ajccom / blog Goto Github PK
View Code? Open in Web Editor NEWPersonal opinion does not represent company opinion
Personal opinion does not represent company opinion




前言:Javascript 是一门灵活的编程语言,吸引着全世界的程序员为其构建整个生态,在 Github 语言使用榜单上,JS 一直是名列前茅。如此热门的一门语言,它自身的演化又是如何的呢?今天我们就来聊一聊,JS 的演进之路。我们会聊到 JS 与 ES 的关系,ES 规范、规范的制订过程等。最后,希望大家能够通过本篇文章了解到 ECMAScript 的一些知识。
首先我们要了解到的是,ECMAScript 它是一套语言规范,即 ECMA-262 规范,制订该规范的组织叫 TC39。
它和 Javascript 的关系,通俗的讲,ECMAScript 就好像是自行车的基础构造,而 Javascript 则是使用了该基础构造的一个品牌产品,好比摩拜和 ofo,本质都是自行车,都是用了自行车的构造,有两个轮子,脚踏板,链子,刹车,龙头等,但是他们品牌不同,附加的装备也不同,比如车锁、车铃等。语言界和 Javascript 使用同样规范的有 ActionScript、JScript 和现在非常火的 NodeJS 等。
Javascript 除了 ECMAScript 提供的语法、API 和关键字等之外,还包括了宿主环境提供的 DOM 和 BOM,诸如 window 对象、XMLHttpRequest 对象、navigator 对象等。
谈到 ES 的版本,可能很多人都知道 ES 6 发布了,改名叫做 ES 2015。今年是 ES 2017 版本发布,在今年 6 月份。那么,ES 的版本是如何迭代的?版本号为何要改成年份呢?带着这两个问题,我们一起往下看。
首先,之前的名称如 ES5,这里的 5 代表的是 ECMA 262 规范的修订版本号,可以理解为第 5 版。即使现在都叫做 ES 201X,我们还是可以以这个数字作为版本号继续使用,ES 7、ES 8、ES 9...ES N。
接下来我们看下 ES 规范各个版本的发布时间:
| 版本 | 时间 | 间隔(年) |
|---|---|---|
| ES 1 | 1997 | 0 |
| ES 2 | 1998 | 1 |
| ES 3 | 1999 | 1 |
| ES 4 | - | - |
| ES 5 | 2009 | 10 |
| ES 6 | 2015 | 6 |
| ES 7 | 2016 | 1 |
| ES 8 | 2017 | 1 |
这个表格上我们看到,ES3 到 ES5 之间间隔了 10年,而且有一个版本难产而死,并没有正式发布,那就是 ES4。这是为什么呢?
这是因为,在那个 10 年之初,IE6 作为浏览器王者,一统天下,之后的 IE7,IE8 都没有带来 IE6 如此的辉煌成就。IE6 当时的盛行,导致了浏览器演进趋于停止,这也就导致浏览器使用的脚本引擎一直停滞,即使开发新的规范,没有浏览器厂商的支持,就形同于一纸空文。ES4 当时希望能解决语言方面的诸多问题,class、namespace、package 等等。但是既没有大厂支持也没有社区的支持(写 JS 的同学大多数觉得这么搞太复杂太不“灵活”),这就最终导致 ES4 规范被取消(其中也有一些不和谐的政治因素)。
时间推移,在 Chrome 诞生后,采用了新的解析引擎 V8 ,成功瓜分了浏览器市场份额,浏览器大战终于再次打响(第一次是网景和微软之间,微软完胜)。各浏览器厂商为了争取更多的用户和开发者,开始争相实现新规范,进行性能竞赛。FireFox、Chrome、Safari 等也都出了各自的新特性实施版本,如果你是开发者,可以下载这些版本体验下最新的提案内容(文章最后有链接)。
09 年诞生的 ES5,其实只是 ES3.1 版本,当初 ES 4 在推进过程中停滞不前,微软和 Yahoo 的代表就干脆另起了一份 ES3.1 规范。规范内容相较 ES4 是相对保守的。
09 年之后,到 15 年,ES6 终于面世了,这其中隔了 6 年时间主要是因为 ES6 增加了很多新功能和新语法。ES6 可以称得上是一次大的版本迭代。这其实是有风险的,委员会成员也各自表达了对这种大版本迭代形式的担忧,大家都不希望再次看到一个 “ES4 事件” 出现。所以以后的 ES 规范会每年一版,并且改名以年份作为版本号。ES6 改名叫 ES 2015,以后每年的版本依次类推。迭代的内容则是将当年 1 月份进入 Stage 4 的提案 Merge 到规范中作为当年版本的新规范。如果一个提案在当年 1 月份还没进入 Satge 4,那么就后延至下一年的版本。
目前来看,每年一个版本增加的内容并不多,ES7 仅增加了几个新内容,ES8 增加了比较重要 async await 函数。对于开发者来说,学习成本还是很低的,比学习某些框架的成本低多了。
每个规范在成为规范之前,都是委员会里的一个提案。每个提案都需要走一个处理流程,称为 TC39 process。流程共分 Stage 0 到 Stage 4,5 个阶段。最终进入 Satge 4 的提案即会成为下一个版本的规范。
我们这里看下 Satge 0 到 Stage 4 阶段都代表什么:
*** Stage 0: strawman ***
自由形式提案,表述提案包含的 ECMAScript 演变思路,由 TC39 成员(member)或已注册成为 TC39 贡献者(contributor)的非会员提交。再由 TC39 会议审查后,将提案添加到 Satge 0 阶段。
*** Stage 1: proposal ***
正式提案,此时需要为提案指定一名 TC39 成员作为提案的带头人(champion)或联合带头人(co-champion)。进入第一阶段的提案要满足:
接下来,TC39 通过接受第一阶段的建议,声明其愿意审议,讨论并对该提案作出贡献。之后,预计将对该提案进行重大修改。
*** Stage 2: draft ***
这是提案作为规范的第一个版本,与最终规范中包含的特性不会有太大差别。这一阶段要求提案必须:
满足这些条件后,提案才能正式进入第二阶段。
接下来,提案只能进行增量的修改。
*** Stage 3: candidate ***
进入这一阶段的提案已经属于基本完成了的。进入这一阶段需要满足的条件有:
接下来,只能在实施及使用过程中引起的关键问题上作出变更。
*** Stage 4: finished ***
进入这一阶段标志着提案已经准备好纳入标准。在提案进入这一阶段之前,需要满足的条件有:
仅就当前看来,ES 规范很大程度上会考虑旧网页兼容性,换句话说,就是你写老代码,也依旧能行。比如在 ES 7 中新增了一个数组对象的方法,本来叫做 contains,用于返回数组中是否包含参数的值,可以说是十分贴切。但是由于老牌的脚本库 mootools 下会产生报错,所以提案最后将 contains 换成了 includes。还有如 typeof null 返回的值是 object,这些奇怪的问题也依旧在最新的规范版本中。
但是,那么多人辛苦制定的规范,是真的没什么用吗?那他们为何还要煞费苦心的指定新规范呢?
