![]()
| package |  |
| tests | |
| docs | |
| license |  |
| stats | |
| support | |
| languages | |
| mirror | |
| funding |
FEDOT is an open-source framework for automated modeling and machine learning (AutoML) problems. This framework is distributed under the 3-Clause BSD license.
It provides automatic generative design of machine learning pipelines for various real-world problems. The core of FEDOT is based on an evolutionary approach and supports classification (binary and multiclass), regression, clustering, and time series prediction problems.

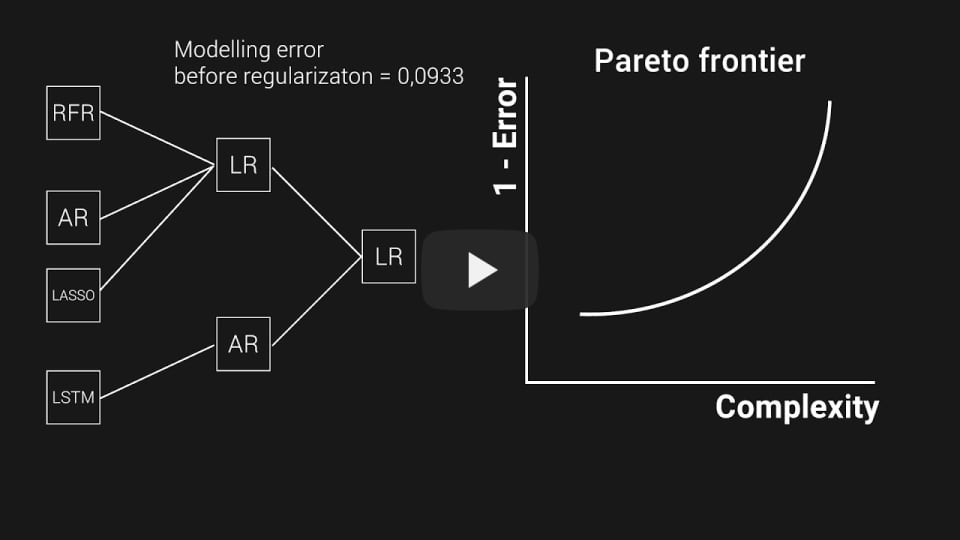
The key feature of the framework is the complex management of interactions between various blocks of pipelines. It is represented as a graph that defines connections between data preprocessing and model blocks.
The project is maintained by the research team of the Natural Systems Simulation Lab, which is a part of the National Center for Cognitive Research of ITMO University.
More details about FEDOT are available in the next video:
- Flexibility. FEDOT can be used to automate the construction of solutions for various problems, data types (texts, images, tables), and models;
- Extensibility. Pipeline optimization algorithms are data- and task-independent, yet you can use special strategies for specific tasks or data types (time-series forecasting, NLP, tabular data, etc.) to increase the efficiency;
- Integrability. FEDOT supports widely used ML libraries (Scikit-learn, CatBoost, XGBoost, etc.) and allows you to integrate custom ones;
- Tuningability. Various hyper-parameters tuning methods are supported including models' custom evaluation metrics and search spaces;
- Versatility. FEDOT is not limited to specific modeling tasks, for example, it can be used in ODE or PDE;
- Reproducibility. Resulting pipelines can be exported separately as JSON or together with your input data as ZIP archive for experiments reproducibility;
- Customizability. FEDOT allows managing models complexity and thereby achieving desired quality.
- Package installer for Python pip
The simplest way to install FEDOT is using pip:
$ pip install fedotInstallation with optional dependencies for image and text processing, and for DNNs:
$ pip install fedot[extra]- Docker container
Available docker images can be found here here.
FEDOT provides a high-level API that allows you to use its capabilities in a simple way. The API can be used for classification, regression, and time series forecasting problems.
To use the API, follow these steps:
- Import
Fedotclass
from fedot.api.main import Fedot- Initialize the Fedot object and define the type of modeling problem. It provides a fit/predict interface:
Fedot.fit()begins the optimization and returns the resulting composite pipeline;Fedot.predict()predicts target values for the given input data using an already fitted pipeline;Fedot.get_metrics()estimates the quality of predictions using selected metrics.
NumPy arrays, Pandas DataFrames, and the file's path can be used as sources of input data. In the case below, x_train, y_train and x_test are numpy.ndarray():
model = Fedot(problem='classification', timeout=5, preset='best_quality', n_jobs=-1)
model.fit(features=x_train, target=y_train)
prediction = model.predict(features=x_test)
metrics = model.get_metrics(target=y_test)More information about the API is available in the documentation section and advanced approaches are in the advanced section.
