I'm interested in Rust, Go, good at designing & writing distributed system.
🔭 And I’m currently working on building resource&traffic scheduling and faas infrastructure using Go and Rust at ByteDance in Hangzhou.
人们往往接受流行,不是因为想要与众不同,而是因为害怕与众不同
Home Page: http://digitalpie.cf





























































































































































Note:第一篇bitcoin日志中介绍了JSON-RPC,
同时记录了启动bitcoind的基本方法。
使用bitcoin-explorer获取block chain中的数据,加以分析处理。这一过程的最开始就利用了JSON-RPC。拿insight为例,其后台insight-api中的核心bitcore就是用来和bitcoind进程通信的,而通信的方式就是JSON-RPC:insight进程向bitcoind进程发送RPC指令,并在回调中得到想要的数据,然后呈现给上层应用做数据可视化。
JSON-RPC协议的本质仍是HTTP协议,也就是说JSON-RPC在HTTP基础上进行通信的。
在2013年更新了2.0版本,bitcoind使用的就是JSON-RPC 2.0
jsonrpc: 用来指定JSON-RPC的版本,必须为2.0
method: 需要调用的方法名
params: 参数数组,
id: 由客户端建立的rpc标识符
jsonrpc: 同上
result: 服务器返回的结果,如果出现错误,就没有这个字段
error: 一个JSON对象,如果调用成功则没有这个字段
id: 与请求的id相同(如果请求失败,id为null)
客户端在同一时刻发送多个请求对象,这些请求对象包装在一个数组中。这时服务器返回的也是个数组,包含对应请求对象的响应。
client => [
{"jsonrpc": "2.0", "method": "sum", "params": [1,2,4], "id": "1"},
{"jsonrpc": "2.0", "method": "notify_hello", "params": [7]},
{"jsonrpc": "2.0", "method": "subtract", "params": [42,23], "id": "2"},
{"foo": "boo"},
{"jsonrpc": "2.0", "method": "foo.get", "params": {"name": "myself"}, "id": "5"},
{"jsonrpc": "2.0", "method": "get_data", "id": "9"}
]
server => [
{"jsonrpc": "2.0", "result": 7, "id": "1"},
{"jsonrpc": "2.0", "result": 19, "id": "2"},
{"jsonrpc": "2.0", "error": {"code": -32600, "message": "Invalid Request"}, "id": null},
{"jsonrpc": "2.0", "error": {"code": -32601, "message": "Method not found"}, "id": "5"},
{"jsonrpc": "2.0", "result": ["hello", 5], "id": "9"}
]
它是中本聪编写的BTC客户端,也是第一个BTC客户端。实现了BTC的相关协议,并提供了RPC通信接口,允许本机进程或远程主机与其通信。
为了方便起见,把bitcoind添加到alias:
echo "alias btcrpc=$HOME/bitcoind -conf=$HOME/bitcoin.conf" >> .bashrc
bitcoind提供了一大堆RPC API,列表详见:
https://en.bitcoin.it/wiki/Original_Bitcoin_client/API_Calls_list
通过help命令也可以获取:
btcrpc help
addmultisigaddress nrequired ["key",...] ( "account" )
addnode "node" "add|remove|onetry"
backupwallet "destination"
createmultisig nrequired ["key",...]
createrawtransaction [{"txid":"id","vout":n},...] {"address":amount,...}
decoderawtransaction "hexstring"
decodescript "hex"
dumpprivkey "bitcoinaddress"
dumpwallet "filename"
encryptwallet "passphrase"
getaccount "bitcoinaddress"
getaccountaddress "account"
getaddednodeinfo dns ( "node" )
getaddressesbyaccount "account"
getbalance ( "account" minconf )
getbestblockhash
getblock "hash" ( verbose )
getblockcount
getblockhash index
getblocktemplate ( "jsonrequestobject" )
getconnectioncount
getdifficulty
getgenerate
gethashespersec
getinfo
getmininginfo
getnettotals
getnetworkhashps ( blocks height )
getnewaddress ( "account" )
getpeerinfo
getrawchangeaddress
getrawmempool ( verbose )
getrawtransaction "txid" ( verbose )
getreceivedbyaccount "account" ( minconf )
getreceivedbyaddress "bitcoinaddress" ( minconf )
gettransaction "txid"
gettxout "txid" n ( includemempool )
gettxoutsetinfo
getunconfirmedbalance
getwork ( "data" )
help ( "command" )
importprivkey "bitcoinprivkey" ( "label" rescan )
importwallet "filename"
keypoolrefill ( newsize )
listaccounts ( minconf )
listaddressgroupings
listlockunspent
listreceivedbyaccount ( minconf includeempty )
listreceivedbyaddress ( minconf includeempty )
listsinceblock ( "blockhash" target-confirmations )
listtransactions ( "account" count from )
listunspent ( minconf maxconf ["address",...] )
lockunspent unlock [{"txid":"txid","vout":n},...]
move "fromaccount" "toaccount" amount ( minconf "comment" )
ping
sendfrom "fromaccount" "tobitcoinaddress" amount ( minconf "comment" "comment-to" )
sendmany "fromaccount" {"address":amount,...} ( minconf "comment" )
sendrawtransaction "hexstring" ( allowhighfees )
sendtoaddress "bitcoinaddress" amount ( "comment" "comment-to" )
setaccount "bitcoinaddress" "account"
setgenerate generate ( genproclimit )
settxfee amount
signmessage "bitcoinaddress" "message"
signrawtransaction "hexstring" ( [{"txid":"id","vout":n,"scriptPubKey":"hex","redeemScript":"hex"},...] ["privatekey1",...] sighashtype )
stop
submitblock "hexdata" ( "jsonparametersobject" )
validateaddress "bitcoinaddress"
verifychain ( checklevel numblocks )
verifymessage "bitcoinaddress" "signature" "message"
ex:
btcrpc getpeerinfo
[
{
"addr" : "127.0.0.1:35629",
"services" : "00000001",
"lastsend" : 1400043134,
"lastrecv" : 1400043134,
"bytessent" : 3357058,
"bytesrecv" : 147242,
"conntime" : 1400039657,
"pingtime" : 0.00000000,
"version" : 70000,
"subver" : "/BitcoinX:0.1/",
"inbound" : true,
"startingheight" : 0,
"banscore" : 0
},
{
"addr" : "50.184.166.246:8333",
"services" : "00000001",
"lastsend" : 1400043145,
"lastrecv" : 1400043133,
"bytessent" : 122888,
"bytesrecv" : 800499,
"conntime" : 1400039658,
"pingtime" : 0.00000000,
"version" : 70001,
"subver" : "/Satoshi:0.8.6/",
"inbound" : false,
"startingheight" : 300640,
"banscore" : 0,
"syncnode" : true
},
{
"addr" : "67.212.92.167:8333",
"services" : "00000001",
"lastsend" : 1400043145,
"lastrecv" : 1400043125,
"bytessent" : 124584,
"bytesrecv" : 749619,
"conntime" : 1400039658,
"pingtime" : 0.00000000,
"version" : 70002,
"subver" : "/Satoshi:0.9.1/",
"inbound" : false,
"startingheight" : 300640,
"banscore" : 0
},
{
"addr" : "174.78.248.214:8333",
"services" : "00000001",
"lastsend" : 1400043134,
"lastrecv" : 1400043144,
"bytessent" : 119650,
"bytesrecv" : 388564,
"conntime" : 1400039659,
"pingtime" : 0.00000000,
"version" : 70002,
"subver" : "/Satoshi:0.9.1/",
"inbound" : false,
"startingheight" : 300640,
"banscore" : 0
},
{
"addr" : "89.98.93.137:8333",
"services" : "00000001",
"lastsend" : 1400043144,
"lastrecv" : 1400043119,
"bytessent" : 130925,
"bytesrecv" : 1011629,
"conntime" : 1400039666,
"pingtime" : 0.00000000,
"version" : 70002,
"subver" : "/Satoshi:0.9.1/",
"inbound" : false,
"startingheight" : 300640,
"banscore" : 0
},
{
"addr" : "199.115.176.18:8333",
"services" : "00000001",
"lastsend" : 1400043135,
"lastrecv" : 1400043127,
"bytessent" : 345728,
"bytesrecv" : 25299,
"conntime" : 1400039675,
"pingtime" : 0.00000000,
"version" : 50000,
"subver" : "",
"inbound" : false,
"startingheight" : 277595,
"banscore" : 0
},
{
"addr" : "108.53.129.182:8333",
"services" : "00000001",
"lastsend" : 1400043134,
"lastrecv" : 1400043144,
"bytessent" : 115329,
"bytesrecv" : 359246,
"conntime" : 1400039691,
"pingtime" : 0.00000000,
"version" : 70002,
"subver" : "/Satoshi:0.9.1/",
"inbound" : false,
"startingheight" : 300640,
"banscore" : 0
},
{
"addr" : "107.170.211.129:8333",
"services" : "00000001",
"lastsend" : 1400043144,
"lastrecv" : 1400043144,
"bytessent" : 133227,
"bytesrecv" : 992178,
"conntime" : 1400039697,
"pingtime" : 0.00000000,
"version" : 70001,
"subver" : "/Satoshi:0.8.5/",
"inbound" : false,
"startingheight" : 300640,
"banscore" : 0
},
{
"addr" : "24.159.17.178:8333",
"services" : "00000001",
"lastsend" : 1400043145,
"lastrecv" : 1400043005,
"bytessent" : 36944879,
"bytesrecv" : 130539,
"conntime" : 1400040379,
"pingtime" : 0.00000000,
"version" : 70002,
"subver" : "/Satoshi:0.9.1/",
"inbound" : false,
"startingheight" : 181817,
"banscore" : 0
}
]
注意JSON-RPC不仅仅通信使用JSON格式,得到的结果当然也是JSON格式的啦。
除了命令行的方式外,也有很多编程语言的wrapper以及curl工具:
这是最Raw的方法,可以看到RPC交互的数据格式:
curl --user user --data-binary '{"jsonrpc": "1.0", "id":"curltest", "method": "getinfo", "params": [] }'
-H 'content-type: text/plain;' http://127.0.0.1:8332/
返回:
{"result":{"balance":0.000000000000000,"blocks":59952,"connections":48,"proxy":"","generate":false,
"genproclimit":-1,"difficulty":16.61907875185736,"error":null,"id":"curltest"}
自然有人写模块啦,node下有很多wrap,这个例子(bitcoin模块)是来自官网的:
var bitcoin = require('bitcoin');
var client = new bitcoin.Client({
host: 'localhost',
port: 8332,
user: 'user',
pass: 'pass'
});
client.getDifficulty(function(err, difficulty) {
if (err) {
return console.error(err);
}
console.log('Difficulty: ' + difficulty);
});
闭包是JavaScript中的一个基本概念。咋一看感觉没什么了不起:不就是在函数中定义了一个嵌套函数,并且嵌套函数能够访问外部变量,然后这个嵌套函数就起个名叫Closure嘛~
没错,在计算机科学文献中闭包的定义不过如此,但你不一定会用。举个例子:
var 一只变量 = 'global';
function 只是测试() {
var 一只变量 = 'local';
function inside() {
return 一只变量;
}
return inside;
}
只是测试()();
在这个例子中外部函数返回了一个闭包inside,然后在全局作用域下调用了返回的这个函数,然后最终返回‘global’。
看上去很简单,不是么?
如果要真是这样的话那就没意思了。。。真实的情况是调用闭包后返回“local”!