我们接下来看看,如果你不学习最新的规范,你会错过什么呢?
比如 ES6 的 Modules,它是静态的模块,可以提供静态分析,进而使用 Tree Sharking 技术可以起到为打包瘦身的效果。再比如使用 for of 可以直接遍历对象的值等等。
ES 8 加入了 async 和 await 规范(当然,你可能很早之前就用过了),它比 callback、Promise 或者 generator 都要让人更容易使用,也更容易读懂代码,是相当好的处理异步的方式。还有比如使用 let、const 定义变量,不会产生变量提升效果。
console.log(a); // 'undefined'
a = 1;
var a = 2;
console.log(b); // Uncaught ReferenceError: a is not defined
b = 1;
let b = 2;还有使用 Set 数据结构可以得到无重复项的数组等等。
那么我只学习最新规范是否就可以不学习老的一套的了呢?其实要这样理解新规范,每一版本的规范,并不是将老规范的推倒重来,可能之后有一天,所有的新规范可以覆盖 ES3 中所有内容了,那么你那时就可以不用再学习 ES3 了,但是目前来看,你或多或少还是要学习一些“老”的内容。
面试中基本上都会问新规范,但从面试技巧上讲,可能并不会那么直接的发问一些纯知识型的问题,比如:
你能告诉我一下 ES 7 中 Array 对象新增了哪些方法,又是怎么用的呢?
这种问题就比较无聊,而且容易使候选人产生一种 “我看一眼就知道了呀” 的抗拒心理。所以一般面试官会以场景出题,可能是这么问:
现在有一个巨大的数组,你有哪些方法可以告诉我,如何判断一个数字都否在该数组中?
这样问,候选人如果知道新规范的实现方法,那肯定是有加分的。
还有比如会问:
我们的 Node 项目中有特别多的异步请求,比如有一个请求需要在前置的请求完成之后发送,你能否帮我设计一下代码思路?
这个时候你会想到什么样的答案呢?
如果业务工作量很大,没那么多时间的话,建议半年或者一年学习一次最新规范,可以订阅一些业界名人的博客、论坛等。如果时间比较充裕,可以通过看 TC39 的 proposals 页面,了解到委员会最新的一些提案。
光看了文档,也需要有实现最新提案的浏览器,可以使用厂商推出的新规范实施版本进行尝试:
firefox nightly: https://www.mozilla.org/en-US/firefox/channel/desktop/#nightly
chrome canary: https://google-chrome-canary.en.softonic.com/
Safari Technology Preview: https://developer.apple.com/safari/download/
前端在 09 年之后,随着 ES5、NodeJS 的出现,发生了翻天覆地的变化。我们开发工具从 DW、notepad++ 换到了 Sublime、VS Code,我们发布过程加入了基于 grunt、gulp、webpack 等的工作流,我们样式书写也从简单的配置文件到 OO 编程,而最大的变化,莫过于我们所写的 JS。从 ES3 到 ES5,再到 ES2015,至今已经是 ES2017,我们有理由相信,ES 的未来是美好的。
2016 年,JS 语言高居 Github 项目使用语言第一名。
我们团队正在寻觅优秀的前端人才,坐标浦东张江,电商行业,如果您正在看机会,不如将简历投递至:[email protected]。
期待您的加入。
function ondragstart (e) {
var id = e.target.getAttribute('for')
e.dataTransfer.dropEffect = 'move'
e.dataTransfer.setData('id', id)
//e.dataTransfer.setDragImage(this, 42, 24) // IE 11 下 DataTransfer 对象没有 setDragImage 方法
e.dataTransfer.effectAllowed = 'move'
}代码在 Chrome 下没有问题,但是在 IE 11 下出现问题:
SCRIPT65535: 意外地调用了方法或属性访问。
查看爆栈上得知:
IE 9 以上需要在 setData 方法的第一个参数中使用 “Text”
修改代码后正常
function ondragstart (e) {
var id = e.target.getAttribute('for')
e.dataTransfer.dropEffect = 'move'
e.dataTransfer.setData('Text', id)
//e.dataTransfer.setDragImage(this, 42, 24)
e.dataTransfer.effectAllowed = 'move'
}var c1 = document.createElement('canvas')
ctx1 = c1.getContext('2d')
ctx1.globalAlpha = 0.1
let gradient = ctx1.createRadialGradient(50, 50, 0.25, 50, 50, 50)
gradient.addColorStop(0, 'rgba(0, 0, 0, 1)')
gradient.addColorStop(1, 'rgba(0, 0, 0, 0)')
ctx1.fillStyle = gradient
ctx1.fillRect(0, 0, 100, 100)
document.body.appendChild(c1)已经向 FF 反馈,目前只能曲折的解决这个问题:
在百度统计中有一个查看网页热力图的功能,对于查看网页上用户热区十分有用。
在公司项目中也希望能够加上热力图功能作为运营的一个参考,于是翻看了一些做热力图的代码库(其实主要是看了 heatmap.js),所以这里将吸收融汇到的一种热力图绘制方法记录一下,权当笔记。
虽然我使用前端方法绘制热力图,但其中原理适用于其他技术领域。
首先准备一个网页文件,添加一个 canvas 元素,这个元素会用来呈现最终结果。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
<canvas id="canvas" width="800" height="800"></canvas>
</body>
</html>需要注意,我通过 canvas 元素的属性设置画布高宽为 800 x 800,而不是样式。虽然通过样式也可以设置 canvas 元素大小,但是样式设置的高宽并不会改变画布的像素总量,可以理解为样式高宽只是将画布进行了缩放。
这一点对于具有交互性操作的画布应用来说是必须要注意的,但并不是本文要阐述的重点,大家知道即可。
再准备一个数据生成器,生成的数据模拟用户点击数据,具有 x、y 坐标和该坐标下的点击量。
function generateData () {
