Demo: https://youtu.be/R2gP6NiPhMU
Autonomous driving is one of the hottest fields these days. However, learners/beginners may find it difficult to explore it and try out because it needs a modified real car. So why not use driving simulation games to try it?
Just like a real autonomous driving car does - It grabs the images of the surrounding environment, in my case it is a screenshot and feed it into a trained CNN. CNN will output the command to control the car.
I use win32 api to grab the screen and record the actions on the keyboard. These information are used as training data for the CNN. The CNN is based on Tensorflow and training on Google Colab using Google Cloud services.
This is an sample input. A grayscale image with two labels indicating throttle ansd steering.

By plotting the bar graph of the data distribution, I find the data is not balanced. Most data has the same label [1,0] which means most of the time, the truck is moving staright. It is resonable in real life but in machine learning it is bad as it will mislead the model.

The problem can be solved by randomly drop some images. I dropped 70% of them in this case. Here is the final result:

For the remaining image, some transformation can be done to expand the training data size and increases the noise resistibility of the model. For example, flip some image to simulate right/left turns and change the image brightness to simulate night/days.

The graph below shows the training/validation accuracy/loss of the final model. Notice that the validation accuracy curve is not flat yet so the model can be further trained for better performance.
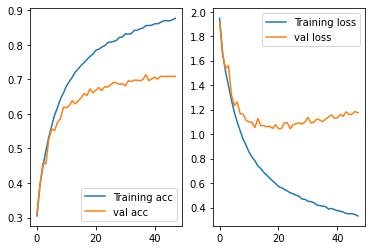
As there is not enough data for the CNN, overfitting occurs. I add some tranformations on the inout data and some dropout layers to fix it.
I manage to build an autonomous driving CNN successfully with only a few hours of data collection. My training data size is about 5GB and it is very small compared to some in-business NNs which usually have training data of PB scale. Have such a small size of training data means it has to sacrifice accuracy, but I manage to keep the accuracy of 73%
How to collect and transform data. How to tune parameters of NN. Dealing with under/overfitting.
The performace of the model can be improved by training with more datas.