为什么?正常情况下在全局声明了一个变量,然后在全局中调用一个函数:
function inside() {
return 一只变量;
}
理论上一只变量并没有在inside函数内部声明,因此他应该是个全局变量,这个函数应该返回‘global’才对啊~~
不过这次注意inside函数是怎么来的:在一个外部函数中返回了这个inside闭包!
我想曾经学过类C语言的同学会对其函数有这样的印象:当函数执行完毕后,其内部定义的任何变量都被释放,并且不允许任何外部引用接触到内部的变量。因此大部分人对JavaScript的闭包存有误解:即使返回了一个内部定义的函数,函数不过是函数,像个模型一样等着任意变量去填充,所以内部定义的变量应该与inside内的变量无关并且误认为应该已经被释放了。
不过C语言不是一门函数式语言,也没有Closure一说。
所以事实是这样的:inside被返回后,由于闭包的特性,它内部会保持对其外部变量的引用,并且函数中定义的局部变量就不会被释放。这里有段来自权威指南中的底层解释:
……基于栈的CPU架构:如果一个函数局部变量定义在CPU的栈中,那么当函数返回时他们就不存在了……
那么闭包如何做到引用外部函数定义的变量呢?下面来说说JavaScript中的作用域链。
在浏览器的全局作用域下,window为对应环境的全局变量,任何直接在该环境中声明或直接调用的变量都将成为window对象的属性。
类比window对象,可以这么理解作用域:每个作用域都对应着一个‘对象’,称其为‘该作用域的全局对象’。
因此,在函数中定义的变量可理解为该函数作用域的作用域对象的属性,也就是所说的变量属于这个局部作用域。
当作用域形成一级一级的嵌套,便形成了作用域链。它是一个由每个作用域对应的作用域对象链接而成的一个对象链表。
在顶级作用域window,作用域链就包含window对象,函数作用域内,作用域链至少包含window对象和当前作用域对象,当嵌套时还有更多的函数作用域对象挂载到链上。
作用域链的特点就是:1.每执行一次函数,都会新建一个作用域对象并挂载到作用域链上,这个作用域对象保存了当前环境下的局部变量和函数参数。这是很好理解的,因为每次执行同一个函数,他们之间的作用域都互不干扰。2.当函数执行完毕,就将这个作用域对象从作用域链中删除(也就是局部变量被释放无法使用),但这成立与否基于一个前提,也就是前面所说的是否返回闭包的情况。
有了作用域对象的概念,就能进一步说解释包调用了。
……如果函数体内不存在嵌套的函数……或者存在嵌套的函数但他们都在父函数中保留了下来……,那么等父函数返回时,对应的作用域对象便会被删除掉。……但如果存在嵌套函数,且父函数返回了这个闭包并被引用/调用(或者将这个闭包存储为一个属性)……这时,就会有一个外部引用指向这个嵌套函数,则这种情况下父作用域对象便不会被释放……
以上是来自权威指南中的一段关于‘闭包如何保存外部变量’的描述。
但究其作用域对象不被释放的根本,还需要词法作用域这个概念,其规则是:函数定义时的作用域链到函数执行时依然有效!
JavaScript函数执行时用到了作用域链,而这个作用域链是在函数定义时确定的。由于嵌套函数定义在函数作用域内,其作用域链包含父函数的作用域对象,所以不管在何时何地执行闭包,这条作用域链都是有效的!
这回闭包的profile是不是就清晰了呢?然后让我们来看看闭包在实际应用中最常见的问题——内存泄漏。
就在昨天,我在浏览器中测试的一段代码引发了内存泄露,并且无法阻止,最后只好关掉重启浏览器。也正是这次的经历,让我对内存泄漏记忆颇深,并且决对不是空谈。
所谓内存泄漏是指分配给应用的内存既 不能被回收 也 不能被重新分配利用 。
在内存管理的环境中,一个对象如果有访问另一个对象的权限(隐式或者显式),叫做一个对象引用另一个对象。 --from MDN
举个循环引用的例子,例如:
//obj1与obj2相互引用
var obj1, obj2;
obj1.pro = obj2;
obj2.pro = obj1;
//obj的自身引用
var obj;
obj.pro = obj;
// 函数作用域对象对外部对象的引用, 外部对象同样引用着函数
a= obj;
a.f = function () {};
引用计数垃圾收集
这是最简单的垃圾收集算法。此算法把“对象是否不再需要”简化定义为“对象有没有其他对象引用到它”。如果没有引用指向该对象(零引用),对象将被垃圾回收机制回收。
如果解释器采用了这种GC算法, 那么循环引用肯定会导致内存泄露, 因为目标对象的引用计数始终大于0. 不过这种算法已被现代浏览器所淘汰了, 大都经过改进, 结合了另一种GC算法:
标记-清除算法
这个算法把“对象是否不再需要”简化定义为“对象是否可以获得”。
假定设置一个叫做根的对象(在Javascript里,根是全局对象)。定期的,垃圾回收器将从根开始,找所有从根开始引用的对象,然后找这些对象引用的对象……从根开始,垃圾回收器将找到所有可以获得的对象和所有不能获得的对象。最后清除无法获得的对象.
正常来讲,这不会出现什么问题。但是当引用的对象之一关联着特占内存的大型数据(像超长字符串、超长哈希映射或DOM对象),问题就来了:
sth = null
rep = () ->
org = sth
unused = () -> org or null
sth =
str: [1..1000000].join ''
fun: () -> unused null
console.log process.memoryUsage()
setInterval rep, 1000这是一个蹩脚的由链式引用引起的内存泄漏。
从浏览器和Node环境下的内存监测来看,每次GC似乎都没有彻底释放内存,显然内存泄漏了。我们来分析一下代码看看这是为什么:
首先,我定义一个显式引用org的闭包unused并且没有调用它. org在rep函数的公共词法作用域中.
第二,sth和org一个道理, 会被unused隐式引用.
最后, unused能被sth.fun函数引用(虽然很明显这个函数没有使用它)。但是因为unused也在rep公共词法作用域内,fun还会保持对unused的引用。
这样就形成了一个链式引用:org指向上一次的sth, unused引用org,而sth.func引用了unused。在当前时刻, 全局变量sth的属性fun作用域中隐式引用了unused, 也就间接引用了unused作用域的引用.
理论上, 这样就保存了一个引用链:
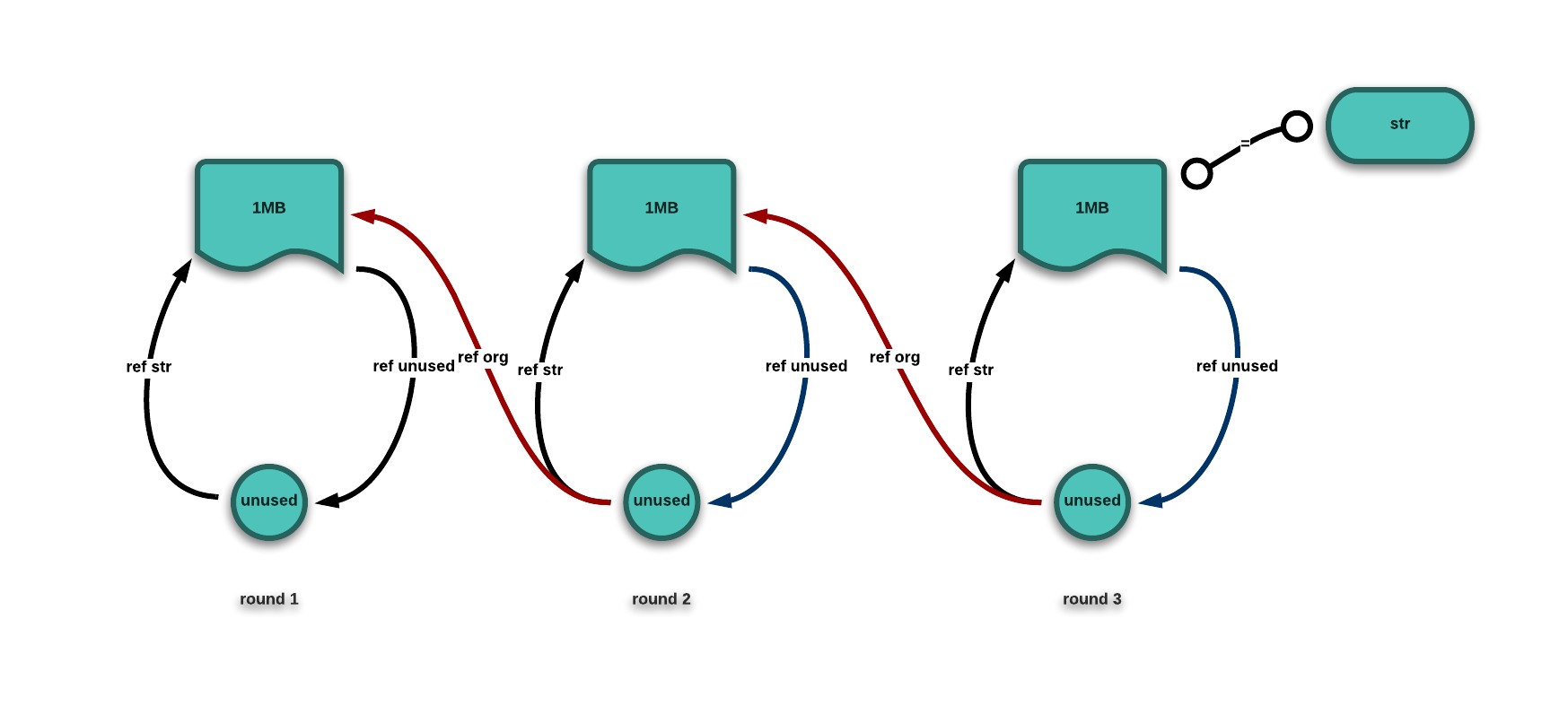
所以,尽管我们每次调用rep函数都会有一个新建的sth对象把sth覆盖,但有引用链的存在,原先的值不但永远不会被清除,还会在每秒不断增加循环调用的个数从而增加内存占用量.
