质的,而且他们通过网络和全球的黑客紧密联系在一起, 所以我们完全可以期待他们未来有振奋人心的产出。在互联网时代的今天,或许按国界的划分来讨论这样的 问题会变得越来越不合时宜。
这一章我们简要地介绍 Lua 语言的基础知识,特别地,我们会有意将讨论放置于 OpenResty 的上下文中。 同时,我们并不会回避 LuaJIT 独有的新特性;当然,在遇到这样的独有特性时,我们都会予以说明。 我们会关注各个语言结构和标准库函数对性能的潜在影响。在讨论性能相关的问题时,我们只会关心 LuaJIT 实现。
1993 年在巴西里约热内卢天主教大学(Pontifical Catholic University of Rio de Janeiro in Brazil)诞生 了一门编程语言,发明者是该校的三位研究人员,他们给这门语言取了个浪漫的名字——Lua,在葡萄牙语里代 表美丽的月亮。事实证明她没有糟蹋这个优美的单词,Lua 语言正如它名字所预示的那样成长为一门简洁、优 雅且富有乐趣的语言。
Lua 从一开始就是作为一门方便嵌入(其它应用程序)并可扩展的轻量级脚本语言来设计的,因此她一直遵从着 简单、小巧、可移植、快速的原则,官方实现完全采用 ANSI C 编写,能以 C 程序库的形式嵌入到宿主程序中。 LuaJIT 2 和标准 Lua 5.1 解释器采用的是著名的 MIT 许可协议。正由于上述特点,所以 Lua 在游戏开发、 机器人控制、分布式应用、图像处理、生物信息学等各种各样的领域中得到了越来越广泛的应用。其中尤以游 戏开发为最,许多著名的游戏,比如 Escape from Monkey Island、World of Warcraft、大话西游,都采用了 Lua 来配合引擎完成数据描述、配置管理和逻辑控制等任务。即使像 Redis 这样中性的内存键值数据库也提 供了内嵌用户 Lua 脚本的官方支持。
作为一门过程型动态语言,Lua 有着如下的特性:
- 变量名没有类型,值才有类型,变量名在运行时可与任何类型的值绑定;
- 语言只提供唯一一种数据结构,称为表(table),它混合了数组、哈希,可以用任何类型的值作为 key 和 value。 提供了一致且富有表达力的表构造语法,使得 Lua 很适合描述复杂的数据;
- 函数是一等类型,支持匿名函数和正则尾递归(proper tail recursion);
- 支持词法定界(lexical scoping)和闭包(closure);
- 提供 thread 类型和结构化的协程(coroutine)机制,在此基础上可方便实现协作式多任务;
- 运行期能编译字符串形式的程序文本并载入虚拟机执行;
- 通过元表(metatable)和元方法(metamethod)提供动态元机制(dynamic meta-mechanism),从而允许程序运行时 根据需要改变或扩充语法设施的内定语义;
- 能方便地利用表和动态元机制实现基于原型(prototype-based)的面向对象模型;
- 从 5.1 版开始提供了完善的模块机制,从而更好地支持开发大型的应用程序;
Lua 的语法类似 PASCAL 和 Modula 但更加简洁,所有的语法产生式规则(EBNF)不过才 60 几个。 熟悉 C 和 PASCAL 的程序员一般只需半个小时便可将其完全掌握。而在语义上 Lua 则与 Scheme 极为相似,她们 完全共享上述的 1 、3 、4 、6 点特性,Scheme 的 continuation 与协程也基本相同只是自由度更高。最引人注 目的是,两种语言都只提供唯一一种数据结构:Lua 的表和 Scheme 的列表(list)。正因为如此,有人甚至称 Lua 为“只用表的 Scheme”。
Lua 非常高效,它运行得比许多其它脚本(如 Perl、Python、Ruby)都快,这点在第三方的独立测评中得到了证实。 尽管如此,仍然会有人不满足,他们总觉得“嗯,还不够快!”。LuaJIT 就是一个为了再榨出一些速度的尝试,它 利用即时编译(Just-in Time)技术把 Lua 代码编译成本地机器码后交由 CPU 直接执行。LuaJIT 2 的测评报告表 明,在数值运算、循环与函数调用、协程切换、字符串操作等许多方面它的加速效果都很显著。凭借着 FFI 特性, LuaJIT 2 在那些需要频繁地调用外部 C/C++ 代码的场景,也要比标准 Lua 解释器快很多。目前 LuaJIT 2 已经支 持包括 i386、x86_64、ARM、PowerPC 以及 MIPS 等多种不同的体系结构。
LuaJIT 是采用 C 和汇编语言编写的 Lua 解释器与即时编译器。LuaJIT 被设计成全兼容标准的 Lua 5.1 语言, 同时可选地支持 Lua 5.2 和 Lua 5.3 中的一些不破坏向后兼容性的有用特性。因此,标准 Lua 语言的代码可以 不加修改地运行在 LuaJIT 之上。LuaJIT 和标准 Lua 解释器的一大区别是,LuaJIT 的执行速度,即使是其汇编 编写的 Lua 解释器,也要比标准 Lua 5.1 解释器快很多,可以说是一个高效的 Lua 实现。另一个区别是, LuaJIT 支持比标准 Lua 5.1 语言更多的基本原语和特性,因此功能上也要更加强大。
若无特殊说明,我们接下来的章节都是基于 LuaJIT 进行介绍的。
- Lua 官网链接:http://www.lua.org
- LuaJIT 官网链接:http://luajit.org
- Lua5.3 参考手册:http://cloudwu.github.io/lua53doc/manual.html
从 1.9.3.2 版本开始,OpenResty 正式对外同时公布维护了 Windows 版本,其中直接包含了编译好的最新版本 LuaJIT。由于 Windows 操作系统自身相对良好的二进制兼容性,使用者只需要下载、解压两个步骤即可。
打开 http://openresty.org,选择左侧的 Download 连接,这时候我们就可以下载最新版本的 OpenResty 版 本(例如笔者写书时的最新版本: ngx_openresty-1.9.7.1-win32.zip)。 下载本地成功后,执行解压缩,就能看到下图所示目录结构:
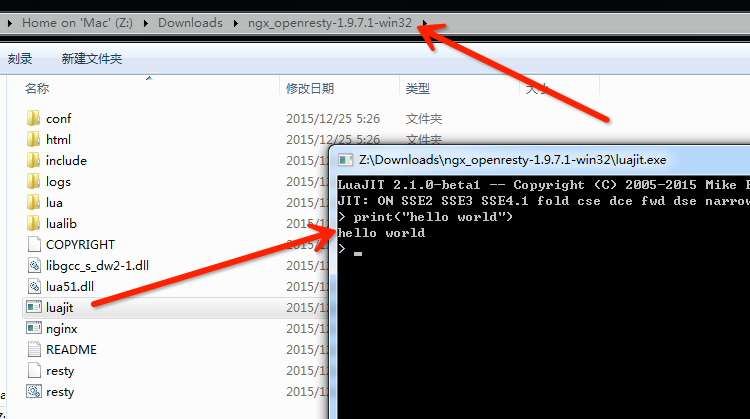
双击图中的 LuaJIT.exe,即可进入命令行模式,在这里我们就可以直接完成简单的 Lua 语法交互了。
到 LuaJIT 官网 http://luajit.org/download.html,查看当前最新开发版本,例如笔者写书时的最新版本: http://luajit.org/download/LuaJIT-2.1.0-beta1.tar.gz。
wget http://luajit.org/download/LuaJIT-2.1.0-beta1.tar.gz
tar -xvf LuaJIT-2.1.0-beta1.tar.gz
cd LuaJIT-2.1.0-beta1
make
sudo make install
大家都知道,在不同平台,可能都有不同的安装工具来简化我们的安装。为什么我们这给大家推荐的是源码这么原 始的方式?笔者为了偷懒么?答案:是的。当然还有另外一个原因,就是我们安装的是 LuaJIT 2.1 版本。
从实际应用性能表现来看,LuaJIT 2.1 虽然目前还是 beta 版本,但是生产运行稳定性已经很不错,并且在运行 效率上要比 LuaJIT 2.0 好很多(大家可自行爬文了解一下),所以作为 OpenResty 的默认搭档,已经是 LuaJIT 2.1 很久了。但是针对不同系统的工具包安装工具,他们当前默认绑定推送的都还是 LuaJIT 2.0,所以 这里就直接给出最符合我们最终方向的安装方法了。
由于LuaJIT 2.1 目前还是beta版本,所以在make install后,并没有进行luajit的符号连接,可以执行下面的指 令将luajit-2.1.0-beta1和luajit进行软连接,从而可以直接使用luajit命令
ln -sf luajit-2.1.0-beta1 /usr/local/bin/luajit
验证 LuaJIT 是否安装成功
luajit -v
LuaJIT 2.1.0-beta1 -- Copyright (C) 2005-2015 Mike Pall.
http://luajit.org/
如果想了解其他系统安装 LuaJIT 的步骤,或者安装过程中遇到问题,可以到 LuaJIT 官网查看: http://luajit.org/install.html
安装好 LuaJIT 后,开始我们的第一个 hello world 小程序。首先编写一个 hello.lua 文件,写入内容后, 使用 LuaJIT 运行即可。
cat hello.lua
print("hello world")
luajit hello.lua
hello world
一个好用趁手的编辑器可以为我们带来极大的工作效率提升,lua本身并不挑编辑器只是一个存文本. 但是如果有 代码提示,方便的goto跳转,在我们理解别人的代码效率上将会有极大的提升.