const MAXX = 800,
MAXY = 800,
MAXV = 100
let result = []
for (let i = 0; i < 1000; i++) {
result.push([Math.ceil(Math.random() * MAXX), Math.ceil(Math.random() * MAXY), Math.ceil(Math.random() * MAXV)])
}
return result
}这个函数返回一个包含一万条数据的数组,每一项内容是 x,y 坐标和点击量。
需要注意返回的数组中可能含有相同
x,y坐标的数据,作为讲解原理的假数据并无大碍但还是请大家能认识到它的小小错误。
我们需要用颜色来表示热力图的高亮程度,使用一个 256 x 1 的画布,通过线性渐变绘制得到一个调色盘。调色盘中的颜色将会用于渲染热力图。
function getPalette () {
let config = {0.25: 'rgb(0,0,0)', 0.55: 'rgb(0,255,0)', 0.85: 'yellow', 1.0: 'rgb(255,0,0)'},
canvas = document.createElement('canvas'),
ctx = canvas.getContext('2d')
canvas.width = 256
canvas.height = 1
let gradient = ctx.createLinearGradient(0, 0, 256, 1);
for (let key in config) {
gradient.addColorStop(key, config[key])
}
ctx.fillStyle = gradient
ctx.fillRect(0, 0, 256, 1)
return ctx.getImageData(0, 0, 256, 1).data
}通过调用 getPalette 方法我们获得一个调色盘图像数据,这个数据的高宽 256 x 1 是故意为之,为什么呢?大家可以带着这个疑问继续往下看。
准备工作完成后,接下来需要进行数据图像化的工作。图像化数据的目的是为了能够让数据转换成图像,一条数据对应一个羽化的圆,通过向圆形填充径向渐变得到。
羽化是 PS 工具中的一个术语,效果是图形外围边框由透明过度到颜色。我们可以使用径向透明渐变实现这个效果,但是在设置径向渐变对象之前,还需要确定圆的半径。
数据中的点击量值,反应了该坐标的热力程度。点击量和图像高亮效果成正比,点击量越高,区域越高亮。
我使用了一种由点击量数据的最大最小值决定的范围进行阈值划分,以确定圆形半径的方法,用以根据不同点击量阈值内数值得到相应半径值。
首先获取点击量最大和最小值:
let dataArray = generateData()
let min = 9999, max = -1
let arr = dataArray.map((data) => data[2])
arr.sort((a, b) => (a - b))
min = arr[0]
max = arr[arr.length - 1]接着获取点击量区间的阈值,然后自定义一个圆形半径的取值范围,并通过每条数据的点击量值获取对应的半径数值:
function getRadius (data) {
let step = Math.floor((max - min) / 10) // 分隔阈值范围
let radiusRange = [10, 20] // 半径取值范围 10 到 20 像素
let value = data[2] // 点击量
let index = Math.ceil((value - min) / step) // 计算点击量落在哪个阈值范围
let radius = radiusRange[0] + (radiusRange[1] - radiusRange[0]) / 10 * index // 得到半径值
return radius
}获得半径值后,就可以设置径向渐变,绘制出这条数据对应的圆形。
注意,为了能够提升性能,并不需要每一条数据都绘制圆。
由于数据通过阈值被划分之后,对应的半径取值的可能性也只有相应的几种可能。所以我通过
shadow canvas(影子画布,即用户看不到的画布)来绘制圆形,当遇到已经绘制过的相同半径的圆形时则直接使用之前已完成的圆形图像。
let shadowCanvasHashmap = {}
function getPointCanvas (radius) {
if (shadowCanvasHashmap[radius]) {
return shadowCanvasHashmap[radius]
} else {
let canvas = document.createElement('canvas'),
ctx = canvas.getContext('2d'),
blur = 0.75, // 透明区域范围(0 到 1区间,以外围为 0)
l = radius * 2
canvas.width = l
canvas.height = l
let gradient = ctx.createRadialGradient(radius, radius, 1 - blur, radius, radius, radius)
gradient.addColorStop(0, 'rgba(0, 0, 0, 1)')
gradient.addColorStop(1, 'rgba(0, 0, 0, 0)')
ctx.fillStyle = gradient
ctx.fillRect(0, 0, l, l) // 直接填充整个画布即可
shadowCanvasHashmap[radius] = canvas
return canvas
}
}上面的代码展示了如何绘制一条数据对应的圆,接下来我们要将所有数据对应的圆绘制到一个和热力图画布一样大小的 shadow canvas 中,姑且称之为“副本”画布。
let copyCanvas = document.createElement('canvas'),
ctx = copyCanvas.getContext('2d')
copyCanvas.width = 800
copyCanvas.height = 800
dataArray.map((data) => {
let radius = getRadius(data)
let pointCanvas = getPointCanvas(radius)
ctx.drawImage(pointCanvas, data[0] - radius, data[1] - radius)
})这里我们新建了“副本”画布,并在上面绘制出所有的圆。
得到的效果如下:

接下来是最重要的一步,就是给图像上色。
通过读取副本画布的图像数据,对图像中各个像素点的透明度通道(alpha 通道)值 x 对应到调色盘 x 位置的像素值,然后使用该处像素的 RGB 值进行上色。这种方法可以保证热力图上呈现的颜色具有连续性。
这下知道为什么调色盘宽度是 256 了吧?