那这个问题该如何解决?对此,有两个解决方案:
1.由于unused函数引用了org,所以可以从这里入手,把unused这个函数中的引用去掉,这样就没有循环引用的闭包了,也就没有泄漏了。
2.将unused和sth引用的根源org做下处理:
//在rep函数体最后加:
org = null;
我测试了100s内的内存占用情况变化, 并做了可视化:
其中灰色代表原始代码, 粉色代表方案二, 淡蓝色代表方案一
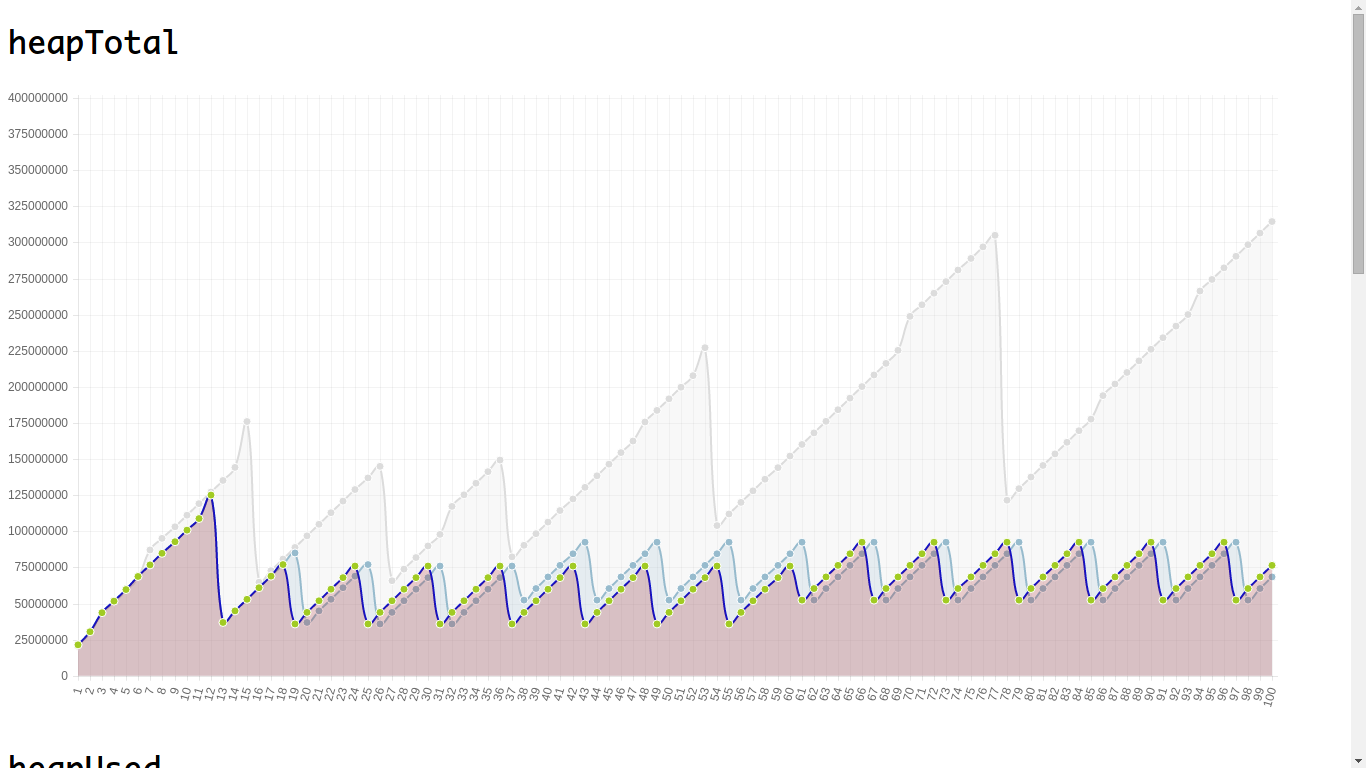
这与我们之前的分析稍微有些出入. 严格来讲, 现代JavaScript引擎已经做到足够智能和优化(就像之前提到的两个GC算法), 如果沿着全局对象不能访问到目标对象, 那么他将被标记为不可用, 因此将被GC. 这就是为什么灰色的原始曲线也会有大幅波动出现.
还没读V8GC的代码, 暂时有这两个猜测 (接下来两段为猜想...)
既然可以被GC, 那么灰色曲线的持续增长又是什么原因? 这里我只能猜测引用链里有显示引用(unused对org)的原因导致每次GC时无法做出准确判断到底该不该回收, 只好等到内存使用量太大并且程序确实不会再用到他们时才GC一次.
或者是GC可以回收那些内存, 只是速率不及内存使用的快, 并且对于包含显示引用的引用关系回收效果甚微(就是不能一次回收干净, 要一点点的拆除ref)
脑补结束, 欢迎指明误区并参与讨论!!
而对于两种解决方案来说, 第一种能够"化显为隐"(unused中不存在对org的显示引用了). 第二种则更直接的断开了引用链(被显示引用的org变成null), 导致上一次产生的str及不可访问又失去了最后一个引用. 这就能让GC快速准确的回收内存.
可以看出, 两种方案的效果基本一样, 内存占用基本保持在一个小范围内波动, 只不过_赋值null_能比_去掉unused引用_更早的进行垃圾收集. 但未经处理的代码就不一样的了, 可以清除的看到灰色区域的内存占用量始终成上涨趋势, 虽然可以看到有进行内存收集的迹象, 但仍抵不住疯狂增长的大潮.
再来看下面这个明显的例子:
//这是昨天我测试的用例2:
var run = function () {
//一个占1MB内存的字符串
var str = new Array(1000000).join(''*'');
var doSth = function () {
if (str === 'something')
console.log("str was something");
};
doSth();
var log = function () {
console.log('interval');
};
setInterval(log, 100);
};
setInterval(run, 1000);
显而易见,setInterval(run, 1000)执行后run函数将会在每秒执行一次;log函数将会在一秒内连续执行10次。
这里的setInterval(log, 100)保存了对log闭包的外部引用,因为str字符串在公共词法作用域内,所以log保持着对str的引用使str不会在run函数结束时被释放,并且在每次执行run时内存占用量都会增加。
(完)
椭圆曲线数字签名算法(ECDSA)为比特币系统运转的可靠基石.
私钥: 随机生成的32byte(256位)数字
公钥: 分为压缩公钥(33byte)和非压缩公钥(65byte)
签名: 对私钥进行HASH运算. 由签名和私钥可推出
地址: 为方便交易而使用的公钥替代物(25byte)
私钥→公钥→地址, 这一过程是不可逆推的.
tx hash id = SHA256(SHA256(tx data))
tx fee = sum(input) - sum(output)
/* 计算tx hash id
* in JavaScript
*/
hex = new Buffer(tx_data, 'hex');
B_hash = crypto.createHash('sha256').update(crypto.createHash('sha256').update(hex).digest()).digest();
// 将Big-Endian转化为Little-Endian
L_hash = Array.prototype.reverse.call(B_hash);
txid = L_hash.toString('hex');每个tx只会在best chain(主链)的某一个block里出现一次, 但可能出现在其他分支中.
每生成210000个block时(4年左右), 来自coinbase的奖励减半. 计算方法: 50 >> (height / 210000) + Fees
全网达到2100W个btc后将不再有coinbase的奖励, 而挖矿收入来源仅剩下Fees(交易矿工费)
BTC系统中, 产生coinbase即发行货币
block大约每10分钟生成一个, 时间由全网算力调整.
挖矿: 即工作量证明. 其实质为计算block hash(生成新的block)的过程, 成功(加入best chain)概率为n%, 即该节点算力占全网的百分比.
区块头(block header)包含"前一个block header的hash"(32byte), "该block中全部tx打包的hash"(32byte), "时间戳"(4byte), "难度"(4byte), "随机数"(4byte)
block hash计算方法: 将header连接得到16进制表示形式, 按little-endian存入内存, 两次SHA256计算得到hash, 最后逆序.
hex = new Buffer(header, 'hex');
hash = crypto.createHash('sha256').update(crypto.createHash('sha256').update(hex).digest()).digest();
revhash = Array.prototype.reverse.call(hash).toString('hex');分支博弈
因为多个挖矿节点的存在, 必然会导致不同block chain的产生, 而网络会根据如下优先级顺序来选取那条block chain作为主分支:
如果各挖各的矿, 会存在多分枝并存, 这时每个分支都有可能成为主链, 而算力最强的节点一定得到最长链. 如果一个节点的分支不是主分支, 则其收益也不会得到认可, 导致0收益. 所以为了降低此风险, 很多节点会联合在一起, 贡献一个分支, 使其保持最长.
多重消费问题
先用btc消费, 使tx进入一个block, 然后构造另一个包含该tx的block, 使相同的输入作为这个tx的输入, 而输出设定为自己的btc地址, 然后计算这个block hash, 并追赶主链, 一旦成功则相当于该tx包含的btc未花费, 就可以再次使用这些btc. 但攻击者能成功追赶并改变主链是一个小概率事件.
看完libuv对watchers和事件循环的描述之后,突然发现我一直以来忽略了一个问题:事件是通过什么方式被监听的?
无论是线程还是进程都和我们生物不同,他们不会自发感知外界环境的改变。所以对于这个问题,第一印象往往是:轮询。也就是用一个 while(true) 循环不断询问外部是否有什么新鲜事。
可问题是,我们从来没见过系统内核进程因为监听一個socket而导致CPU狂转、系统挂掉吧。还有,浏览器中监听JavaScript事件是常事,它也没让系统变卡顿啊。
单从这一点来看,轮询事件的产生并非上策!除了轮询,还有什么方法能做到事件的监听呢?或许我们可以从操作系统的底层——计算机硬件工作流程中找到答案。
操作系统在与外设进行交互是典型的事件监听:CPU与设备控制器之间有一条中断请求线,设备控制器会在外设I/O结束时通过电信号向CPU发送中断请求,CPU在原子指令过后检查中断线的状态位判断I/O是否结束,如果结束的话就跳转到内存特定进程位置(中断向量)调度中断处理程序。
我们先来简单分析一下底层的事件监听模型。所谓事件是由源发出,就是一个电信号(或脉冲信号)。进程虽然做不到监听,但硬件CPU却可以,它能接收到电信号的变化。最后CPU对事件做出反应,也就是调度处理进程。
没错,事件监听还可以靠中断来实现。
阻塞I/O、非阻塞I/O、同步I/O、异步I/O是操作系统的几大I/O模式。
我们往往会认为阻塞I/O与同步I/O等同,非阻塞I/O与异步I/O等同。其实这种观点是不准确的,这里科普一下他们的细微区别。
阻塞I/O,即进程/线程在做I/O操作时,被CPU调度到阻塞队列,等待I/O操作的结束,然后进程再被调度回来,处理I/O结果。在等待期间,进程除了休眠无法做任何事情,不过他不占用CPU时间片,这时CPU可以先调度其他进程,当I/O完成时以事件形式通知CPU。
非阻塞I/O与上述相反。进程不会一直等待到I/O操作结束,当I/O请求发出时,进程会立马从系统调用返回,这时进程可以继续工作,也就是CPU不必将其调度到阻塞队列了。但此时进程很可能还没有得到I/O结果,所以要通过轮询来检验I/O是否操作结束。虽说进程没有被阻塞,不过CPU的时间片被白白占用。
同步I/O,就是进程先等待I/O结果,再继续处理其他任务。所以说,同步I/O由阻塞I/O实现。
而异步I/O与非阻塞I/O的差别就是:前者的I/O调用在不阻塞进程的前提下完整的执行,后者的I/O调用为了不阻塞进程会立刻返回,即便是没有得到I/O最终结果。
上面提到的阻塞和非阻塞是针对_进程_而言的,和_CPU_的阻塞正好相反,这点必须要认清。
libuv在Linux平台上使用了Linux的_epoll_机制。epoll是Linux平台的I/O事件通知工具,主要用来处理大量的文件句柄。
libuv的事件循环特性就是由epoll提供的,先介绍一下epoll。
epoll的函数在头文件sys/epoll.h中。用epoll编写程序会用到两个数据结构:
/* 保存触发事件的某个文件描述符相关的数据 */
typedef union epoll_data {
void *ptr;
int fd;
__uint32_t u32;
__uint64_t u64;
} epoll_data_t;
和
/* 用于注册所感兴趣的事件和回传所发生待处理的事件 */
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};其中结构体epoll_event的events成员是表示感兴趣的事件和被触发的事件,可能的取值为:
EPOLLIN:表示对应的文件描述符可以读; EPOLLOUT:表示对应的文件描述符可以写; EPOLLPRI:表示对应的文件描述符有紧急的数据可读; EPOLLERR:表示对应的文件描述符发生错误; EPOLLHUP:表示对应的文件描述符被挂断; EPOLLET:表示对应的文件描述符有事件发生;
epoll提供的API有如下几个函数:
int epoll_create(int size)
创建一个epoll实例,并返回一个引用该实例的文件描述符。
int epoll_ctl(int epfd, int op, int fd, struct epoll_event* event)
在给定文件描述符增加、删除、修改事件。
int epoll_wait(int epfd, struct epoll_event* events, int maxevents, int timeout)
等待I/O事件,并阻塞调用线程。
最后一个timeout参数表示epoll_wait的超时条件,为0时表示马上返回,为-1时表示函数会一直等下去直到有事件返回,为任意正整数时表示等这么长的时间,如果一直没有事件,则会返回。
对于这几个函数的使用,man手册里给出一个很有代表性的例子:
#define MAX_EVENTS 10
struct epoll_event ev, events[MAX_EVENTS];
int listen_sock, conn_sock, nfds, epollfd;
/* Set up listening socket, 'listen_sock' (socket(),
bind(), listen()) */
epollfd = epoll_create(10);
if (epollfd == -1) {
perror("epoll_create");
exit(EXIT_FAILURE);
}
ev.events = EPOLLIN;
ev.data.fd = listen_sock;
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, listen_sock, &ev) == -1) {
perror("epoll_ctl: listen_sock");
exit(EXIT_FAILURE);
}
/* 这里相当于事件循环的开始,epoll先阻塞进程,等待指定事件到来 */
for (;;) {
nfds = epoll_wait(epollfd, events, MAX_EVENTS, -1);
if (nfds == -1) {
perror("epoll_pwait");
exit(EXIT_FAILURE);
}
/* 一旦事件触发,继续事件循环,这里获取事件触发时的数据 */
for (n = 0; n < nfds; ++n) {
if (events[n].data.fd == listen_sock) {
conn_sock = accept(listen_sock,
(struct sockaddr *) &local, &addrlen);
if (conn_sock == -1) {
perror("accept");
exit(EXIT_FAILURE);
}
setnonblocking(conn_sock);