我从最初的记事本编辑,vi,到后来的UE自定义语法高亮和函数列表,以及scite等寻找和尝试过能找到的绝大部分 的lua编辑器. 我想在编辑器选择上面(linux下的不熟= =)应该比较有发言权.这里我主要讲我的环境是如何的.
选择过程我就不详述了,这里只讲解如果在你自己的windows上配置好ide
idea是一个java语言非常受好评的编辑器,但是并不是只支持java.
目前通过开放的插件编写已经支持绝大部分语言且使用的非常好用顺手,相信使用过的都会深有感受的.
其中Community版本是免费的,下载完后双击安装即可.
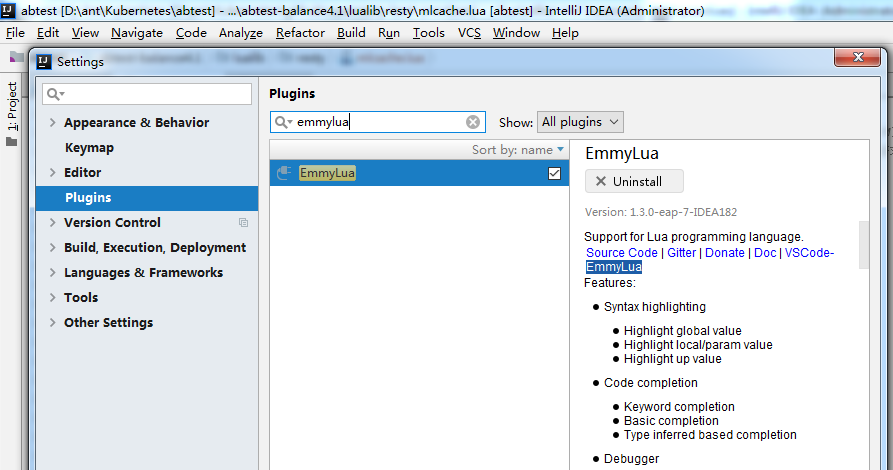
安装完成后打开File->Settings->Plugins在其中输入emmylua点击右边的install安装并重启idea
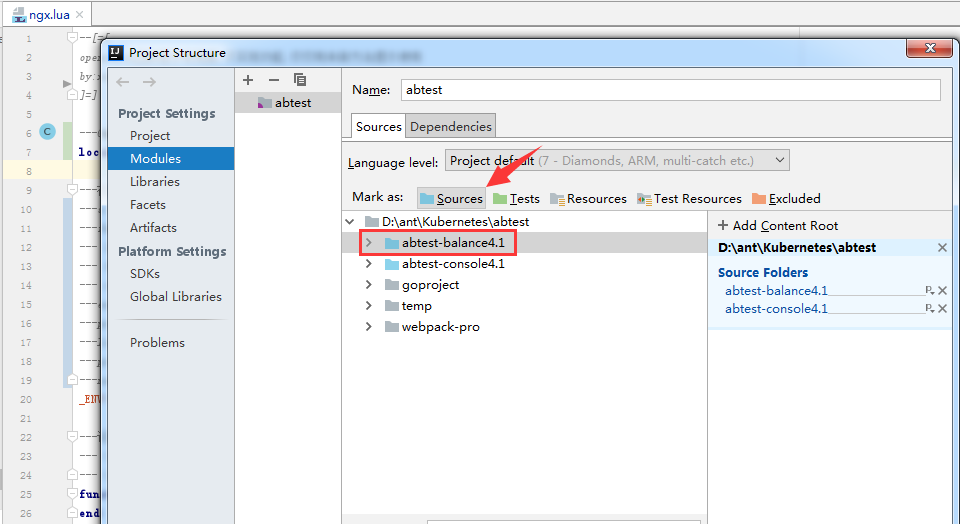
新建一个lua项目 在File->Project Structure里面配置好modules和lib,如下图.
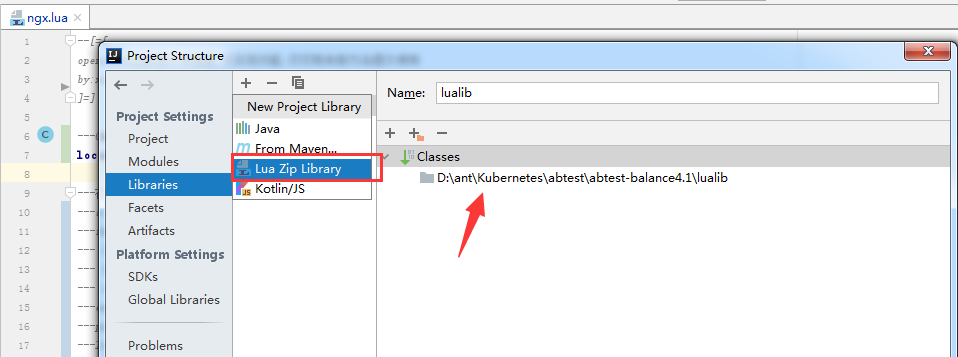
至此一个包含lua语法提示和调整的编辑器环境就配置好了.
有关emmylua的详细帮助文档看这里
你可以在Setting里面配置鼠标移动到方法上后一定时间自动弹出

也可以按Ctrl+q手动弹出,效果如下(= =目前我使用的版本文档中的换行显示还有问题)
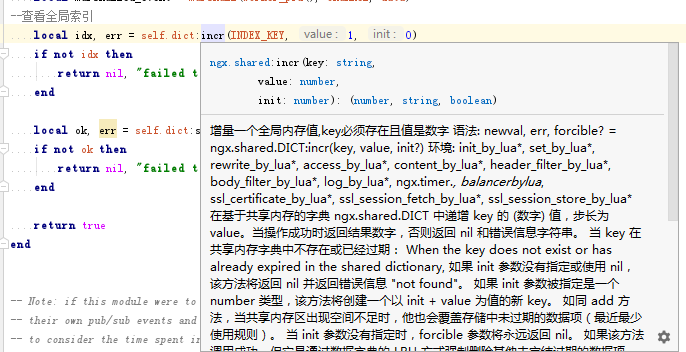
在任何已经被定义的方法上按住Ctrl+鼠标点击该方法就可以自动打开和跳转到方法定义上面,非常方便
在你输入识别的全局或者局部变量上面按点会自动出现可选方法做提示,不用记住所有的方法.
由于emmylua并没有自带openresty的库函数,所以我们需要自己写函数提示,这里我提供我自己写的供你们 下载 和丰富.请丢到你的lualib根目录中
下面是一个简单的库函数定义示例
---语法: pid = ngx.worker.pid()
---
---语法: set_by_lua*, rewrite_by_lua*, access_by_lua*, content_by_lua*, header_filter_by_lua*, body_filter_by_lua*, log_by_lua*, ngx.timer.*, init_by_lua*, init_worker_by_lua*
---
---这个函数返回一个Lua数字,它是当前 Nginx 工作进程的进程 ID (PID)。这个 API 比 ngx.var.pid 更有效,ngx.var.VARIABLE API 不能使用的地方(例如 init_worker_by_lua),该 API 是可以的。
---@return number
function ngx.worker.pid()
end
方法提示不一定要使用独立的文件定义,可以直接在库里面定义,如:
至于里面的含义就要去这里看和理解拉.