Jupyter notebooks with tutorials are located in examples repository. There you can find the following guides:
- Intro to AutoML
- Intro to FEDOT functionality
- Intro to time series forecasting with FEDOT
- Advanced time series forecasting
- Gap-filling in time series and out-of-sample forecasting
- Hybrid modelling with custom models
Notebooks are issued with the corresponding release versions (the default version is 'latest').
Also, external examples are available:
Extended examples:
- Credit scoring problem, i.e. binary classification task
- Time series forecasting, i.e. random process regression
- Spam detection, i.e. natural language preprocessing
- Wine variety prediction with multi-modal data
Also, several video tutorials are available available (in Russian).
We also published several posts devoted to different aspects of the framework:
In English:
- How AutoML helps to create composite AI? - towardsdatascience.com
- AutoML for time series: definitely a good idea - towardsdatascience.com
- AutoML for time series: advanced approaches with FEDOT framework - towardsdatascience.com
- Winning a flood-forecasting hackathon with hydrology and AutoML - towardsdatascience.com
- Clean AutoML for “Dirty” Data - towardsdatascience.com
- FEDOT as a factory of human-competitive results - youtube.com
- Hyperparameters Tuning for Machine Learning Model Ensembles - towardsdatascience.com
In Russian:
- Как AutoML помогает создавать модели композитного ИИ — говорим о структурном обучении и фреймворке FEDOT - habr.com
- Прогнозирование временных рядов с помощью AutoML - habr.com
- Как мы “повернули реки вспять” на Emergency DataHack 2021, объединив гидрологию и AutoML - habr.com
- Чистый AutoML для “грязных” данных: как и зачем автоматизировать предобработку таблиц в машинном обучении - ODS blog
- Фреймворк автоматического машинного обучения FEDOT (Конференция Highload++ 2022) - presentation
- Про настройку гиперпараметров ансамблей моделей машинного обучения - habr.com
In Chinese:
- 生成式自动机器学习系统 (presentation at the "Open Innovations 2.0" conference) - youtube.com
The latest stable release of FEDOT is in the master branch.
The repository includes the following directories:
- Package core contains the main classes and scripts. It is the core of the FEDOT framework
- Package examples includes several how-to-use-cases where you can start to discover how FEDOT works
- All unit and integration tests can be observed in the test directory
- The sources of the documentation are in the docs directory
Currently, we are working on new features and trying to improve the performance and the user experience of FEDOT. The major ongoing tasks and plans:
- Implementation of meta-learning based at GNN and RL (see MetaFEDOT)
- Improvement of the optimisation-related algorithms implemented in GOLEM.
- Support for more complicated pipeline design patters, especially for time series forecasting.
Any contribution is welcome. Our R&D team is open for cooperation with other scientific teams as well as with industrial partners.
Also, a detailed FEDOT API description is available in Read the Docs.
- The contribution guide is available in this repository.
We acknowledge the contributors for their important impact and the participants of numerous scientific conferences and workshops for their valuable advice and suggestions.
- The optimisation core implemented in GOLEM repository.
- The prototype of the web-GUI for FEDOT is available in the FEDOT.WEB repository.
- The prototype of FEDOT-based meta-AutoML in the MetaFEDOT repository.
- Telegram channel for solving problems and answering questions about FEDOT
- Natural System Simulation Team
- Anna Kalyuzhnaya, Team leader ([email protected])
- Newsfeed
- Youtube channel
- @article{nikitin2021automated,
title = {Automated evolutionary approach for the design of composite machine learning pipelines}, author = {Nikolay O. Nikitin and Pavel Vychuzhanin and Mikhail Sarafanov and Iana S. Polonskaia and Ilia Revin and Irina V. Barabanova and Gleb Maximov and Anna V. Kalyuzhnaya and Alexander Boukhanovsky}, journal = {Future Generation Computer Systems}, year = {2021}, issn = {0167-739X}, doi = {https://doi.org/10.1016/j.future.2021.08.022}}
- @inproceedings{polonskaia2021multi,
title={Multi-Objective Evolutionary Design of Composite Data-Driven Models}, author={Polonskaia, Iana S. and Nikitin, Nikolay O. and Revin, Ilia and Vychuzhanin, Pavel and Kalyuzhnaya, Anna V.}, booktitle={2021 IEEE Congress on Evolutionary Computation (CEC)}, year={2021}, pages={926-933}, doi={10.1109/CEC45853.2021.9504773}}
Other papers - in ResearchGate.





![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")








































































































