let imageData = copyCanvas.getContext('2d').getImageData(0, 0, 800, 800),
palette = getPalette()
let data = imageData.data,
l = data.length, alpha = 0, offset = 0
for (let i = 0; i < l; i += 4) {
alpha = data[i + 3] // alpha 值的取值范围和 R、B、G 相同是 0 - 255
offset = alpha * 4 // 对应到调色盘图像数据位置
data[i] = palette[offset]
data[i + 1] = palette[offset + 1]
data[i + 2] = palette[offset + 2]
data[i + 3] = palette[offset + 3]
}
imageData.data.set(data)
document.getElementById('canvas').getContext('2d').putImageData(imageData, 0, 0)好,到这里,热力图已经成功渲染出来了。

刚才的过程中,我们对“副本”画布的所有像素点进行了遍历,这是一个比较耗性能的地方。
优化方法是对热力图高亮区域进行范围计算,然后只读取这个范围内的图像数据,可以节省遍历次数,提高性能。

在对数据进行绘制圆的过程中,新增了很多 shadow canvas 元素存储不同半径的原形图像,这样可以有效减少重复绘制次数。但是注意要在最后对这些元素进行清理哦。
最近在做一个热力图图像中显著性区域识别的需求,比如有如下一个图像:

需要识别出图像中高亮较集中的区域,即高亮集中的区域被认为是图像中的显著性区域,效果如下:

在没有原始数据情况下,需要对原始图像中的图像数据进行分析,然后可以通过射线法等方法得到显著性区域范围。
而在拥有原始数据的情况下,我们可以通过简单的操作原始数据获取图像显著性区域,十分方便。
这里通过一个例子,来介绍一下基于原始数据的图像显著性区域识别方法。
首先准备了一个页面用于渲染图像,内容如下:
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
.box {width: 500px; height: 500px; border: 1px solid #bbb; position: relative;}
.item {width: 10px; height: 10px; border-radius: 5px; position: absolute; background: rgba(0, 0, 0, 0.4); transform: translate(-50%, -50%)}
.line {border: 1px solid red; position: absolute;}
</style>
</head>
<body>
<div class="box"></div>
<script></script>
</body>
</html>代码中预定义了样式,可以看出,box 元素将会是图像的"画布",item 元素是画布中的点,而 line 元素是包裹范围的选框。
本文提到的原始数据是指含有 x, y 坐标信息的数据集合,并且该数据集合被用于绘制图像,如:
var data = [
{x: 20, y: 31},
{x: 104, y: 99},
...
]这里通过随机数生成一个原始数据:
var items = [], max = 500, len = 1000, i = 0
// 生成 1000 个坐标点,范围 [0 - 500)
for (i; i < len; i++) {
items.push([Math.floor(Math.random() * max), Math.floor(Math.random() * max)])
}得到数据后,我们可以先在画布上绘制点。
var html = ''
items.map(function (item) {
html += '<div class="item" style="left: ' + item[0] + 'px; top: ' + item[1] + 'px"></div>'
})
document.querySelector('.box').innerHTML = html效果如图:
我们需要识别的范围,简单的说就是多个连续的数据点的集合所形成的范围。所以第一步,我们需要通过一个点来寻找它所在的连续数据点集合。
连续数据点集合的获取方法描述如下:
1 设定一个点作为起始点;
2 遍历数据寻找与起始点“连续”的点,即两点距离小于某一阈值;
3 对获取到的“连续”点集合进行遍历重复 1 - 3 步骤直到全部遍历完成。
完成一次连续数据点集合的获取即代表着获取到了一个数据范围。但是该数据范围是否“显著”,这个是需要判断的,例子中将仅以数据点的个数作为判断依据;实际应用中判断显著性应该还需要结合图像中的其他权重值,比如热力图中每个点的点击量值。
我们先定义一下获取两个点距离的方法:
// 十分熟悉的勾股定理
function getDistance (p1, p2) {
return Math.sqrt(Math.pow(p2[1] - p1[1], 2) + Math.pow(p2[0] - p1[0], 2))
}获取连续数据点的方法定义如下:
/**
* infect 通过一个起始点获取一个连续数据点集合
* @params {Array} startPoint 起始点
* @params {Array} restPoints 剩余待计算点的集合
* @params {Array} range 已计算所得的连续数据点集合
* @return {Array} 连续数据点集合
*/
function infect (startPoint, restPoints, range) {
var i = 0, temp = []
// 还有剩余待计算点时,对下一个待计算点进行连续判断(这里仅以距离作为判断依据),如果是连续点,则将该点加入数据集合并从剩余待计算点集合中剔除。
while (restPoints[i]) {
if (getDistance(startPoint, restPoints[i]) <= 5 * 2) {// 距离小于两圆半径之和表示“连续”
if (range.indexOf(restPoints[i]) === -1) {