总之如果你的库都定义好了方法提示,在你理解源码的时候将会非常方便快速.相信我
你可以在你的 CentOS 系统中添加 openresty 仓库,这样就可以便于未来安装或更新我们的软件包(通过 yum update 命令)
- 运行下面的命令就可以添加openresty 的仓库:
sudo yum install yum-utils
sudo yum-config-manager --add-repo https://openresty.org/package/centos/openresty.repo
- 然后就可以像下面这样安装软件包,比如 openresty:
sudo yum install openresty
- 如果你想安装命令行工具 resty,那么可以像下面这样安装 openresty-resty 包:
sudo yum install openresty-resty
- 命令行工具 opm 在 openresty-opm 包里,而 restydoc 工具在 openresty-doc 包里头。 列出所有 openresty 仓库里头的软件包:
sudo yum --disablerepo="*" --enablerepo="openresty" list available
- 设置环境变量
为了后面启动 OpenResty 的命令简单一些,不用在 OpenResty 的安装目录下进行启动,我们设置环境变量来简化操作。 将 nginx 目录添加到 PATH 中。打开文件 /etc/profile, 在文件末尾加入export PATH=$PATH:/opt/openresty/nginx/sbin, 若你的安装目录不一样,则做相应修改。 注意:这一步操作需要重新加载环境变量才会生效, 可通过命令source /etc/profile或者重启服务器等方式实现。
这是一个重要的可量化指标,如果代码覆盖率很高,你就可以放心的修改代码,在发版本的时候也能睡个安稳觉。 否则就是拆东墙补西墙,陷入无尽的 bug 诅咒中。
那么在 OpenResty 里面如何看到代码覆盖率呢?其实很简单,使用 LuaCov 可以很方便的实现。
如果没有安装luarocks, 先安装之:
yum install luarocks -y
或者直接编译安装
--repos https://luarocks.github.io/luarocks
--wget https://luarocks.github.io/luarocks/releases/luarocks-3.1.3.tar.gz
--cd luarocks-x.x.x & configure & make & make install
我们先了解下 LuaCov,这是一个针对 Lua 脚本的代码覆盖率工具,通过 luarocks 来安装:
luarocks install luacov
如果你的项目比较大,建议安装
luarocks install cluacov
后者通过 C 代码加速了 luacov 的耗时操作。亲测能够快近一倍呢。
安装了 LuaCov 之后,还需要先配置一下。
在 OpenResty 里面使用 LuaCov,只用在 Nginx.conf 中增加 init_by_lua_block(只能放在 http 上下文 中)既可。
init_by_lua_block {
require 'luacov.tick'
jit.off()
}
这个 *_bolck 语法在较新的 OpenResty 版本中新引入,如果提示指令不存在,请使用最新的版本来测试。 抑或在 LuaCov 配置文件 .luacov 中加入 tick = true 这一行。效果是一样的。
另外,由于 LuaCov 的分析文件默认按照 100 条一批来写入的,如果你的代码量不大,可能就会不准确。 这时候可以设置 savestepsize = 2 来提高写入频率。
更多可用配置请访问 LuaCov 的配置文档: http://keplerproject.github.io/luacov/doc/modules/luacov.defaults.html
重新启动 OpenResty 后,LuaCov 就已经生效了。
你可以跑下单元测试,或者访问下 API 接口,在当前工作目录下,就会生成 luacov.stats.out 这个统计文件。 然后 cd 到这个目录下,运行:
luacov access-service.lua
这样就会生成只针对access-service.lua的可读性比较好覆盖率报告文件luacov.report.out。
需要注意的是,luacov 这个命令后面不用加任何的参数,这个在官方文档里面有说明,只是比较隐晦。
我们看下 luacov.report.out 里面的一个片段:
1 function get_config(mid, args)
13 local configs = {}
13 local res, err = red:hmget("client_".. mid, "tpl_id", "gid")
13 if err then
****0 return nil, err
end
end
代码前面的数字,代表的是运行的次数。而 ****0 很明确的指出这行代码没有被测试案例覆盖到。
在 luacov.report.out 的最后会有一个汇总的覆盖率报告:
可以看到,在我的这个单元测试里面,一共涉及到近 20 个代码文件。其中倒数第三个是我测试的 API 接口, 覆盖到的代码有 19 行,没有覆盖的有 3 行,所以代码覆盖率是 86.36%(19.0 / (19 + 3))。
最后有一个总的代码覆盖率是 28.3%,这个值在跑完所有单元测试后是有意义的,单跑一个是没有参考价值的, 因为很多基础函数可能并没有运行到。
各位看官注意,这样还有一个坑,一般的资料都没提及。如果你每次测试之后,发现覆盖 率老是偏低。 没错,你无需怀疑,我就碰到了这个问题。研究了很久,才搞清楚,是多进程导致的。
把nginx.conf里的工作进程数设为1就好了:
worker_processes 1;
语法很简单,不难掌握,学会以下几种就基本够用啦。
在类的前面添加@class注解
---@class JsonValue---@field _content tablelocal JsonValue = {}
不用定义类,直接用注解声明类的结构
---@class ModuleInfo
---@field modulelist string[]
---@field tradeCapable string|"y"
---@field tradeTime string|"20"
---
---@class SiteItem
---@field siteName string|"北京移动"
---@field siteUrl string|"sjzqdb.csc.com.cn"
---@field moduleInfo ModuleInfo---
---中台接口sites_status-100000.json的结构
---@class sites_status_100000
---@field data { siteItems: StatusSiteItem[]}
---
在函数前面添加@overload,@param, @return注解
---@overload fun(user_id: string, phone_num: string, now_time: number): number
---@param user_id string
---@param phone_num string
---@param now_time number
---@return stringlocal
function buildInitServiceAccessToken(user_id, phone_num, now_time)
在变量定义前面添加@type注解
---@type cjson
local cjson = require "cjson"
---@type ServicePara[]
local servers = {}
---@type {uri: string, level: number}[]
auth_agent_authority = {}
在函数定义前面添加@generic注解
---@generic T
---@param self T[] | table<string, T>
---@return fun():T
function table.values(self)
在函数定义前面添加@vararg注解
---@vararg string|number
function mine_logger.RUN_LOG(self, seq_no,fmt, ...)
详细文档参考emmy官网 https://emmylua.github.io/zh_CN/index.html
Lua没有try-catch这种高级的结构化异常处理, 但是lua却稍不留神随时都会抛出异常。例如下面几种情况:
- 空值nil稍不留神就会引发异常
- cjson.decode在json格式错误时引发异常
- Io.lines在找不到文件时引发异常
- ...
-
lua并不是没有异常处理, 他只能简单的处理异常, lua函数pcall/xpcall就是用来捕获异常的。
-
pcall只能简单的获得错误描述。
-
xpcall可以在错误时获取堆栈信息,相当于try-catch啦。
-
这两个函数的返回值是一样的, 都是(ok, value|error)
- ok为true时value为func的返回值。
- ok为false时value为错误信息。
需要特别注意的是, emmy中对这两个函数的声明不准确。这会导致你在调用时, 编辑器可能会标记为警告。
--- pcall的准确声明
---@generic T
---@param func fun(...) T
---@return boolean, T|string @ok, value|error
pcall(func, ...)
local ok, t = pcall(cjson.decode, str)
if not ok then
-- 发生异常时, ok = false, result为错误信息
ngx.log(ngx.ERR, t)
end
---@param callback fun(msg: string): string @参数为错误信息,返回值也是错误信息
---@param func fun(...) : T
---@return boolean, T|string @ok, value|error
xpcall(func, callback, ...)
---@param msg string
---@return string msg
local function catch_error(msg)
print("---catch_error---" .. tostring(msg), ":\n", debug.traceback())
return msg
end
local ok, t = xpcall(cjson.decode, catch_error, str)
if not ok then
-- 发生异常时, ok = false, result为错误信息
ngx.log(ngx.ERR, t)
end
- __add: 对+进行重载
- __sub: 对-进行重载
- __mul: 对*进行重载
- __div: 对/进行重载
- __unm: 对相反数进行重载
- __mod: 对%进行重载
- __pow: 对^进行重载
- __concat: 对连接操作符进行重载
- __eq: 对==进行重载
- __lt: 对<进行重载
- __le: 对<=进行重载
- __tostring: 类似于C++中对<<的重载 只要做了该重载,在使用print时就会使用对应的函数做处理后再输出
各位看官注意到没, 一个坑爹的问题,不能重载大于>和大于等>=操作符。
在openresty-lua中有2套正则表达式,一个是lua自带的,一个是nginx的ngx.lua,他们的主要区别如下:
- Lua正则不标准的, ngx.re是标准的(更通用, 方便移植)
- lua正则任何时候都能用, ngx.re有限制(在init阶段不能用)
- ngx.re正则支持缓存,效率更高。
- Lua正则转义符为”%”, ngx.re为”\”
- Lua正则虽然不标准,确是lua字符串处理最强大的部分,是你必须掌握的部分。
正则表达式由元字符按照规则(语法)组成。lua中的特殊字符是%.^$+-*?,一共12个。它们和一般字符按规则 构成了lua的正则表达式。
备注
- lua不支持分组后面接重复词(+*?),对于复杂的匹配可以用find+循环手动处理。
- %bxy跟预定义字符集有区别,前者在[...]仍保持原意,后者则失去特殊意义
- 上表中是lua对正则的支持,其他的正则如命名组,重复{m, n}等并不能在lua中用。注意转义字符是%不是
string.find(str, "%.")