ev.events = EPOLLIN | EPOLLET;
ev.data.fd = conn_sock;
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, conn_sock,
&ev) == -1) {
perror("epoll_ctl: conn_sock");
exit(EXIT_FAILURE);
}
} else {
do_use_fd(events[n].data.fd);
}
}
}然后我们回过头看看Node(或者说libuv)内部是如何实现事件循环、事件监听、异步回调的。
libuv负责从操作系统那里收集事件或监视其他资源的事件,而用户可以注册在某个事件发生时要调用的回调函数。
监视器(Watchers)是 libuv 用户用于监视特定事件的工具。他们都是以 uv_TYPE_t 命名的抽象结构体,这个类型表明了监视器的用途。
下面是所有的监视器(也称作事件处理器)列表:
typedef struct uv_loop_s uv_loop_t;
typedef struct uv_err_s uv_err_t;
typedef struct uv_handle_s uv_handle_t;
typedef struct uv_stream_s uv_stream_t;
typedef struct uv_tcp_s uv_tcp_t;
typedef struct uv_udp_s uv_udp_t;
typedef struct uv_pipe_s uv_pipe_t;
typedef struct uv_tty_s uv_tty_t;
typedef struct uv_poll_s uv_poll_t;
typedef struct uv_timer_s uv_timer_t;
typedef struct uv_prepare_s uv_prepare_t;
typedef struct uv_check_s uv_check_t;
typedef struct uv_idle_s uv_idle_t;
typedef struct uv_async_s uv_async_t;
typedef struct uv_process_s uv_process_t;
typedef struct uv_fs_event_s uv_fs_event_t;
typedef struct uv_fs_poll_s uv_fs_poll_t;
typedef struct uv_signal_s uv_signal_t;监视器是通过调用uv_TYPE_init(uv_TYPE_t*)函数来创建。
Note:如上所示,有些监视器初始化函数要用事件循环作为第一个参数。
让监视器监听事件则调用:uv_TYPE_start(uv_TYPE_t*, callback)
而停止监听则调用:uv_TYPE_stop(uv_TYPE_t*)
回调函数是当监视器感兴趣的事件发生时,由 libuv 调用的函数。应用程序指定的逻辑一般会在回调函数中的实现。
只要有活动的监视器,事件循环就会一直运行。没有活动的事件监视器, uv_run() 退出。
ex:
#include <stdio.h>
#include <uv.h>
int64_t counter = 0;
void wait_for_a_while(uv_idle_t* handle, int status) {
counter++;
if (counter >= 10e6)
uv_idle_stop(handle);
}
int main() {
uv_idle_t idler;
uv_idle_init(uv_default_loop(), &idler);
uv_idle_start(&idler, wait_for_a_while);
printf("Idling...\n");
uv_run(uv_default_loop(), UV_RUN_DEFAULT);
return 0;
}系统运行中会在监视器启动时给事件循环引用计数加 1,而在监视器停止时给事件循环引用减 1。也可以手动修改处理器引用计数:
void uv_ref(uv_handle_t*);
void uv_unref(uv_handle_t*);使用这些函数可让事件循环在监视器处于活动状态下退出,或让事件循环使用自定义对象来维持其活动状态。
在笔记1中介绍了Node主线程与libuv I/O线程、事件循环的协作关系,这里我们总结一下Node的工作原理。
在Node启动时,主线程内先初始化一些必要的Watchers,比如I/O Watchcers,然后解析js文件,调用相应的libuv函数,最后执行libuv的事件循环函数,先检查watchers队列是否有到来的事件,有就在当前线程中处理,没有阻塞主线程,等待事件唤醒(epoll实现)。
对于js文件中调用libuv函数的语句,将会执行相应函数,利用epoll机制开启一系列I/O线程,设置watchers的回调函数,调用底层API,并进入阻塞态等待调用结束。系统调用结束,返回结果,I/O线程将返回结果赋给watchers回调函数的参数。同时向epoll机制提交状态。
主线程中epoll将再次激活事件循环,从阻塞处向下执行:调用watchers的回调函数。直到再次阻塞在epollwait那里(如果程序并没有设置listen,事件循环在下次检测不到新的事件时就退出循环(引用计数减1),结束程序,例如“文件读取”。如果http上调用了listen函数,将会不断的检测事件的到来~,即引用计数保持为1)。
上面讲的情况都是I/O,可是事件循环处理的事件不仅仅是I/O事件,还包括process.nextTick产生的Idle事件,计时器的定时事件,setImmediate的check事件。
而我们发现了一个优先级顺序:idle观察者 > I/O观察者 > check观察者。也就是说事件循环每次都是按这个顺序来依次检查watchers的。
进一步的实验我们将会发现:idle观察者和I/O观察者将会在一次事件循环中调用队列中的所有回调函数,而check观察者每次之调用队列头中的回调函数。
读了两年大学,突然发现我们现在最缺的就是ideas。在多方_邪恶势力_的压迫下逐渐丧失了发现事物,思考问题,解决问题的能力,对周围的东西找不出关键点,对一个新技术不知道该怎么把玩能发挥其价值。一句话:没有猎奇心理。
话说,没有创意生活还有什么乐趣???
没有创意,做项目真的是在浪费时间,不如去搞搞科研呢。写几个模块,库,框架。
信息化时代的一大特点就是快速的资源共享,说的更有价值点就是知识的共享。twitter、facebook之类社交网络的火爆可以在一定程度上反应信息涟漪的扩散速度之快。这说明大多数人都喜爱聚集在一起balabala。第二大特点是信息获取方便,手边常备Google,连小白都可以装大牛 ;)
如何搜集、挖掘并利用网络上分散的碎片化信息呢?要想对网络上海量的信息做集中化分析归类处理真的很难,我想这不是我们现在该考虑的。我们应该让每个人自觉的做信息归类。
这个想法是受BitCoin的启发。BitCoins从诞生到交易,都是由用户自己的工作去完成和证实的,其整个一条区块链记录了从第一个BitCoin诞生起到现在的交易阶段的全部用户的交易信息:每个用户可以验证交易区块的正确性,一旦验证无误,将会得到一定数量BitCoins的奖励。当然这是相当耗时耗财的,因此没人愿意费力不讨好。
因为bitcoin的获取,促使人们自觉的付出劳动力去做block正确性验证,然而这一过程恰恰做到了BitCoins交易信息归档,而且是由网络上每个BitCoins用户完成的。对于每个idea的贡献也是如此:贡献者不但会了解网络中其他人经过几番讨论或深思熟虑的想法还会因自己的idea贡献而得到某种奖励。
这种思路正是P2P网络架构体系的核心:去中心化。每个节点都可以从其他各个节点获取自己想要的信息,同时作为等价节点,他也可以提供自己的信息给他人,至于信息的划分归类归档,全靠每个节点的贡献来完成,而相对的中心节点则仅仅存储分支/节点的地址。
对于好的idea,可以fork,正如GitHub上repo的fork,可以发送pull request,还可以可以merge…。就是说主分支如果满意子分支的提交,可以允许合并。
不同的idea在主分支上有自己的唯一节点,一个idea分支会记录这个idea不断完善,创新,衍生的过程以及每个人的贡献和基于该idea诞生的projects等等。
最终形成的是ideas结构化体系,做到了自动为不同的idea分类整理归档。最终形成一颗条理清晰的知识结构树。
合理利用idea进行分支、演化,取众家之精华,丰富每个idea并让它变得更有意义。
每个idea开始都是一个节点,不断进行add的话,会grown成一个链,这个idea会越来越丰富,可用之处会越来越多。当达到一定规模时,必然会有副产ideas出现,这时可以进行fork:将会产生一个新的子分支,这个idea是父idea的超集。当然,整个idea可以是private的:),仅供队友之间修改。
和个人记事,日程管理,团队协作等等工具的不同之处就是:核心不是存储想法也不是项目管理,而是建立在社交涟漪模型上进行折射分享,以ideas为社交目的,让每个感兴趣的人参与进来,形成一个ideas共享树。
没有圈子、好友、留言、个人信息。有创建的idea分支,标签,建议,贡献内容,应用idea的项目。
最开始时会有一个主干节点,我们会在上面添加初始的idea集合初步形成一个分支。每个org或个人都有权限修改这个主分支。
我们每隔一段时间搜集生活中的细节,互联网上的变革,通过算法选取那些值得思考的关键词,最后推送到主干分支上。
参与人数增长率特快的idea暂时将会排名上升,一旦人数足够多将稳定排名一段时间,而那些新生的idea应该靠前排名,贡献者、参观者数量波动小的idea暂时将会下降排名。
NOTE1: 关于剽窃他人创意这个问题自古以来就有。主要和个人素质、占有欲、控制欲、自私心理有关。
如果想剽窃他人的idea,不如贡献一下自己的点子吧,和他们一起完善这个idea,并从这个idea中分支出自己的:)
实在不行就面壁吧~~
我可以创建一个idea,随意描述想法,并直接扩展出已想好的子分支,然后我就成为这个idea树的创始人。这颗idea树可能会在explorer里出现。这时恰巧你也在考虑这个问题,或想寻找有关这个idea的讨论,然后你就发现了这个idea,你不能删掉我创建的分支、节点,但你可以修改(讨论)或直接fork成你的,并在此基础上删改。
别忘了,人类是地球上最富有创造力的群体,他们发明了汽车与电灯,改进了工具使用方式。各具特色而又层出不穷的创新,将人类文明一步步推向巅峰。归根结底创造力是我们不可或缺的东西、上帝给予我们的最佳馈赠。
NOTE2:incbrain,可以解释成increasing brain 或 brain with innovation and creative
fix bugs:
新增功能:
今天简单的看了看色彩学和颜色理论,终于明白视觉错觉和基色选择的原理,涨了不少姿势。
在玩前端时没少和颜色打交道,大多时间里也都是选选配色。其实我觉得配色不仅仅是看着颜色表一个个试,还应该有混色计算,补色计算等等,例如你想写一个图像处理的软件,其中的反色,混色,颜色渐变等等就需要考虑了。
高中物理讲过,“红(R)、绿(G)、蓝(B)” 是光的三原色,也称三基色。在做网页配色时常见的RGB值指的就是红绿蓝三色各自强度值以16进制表示的拼接值。
三种色光按不同比例混合就能得到所有颜色(七色)的色光,而同等强度的三基色混合,就会出现灰色,灰色代表一个范围(不含色光):[ 纯黑, 纯白 ],其间任何一种颜色都属于灰色。
要说混色理论,首先得了解一些颜色的基础知识。
除了三基色RGB,还有另外一种三基色CMY。按人眼能观察到的颜色来源分类,前者属于光源三基色,如灯光、显示器;而后者属于染料三基色:青(C)、洋红(M)、黄(Y),如报纸、书等本身不发光的物体。
其实染料三基色也是基于光源三基色而得到的。因为青色吸收红色,洋红吸收绿色,黄色吸收蓝色,这样就再次组成了红绿蓝三基色,通过控制CMY各自的强度,同样达到产生各种色彩。
下面简单介绍RGB三原色的混色计算。
由于不同波长的色光叠加会产生另一种色光,而且这一叠加可能蕴含某种规律。我们将三原色各自的强度以二位16进制数字表示,也就是将强度人为分成256个点。先从最简单的黑色#000000,白色#FFFFFF考虑。黑色是三色皆尽,白色是三色至上,而#000000 + #FFFFFF = #FFFFFF,也就是说“在伸手不见五指的黑夜里手电筒里射出的是白光”,数字的设定恰好符合感官的描述。
对于基本的混色计算,我们可以从单一颜色来分解:比如颜色值#60b044,可以拆成颜色1#600000、颜色2#00b000以及颜色3#000044三色光的叠加,当然,其他值的组合也行,只要满足R的加和是60,G的加和时b0,B的加和是44。所以,任意色的普通混色就是对应相加。
CMY的同理,只不过是RGB的补色运算,即:
CMY:(x,y,z) => RGB:(#FF-x,#FF-y,#FF-z)
这样我们就可以写一个混色函数:
function mix(ca, cb) {
r = ca >> 16 + cb >> 16
g = ca & 0xff00 >> 8 + cb & 0xff00 >> 8
b = ca & 0xff + cb & 0xff
return (r > 0xff ? 0xff : r) << 16 + (g > 0xff ? 0xff : g) << 8 + b > 0xff ? 0xff : b;
}bobobob
历经3个月yinle.me终于能以正常的姿态见人了。idea最初起源于一个已经不在Lab的学长,我对这个想法很感兴趣(已经被打印问题困扰很久了),想想今后要是能用上这样一个东西,打印岂不是美哉快哉?