temp.push(restPoints[i])
restPoints.splice(i, 1)
i--
}
}
i++
}
range = range.concat(temp)
// 上面一次遍历仅获得了起始点的连续点,接下来计算起始点的连续点的连续点,依此类推,直到没有剩余待计算点为止
i = 0
while (temp[i] && restPoints.length > 0) {
range = range.concat(infect(temp[i], restPoints, [temp[i]]))
i++
}
return range
}代码中通过对起始点的连续点中的每一个点进行连续点求值,获得最终一个范围内的所有数据点。
接下来,我们通过 infect 函数获得所有范围集合。
function findRangeAndDraw () {
var startPoint = null, i = 0, ranges = [], rest = items.slice(0)
// 获取到一个范围数据点集合后,如果还有剩余待计算点,继续进行范围获取。
while (rest.length) {
startPoint = rest.shift()
ranges.push(infect(startPoint, rest, [startPoint]))
}
// 绘制所有范围
draw(ranges)
}在最后的绘制方法中,需要对范围内的所有数据点进行遍历以确定范围的左上角顶点和长宽,代码如下:
function draw (ranges) {
var i = 0, points = ranges.shift(), maxX = 0, maxY = 0, minX = max, minY = max, width = 0, height = 0
if (points.length === 1) {
// 如果范围内仅一个点,继续绘制
if (ranges.length) {
draw(ranges)
return
}
} else {
// 获取左上角顶点和右下角顶点坐标
points.map(function (point) {
maxX = Math.max(point[0], maxX)
maxY = Math.max(point[1], maxY)
minX = Math.min(point[0], minX)
minY = Math.min(point[1], minY)
})
// 计算获取高宽,这里的数值 5 每个点的半径,见 CSS 中的属性
minX = minX - 5
minY = minY - 5
width = maxX - minX + 5
height = maxY - minY + 5
}
document.querySelector('.box').insertAdjacentHTML('afterBegin', '<div class="line" style="left: ' + minX + 'px; top: ' + minY + 'px; width: ' + width + 'px; height: ' + height + 'px;"></div>')
if (ranges.length) {
draw(ranges)
}
}所有代码完成,最后执行 findRangeAndDraw 方法,运行后效果如下:
[!ranges.jpg]
上述方法通过操作原始数据获取图像的显著性区域,还有很多方法可以不依靠原始数据获取图像显著性区域。
这里简单介绍两种方法。
射线法是不依靠原始数据而能得到显著性区域范围的一种方法。
它的获取范围的步骤是:
1 设定显著性区域的阈值并通过图像获得图像的像素数据;
2 遍历图像像素数据,获得显著点的集合;
3 遍历显著点集合,对每一个显著点,
3.1 依序发射 4 条直线,每条直线成45度夹角,最终形成一个“米”字;
3.2 依序遍历这 4 条直线,判断距离显著点最近的该线上背景色点坐标;
3.3 遍历完成 4 条线,获得一个具有 8 个点的集合;
3.4 确定该显著点的范围,并在下次遍历中跳过该范围内的所有点的计算;
4 重复步骤 3 中的所有小步骤直到没有显著点可计算;
5 绘制所有范围。
区块统计法是通过对图像进行 N 等分后获得 N 个区块,然后判断相邻区块是否含有显著性区块,最终获得显著性区域的一种方法。同样,该方法也不依靠原始数据。
它的步骤如下:
1 获得图像的像素数据;
2 将图像划分为 N 个区块,如以 5 * 5 的像素范围为一个区块;
3 遍历区块,判断在区块范围内的像素数据是否含有显著性像素,是则将区域标记为 1,否则为 0;
4 对标记为 1的区块进行遍历,并对相邻的标记为 1 的区块进行合并为一个范围;
5 绘制所有范围;
通过操作图像的原始数据,可以获取到图像的显著性区域范围。而当没有原始数据时,我们也可以通过分析图像的像素数据获得范围。
目前,分析图像的显著性区域技术使用的非常广阔。比如常见的二维码识别、条形码识别、商品识别、色情图像识别等等,当然每一个具体的场景对应的算法都会有所不同,希望本文能够对大家能够深入其中带来一点帮助。
本文旨在通过代码分析让读者了解基于神经网络进化的机器学习实现方法。
之前 G 家的 Alpha Go 打败人类围棋冠军的事件将人工智能推上了人民群众议论的焦点。人工智能的热潮随之扑面而来,无论是手机、摄像、点外卖,无不标榜自己具有人工智能加成。一时间人工智能成为了时代的宠儿。
前不久在逛 github 的时候,偶然发现了一个叫 Neuroevolution.js 的文件,项目作者用它实现了一个人工智能玩游戏的 Demo
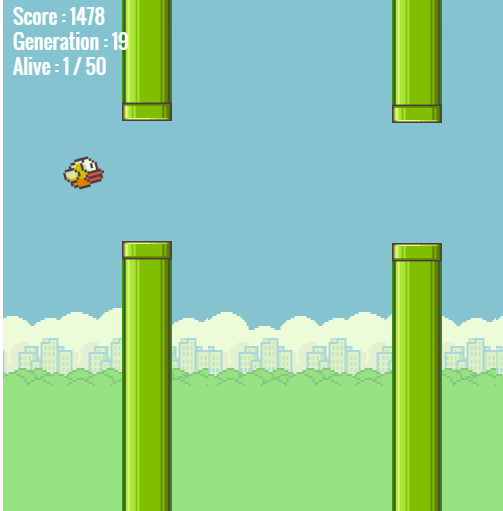
【游戏截图】
我认真的读了代码,结合有限的知识,下面尝试将代码讲解下,看看 Neuroevolution 是如何实现机器学习方式之一 —— 神经网络的。
首先介绍一下神经网络。神经网络的研究很早就已出现,今天“神经网络”已经是一个相当大的、多学科交叉的学科领域。神经网络的定义也多种多样,这里我们采用如下定义:
神经网络是由具有适应性的简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系统对真实世界物体所作出的交互反应。
神经网络中最基本的成分是“神经元”模型,即上述定义中的“简单单元”。神经元互相相连,当有一个神经元接受外部信息并被“激活”,那么它会向相连神经元发送“化学物质”,改变它们的电位。如果某神经元的电位超过一个“阈值”,那么它也会向相连神经元发送“化学物质”。经过一系列的连锁反应,根据最后的神经元输出,就能得到相应的反馈,比如“跳”、“咬”等动作。