千万注意正则里的%, 因为lua正则"."为保留字符, 必须转义。
string.match(filename, "(%.%w+)$")
string.match("127.0.0.1:6379", "(%d+%.%d+%.%d+%.%d+):(%d+)")
在OpenResty中,同时存在两套正则表达式规范:Lua语言的规范和Nginx的规范;即使您对Lua语言中的规范 非常熟悉,我们仍不建议使用Lua中的正则表达式。
- 因为Lua中正则表达式的性能并不如Nginx中的正则表达式优秀;
- Lua中的正则表达式并不符合POSIX规范,而Nginx中实现的是标准的POSIX规范,后者明显更具备通用性。
Lua中的正则表达式与 Nginx 中的正则表达式相比,有 5%-15%的性能损失,而且 Lua 将表达式编译成 Pattern 之 后,并不会将 Pattern 缓存,而是每此使用都重新编译一遍,潜在地降低了性能。Nginx中的正则表达式可以通过 参数缓存编译过后的 Pattern ,不会有类似的性能损失。
o 选项参数用于提高性能,指明该参数之后,被编译的 Pattern 将会在 worker 进程中缓存,并且被当前 worker 进程的每次请求所共享。 Pattern 缓存的上限值通过 lua_regex_cache_max_entries 来修改。
Nginx 中的正则表达式包括ngx.re.match、ngx.re.find、ngx.re.gmatch、ngx.re.sub、ngx.re.gsub,这5个函数, 函数的作用域都是:
- init_worker_by_lua*,
- set_by_lua*,
- rewrite_by_lua*,
- access_by_lua*,
- content_by_lua*,
- header_filter_by_lua*,
- body_filter_by_lua*,
- log_by_lua*, ngx.timer.*,
- balancer_by_lua*,
- ssl_certificate_by_lua*,
- ssl_session_fetch_by_lua*,
- ssl_session_store_by_lua*
语法:captures, err = ngx.re.match(subject, regex, options?, ctx?, res_table?)
只有第一次匹配的结果被返回,如果没有匹配,则返回nil;或者匹配过程中出现错误时,也会返回nil,此时错误 信息会被保存在err中。
当匹配的字符串找到时,一个Lua table captures会被返回,captures[0]中保存的就是匹配到的字串, captures[1]保存的是用括号括起来的第一个子模式的结果,captures[2]保存的是第二个子模式的结果, 依次类似。
参数:options
| a | 锚定模式,只从头开始匹配. |
| d | DFA模式,或者称最长字符串匹配语义,需要PCRE 6.0+支持. |
| D | 允许重复的命名的子模式,该选项需要PCRE 8.12+支持,例如local m = ngx.re.match("hello, world", "(?<named>\w+), (?<named>\w+)", "D") <br/> — m["named"] == {"hello", "world"} |
| i | 大小写不敏感模式. |
| j | 启用PCRE JIT编译, 需要PCRE 8.21+ 支持,并且必须在编译时加上选项–enable-jit,为了达到最佳性能,该选项总是应该和’o’选项搭配使用. |
| J | 启用PCRE Javascript的兼容模式,需要PCRE 8.12+ 支持. |
| m | 多行模式. |
| o | 一次编译模式,启用worker-process级别的编译正则表达式的缓存. |
| s | 单行模式. |
| u | UTF-8模式. 该选项需要在编译PCRE库时加上–enable-utf8 选项. |
| U | 与”u” 选项类似,但是该项选禁止PCRE对subject字符串UTF-8有效性的检查. |
| x | 扩展模式 |
可选参数:ctx
可选参数ctx可以传入一个Lua Table,传入的Lua Table可以是一个空表,也可以是包含pos字段的Lua Table。如果 传入的是一个空的Lua Table,那么,ngx.re.match将会从subject字符串的起始位置开始匹配查找,查找到匹配串后,修改 pos的值为匹配字符串的下一个位置的值,并将pos的值保存到ctx中,如果匹配失败,那么pos的值保持不变;如果传入的是 一个非空的Lua Table,即指定了pos的初值,那么ngx.re.match将会从指定的pos的位置开始进行匹配,如果匹配成功了, 修改pos的值为匹配字符串的下一个位置的值,并将pos的值保存到ctx中,如果匹配失败,那么pos的值保持不变。
示例:
local ctx = {pos = 1}
local url = "https://www.baidu.com/s?wd=site%3Ahuangxiaobai.com&iq=site%3Abaidu.com&ie=utf-8"
local capture, err = ngx.re.match(url, "site([^&]+)", "jo", ctx)
print(capture)
print(ctx)
输出:
{"0":"site%3Ahuangxiaobai.com","1":"%3Ahuangxiaobai.com"}
{"pos":51}
结论 :
- ngx.re.match有点类似PHP中的preg_match,第一次匹配后 将会停止搜索。
- 任何时刻带上参数"jo"
- 如无匹配或匹配错误,capture返回nil,使用 if not capture 判断是否匹配即可。
语法: from, to, err = ngx.re.find(subject, regex, options?, ctx?, nth?)
该方法与ngx.re.match方法基本类似,不同的地方在于ngx.re.find返回的是匹配的字串的起始位置索引和结束位置 索引,如果没有匹配成功,那么将会返回两个nil,如果匹配出错,还会返回错误信息到err中。
该方法相比ngx.re.match,不会创建新的Lua字符串,也不会创建新的Lua Table,因此,该方法比ngx.re.match更加 高效,因此,在可以使用ngx.re.find的地方应该尽量使用。
参数options和 参数 ctx ,参考ngx.re.match
参数:nth
可以指定返回第几个子模式串的起始位置和结束位置的索引值,默认值是0,此时将会返回匹配的整个字串; 如果nth等于1,那么将返回第一个子模式串的始末位置的索引值;如果nth等于2,那么将返回第二个子模式串的始末位置的 索引值,依次类推。如果nth指定的子模式没有匹配成功,那么将会返回两个nil
结论:
- ngx.re.match有点类似PHP中的preg_match,第一次匹配后 将会停止搜索。
- 任何时刻带上参数"jo"
- 如无匹配或匹配错误,from、to返回nil,使用 if not from 判断是否匹配即可。
- 性能优越于 ngx.re.match
语法:iterator, err = ngx.re.gmatch(subject, regex, options?)
与ngx.re.match相似,区别在于该方法返回的是一个Lua的迭代器,这样就可以通过迭代器遍历所有匹配的结果。 如果匹配失败,将会返回nil,如果匹配出现错误,那么还会返回错误信息到err中。
示例:
local url = "https://www.baidu.com/s?wd=sit1e%3Ahuangxiaobai.com&iq=sit1e%3Abaidu.com&ie=utf-8"
local iterator, err = ngx.re.gmatch(url, "site([^&]+)", "jo")
if iterator then
while true do
local it, err = iterator()
if not it then break end
print(it)
end
end
输出:
{"0":"site%3Ahuangxiaobai.com","1":"%3Ahuangxiaobai.com"}
{"0":"site%3Abaidu.com","1":"%3Abaidu.com"}
注意:ngx.re.gmatch返回的迭代器只能在一个请求所在的环境中使用,就是说,我们不能把返回的迭代器赋值给 持久存在的命名空间(比如一个Lua Packet)中的某一个变量。
结论:
- ngx.re.match有点类似PHP中的preg_match_all
- 任何时刻带上参数"jo"
- 如无匹配或匹配错误,iterator 返回nil,使用 if not iterator 判断是否匹配即可。
- ngx.re.gmatch返回的迭代器只能在一个请求所在的环境中使用,就是说,我们不能把返回的迭代器赋值给持久存在的 命名空间
语法:newstr, n, err = ngx.re.sub(subject, regex, replace, options?)