从寒假开始写前端的逻辑&UI,为了加快响应时间、提高脚本效率,同时保持松耦合以及模块化,我重头到尾写了yinle的前端逻辑框架、动态响应式布局外加一个独立的拖拽事件库。技术栈的这一层真没少下工夫。
后台业务处理部分我们最初选择了Ruby Sinatra框架,这一块是由另一位同学负责,后来因其为忙于其他多个项目,Lab里个忙各的,最后不得不交由我来搞。对Ruby代码,刚开始看着挺清晰,但是越看越迷茫…也不能现学现做吧。折腾了一两天,把代码写的乱七八糟,自己都不忍直视了。。于是我决定,干脆拿Node.js重写一遍算了,总比在这里纠结好。
我也是急急忙忙敲了一晚上,把原型做出来了。第二天陆陆续续修正bugs,增加安全机制,过滤检测模块。下午部署到了Lab服务器上,在内部测试了一下,绑定域名,然后就这样上线了。
说实话,当时心里还是有点没底,毕竟匆忙上线,还不知道有什么问题。昨晚模拟了一次次攻击,对一些模块进行了反复的测试,终于有点信心了,然后做了小范围的宣传。
目前功能:
细节更新:
bugs fixed:
安全性检测:
近两年用Node写过几个web应用。过程远比预期的困难,涉及到了HTTP协议、TCP/IP协议、WebSocket协议等计算机网络知识,MongoDB、noSQL、schema设计等NoSQL数据库知识,进程、线程、同步、异步、并发、阻塞、文件系统、锁等操作系统知识,这些都是超出Node范畴的东西。然而Node中却处处提到他们,而Node的核心也构建在大多数这些基础知识之上,我觉得仅仅是“使用”并不能让你真正理解精髓。所以,要想理解&精通Node,需先广泛汲取必备知识,这也是我为毛要学习底层的原因。
这篇笔记记录了我学习libuv的过程,包括对一些模糊概念的解释,Node事件机制的实现。
没错,libuv就是Node两个核心架构(libuv + V8)之一!
/* note: 操作系统默认为*nix */
先获取libuv的源码。git clone下来github上的项目或通过HTTP访问dist页面下载,当时的版本是 libuv-v0.11.17 。
编译源码。过程很简单,我们可以参照README进行构建,这里提供了两种方式:
1.通过autotools:
$ sh autogen.sh
$ ./configure
$ make
$ make check
$ make install2.通过GYP自动构建工具(我采用了第一种方式)
make会自动在/usr/local/lib目录下增加编译libuv应用程序使用的动态/静态链接库:libuv.so和libuv.a,同时在/usr/local/include目录下添加uv.h头文件。
源码编译通过后就可以开始学习之旅了。可以根据joyent的wiki或者源码注释详细的学习libuv的实现与使用方法。目前网上有一份官方英文版的初步介绍libuv的doc“An Introduction to libuv”。
我会按照上面提到的文档中目录的顺序写这篇笔记,并且只要大学认真的学过C语言就能读懂代码。
libuv是Node.js底层架构的一部分,作为异步I/O库,为Node提供了事件循环与回调机制以及对POSIX标准系统API的访问能力,例如:Socket、FileSystem、Process、Thread以及进程间通信等ECMAScript标准中不具备的。
在libuv之前也有一个名为libev的库,只不过libev仅适用于*nix,对Windows并没有提供支持。而libuv封装了Windows平台和Unix平台一些底层的特性,对外提供了一套统一的API。
Node对外宣传自身无与伦比的并发性能时常常提到“单线程异步无阻塞I/O模型”,不过大多数人刚开始接触Node时总存在这样几个疑惑:
为了解决这些问题,我们必须从底层的libuv入手。 其实在Node启动后至少跑起了两个线程:V8引擎线程和libuv线程。v8用来解析执行JavaScript语法,libuv在最后开启事件循环和监听器,检查并捕捉异步I/O完成后传来的消息。(这里不要误解,并不是说Node一启动就开俩线程,而是在一个主线程中执行v8 C++代码和libuv C代码,只是libuv涉及到了启用多线程)
我们的问题都能在下面这个例子中得到解答。
/* step 1 */
var http = require('http');
var fs = require('fs');
/* step 2 */
console.log('first interrupt');
/* step 3 */
http.createServer(callback).listen(8080);
/* step 4 */
console.log('output early');
function callback(req, res) {
var buffer;
req.on('data', function (data) {
buffer += data;
});
res.end(data);
}所谓“单线程”是指Node中主线程,所有的JavaScript代码都在这个线程中被解析执行。命令node app.js之后,Node线程按照注释中step的顺序解析代码。
step 1解析后涉及到文件的同步读取操作,后台libuv文件读取函数调用完成后,进入step 2,执行同步的控制台输出语句,step 2完成,开始step 3创建http服务器的异步函数。v8解析执行完毕后,将会调用libuv的网络相关函数。
与此同时,被调用的libuv函数将生成一个对象req,包含来自V8提供的参数信息、将要调用的底层函数的指针。然后为对应的I/O Wathcer注册一个参数为对象req的回调函数,之后开启一个I/O线程用来处理I/O请求,这个I/O线程首先将对象req中的底层函数指针提取出来以执行这个函数,这个函数调用POSIX系统网络访问API,做一个系统调用,从用户态陷入内核态,交由操作系统内核进程完成主机端口的监听并通过操作系统注册一个消息监听器以便任务完成时通知I/O线程。
当I/O线程接收到来自操作系统的调用完成消息通知,把调用结果赋给对象req的result属性,随后将req加入对应的I/O Watchers队列里。
从这里开始,Node主线程的前三个任务完成,立即开始step 4的控制台输出。
而后libuv的工作就是做事件循环检测到来的事件。事件循环依次询问各种类型的Watchers是否有完成的事件?Wathcers开始检查自己的队列是否有req对象,如果有的话,通知事件循环“是”,然后事件循环将req对象依次出队做Wathcers的参数执行之前绑定的回调函数。在这个回调函数中,会检查req对象的V8传入参数,如果V8线程传入了callback,就以req的result属性为参数在主线程中调用callback。
然后事件循环会继续检测本次循环中是否还有活跃的(产生新事件)监视器,如果没有的话就退出事件循环程序结束,否则接着循环。
以上回答了第一和第三个问题,不过“事件循环”究竟是啥还没有回答清楚,接下来先简单的解释一下事件循环。
事件循环是libuv中捕获广播事件的一种机制,它类似一个循环的结构。Linux系统下该机制由epoll轮询实现:当Node启动时,代码最后开始第一次事件循环,如果此时没有事件发生,就阻塞进程,让出CPU。当新的req对象加入Watcher队列(也就是内核完成了I/O操作),激活事件循环,并再次询问Wathcer是否有事件到来,如果有就调用对应Watcher的回调函数,然后询问其他Wathcers是否还有待处理的事件,没有的话退出事件循环。下面是epoll实现的事件循环模型:
while (true) {
epollwait(core_events); // 内核没有发送I/O事件就阻塞循环
while (new events in Watchers)
while (Watcher[i].queue NOT NULL)
execute Watchers[i].callback with args req;
}
使用libuv编写Node模块扩展就会发现这个“事件循环”由uv_run函数启动。按照libuv参考的说法,该函数封装了事件循环,通常最后调用,并传入uv_default_loop参数来获取默认的事件循环:(Node使用默认事件循环作为主循环)
这里给一个官方的小例子,跑一个新的事件循环:
#include <uv.h>
#include <stdlib.h>
int main() {
uv_loop_t *loop = uv_loop_new();
printf("Now quitting.\n");
uv_run(loop, UV_RUN_DEFAULT);
return 0;
}how to run it?