神经网络进化是指通过一代又一代“优胜劣汰”方式筛选出适应“生存规则”的个体,这些个体所具备的“基因”含有能够使其作出对外部环境正确反应的神经网络。
神经网络进化的方式特点在于其越来越“智能”的进化过程无需人工干预,理想情况下仅依靠自身的逻辑就可产生趋于最优的解。
以 Demo 游戏为例,游戏中每一代会若干个个体,小鸟。每一代的个体全部死亡后会依据得分最高的一部分,使它们的基因延续给下一代(过程略复杂,后文有详解),如此往复,最后得到了一个或者多个能够持续穿越管道的个体。
如果你有足够耐心,可以看到存活个体已经掌握游戏生存规则,达到了人类难以企及的分数。

【难以企及】
Neuroevolution 文件中我们可以很清晰的看到它的代码结构,除 Neuroevolution 对象本身的属性和方法外,其中还包括 Generations、Generation、Genome、Network、Layer、Neuron 类(JS 的类可以通过 prototype 模拟的,所以虽然没使用 class 关键字,但本文也称之为“类”)。
下面我们分析下 Neuroevolution 对象和这些类的作用。
Neuroevolution 对象(其实是个方法,但是 JS 中方法也是对象,姑且称之为对象)提供了一些基础配置,如下:
| 配置项 | 描述 |
|---|---|
| activation | 激活函数,经典 S(Sigmoid)函数 |
| randomClamped | 随机值函数,返回一个 -1 到 1 的浮点数 |
| network | 神经网络层配置 |
| population | 人口,每一代产生的个体数量 |
| elitism | 上一代最优基因的延续比例 |
| randomBehaviour | 下一代随机基因的比例 |
| mutationRate | 神经元的突触异变率 |
| mutationRange | 神经元的突触异变量 |
| historic | 上一代的存活人口 |
| lowHistoric | 是否不存储上一代神经网络 |
| scoreSort | 分数升降序,即声明分数越高越好还是越低越好 |
| nbChild | 生育数,上一代 2 个体繁殖的后代数量 |
这里的配置参数 network 如何配置?Demo 中使用的值 [2, [2], 1] 如何理解?
Neuvol = new Neuroevolution({
population:50,
network:[2, [2], 1],
});network 配置项第一和第三个参数表示输入层和输出层的神经元个数,第一层我们称之为输入层,第三层我们称之为输出层。输入层和输出层就构成了一个感知机。
感知机能够轻易的实现逻辑与或非运算。
比如输入层有两个值 x1, x2,输出层为 y
y = x1 && x2 // 与运算
y = x1 || x2 // 或运算
y = !x1 // 非运算感知机如果只有输入和输出层,且仅输出层有激活函数处理,功能是十分有限的,即使简单的异或问题也难以解决。
所以一般情况下,神经网络除了输入和输出层外,还会有若干的隐藏层,即 network 值第二项。
network 值第二项值为数组,数组项的个数表示隐藏层个数,每一项的数值表示该隐藏层的神经元个数。比如配置:
network: [2, [2, 2, 2], 1]表示有 3 层隐藏层,每一层含有 2 个神经元。
通常情况下,我们称含有 1 个隐藏层的神经网络为单层神经网络,多个隐藏层的神经网络为多层神经网络。
隐藏层的主要工作是对输入层传过来的数据进行加工,然后传递给下一层网络,最终传递给输出层,如图:

【单层网络神经图片】
理论上隐藏层越多,神经网络的学习成本就越高。深度学习的神经网络其隐藏层数量是十分庞大的,可能会涉及上亿个参数需要调试。而神经网络进化是基于自身逻辑进行微调,从而产生足够”智能“的神经网络。
重新回到 Neuroevolution 对象,它具有如下方法:
| 方法 | 描述 |
|---|---|
| set | 覆盖默认配置参数 |
| generations | Generations 实例 |
| restart | 重新开始生成后代 |
| nextGeneration | 返回下一代所有神经网络 |
| networkScore | 用于神经网络计分 |
其中 networkScore 方法用于为神经网络计分,通过配置参数 scoreSort 和其得分可以确定该神经网络在当代所有神经网络中的排名顺序。
下面我们看看其他的类。
var Neuron = function () {
this.value = 0;
this.weights = [];
}
/**
* Initialize number of neuron weights to random clamped values.
*
* @param {nb} Number of neuron weights (number of inputs).
* @return void
*/
Neuron.prototype.populate = function (nb) {
this.weights = [];
for (var i = 0; i < nb; i++) {
this.weights.push(self.options.randomClamped());
}
}Neuron 类很简单,它的实例由 value 和 weights 属性和一个 populate 方法组成。
value 即神经元的值,该值通过系列计算后由激活函数输出weights 为神经元的突触,其个数等于输入层神经元个数populate 方法可以向神经元突触填充随机值/**
* Neural Network Layer class.
*
* @constructor
* @param {index} Index of this Layer in the Network.
*/
var Layer = function (index) {
this.id = index || 0;
this.neurons = [];
}
/**
* Populate the Layer with a set of randomly weighted Neurons.
*
* Each Neuron be initialied with nbInputs inputs with a random clamped
* value.