该方法主要实现匹配字符串的替换,会用replace替换匹配的字串,replace可以是纯字符串,也可以是使用$0, $1等子模式串的形式,ngx.re.sub返回进行替换后的完整的字符串,同时返回替换的总个数;options选项, 与ngx.re.match中的options选项是一样的。
示例:
local url = "https://www.baidu.com/s?wd=site%3Ahuangxiaobai.com&iq=site%3Abaidu.com&ie=utf-8"
local newStr, n, err = ngx.re.sub(url, "site([^&]+)", "[$0][$1]", "jo")
print(newStr)
输出:
https://www.baidu.com/s?wd=[site%3Ahuangxiaobai.com][%3Ahuangxiaobai.com]&iq=site%3Abaidu.com&ie=utf-8
结论:
- 也只仅匹配一次,第一次匹配后 将会停止搜索。
- 如无匹配,则newstr返回,和subject相同的字符串。
- $0表示整个匹配的子串,$1表示第一个子模式匹配的字串,以此类推。
- 可以用大括号{}将相应的0,1,2...括起来,以区分一般的数字。
- 如果想在replace字符串中显示$符号,可以用$进行转义(不要用反斜杠$对美元符号进行转义,这种方法不会 得到期望的结果)
- 如果replace是一个函数,那么函数的参数是一个"match table", 而这个"match table"与ngx.re.match 中的返回值captures是一样的,replace这个函数根据"match table"产生用于替换的字符串。
例如:
local newstr, n, err = ngx.re.sub("hello, 1234", "[0-9]", "${0}00")
例如:
local newstr, n, err = ngx.re.sub("hello, 1234", "[0-9]", "$")
例如:
local replace = function(m)
return "["..m[0].."]["..m[1].."]"
end
local url = "https://www.baidu.com/s?wd=site%3Ahuangxiaobai.com&iq=site%3Abaidu.com&ie=utf-8"
local newStr, n, err = ngx.re.sub(url, "site([^&]+)", replace, "jo")
print(newStr)
输出:
https://www.baidu.com/s?wd=[site%3Ahuangxiaobai.com][%3Ahuangxiaobai.com]&iq=site%3Abaidu.com&ie=utf-8
语法:
newstr, n, err = ngx.re.gsub(subject, regex, replace, options?)
该方法与ngx.re.sub是类似的,但是该方法进行的是全局替换。
示例:
local replace = function(m)
return "["..m[0].."]["..m[1].."]"
end
local url = "https://www.baidu.com/s?wd=site%3Ahuangxiaobai.com&iq=site%3Abaidu.com&ie=utf-8"
local newStr, n, err = ngx.re.gsub(url, "site([^&]+)", replace, "jo")
print(newStr)
输出:
https://www.baidu.com/s?wd=[site%3Ahuangxiaobai.com][%3Ahuangxiaobai.com]&iq=[site%3Abaidu.com][%3Abaidu.com]&ie=utf-8
结论:
- 用法同ngx.re.sub,只不过该方法进行的是全局替换
Lua 里面的函数必须放在调用的代码之前,下面的代码是一个常见的错误:
-- test.lua 文件
local i = 100
i = add_one(i)
function add_one(i)
return i + 1
end
我们将得到如下错误:
luajit test.lua
luajit: test.lua:2: attempt to call global 'add_one' (a nil value)
stack traceback:
test.lua:2: in main chunk
[C]: at 0x0100002150
为什么放在调用后面就找不到呢?原因是 Lua 里的 function 定义本质上是变量赋值,即
function foo() ... end
等价于
foo = function () ... end
因此在函数定义之前使用函数相当于在变量赋值之前使用变量,Lua 世界对于没有赋值的变量,默认都是 nil, 所以这里也就产生了一个 nil 的错误。
一般地,由于全局变量是每个请求的生命期,因此以此种方式定义的函数的生命期也是每个请求的。为了避免 每个请求创建和销毁 Lua closure 的开销,建议将函数的定义都放置在自己的 Lua module 中,例如:
-- my_module.
lualocal _M = {_VERSION = "0.1"}
function _M.foo()
-- your code
print("i'm foo")
end
return _M
然后,再在 content_by_lua_file 指向的 .lua 文件中调用它:
local my_module = require "my_module"
my_module.foo()
因为 Lua module 只会在第一次请求时加载一次(除非显式禁用了 lua_code_cache 配置指令),后续请求便可 直接复用。
缓存是一个大型系统中非常重要的一个组成部分。在硬件层面,大部分的计算机硬件都会用缓存来提高速度, 比如 CPU 会有多级缓存、RAID 卡也有读写缓存。在软件层面,我们用的数据库就是一个缓存设计非常好的 例子,在 SQL 语句的优化、索引设计、磁盘读写的各个地方,都有缓存,建议大家在设计自己的缓存之前, 先去了解下 MySQL 里面的各种缓存机制,感兴趣的可以去看下High Performance MySQL这本非常有价值的 书。
一个生产环境的缓存系统,需要根据自己的业务场景和系统瓶颈,来找出最好的方案,这是一门平衡的艺术。
一般来说,缓存有两个原则。一是越靠近用户的请求越好,比如能用本地缓存的就不要发送 HTTP 请求,能 用 CDN 缓存的就不要打到 Web 服务器,能用 Nginx 缓存的就不要用数据库的缓存;二是尽量使用本进程 和本机的缓存解决,因为跨了进程和机器甚至机房,缓存的网络开销就会非常大,在高并发的时候会非常明 显。
我们介绍下在 OpenResty 里面,有哪些缓存的方法。
我们看下面这段代码:
function get_from_cache(key)
local cache_ngx = ngx.shared.my_cache
local value = cache_ngx:get(key)
return value
end
function set_to_cache(key, value, exptime)
if not exptime then
exptime = 0
end
local cache_ngx = ngx.shared.my_cache
local succ, err, forcible = cache_ngx:set(key, value, exptime)
return succ
end
这里面用的就是 ngx shared dict cache。你可能会奇怪,ngx.shared.my_cache 是从哪里冒出来的?没错, 少贴了 nginx.conf 里面的修改:
lua_shared_dict my_cache 128m;
如同它的名字一样,这个 cache 是 Nginx 所有 worker 之间共享的,内部使用的 LRU 算法(最近最少使用) 来判断缓存是否在内存占满时被清除。
直接复制下春哥的示例代码:
local _M = {}
-- alternatively:
local lrucache = require "resty.lrucache.pureffi"
local lrucache = require "resty.lrucache"
-- we need to initialize the cache on the Lua module level so that
-- it can be shared by all the requests served by each nginx worker process:local c = lrucache.new(200) -- allow up to 200 items in the cache
if not c then
return error("failed to create the cache: " .. (err or "unknown"))
end
function _M.go()
c:set("dog", 32)
c:set("cat", 56)
ngx.say("dog: ", c:get("dog"))
ngx.say("cat: ", c:get("cat"))
c:set("dog", { age = 10 }, 0.1) -- expire in 0.1 sec
c:delete("dog")
end
return _M
可以看出来,这个 cache 是 worker 级别的,不会在 Nginx wokers 之间共享。并且,它是预先分配好 key 的 数量,而 shared dict 需要自己用 key 和 value 的大小和数量,来估算需要把内存设置为多少。
shared.dict 使用的是共享内存,每次操作都是全局锁,如果高并发环境,不同 worker 之间容易引起竞争。所 以单个 shared.dict 的体积不能过大。lrucache 是 worker 内使用的,由于 Nginx 是单进程方式存在,所以永 远不会触发锁,效率上有优势,并且没有 shared.dict 的体积限制,内存上也更弹性,但不同 worker 之间数据 不同享,同一缓存数据可能被冗余存储。
你需要考虑的,一个是 Lua lru cache 提供的 API 比较少,现在只有 get、set 和 delete, 而 ngx shared dict 还可以 add、replace、incr、get_stale(在 key 过期时也可以返回之前的值)、 get_keys(获取所有 key,虽然不推荐,但说不定你的业务需要呢);第二个是内存的占用, 由于 ngx shared dict 是 workers 之间共享的,所以在多 worker 的情况下,内存占用比较少。
ngx.timer.at 会创建一个 Nginx timer。在事件循环中,Nginx 会找出到期的 timer,并在一个独立的协程中 执行对应的 Lua 回调函数。 有了这种机制,ngx_lua 的功能得到了非常大的扩展,我们有机会做一些更有想象力的功 能出来。比如 批量提交和 cron 任务。随便一提,官方的 resty-cli 工具,也是基于 ngx.timer.at 来运行指定的 代码块。
比较典型的用法,如下示例:
local delay = 5
-- do some routine job in Lua just like a cron job
local handler = function (premature)
if premature then
return
end
local ok, err = ngx.timer.at(delay, handler)
if not ok then
ngx.log(ngx.ERR, "failed to create the timer: ", err)
return
end
end
local ok, err = ngx.timer.at(delay, handler)
if not ok then
ngx.log(ngx.ERR, "failed to create the timer: ", err)
return
end
从示例代码中我们可以看到,ngx.timer.at 创建的回调是一次性的。如果要实现“定期”运行,需要在回调函数 中重新创建 timer 才行。不过当前主线上的 OpenResty 已经引入了新的 ngx.timer.every 接口,允许直接创建 定期执行的 timer。
ngx.timer.at 的 delay 参数,指定的是以秒为单位的延迟触发时间。跟 OpenResty 的其他函数一样,指定的时 间最多精确到毫秒。如果你想要的是一个当前阶段结束后立刻执行的回调,可以直接设置 delay 为 0。 handler 回调第一个参数 premature,则是用于标识触发该回调的原因是否由于 timer 的到期。Nginx worker 的退出, 也会触发当前所有有效的 timer。这时候 premature 会被设置为 true。回调函数需要正确处理这一参数(通常 直接返回即可)。
需要特别注意的是:有一些 ngx_lua 的 API 不能在这里调用,比如子请求、ngx.req.*和向下游输出 的 API(ngx.print、ngx.flush 之类),原因是这些调用需要依赖具体的请求。但是 ngx.timer.at 自身的运行, 与当前的请求并没有关系的。
再说一遍,ngx.timer.at 的执行是在独立的协程里完成的。千万不能忽略这一点。有人可能会犯这样的错误:
local tcpsock = create_tcp_client() -- 创建一个 cosocket 连接
local ok, err = ngx.timer.at(delay, function()
tcpsock:send() -- bad request!