注意最开始提到的libuv.so,这是编译时必须引入的,如果直接gcc -o test test.c会编译出错。
gcc -o test test.c -luv
./test对于事件循环,epoll的实现机制是透明的。不过关于“epoll如何捕获内核I/O事件”仍是个问题,网上查阅大量资料无果。
仍需继续阅读libuv和Node源码。
Bitcoins 结构简图
Bitcoins:{
BlockChain <Master>:{
Block0:{
Transaction0 :{ …… }
Transaction1 :{ …… }
Transaction2 :{ …… }
……
}
Block1:{
Transaction0 :{ …… }
Transaction1 :{ …… }
Transaction2 :{ …… }
……
}
……
}
BlockChain <Abandon>:{
……
}
……
}
货币的主要用途是交易,BitCoins也自然如此,因此交易(Transactions)作为BlockChains的原子构成(从上图可知)是很重要的。
每个Block都是由多条Transactions(简写为Tx)组成。每条tx记录了每笔Bitcoins交易的详细信息。
每个Block的首条tx记录被称为Coinbase tx。其特点是只有输出而没有输入,因为这条tx是Bitcoin系统为了回报_挖矿_而生成的Bitcoin奖励。(这也是Bitcoins的发行方式)
该Block中其余的tx都是允许有几个输入和几个输出。输入代表从前一比交易中获得bitcoins,输出代表花费(其实是转帐)目前这笔交易中的bitcoins。一旦某个Tx的一个输出成为另一个Tx的输入,那么该笔比特币即为已花费。
每笔tx有在此block中唯一的Hash值来标识,它是通过对交易数据做两次SHA256加密运算得出。
这些tx信息是全网公开的,以明文形式存储(比特币系统里的所有数据都是明文的),只有当需要转移货币所有权时,才需要用私钥签名来验证。
{
# hex包含了这个tx的全部信息,以下内容均可由hex解析出来
"hex" : "……",
# txid由hex键经过两次SHA256加密生成
# Note:运算结果结果应该是按小端字节次序(little endian)读取的
# 唯一标识了这个交易
"txid" : "……",
# 本次交易的版本号
"version" : 1,
# 在给定时间之前该交易信息被“锁定”(即不能被录入到blocks中)
"locktime" : 0,
# generation交易的输入,为一个数组
"vin" : [
{
"coinbase" : "……",
"sequence" : 4294967295
}
],
# 交易的输出,同为一个数组
"vout" : [
{
"value" : 50.01000000,
"n" : 0,
"scriptPubKey" : {
"asm" : "……",
"hex" : "……",
"reqSigs" : 1,
"type" : "pubkey",
"addresses" : [
"1LgZTvoTJ6quJNCURmBUaJJkWWQZXkQnDn"
]
}
}
],
# 标记这个tx属于哪个blocks
"blockhash" : "……",
"confirmations" : 145029,
"time" : 1301705313,
"blocktime" : 1301705313
}
{
# 键名与含义大至于上面的相同,唯一区别是“vin键”,下面有解释。
"hex" : "……",
"txid" : "……",
"version" : 1,
"locktime" : 0,
# 普通tx的输入
"vin" : [
{
"txid" : "……",
"vout" : 0,
"scriptSig" : {
"asm" : "……",
"hex" : "……"
},
"sequence" : 4294967295
},
{
"txid" : "……",
"vout" : 1,
"scriptSig" : {
"asm" : "……",
"hex" : "……"
},
"sequence" : 4294967295
},
{
"txid" : "……",
"vout" : 1,
"scriptSig" : {
"asm" : "……",
"hex" : "……"
},
"sequence" : 4294967295
}
],
"vout" : [
{
"value" : 0.84000000,
"n" : 0,
"scriptPubKey" : {
"asm" : "……",
"hex" : "……",
"reqSigs" : 1,
"type" : "pubkeyhash",
"addresses" : [
"1A3q9pDtR4h8wpvyb8SVpiNPpT8ZNbHY8h"
]
}
},
{
"value" : 156.83000000,
"n" : 1,
"scriptPubKey" : {
"asm" : "……",
"hex" : "……",
"reqSigs" : 1,
"type" : "pubkeyhash",
"addresses" : [
"1Bg44FZsoTeYteRykC1XHz8facWYKhGvQ8"
]
}
}
],
"blockhash" : "……",
"confirmations" : 147751,
"time" : 1301705313,
"blocktime" : 1301705313
}
以上,第一个block中的首笔交易,第二个是含有三输入两输出的普通交易。
注释已经注明,他们之间的区别是在vin(交易来源)字段:
对于首笔交易自然没有输入,其vin字段的值为:
{
# coinbase字段允许挖矿者写入自定义的信息,
# 如中本聪在首个 block 的首条 transaction 中写入了:
# “04ffff001d0104455468652054696d65732030332f4a616e2f32303039204368616e63656c6c6f72206f6e206272696e6b206f66207365636f6e64206261696c6f757420666f722062616e6b73”
# 转码过来之后就是:
# “The Times 03/Jan/2009 Chancellor on brink of second bailout for banks”
"coinbase" : "……",
"sequence" : ……
}
普通交易的vin字段:
{
"txid" : "……",
"vout" : 0,
"scriptSig" : {
# 公钥
"asm" : "……",
# 签名
"hex" : "……"
},
"sequence" : ……
}
上面已经说了,txid是由hex生成的,下面就是txid的计算方法:
funtion getTxid(hex) {
bin = new Buffer(hex, 'hex');
buf_BE = crypto.createHash('sha256').update(crypto.createHash('sha256').update(bin).digest()).digest();
buf_LE = Array.protptype.reverse.call(buf_BE); // 转换为小段次序
txid_hash = buf_LE.toString('hex');
}
Note:其他字段解释(引自比特币实验室)
sequence:若该笔交易的所有输入交易的sequence字段,均为INT32最大值(0xffffffff),则忽略lock_time字段。否则,该交易在未达到Block高度或达到某个时刻之前,是不会被收录进Block中的。
lock_time:是一个多意字段,表示在某个高度的Block之前或某个时间点之前该交易处于锁定态,无法收录进Block。
0 立即生效
< 500000000 含义为Block高度,处于该Block之前为锁定(不生效)
= 500000000 含义为Unix时间戳,处于该时刻之前为锁定(不生效)
从解析后的Transaction结构中,可以得到每个tx的每笔花费信息,包括花费数量、转帐地址以及后续交易的hex等等,如:
{
# 本次转帐金额
"value" : 0.84000000,
"n" : 0,
# 公钥
"scriptPubKey" : {
"asm" : "……",
"hex" : "……",
"reqSigs" : 1,
"type" : "pubkeyhash",
# 转帐地址
"addresses" : [
"1A3q9pDtR4h8wpvyb8SVpiNPpT8ZNbHY8h"
]
}
}
爬虫常被看作是一个边缘hack技术。通过别人的前端页面获取数据似乎为人所不耻,但是不管人们怎么评价它,爬虫的作用就摆在那里,有用没用全取决于你的目的。
为什么在互联网这片浩瀚的海洋里,我仍然旧事重提?起因与我最近做的事有关。
如果说让你爬取一个网页,你会怎么做?
OK,你很可能会说这很简单:“拿一个HTTPClient请求一下那个URL不就行了”。
对于普通网页,可能很顺利的就拿下了,那么对于如下几种情况,该怎么办呢:
我把以上情景大致分为两类:
拒绝访问的一般就是在Web server上做了爬虫防范措施。当有客户端请求数据时,对其进行检测,如果判断为浏览器,则允许与自己通信,否则就可以用各种方法为难客户端,比如:close这个socket(切断连接),返回非浏览器客户端不懂的redirect 302或非法访问等等。
至于如何断定该客户端就是浏览器或一定不是浏览器,有好多方法,打开network流量监视器,可以看到每个请求的详细内容,服务器可以检查:
Referer,Host,User-Agent,因为这些是浏览器最具代表性的字段。
一般我们把这几个字段也一同提交过去大多数服务器就能被搞定了,但随着技术的进步,防范措施也在不断改进。
但对于最后一种情况,你可能会很头痛并且百思不得其解,这也是我在实际操作中遇到的问题。
我在爬取一个看似再正常不过的页面时,爬取工具竟然crash了!排除网络问题,我又详细的看了几遍浏览器中的请求头,以及是否有明显的redirect痕迹。结果很遗憾:network控制台仅显示了一个请求,响应码为200!:

这个问题很蹊跷,先不管爬虫怎么崩的,把浏览器的所有请求头发过去试试再说。结果令我意外的是爬虫再次崩溃了!我再次检查了请求字段是否写错,然后排除了请求头的问题。
既然不是请求头的问题,那这个服务器究竟是靠什么判断客户端类型的呢?这个我当时真的没想明白。
这下几乎头绪全没了。我真想到了302 redirect,但控制台里完全没有这个请求啊,有的只是个200。
而后我又拿wget将这个页面下载了下来,打开一看,大吃一惊,竟然完完整整的下载下来了!
看wget的log,在请求的阶段,确实存在一个目标地址临时转移,也就是说确实有返回302这么一个过程。继续看,发现location竟然是自己。
到这里我终于明白爬虫为什么crash了,原来这货在往死循环里跳!
但问题仍为解决,如果说真的是redirect loop,那浏览器也应该请求失败才对啊,况且我把请求头都加进去了,按理来说应该伪装成了浏览器。但却失败了。
我想了好久,302 location为自己这肯定没错了,问题一定出在请求信息上。既然浏览器没进入死循环,那么说明一定在某个条件下停止了,并且绝对不是在第一次请求时就得到页面!在这一系列请求中,好多字段都是不变量,能让条件改变的,应该只有双方交互用的cookies了。但之前我已经说过,把所有字段都添加进去了,当然也包括cookies,为什么就失败了?因为cookie在这个循环中是变量!而服务器是在至少第二次循环请求中通过检测上一次为客户端设置好的cookies来判断客户端类型的:只有正确携带上一次设置的cookie的客户端才是真正的浏览器!我突然觉得这个想法非常靠谱,因为也只有这样了。
为了验证我的想法,我手写了一个简单的爬虫,首次请求仅传入了一个URL,然后进入递归函数,并附带浏览器请求头信息,同时把上一次服务器响应的cookies一并写入请求头,再去发起下一次请求。
这次跑爬虫时,果然不出我所料,网页的内容正确显示出来了,并且是经过了两次请求。
兴奋过后,反过来想想,这个防范构思的确巧妙,巧妙利用了redirect loop和cookie变量的特点,覆盖了流量检测工具对请求的识别(redirect loop导致仅显示了最后一个成功的请求,让人以为这仅仅是一次普通的请求,并不存在跳转),并借助“询问”的方式,检查对方能否携带正确的cookie(也就是能否明白上次给你的东西),使爬虫左右为难。
所以,解决这类问题的关键就是:无论何时,不管是否有redirect,请求头中都要附带标志性字段和变量cookie。
接下来谈谈允许访问时的爬取失败情况。
这类例子很常见。尤其是在动态加载的网页里,大部分内容是由script标签和Ajax技术异步加载,这样我们直接抓取网页必然会导致失败。通常的对策是,先分析这个页面的所有流量去向,把异步加载的那些URL全提取出来,然后再遍历这些URL做循环请求,这样反倒方便了不少,毕竟这些URL是以JSON API形式返回的,格式已经是很清晰的了,根本不用HTML解析器做麻烦的节点分析了。
但这仅仅是异步加载中的冰山一角,可能在你分析的第一步就进行不下去了:流量监测里找不到异步请求的API。
没用Ajax,也没静态加载,看起来很玄乎哈?但仔细看流量分析表里的script,他们都是异步请求的,看来数据都应该与他们有关,并且既然没有后续的数据请求了,那就说明我们所需的数据全部包含在那些异步加载的script里。那么该如何获取这些数据呢?
这时就需要一双犀利的眸子了。。。可能是在脚本的一个变量里存储着,这是我们最期望的。
对于脚本中的字符串,怎么高效处理?用match正则匹配?NONONO,那样太麻烦,eval在这里才派上大用场了,把这些脚本字符串统统传给eval。
这里顺便说个题外话,关于eval,大家虽然知道他强大,却也惧其三分,原因在于eval载全局环境下执行代码导致结果是不可预测的,这个例子中就完美的证实了这一点,不过细节我就不说了。
回到正题,假设我们并没有在某些显示变量中发现要找的数据,而是藏在函数参数中或函数作用域内。
仍然采用高效的办法:把字符串中的所有函数,对象在外部重新声明一下,然后在数据出现的那个函数体里手动构造全局变量,指向参数或者局部变量,等eval调用完毕,全局变量里存放的就是抓取的数据了。期间涉及到的技术内幕之一是可能需要对字符串中的重叠变量进行替换,replace是个不错的选择。
下面该处理爬虫返回的数据了,对于JSON数据或者JSONP返回的数据很好办,我们主要是解析“爬”下来的东西,也就是一大堆混乱的HTML代码,各类编程语言都有HTML/XML节点解析库,比如说JavaScript中的cheerio,有了这样的工具干起活来也相对容易。
以上就是这两天的技术总结。关于爬虫还有好多话题待挖掘,这篇工作日志里就不详谈了。
刚刚我从原博客里拿出了几篇值得保留的post放到issues上,意味着从此与Jekyll再无瓜葛了。
以前总想着要把界面设计的足够特立独行,足够别致。后来一些乱七八糟的麻烦让我觉得UI那些都是浮云,唯有实实在在的东西才值得保存,因此blog转向github issues。
我以前常在windows环境下硬盘安装ubuntu, 过程挺痛快的, 没遇到什么大波折, 我想Linux下安装windows也会一样容易吧.
先列表统计一下安装方式:
光盘方式最傻瓜, 除此之外U盘安装最简单, 每款操作系统都有U盘刻录工具, 只要把镜像交给它基本上就ok了.
不过像我这样不喜欢用寻常方法的, 就要花点时间研究研究另外两种方法了.
忽略上面那句话, 其实是被迫用其他方法的.
家里的ubuntu 13.10台式机要装windows 7, 现在手边没有光盘, 只有一个1GB的U盘, 但找到一个闲置的IDE接口老式硬盘.