*
* @param {nbNeurons} Number of neurons.
* @param {nbInputs} Number of inputs.
* @return void
*/
Layer.prototype.populate = function (nbNeurons, nbInputs) {
this.neurons = [];
for (var i = 0; i < nbNeurons; i++) {
var n = new Neuron();
n.populate(nbInputs);
this.neurons.push(n);
}
}Layer 类负责管理神经网络中的层。每个 Layer 实例需要确定它在整个网络中的位置 index,和它含有的神经元 neurons 数组。它提供的 populate 方法可以为实例填充神经元。
Network 类负责管理神经网络,它的实例具有一个 layers 数组存放 Layer 实例。我们再看看 Network 实例的方法。
perceptronGeneration 方法该方法会通过调用 Layer 和 Neuron 实例的填充方法将神经网络填充完整。它的填充过程如图:

【神经网络填充图】
一个完整神经网络包含相应的层,每一层包含相应的神经元,而神经元包含值和突触。
值得注意的是,第一层输入层是没有突触的,之后的所有层包括最后的输出层的神经元都会拥有和输入神经元个数相同的突触数量。
那么突触具体的作用是什么呢?
compute 方法从 compute 方法中可以解读到,突触其实就是用以对神经元的值进行微调的一种参数,当神经元接收到前一层神经元传递的值,接着和突触发生“反应”,然后根据所有突触的值,通过激活函数,成为当前神经元新的 value 值。
/**
* Compute the output of an input.
*
* @param {inputs} Set of inputs.
* @return Network output.
*/
Network.prototype.compute = function (inputs) {
// Set the value of each Neuron in the input layer.
for (var i in inputs) {
if (this.layers[0] && this.layers[0].neurons[i]) {
this.layers[0].neurons[i].value = inputs[i];
}
}
var prevLayer = this.layers[0]; // Previous layer is input layer.
for (var i = 1; i < this.layers.length; i++) {
for (var j in this.layers[i].neurons) {
// For each Neuron in each layer.
var sum = 0;
for (var k in prevLayer.neurons) {
// Every Neuron in the previous layer is an input to each Neuron in
// the next layer.
sum += prevLayer.neurons[k].value *
this.layers[i].neurons[j].weights[k];
}
// Compute the activation of the Neuron.
this.layers[i].neurons[j].value = self.options.activation(sum);
}
prevLayer = this.layers[i];
}
// All outputs of the Network.
var out = [];
var lastLayer = this.layers[this.layers.length - 1];
for (var i in lastLayer.neurons) {
out.push(lastLayer.neurons[i].value);
}
return out;
}前文提到了很多次的激活函数,这里解释下。框架使用的激活函数代码如下:
/**
* Logistic activation function.
*
* @param {a} Input value.
* @return Logistic function output.
*/
activation: function (a) {
ap = (-a) / 1;
return (1 / (1 + Math.exp(ap)))
}通过激活函数,我们可以将一个值使用约束在 0 到 1 的范围内,且当参数 a 等于 0 时,激活函数取值为 0.5。
激活函数在坐标系中呈现为 S 形连续图像,如图:
【S函数图像】
连续的图像能够确保在微小的修改下,得到的值是相近的,有利于参数微调(如果参数调整的幅度过大,就会产生”震荡“,使最优解难以被归纳得过)。
getSave 方法和 setSave 方法这对方法中,getSave 方法是将神经网络的神经元和突触保存为一种结构,包含所有层的神经元个数和所有神经元突触的值。这种结构将神经网络中的层以数组的形式表示,这为复制神经网络的逻辑提供了方便。
setSave 方法正好相反,可以将上述的数据结构写入一个神经网络中,即将层和突触数据填充入新的神经网络。
Generation 类Genome 类负责将神经网络和外部环境因素关联,起到纽带的作用。每一个基因包含一个神经网络。
Generation 类负责管理 Genome 实例,直觉上我们会认为所有存活的基因都在 Generation 示例下,但实际上 Generation 仅仅负责记录存活失败的基因并为它们排序。它具有如下方法:
| 方法 | 描述 |
|---|---|
| addGenome | 往最新一代中添加一个 Genome 实例 |
| breed | 通过两个 Genome 实例繁殖出新一代的 Genome 实例 |
| generateNextGeneration | 生成新一代个体 |
addGenome 方法被用于生成新一代基因,并且该方法会对基因的“生存能力”进行排序。Demo 中每阵亡一个小鸟,就会生成新的基因。
generateNextGeneration 方法是比较核心的方法。当游戏中的个体全部存活失败,就会执行 generateNextGeneration 方法。新一代个体的生成逻辑是:
elitism 比例的当代基因,然后复制该部分基因的神经网络用于下一代;randomBehaviour 比例的基因,随机初始化后用于下一代;/**
* Generate the next generation.
*
* @return Next generation data array.
*/
Generation.prototype.generateNextGeneration = function () {
var nexts = [];
for (var i = 0; i < Math.round(self.options.elitism *
self.options.population); i++) {
if (nexts.length < self.options.population) {
// Push a deep copy of ith Genome's Nethwork.
nexts.push(JSON.parse(JSON.stringify(this.genomes[i].network)));
}
}
for (var i = 0; i < Math.round(self.options.randomBehaviour *
self.options.population); i++) {
var n = JSON.parse(JSON.stringify(this.genomes[0].network));
for (var k in n.weights) {
n.weights[k] = self.options.randomClamped();
}
if (nexts.length < self.options.population) {
nexts.push(n);
}
}
var max = 0;
while (true) {
for (var i = 0; i < max; i++) {
// Create the children and push them to the nexts array.
var childs = this.breed(this.genomes[i], this.genomes[max],
(self.options.nbChild > 0 ? self.options.nbChild : 1));
for (var c in childs) {
nexts.push(childs[c].network);
if (nexts.length >= self.options.population) {
// Return once number of children is equal to the
// population by generatino value.
return nexts;
}
}
}
max++;
if (max >= this.genomes.length - 1) {
max = 0;
}
}
}在基因繁殖过程中,新基因的每个神经元会获得两个父基因提供的神经元的突触,并且基于 mutationRate 配置参数,可能会使突触产生变化。
/**
* Breed to genomes to produce offspring(s).