end)
cosocket 跟某个特定的 ngx_http_request_t* 绑定在一起的。虽然由于闭包,在回调函数中我们依旧可 以访问 tcpsock,但整个上下文已经不一样了。
下面几行代码演示了如何获得请求头sign_token
local headers = ngx.req.get_headers()
local sign_token = Headers["sign_token"]
-- 或者local sign_token = headers.sign_token
特别提醒:一般情况下, sign_token是一个字符串。但是如果客户端重复填写了该头,该字段就是一个 类型为string[]的table, 这时你可能须要从中选择一个作为正确的请求头。
下面几行代码演示了如何设置自定义回应头sign_token
ngx.header["sign_token"] = value
--或者 ngx.header.sign_token = value
特别提醒:自定义回应头被设置, 但是客户端收到的头变成了”sign-token”。因为下划线”_”会被默认 替换成连接符”-”, 可以通过如下指令关闭这个替换:
lua_transform_underscores_in_response_headers off;
建议http头名称中可以用减号”-”,不要用下划线。
特别注意:关闭之后产生了副作用:
ngx.header.content_type这样的语法不能用了, 只能用ngx.header[“Content-Type”] = content_type这样的语法了。
local cookie_str = ngx.req.get_headers()["cookie"]
local user_id = ngx.var.cookie_user_id
再次特别提醒:设置了如下语句
lua_transform_underscores_in_response_headers off;
之后, ngx.header.set_cookie这样的语法不能用了。
- 设置单行cookie
ngx.header['Set-Cookie'] = str
- 设置多行cookie
ngx.header['Set-Cookie'] = {'a=32; path=/', 'b=4; path=/'}
- 读取请求包体
普通请求体可以通过ngx.req.get_body_data获得,大包体须从文件读取。
ngx.req.read_body()
local req_filename
local body_str = ngx.req.get_body_data()
if not body_str then
req_filename = ngx.req.get_body_file()
if req_filename then
--- 从文件读包体
local f = io.open(file_name, "r")
body_str = f:read("*all")
f:close()
end
end
--- 确保body_str非nil
body_str = body_str or ""
-
修改请求体
- 直接调用ngx.req.set_body_data(经实测该函数似乎没有data大小限制,也不写入文件)
- 调用ngx.req.append_body,当包体太大时会自动写入文件。推荐该方法:
body_str = do_something(body_str) ngx.req.init_body() ngx.req.append_body(body_str) ngx.req.finish_body()
空数组在lua中就是一个空table, 转化成json时就成了空对象{}。
这通常不是我们期望的结果,对象通常是不会空的。当成空数组处理,适应性更广。
- 将所有的空table都当成空数组处理
local cjson = require "cjson"
cjson.encode_empty_table_as_object(false)
该设置全局生效,之后所有的空table都会当成空数组。
如果你确任系统里不会有空对象,这个方法最省事。
- 指定某table就是数组
setmetatable(root.data, cjson.array_mt)
- 当某table为空时指定其为空数组
if #root.data == 0 then
setmetatable(root.data, cjson.empty_array_mt)
End
- lua协程封装得好啊,原汁原味。
- 太原始了,连个协程调度器都没有。
- Lua协程最大的优点,它本身就是一个生产者-消费者模型。
- 协程创建之后,通常有一个消费者循环用resume去调度它,同时接收其发送的结果。
- 协程函数内,通常有一个生产者循环用yield切换协程,同时发送结果给其调度者。
基本语法
| 方法 | 描述 |
|---|---|
| co = oroutine.create(func) | 创建 coroutine,返回 coroutine, 参数是一个函数,当和 resume 配合使用的时候就唤醒函数调用 |
| ok, res1, res2, ... = coroutine.resume(co, ...) | 重启 coroutine,和 create 配合使用 |
| coroutine.yield(...) | 挂起 coroutine,将 coroutine 设置为挂起状态,这个和 resume 配合使用能有很多有用的效果 |
| coroutine.status | 查看 coroutine 的状态 dead,suspended,running |
| fun = coroutine.wrap(func) | 创建 coroutine,返回一个函数,一旦你调用这个函数,就进入 coroutine |
| coroutine.running | 返回正在跑的 coroutine,一个 coroutine 就是一个线程,当使用running的时候,就是返回一个 corouting 的线程号 |
参考用例: lua怎么异步调用自定义动态库
- 这个协程封装的好啊, 它就像线程,不用关心调度问题。
- 它更像Future, 创建之后wait结果就行了。
- 方便创建多个协程同时运行。
- 创建的的子协程依附于父协程,父协程退出,它们也退出。这一点不同于线程和进程。
相关API
| 方法 | 描述 |
|---|---|
| co1 = ngx.thread.spawn(func, ...) | 创建协程, 协程即开始运行 |
| ok, res1, res2, ... = ngx.thread.wait(co1, co2, ...) | 等待结果, 只有直属父协程才能等待它的子轻线程, 否则将会有Lua异常抛出。 |
| ok, err = ngx.thread.kill(co) | 结束协程, 成功时返回一个 true ,其他情况则返回一个错误字符描述信息。 |
| ngx.sleep(seconds) | 切换协程, 时间可以精确到 0.001 秒 (毫秒)。自版本 0.7.20 开始,0 也 可以作为时间参数被指定。 |
location /thread001 {
content_by_lua_block {
local get_response(host, port)
local sock = ngx.socket.tcp()
local ok, err = sock:connect(host, port)
if not ok then
return nil, err
end
local data, err = sock:receive()
if not data then
return nil, err
end
return data
end
local t1 = ngx.thread.spawn(get_response, "lua.org", 8080)
local t2 = ngx.thread.spawn(get_response, "nginx.org", 8080)
local ok, res1, res2 = ngx.thread.wait(t1, t2)
ngx.say(res1 .. res2)
}
}
首先,重要的事情说三遍:
1. nginx_lua所有调用都不能阻塞
2. nginx_lua所有调用都不能阻塞
3. nginx_lua所有调用都不能阻塞
lua功能很弱,实现不了太复杂的功能。所以自定义动态库,然后由lua来调用, 似乎是个办法。
是的,一般是没问题的。 但是,如果自定义的业务不能立即完成,那该如何呢?