难道没U盘就玩不转吗? 这怎么可能~ window装ubuntu不也是用硬盘安装的嘛~~~
ok, 玩玩在ubuntu下用外置硬盘装windows.
还好经过一番折腾终于成功了. 思路是这样的:
准备windows 的镜像文件, 比如win.iso.
找到外置硬盘:
df -lh
# 比如/dev/sdb给外置硬盘重新分区:
sudo fdisk /dev/sdb
# 看下分区表:
p
# 假设sdb被分为sdb1和sdb2两个分区
# 删除原有分区
d
# 重新创建分区
# 把整块硬盘划分为一个分区:
n
# 因为是整块硬盘, 所以参数不用更变,使用默认即可
# 现在分区变成了sdb1
# 为了制作启动盘, 所以要把分区设为可启动
a
# 因为要引导的是windows, 所以还要把文件系统类型标记为NTFS
# (HPFS/NTFS/exFAT), 编号为7
t 7
# 写入新的分区表
w
# 如果这块硬盘在分区之前已经挂在, 那么之后可能会提示无法变更分区表, 这时可以先卸载它:
# 假设挂载点为/media/ran/hd
sudo umount /media/ran/hd
# 然后执行partprobe强制内核写入新的分区表
sudo partprobe
# 如果还是提示分区表无法写入, 那么重启一下系统吧格式化分区:
# 格式化为NTFS
mkfs.ntfs -f /dev/sdb1写入windows专用引导, 学过操作系统我们都清楚, 这一步很关键.
# 我Google发现用lilo程序(类似grub的老式引导设置)可以写入windows系统引导.
# 一般ubuntu是不会安装lilo的, 因为默认是用的是grub
sudo apt-get install lilo
# 向硬盘中写入主引导记录
sudo lilo -M /dev/sdb mbr挂载镜像和硬盘
sudo mount -o loop win.iso /media/ran/iso
sudo mount /dev/sdb1 /media/ran/hd
拷贝镜像文件
# 这一步用cp还是dd都行,怎么搞都可以了
cp -r /media/ran/iso/* /media/ran/hd到这里, 一个windows启动硬盘就诞生了. 这一方法不会受限于系统的版本.
为了以后不再重复上面的步骤, 最好是把折腾到这一步的所有工作成果再保存成一个镜像文件:
# 注意block和count的选择, 要不然全盘复制可就得不偿失了.
dd if=/dev/sdb1 of=/home/ran/bak/win.isoHTML5为我们带来不少新奇的东西,除了那几个闪亮的明星“WebSocket”、“Worker”、“Canvas”等等之外,还有几个非著名演员(包括但不限于):“Blob”、“ArrayBuffer”、“URL”、“FormData”。这些小角色是用来支持二进制字节数据操作的。但Blob和ArrayBuffer的分界线似乎很模糊,我们写程序时往往会纠结应该使用哪种方式来在和Server进行数据交互,所以今天我们就把他们弄明白。
我在前几篇里简单的翻译了Node中Buffer函数和buffer对象的解释及用法。没错,_buffer_就是缓冲区的意思。“缓冲”的目之一就是为了解决设备之间I/O速度差异的问题:当一个Socket A向Socket B发送数据时,到达的比特流首先会在B的缓冲区里停留,然后再由B进行读取,如果没有这个缓冲区,B就有可能无法读取完整的数据。
当然,这里谈到的ArrayBuffer就类似刚刚所说的_缓冲区_。这些缓冲区都是按byte(字节)进行划分的。这个ArrayBuffer和Node环境下的Buffer很像,并且都是一个特殊的数组(将缓冲区作为数组来使用)。虽说Node里也有ArrayBuffer,不过和前端的ArrayBuffer稍有些区别,这里我们讨论的是浏览器端的ArrayBuffer。
如果缓冲区这个解释略抽象,那么就把他当成是一个用来装byte数据的容器吧。可以算是浏览器端最基础的数据格式了,请记住关键字:字节。这是用以区分后面提到的Blob的最好描述。
// 申请一个10byte的缓冲区
var af = new ArrayBuffer(10);
对于ArrayBuffer,HTML5还提供了几个高级的封装,用以快捷操作字节数据,我们称之为view:
比如说,Uint8Array就是利用ArrayBuffer开辟一个数组,元素类型为8bit(1byte)无符号整型的:
//10个元素的缓冲区(也就是10 * 1 byte)
var ui8arr = new Uint8Array(10);
//等价于
var af = new ArrayBuffer(10);
var ui8arr = new Uint8Array(af);
获取了view的实例,我们就可以使用实例的方法,对缓冲区进行读写。
这些view既可以像ArrayBuffer一样按数目申请空间,又可以引用已有的ArrayBuffer空间。
对于后一种情况,无论用view创建多少个实例,这些引用都是指向原始的ArrayBuffer内存地址,所以一旦对某一view的实例做了变动,其他view的实例也会变化。
注意:通过view对ArrayBuffer进行读写时,需要注意byte的读写方式,即“低位优先字节次序”和“高位优先字节次序”。
所谓字节次序是指占内存多于一个字节类型的数据在内存中的存放顺序。
举个形象的例子。将一个4byte的数0xFE051324放入内存,如果是低优先顺序,内存中的存储如下:
内存地址减小 <—— | 24 | 13 | 05 | FE | ——> 内存地址增大
如果按照高位优先顺序来存储这一数据,在内存中的实际存放是这样的:
内存地址减小 <—— | FE | 05 | 13 | 24 | ——> 内存地址增大
正好对称过来,如果仍按照“低位次序”的方式来读取,则读出来的数据就是:0x241305FE
因此,事先知道数据的读取方式很重要。那如何按照我们所期望的方式来读取呢?还要感谢HTML5,它提供了更高级的view:DataView对象,专业操作ArrayBuffer。
var af = new ArrayBuffer(10);
//使用DataView管理ArrayBuffer
var dv = new DataView(af);
DataView的实例提供了一系列读写ArrayBuffer的方法,如:
// 从ArrayBuffer索引为2(第三个byte)的元素开始,读取16位无符号整型
dv.getUint16(2);
//默认是按“高位次序”进行读写的,如果需要改成“小端次序”:
dv.getUint16(2, true);
//“高位次序” 写操作,从索引为2开始,写入16位无符号整型0xFF
dv.setUint16(2, 0xFF, false);
具体的API这里就不写了,详见W3c草案。
Blob是当前Web前端很常用的数据格式,是Binary Large Object(大型二进制对象)的缩写。代表原始的二进制数据。和ArrayBuffer类似,都是二进制数据的容器。
//可以用字符串构建Blob
var blob = new Blob(['ran aizen on github']);
//ArrayBuffer也行
var blob = new Blob([new ArrayBuffer(10)]);
从描述上来看,ArrayBuffer似乎是Blob的底层,Blob内部使用了ArrayBuffer。并且构造好的一个Blob实体就是一个raw data。既然用途差不多,那为什么一个Blob一个ArrayBuffer呢?当然,设计Blob和ArrayBuffer的目的是不同的。因为ArrayBuffer更底层,所以它专注的是细节,比如说按字节读写文件。相反,Blob更像一个整体,它不在意细节:就是那么一个原始的Binary Data,你只要来回传输就行了。
En, this is a good question~ 还记得ajax和WebSocket吗?如何用这两种技术去传输文件呢?Good!派上用场了~
先看看WebSocket:
var ws = new WebSocket('ws://chat.io');
//ok,我们建立了一个ws通信链接,接着看看数据是以什么格式传输的:
ws.binaryType // -> "blob"
当然,type的类型可以在允许的范围内自定义,不过默认是blob。也就是说,Blob可以用在WebSocket通信中,并且它就是通信中的二进制数据,对应Node中的Buffer(Node中接收到的二进制数据就是Buffer的实例)。看来使用Blob可以很好地与Node Server进行交互。
使用ajax中传文件并不是件新鲜事,我们使用的网盘或云相册几乎都用了这一方式。
var xhr = new XMLHttpRequest();
//如果要得到二进制数据,一般是文件,可以设为blob
xhr.responseType = "blob";
//上传二进制数据
xhr.send(row)
在HTML5新的标准中File对象的内部就使用了Blob,从<input>标签中获取的File对象即是一个Blob实例。
blob文件的转换,可以使用FileReader对象:
var fd = new FileReader();
//fd有几个文件读取方法,可以得到ArrayBuffer、Blob或String的数据
//可以使用ArrayBuffer读取方式,得到的会是一个ArrayBuffer实例
fd.readAsArrayBuffer(file);
//这里使用了blob的方式,所以会得到一个blob对象
//fd.readAsBinaryString(file);
fd.onload = function (e) {
//读取成功后得到ArrayBuffer
buffer = e.target.result;
};
上面的例子中,我们将一个blob文件以ArrayBuffer的形式进行读取,得到了一个ArrayBuffer的实例。
为什么要把Blob弄成ArrayBuffer?因为这样我们就可以对文件的字节进行读写了,比如说要判断一个文件的类型,就可以读取它的前两个字节,与Hash表进行匹配,等等。
其实在C / S的交互中,发送的数据往往直接就是Binary Data, 很少需要一个底层的ArrayBuffer按byte来手动构造数据。“茫茫Web,不要在意细节嘛”~
下面还有一个使用Blob的使用例子,通过Blob构造URL:
URL对象的createObjectURL方法允许传入一个blob,并得到一个临时的URL:
//假如Server响应了一个图片
var URI = URL.createObjectURL(xhr.response);
var img = document.createElement('img');
//我们可以把blob url用在这里:
img.src = URI;
document.append(img);
至于选择Blob还是ArrayBuffer,关键要看你的目的是什么。
二进制已经融入了WEB前端世界,这里仅仅介绍了两位角色,还有好多新鲜玩意等待你探索。慢慢玩吧,*年~
感谢这学期开了一门嵌入式操作系统, 纠正了我一些认识上的误区.
当涂老师提到idle进程时, 我突然想起了init,
Init是所有进程的祖先, 它是内核创建的第一个进程...
记得我们学操作系统时水笔老范说了好几遍, 已经牢牢刻在脑海里了, 所以潜意识里仍是不假思索认为init是头子. 可是仔细看idle的作用以及地位, 貌似比init进程还有高, 这就让有点怀疑当初所学的东西是不是漏掉了什么...
确实当年学操作系统时漏掉了一些重要的东西, 今天和实验室的师兄们讨论了之后终于补回来了.
当boot loader选定并加载一个内核后, 将计算机控制权交给加载的内核, 并创建一些系统函数. 当准备工作完成, 内核逻辑开始调用定义的start_kernal()函数.
start_kernal()函数的任务就是建立中断处理机制, 初始化内存管理的剩余部分, 初始化调度器, 初始化设备以及驱动等等. 最后调用rest_init()函数创建init进程(pid 1), 并将(内核)自己做为idle进程(pid 0).
init进程由内核创建, 并在用户空间执行. 它在用户空间执行upstart服务(启动脚本), 创建非系统服务并调用login程序进行用户登录控制. 下面是init的代码:
static int init(void * unused)
{
lock_kernel();
do_basic_setup();
prepare_namespace();
/*
* Ok, we have completed the initial bootup, and
* we're essentially up and running. Get rid of the
* initmem segments and start the user-mode stuff..
*/
free_initmem();
unlock_kernel();
if (open("/dev/console", O_RDWR, 0) < 0) // stdin
printk("Warning: unable to open an initial console.\n");
(void) dup(0); // stdout
(void) dup(0); // stderr
/*
* We try each of these until one succeeds.
*
* The Bourne shell can be used instead of init if we are
* trying to recover a really broken machine.
*/
if (execute_command)
execve(execute_command,argv_init,envp_init);
execve("/sbin/init",argv_init,envp_init);
execve("/etc/init",argv_init,envp_init);
execve("/bin/init",argv_init,envp_init);
execve("/bin/sh",argv_init,envp_init);
panic("No init found. Try passing init= option to kernel.");
}init函数最后执行了系统调用exec, 将可作为init程序的二进制镜像加载到内存.