*
* @param {g1} Genome 1.
* @param {g2} Genome 2.
* @param {nbChilds} Number of offspring (children).
*/
Generation.prototype.breed = function (g1, g2, nbChilds) {
var datas = [];
for (var nb = 0; nb < nbChilds; nb++) {
// Deep clone of genome 1.
var data = JSON.parse(JSON.stringify(g1));
for (var i in g2.network.weights) {
// Genetic crossover
// 0.5 is the crossover factor.
// FIXME Really should be a predefined constant.
if (Math.random() <= 0.5) {
data.network.weights[i] = g2.network.weights[i];
}
}
// Perform mutation on some weights.
for (var i in data.network.weights) {
if (Math.random() <= self.options.mutationRate) {
data.network.weights[i] += Math.random() *
self.options.mutationRange *
2 -
self.options.mutationRange;
}
}
datas.push(data);
}
return datas;
}以 mutationRange 为 0.5 为例,突触的变化范围在 (-0.5, 0.5)。
Generations 负责记录当代个体和生成下一代所有个体,它具有如下几个方法:
| 方法 | 描述 |
|---|---|
| firstGeneration | 生成初代 |
| nextGeneration | 生成下一代 |
| addGenome | 往最新一代中添加基因(个体) |
另外 Generations 还有一个同名的属性 generations,是一个数组,用于存放当代个体的最终状态。
每一代生成后,同时会向 generations 数组中插入一个空的 Generation 实例。在当代的个体存活失败时,通过 addGenome 方法生成新的基因,该基因保存了传入的神经网络数据,然后根据 score 值排序候放入 Generation 实例的 genomes 数组中。
由于使用了多处同名函数,这里的逻辑是有点绕的,可以仔细阅读代码辅助理解。
最后我们再看下游戏是如何和框架集成的。
从 game.js 文件看,首先是初始化 Neuroevolution 框架。
Neuvol = new Neuroevolution({
population:50,
network:[2, [2], 1],
});游戏中每一代生成 50 个个体,输入层 2 个神经元,1 层隐藏层,含有 2 个神经元,输出层 1 个神经元。
游戏开始时,会调用 nextGeneration 方法生成个体,然后根据个体数量产生对应游戏中的 bird 实例(游戏中一个鸟配一个神经网络)。
游戏过程中,会不断调用 bird 对应 network 实例的 compute 方法,根据输出值判断是否需要执行 flap 方法。也就是鸟会根据其神经网络的输出值判断是否进行跳跃。
然后在判断存活失败时,会对鸟的神经网络打分(当前的游戏分数),用以在当代个体中排序。
最后当当代个体全部失败后,游戏会重新调用 start 方法,使用游戏重新开始。但是这时的神经网络已经完成了一代的进化。
if(this.birds[i].isDead(this.height, this.pipes)){
this.birds[i].alive = false;
this.alives--;
//console.log(this.alives);
Neuvol.networkScore(this.gen[i], this.score);
if(this.isItEnd()){
this.start();
}
}神经网络进化只是机器学习中的一种实现方式,还有很多实现方式,包括强化学习、规则学习、计算学习等,而仅就神经网络形式而言,也有 RBF (Radial Basis Function,径向基函数)网络、ART (Adaptive Resonance Theory,自适应谐振理论)网络、深度学习等常见的神经网络。
如果大家有兴趣,推荐阅读周志华教授编著的《机器学习》一书。
在我们大部门前端团队多,人员多,仅1个版本仓库(不包括其中子模块)的背景下,当前使用的 GIT 工作流有点不适应眼下规模,容易产生问题。
这里总结过往经验,给出一个规范指导,欢迎一起探讨。
纯理论的论述一个规范不光是很枯燥和乏味的,也难以让人直观理解,这里我以一个假设作为规范的背景。
假设我们工程下目前正有 3 个团队在进行 3 个不同版本的功能开发,如图:

背景设定,图中可以看到,3 个团队都在进行 3 个版本的开发,所有功能版本分散在 4 个变更窗口中。
再假设人员充足的前提下,各团队对各功能同时进行开发,为了确保开发测试流程通畅,需要新建名称包含变更日期的分支作为功能回归分支,分支基于上一次变更的稳定版本。
新建功能回归分支:(create branch)
b20171102b20171109b20171116b20171123这些分支分别用于各版本功能的回归测试。
各团队在开发过程伊始,先基于上一次变更的稳定版本新建开发分支,分支名称中体现团队、功能和变更时间,以 team1 为例:
team1_fe1_20171102team1_fe2_20171109team1_fe3_20171116团队维度主要是为了能够区分团队,功能维度是为了区别开发的功能,时间维度用于判断分支最后 Merge 到哪一个回归分支上。
当开发工作完成进入测试阶段时,需要进行的回归过程如下:
各团队将需要回归的分支拉取对应的回归分支进行代码更新和整合(fetch & pull),然后将代码提交(push)到回归分支。
图示:

图中可以看到,各版本的开发分支被合到回归分支上。
分支合并完成后,在前端 CI 项目中修改构建配置,构建对应分支进行测试。
变更完成后需要将当期变更的版本往 develop 分支合并,大版本可以打上 tag 作为标记。
对于已完成使命的开发和回归分支,应当进行定期清理。
欢迎大家一起探讨。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