呵呵,无解。
呜呼哉,也不是一点办法都没有。瞧瞧,lua5.2开始有了新一个函数lua_yieldk,专为解决 此问题而来,你不访试试(可惜的是,Openresty默认的解释器是lua5.1,这个函数暂不方便使用)。
嗯嗯,好办法肯定是没有了,那就给你个矬点办法吧:轮询。就是在动态库里提供一个问函数 (也叫轮询函数), 在lua里通过协程不停地调它,问它完成没有,直至完成为止。
-- 假设自定义动态库的轮询函数是get_result
local aaa = require "aaa"
local future = aaa.do_something()
local co_wrap = function(func)
local co = coroutine.create(func)
return function(...)
return select(2, coroutine.resume(co, ...))
end
end
local poll_result = function(future_)
local result = nil
repeat
-- 生产者循环
coroutine.yield(ret)
result = aaa.get_result(future_)
until result
return result
end
local ask = co_wrap(poll_result)
local result = nil
repeat
-- 消费者循环
result = ask(future)
until result
print(result)
火焰图和直方图、曲线图一样,是一种分析数据的方式,它可以更直观、更形象地展示数据,让 人很容易发现数据中的隐藏信息。之所以叫火焰图,是因为这种图很像一簇火焰。
火焰图展现的一般是从进程(或线程)的堆栈中采集来的数据,即函数之间的调用关系。从堆栈 中采集数据有很多方式,下面是几种常见的采集工具:
- Performance Event
- SystemTap
- DTrace
- OProfile
- Gprof
数据采集到了,怎么分析它呢?为此,Brendan Gregg开发 了专门把采样到的堆栈轨迹(Stack Trace)转化为直观图片显示的 工具——Flame Graph,这样就很容易生成 火焰图了。
可见,火线图本身其实很简单,难的是从火焰图中发现问题,并且能够解释这种现象,从 而找到优化系统或者解决问题的方法。
一般来说,当发现 CPU 的占用率和实际业务应该出现的占用率不相符,或者对 Nginx worker 的资源使 用率(CPU,内存,磁盘 IO )出现怀疑的情况下,都可以使用火焰图进行抓取。另外,对 CPU 占用率低、吐吞 量低的情况也可以使用火焰图的方式排查程序中是否有阻塞调用导致整个架构的吞吐量低下。
常用的火焰图有三种:
- lj-lua-stacks.sxx 用于绘制 Lua 代码的火焰图
- sample-bt 用于绘制 C 代码的火焰图
- sample-bt-off-cpu 用于绘制 C 代码执行过程中让出 CPU 的时间(阻塞时间)的火焰图
这三种火焰图的用法相似,输出格式一致,所以接下的章节中我们只介绍最为常用的 lj-lua-stacks.sxx。
SystemTap 是一个诊断 Linux 系统性能或功能问题的开源软件,为了诊断系统问题或性能,开发者或调试 人员只需要写一些脚本,然后通过 SystemTap 提供的命令行接口就可以对正在运行的内核进行诊断调试。
首先需要安装当前内核版本对应的开发包和调试包(这一步非常关键也最为艰难):
- 下载安装内核调试包
# rpm -ivh kernel-debuginfo-common-$(uname -r).rpm
# rpm -ivh kernel-debuginfo-$(uname -r).rpm
# rpm -ivh kernel-devel-$(uname -r).rpm
这些 rpm 包可以在该网址中下载: * http://debuginfo.centos.org * http://rpm.pbone.net
- 或者用yum安装内核调试包
yum install kernel-debuginfo-common-x86_64-$(uname -r).rpm
yum install kernel-debuginfo-$(uname -r).rpm
yum install kernel-devel-$(uname -r)
如果找不到这些包,修改或者新建yum源:
# /etc/yum.repos.d/CentOS-Debug.repo
#Debug Info
[debug]
name=CentOS-$releasever - DebugInfo
baseurl=http://debuginfo.centos.org/$releasever/$basearch/
gpgcheck=0
enabled=1
protect=1
priority=1
- 或者用debuginfo-install安装内核调试包
同样依赖上面的yum源
debuginfo-install -y kernel-$(uname -r)
- 然后安装 systemtap:
yum install systemtap systemtap-runtime
- 测试systemtap安装成功否:
#stap -v -e 'probe vfs.read {printf("read performed\n"); exit()}'
Pass 1: parsed user script and 103 library script(s) using 201628virt/29508res/3144shr/26860data kb, in 10usr/190sys/219real ms.
Pass 2: analyzed script: 1 probe(s), 1 function(s), 3 embed(s), 0 global(s) using 296120virt/124876res/4120shr/121352data kb, in 660usr/1020sys/1889real ms.
Pass 3: translated to C into "/tmp/stapffFP7E/stap_82c0f95e47d351a956e1587c4dd4cee1_1459_src.c" using 296120virt/125204res/4448shr/121352data kb, in 10usr/50sys/56real ms.
Pass 4: compiled C into "stap_82c0f95e47d351a956e1587c4dd4cee1_1459.ko" in 620usr/620sys/1379real ms.
Pass 5: starting run.
read performed
Pass 5: run completed in 20usr/30sys/354real ms.
如果出现如上输出表示安装成功。 如果不安装systemtap-runtime,这里可能会有很多编译错误。
我是菜鸟,我喜欢用傻瓜式无脑安装。
-
yum update kernel-*
没有这个将可能出现很多不必要的麻烦 -
先安装systemtap
yum install systemtap systemtap-runtime -
再安装内核信息包kernel*
stap-prep -
耐心等待吧,蜗牛般的网速。
首先,需要下载 stapxx 工具包:Github地址。 该工具包 中包含用 perl 写的,会生成 stap 探测代码并运行的脚本。如果是要抓 Lua 级别的情况,请使用其中 的 lj-lua-stacks.sxx。 由于 lj-lua-stacks.sxx 输出的是文件绝对路径和行号,要想匹配具体的 Lua 代码, 需要用 fix-lua-bt 进行转换。
# ps -ef | grep nginx (ps:得到类似这样的输出,其中15010即使worker进程的pid,后面需要用到)
hippo 14857 1 0 Jul01 ? 00:00:00 nginx: master process /opt/openresty/nginx/sbin/nginx -p /home/hippo/skylar_server_code/nginx/main_server/ -c conf/nginx.conf
hippo 15010 14857 0 Jul01 ? 00:00:12 nginx: worker process
# copy openresty-systemtap-toolkit/fix-lua-bt 到 stapxx 下面
# copy FlameGraph/stackcollapse-stap.pl 到 stapxx 下面
# copy FlameGraph/flamegraph.pl 到 stapxx 下面
# cd stapxx
# ./stap++ ./samples/lj-lua-stacks.sxx -I ./tapset --arg time=5 --skip-badvars -x 15010 > tmp.bt (-x 是要抓的进程的 pid, 探测结果输出到 tmp.bt)
# ./fix-lua-bt tmp.bt > flame.bt (处理 lj-lua-stacks.sxx 的输出,使其可读性更佳)
其次,下载 Flame-Graphic 生成包:Github地址,该工具包中包含多个火焰图生成工具,其中, stackcollapse-stap.pl 才是为 SystemTap 抓取的栈信息的生成工具
# ./stackcollapse-stap.pl flame.bt > flame.cbt
# ./flamegraph.pl flame.cbt > flame.svg
如果一切正常,那么会生成 flame.svg,这便是火焰图,用浏览器打开即可(或者直接拖到浏览器里)。
ps:如果在执行 lj-lua-stacks.sxx 的时间周期内(上面的命令是 5 秒), 抓取的 worker 没有任 何业务在跑,那么生成的火焰图便没有业务内容。为了让生成的火焰图更有代表性,我们通常都会在抓取的 同时进行压测。
我在实验时遇到的问题是,验证时出现下面的输出:
# stap -v -e 'probe vfs.read {printf("read performed"); exit()}'
Checking "/lib/modules/2.6.32-358.el6.x86_64/build/.config" failed with error: No such file or directory
Incorrect version or missing kernel-devel package, use: yum install kernel-devel-2.6.32-358.el6.x86_64
如果你确实已经安装了对应版本的kernel-devel; 你们不防rpm -ql kernel-devel 看看安装到哪里了, 如果是 /usr/src/kernels/2.6.32-431.el6.x86_64 那么不妨执行:
ln -s /usr/src/kernels/2.6.32-431.el6.x86_64 /lib/modules/2.6.32-431.el6.x86_64/build
卸载kernel
- yum remove kernel-devel
重新安装systemtap
- rpm -ivh kernel-devel-$(uname -r).rpm
- semantic error: while resolving probe point: identifier 'kernel'
- semantic error: missing x86_64 kernel/module debuginfo
- resolving probe point: identifier 'kernel'
重新安装内核调试信息即可
- kernel-debuginfo-common-
uname -r - kernel-debuginfo-
uname -r
- note: expected xxx
- error: implicit declaration of
- error: passing argument 1 of
卸载kernel
- yum remove kernel-devel
重新安装systemtap
- rpm -ivh kernel-devel-$(uname -r).rpm
No DWARF information found
这是因为找不到 DWARF 调试信息
- 到openresty-x.x.x/bundle/LuaJIT-2.1.0 直接编译重新安装
$ sudo make install CCDEBUG=-g -B -j8 PREFIX=/usr/local/openresty/luajit
- 或者编译后替换openresty的2个文件
$ cd openresty-x.x.x/bundle/LuaJIT-2.1.0
$ make CCDEBUG=-g -B -j8 PREFIX=/usr/local/openresty/luajit
$ cd /usr/local/openresty/luajit/bin/
$ sudo cp luajit-2.1.0-beta2 luajit-2.1.0-beta2_20160829
$ sudo cp ~/LuaJIT-2.1.0-beta2/src/luajit/luajit luajit-2.1.0-beta2
$ cd /usr/local/openresty/luajit/lib/
$ sudo cp libluajit-5.1.so.2.1.0 libluajit-5.1.so.2.1.0_20160829
$ sudo cp ~/LuaJIT-2.1.0-beta2/src/libluajit.so libluajit-5.1.so.2.1.0
ERROR: Array overflow, check MAXMAPENTRIES
加参数 -D MAXMAPENTRIES=10000
我本想将其设大点(10万),一执行操作系统就挂了。
- man stap
- https://www.sourceware.org/systemtap/SystemTap_Beginners_Guide/using-systemtap.html
- https://www.sourceware.org/systemtap/SystemTap_Beginners_Guide
一个正常的火焰图,应该呈现出如官网给出的样例(官网的火焰图是抓 C 级别函数):

从上图可以看出,正常业务下的火焰图形状类似的“山脉”,“山脉”的“海拔”表示 worker 中业务函数的 调用深度,“山脉”的“长度”表示 worker 中业务函数占用 cpu 的比例。
下面将用一个实际应用中遇到问题抽象出来的示例(CPU 占用过高)来说明如何通过火焰图定位问题。
问题表现,Nginx worker 运行一段时间后出现 CPU 占用 100% 的情况,reload 后一段时间后复现,当出现 CPU 占用率高情况的时候是某个 worker 占用率高。
问题分析,单 worker cpu 高的情况一定是某个 input 中包含的信息不能被 Lua 函数以正确地方式处理导致 的,因此上火焰图找出具体的函数,抓取的过程需要抓取 C 级别的函数和 Lua 级别的函数,抓取相同的时间, 两张图一起分析才能得到准确的结果。
抓取步骤:
- 安装SystemTap
- 获取 CPU 异常的 worker 的进程 ID :
ps -ef | grep nginx - 使用 lj-lua-stacks.sxx 抓取栈信息,并用 fix-lua-bt 工具处理:
# making the ./stap++ tool visible in PATH:
$ export PATH=$PWD:$PATH
# assuming the nginx worker process pid is 6949:
$ stap++ ./samples/lj-lua-stacks.sxx -I ./tapset --arg time=5 --skip-badvars -x 6949 > tmp.bt
Start tracing 6949 (/opt/nginx/sbin/nginx)
Please wait for 5 seconds
$ fix-lua-bt tmp.bt > a.bt
- 使用 stackcollapse-stap.pl 和 flamegraph.pl:
stackcollapse-stap.pl a.bt > a.cbt
flamegraph.pl a.cbt > a.svg
-
a.svg 即是火焰图,拖入浏览器即可:
-
从上图可以清楚的看到 get_serial_id 这个函数占用了绝大部分的 CPU 比例,问题的排查可以从这里入手,找到 其调用栈中异常的函数。

PS:一般来说一个正常的火焰图看起来像一座座连绵起伏的“山峰”,而一个异常的火焰图看起来像一座“平顶山”。
因为docker容器里的系统和宿主共用内核,导致容器里不能安装火焰图。
当运行一个 SystemTap 脚本的时候,SystemTap 会在脚本外构建一个内核模块,SystemTap 然后把这个 内核模块加载进内核,允许它直接从内核提取指定的数据。
正常情况下,SystemTap 仅仅会运行在部署了 SystemTap 的系统上。这意味着,如果你想在 10 个系统 上运行 SystemTap,你必须把 SystemTap 部署到所有的系统上。有时候,这可能既不可行也不理想。比如,公 司政策禁止管理员在指定的机器上安装 RPM 包来提供编译和 debug 信息,从而防止 SystemTap 的部署。为了 解决这一问题,SystemTap 允许你使用 Cross-instrumentation。
Cross-instrumentation 是一个从一台计算机上的 SystemTap 脚本生成 SystemTap 测量模块并在另一台 计算机上使用的过程。这个过程提供了以下好处:
- 各种主机的内核信息包可以被安装在单台主机上
- 每台目标机器仅仅需要被安装一个 RPM 包,为了使用生成的 SystemTap 测量模块:systemtap-runtime 包
为了简单起见,在这一节中使用以下术语:
- 测量模块 - 从 SystemTap 脚本构建的内核模块。SystemTap 模块在主机系统上被构建,将在目标系统的内核上被加载。
- 主机系统 - SystemTap 脚本编译测量模块的系统,为了在目标系统上加载它们。
- 目标系统 - SystemTap 脚本构建测量模块系统
- 目标内核 - 目标系统的内核,这个内核用于你加载或运行测量模块
为了配置一个主机系统和一个目标系统,需要完成以下步骤:
- 在每台目标系统安装 systemtap-runtime 包
- 通过在每台主机上运行 uname -r 命令来决定运行在每台目标系统上的内核
- 在主机系统上安装 SystemTap。在主机系统上,你将可以为目标系统构建测量指令。关于怎样安装 SystemTap 的指令,可以参考“SystemTap 学习笔记 - 安装篇”。
- 前期确定目标系统的内核版本,安装目标内核和在主机系统上的相关的 RPM 包,如 “SystemTap 学习笔记 - 安装篇” 中的 “手动安装必需的内核信息包” 所述。如果多个目标系统使用不同的目标内核,为在目标系统上使用的每个不同的内核重复这一步骤。
完成这些步骤后,你现在可以在主机系统上构建测量模块。为了构建测量模块,在主机系统上运行以下命 令(一定要指定适当的值):
stap -r kernel_version script -m module_name
这里, kernel_version 涉及到目标内核的版本(在目标系统上通过 uname -r 命令输出),script 涉及到 转换成测量模块的脚本,module_name 涉及测量模块要求的名称。
注:为了确定运行的内核的架构,你可以使用以下命令: uname -m
一旦测量模块被编译完成,拷贝它到目标系统,然后用下面的命令加载它:
staprun module_name.ko
例如,为 2.6.18-92.1.10.el5 (x86_64 架构) 的目标内核从一个名称为 simple.stp 的 SystemTap 脚本创建一个测 量模块 simple.ko,使用以下命令:
stap -r 2.6.18-92.1.10.el5 -e 'probe vfs.read {exit()}' -m simple
这将创建一个名为 simple.ko 的模块,为了使用这个测量模块,拷贝它到目标系统,然后在目标系统运行以下命令:
staprun simple.ko
注:重要!!!! 主机系统必须与目标系统是相同的架构以及相同的 Linux 发行版,为了使构建的测量模块能正常工作。
参考资料
- http://sourceware.org/systemtap/SystemTap_Beginners_Guide/using-systemtap.html
- https://segmentfault.com/a/1190000000671438
-
字符串与数字作比较
因为lua变量没有类型, 所以任何变量之间都可以做比较,非常容易导致悄无声息难以觉察的逻辑错误
Local serverId = "201" Local id = 201 If serverId == id then --- never reach here End -
lua的正则表达式
因为lua正则不标准,导致很容易犯错。例如
在字符串str查找点号".", 我习惯这么写
str:find(".")其他语言(c++,java)大概都是这么写的,在lua里是错的, 正确语法是:
str:find("%.") -
ngx.re返回的数组索引居然从0开始
通常lua的数组索引是从1开始。
-
Io.lines必须迭代到结束文件才会关闭
所以该迭代必须全部完成,中途不能break或return。
-
在init阶段有些东东不能用
例如: package,redis,ngx.re
-
Lua5.3 参考手册
-
OpenResty最佳实践
-
OpenResty官网
-
Emmy官网