现在来看看kernal space在系统启动过程中都干点什么.
the kernel looks for an init process to run, which (separately) sets up a user space and the processes needed for a user environment and ultimate login. The kernel itself is then allowed to go idle, subject to calls from other processes.
调用start_kernal()函数这一阶段称作Kernel startup stage. 阶段最后才创建init进程. rest_init代码如下:
rest_init() {
// init process, pid = 1
kernel_thread(init, NULL, CLONE_FS | CLONE_FILES | CLONE_SIGNAL);
unlock_kernel();
current->need_resched = 1;
// idle process, pid = 0
cpu_idle(); // never return
}可见idle"进程"就是start_kernal演变过来.
The startup function for the kernel (also called the swapper or process 0)
而idle的任务就是空转! 当系统中没有其他任何进程使用CPU时, 因为CPU也不能闲着呀, 所以这时调度器就把CPU控制权交给idle进程, idle进程的诞生是通过cpu_idle()函数完成的, 而这个函数永远不会返回.:
/*
* The idle thread. There's no useful work to be
* done, so just try to conserve power and have a
* low exit latency (ie sit in a loop waiting for
* somebody to say that they'd like to reschedule)
*/
void cpu_idle (void)
{
/* endless idle loop with no priority at all */
init_idle();
current->nice = 20;
current->counter = -100;
while (1) {
void (*idle)(void) = pm_idle;
if (!idle)
idle = default_idle;
while (!current->need_resched)
idle();
schedule();
check_pgt_cache();
}
}
///////////////////////////////////////////////////////////////////////////////
void __init init_idle(void)
{
struct schedule_data * sched_data;
sched_data = &aligned_data[smp_processor_id()].schedule_data;
if (current != &init_task && task_on_runqueue(current)) {
printk("UGH! (%d:%d) was on the runqueue, removing.\n",
smp_processor_id(), current->pid);
del_from_runqueue(current);
}
sched_data->curr = current;
sched_data->last_schedule = get_cycles();
clear_bit(current->processor, &wait_init_idle);
}
///////////////////////////////////////////////////////////////////////////////
void default_idle(void)
{
if (current_cpu_data.hlt_works_ok && !hlt_counter) {
__cli();
if (!current->need_resched)
safe_halt();
else
__sti();
}
}到这里我想你应该明白idle进程的由来了以及与init的关系了.
现在在linux下执行命令ps -eaf, 查看一下:
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 17:48 ? 00:00:01 /sbin/init
root 2 0 0 17:48 ? 00:00:00 [kthreadd]
root 3 2 0 17:48 ? 00:00:00 [ksoftirqd/0]
root 5 2 0 17:48 ? 00:00:00 [kworker/0:0H]
root 7 2 0 17:48 ? 00:00:09 [rcu_sched]
pid为1的init进程的父进程pid为0 (第二个进程是内核进程的守护进程, 也是由内核创建), 也就是说忽略内核进程的情况下:
Init是所有进程的祖先, 它是内核创建的第一个进程
这句话是对的, init确实是所有用户级进程的祖先.
其实最初讨论话题是由调度工作谁来做展开的. 现在如果你不知道上面的内容, 你怎么想?
我最开始头脑中有这么几个策略:
schedule()函数进行进程调度.之所以会有后两个想法, 是因为我觉得每个进程都可以主动让出CPU控制权并调用schedule函数挑选就绪队列中的进程.
如果我清除的意识到init是user-space进程的话就直接排除掉了. 假设init负责了进程的调度, 那么首先由init → process_a, 如果process_a的时间片到了呢? 由于调度权在init进程, 所以这时没有任何用户空间进程可以执行, 于是idle进程篡位, 系统暂时进入空转, cpu_idle函数通过调用schedule函数才可以从就绪队列选择一个进程继续执行. 如果process_a正在执行时来了一个高优先级的进程呢? 中断之后由于没有调度器执行, 于是又进入idle的天下.
也就是说, 把调度权交给init完全就是废了, 一点用没有.
idle进程其实就是内核的一部分, 读一读它的源码你会发现它还负责调度工作:
while (1) {
void (*idle)(void) = pm_idle;
if (!idle)
idle = default_idle;
while (!current->need_resched)
idle();
schedule();
check_pgt_cache();
}脑补一下这样一个场景: 某个进程由于某些原因放弃了CPU使用权. 由于idle进程(与其说是一个进程, 到不如说是部分内核代码, 本身没有什么就绪可言)是一个死循环, 检测到需要调度, 则调用schedule()函数完成进程调度工作.
所以不把idle进程看做"进程"的一个原因可能是它是Scheduler吧.
但是呢, 这仅仅是现有操作系统的一种调度手段, 可并不代表这是唯一的调度手段. 可以脑洞大开, 让任一进程都可以作为调度器! 只要修改linux现有的代码, 当然, 那种情况就另当别论了.
Node对两个Timer的超时时间做了个小trick, 任何大于TIMEOUT_MAX小于1ms的超时都被视为1ms.
setTimeout和setInterval在Node下的封装基本上一样, 这里单拿前者举例.
exports.setTimeout = function(callback, after) {
after *= 1; // coalesce to number or NaN
// 保证setTimeout永远会延时执行
if (!(after >= 1 && after <= TIMEOUT_MAX)) {
after = 1; // schedule on next tick, follows browser behaviour
}
// ...
var ontimeout = callback;
timer._onTimeout = ontimeout;
// ...
exports.active(timer);
return timer;
};官方文档对setImmediate并不准确, 基本上让所有没读过源码(包括读得不仔细)的人对其产生极大误解.
主要来自setImmediate和setTimeout(0)谁先谁后的问题,
exports.setImmediate = function(callback, arg1, arg2, arg3) {
var i, args;
var len = arguments.length;
var immediate = new Immediate();
L.init(immediate);
// ...
// 这里是setImmediate能执行的关键, c++作用域里会检查`_needImmediateCallback`
// c++那部分代码太长我就不贴了, 全在src/node.cc里, 自己去看.
if (!process._needImmediateCallback) {
process._needImmediateCallback = true;
process._immediateCallback = processImmediate;
}
// ...
return immediate;
};这个在异步函数里优先级最高大家都知道, 属于idle观察者也清. 代码在src/node.js里实现.
代码很长, 不多说, 所有process.nextTick堆积的任务都会在事件循环的next tick(后面讲)里一口气执行.
这里还有一个重点: _tickCallback函数是idle观察者在next tick里的主回调函数:
function _tickCallback() {
var callback, args, tock;
do {
while (tickInfo[kIndex] < tickInfo[kLength]) {
tock = nextTickQueue[tickInfo[kIndex]++];
callback = tock.callback;
args = tock.args;
// Using separate callback execution functions helps to limit the
// scope of DEOPTs caused by using try blocks and allows direct
// callback invocation with small numbers of arguments to avoid the
// performance hit associated with using `fn.apply()`
if (args === undefined) {
doNTCallback0(callback);
} else {
switch (args.length) {
case 1:
doNTCallback1(callback, args[0]);
break;
case 2:
doNTCallback2(callback, args[0], args[1]);
break;
case 3:
doNTCallback3(callback, args[0], args[1], args[2]);
break;
default:
doNTCallbackMany(callback, args);
}
}
if (1e4 < tickInfo[kIndex])
tickDone();
}
tickDone();
_runMicrotasks();
emitPendingUnhandledRejections();
} while (tickInfo[kLength] !== 0);
}当整个队列清空后, 继续向下执行_runMicrotasks, Microtask是什么?,
我们暂且不理会它, 先来看与其相关的代码:
function scheduleMicrotasks() {
if (microtasksScheduled)
return;
nextTickQueue.push({
callback: runMicrotasksCallback,
domain: null
});
tickInfo[kLength]++;
microtasksScheduled = true;
}
function runMicrotasksCallback() {
microtasksScheduled = false;
_runMicrotasks();
if (tickInfo[kIndex] < tickInfo[kLength] ||
emitPendingUnhandledRejections())
scheduleMicrotasks();
}注意到microtask在调度时跟process.nextTick的行为差不多, 也是将任务压到nextTickQueue里, 然后在next tick里一次性处理掉.
process.nextTick初始化过程的其他部分代码:
startup.processNextTick = function() {
// 保存nextTick任务的队列
var nextTickQueue = [];
var pendingUnhandledRejections = [];
var microtasksScheduled = false;
// ...
function emitPendingUnhandledRejections() {
var hadListeners = false;
while (pendingUnhandledRejections.length > 0) {
var promise = pendingUnhandledRejections.shift();
var reason = pendingUnhandledRejections.shift();
if (hasBeenNotifiedProperty.get(promise) === false) {
hasBeenNotifiedProperty.set(promise, true);
if (!process.emit('unhandledRejection', reason, promise)) {
// Nobody is listening.
// TODO(petkaantonov) Take some default action, see #830
} else {
hadListeners = true;
}
}
}
return hadListeners;
}
addPendingUnhandledRejection = function(promise, reason) {
pendingUnhandledRejections.push(promise, reason);
scheduleMicrotasks();
};
};上面三个是Node下很常用的用来实现异步函数的工具, 可惜官网并没有对他们的差别给出易懂的解释(我猜测原因是他们默认你充分了解event loop并且熟读libuv源码...).
好了, 这里必须要说的一个例子:
setImmediate的表现在新旧版本中的差异:
setImmediate ->
console.log 'immediate-1'
process.nextTick ->
console.log 'nextTick-1'
setImmediate ->
console.log 'immediate-2'
process.nextTick ->
console.log 'nextTick-2'我在Node-v0.11.14中的测试结果符合以往的认知:
# immediate-1
# nextTick-1
# immediate-2
# nextTick-2按照正常的认知, 因为process.nextTick属于idle, 而setImmediate属于check, 它积压的任务在每个tick里执行一个.
所以setImmediate的第一个任务执行完后并不会接着执行第二个任务, 而是进入next tick, 执行process.nextTick的任务.
然而在iojs-v3.2中出现了颠覆世界观的一幕:
# immediate-1
# immediate-2
# nextTick-1
# nextTick-2输出结果很让人惊讶, 这种情况应该是setImmediate和process.nextTick一样把所有任务在next tick里一气呵成了.
不过并没有见官方文档做出改动, 暂不知道这种解释是否正确.
这里要举另外一个例子, setImmediate和setTimeout的表现.
setImmediate(function() { console.log('immediate'); });
setTimeout(function() { console.log('timeout'); }, 0);哪个先打印出来? 'immediate'? 'timeout'? 可以尝试一下, 实际结果可能是这样的:
# 第N次尝试 =>
# timeout
# immediate
# ...
# 第M次尝试 =>
# immediate
# timeout如果process.nextTick乱入:
process.nextTick ->
console.log 'nexttick'
setImmediate ->
console.log 'immediate'
setTimeout ->
console.log 'timeout'结果又是另一番景象:
# nexttick
# timeout
# immediate先从解释第一种情况. 在libuv的event loop代码中有这么一段核心代码. 上面没少提到next tick, event loop的每一次loop被称作一个tick:
while (r != 0 && loop->stop_flag == 0) {
// tick开始时更新当前时间
uv__update_time(loop);
// 1. 执行超时的计时器任务
uv__run_timers(loop);
// 2. 执行上次推迟执行的I/O回调函数
ran_pending = uv__run_pending(loop);
// 3. 执行idle任务
uv__run_idle(loop);
// 4. 执行prepare任务
uv__run_prepare(loop);
timeout = 0;
if ((mode == UV_RUN_ONCE && !ran_pending) || mode == UV_RUN_DEFAULT)
timeout = uv_backend_timeout(loop);
// 5. 开始I/O poll, (网络I/O为epoll(Linux为例), 文件系统I/O等其他异步任务为thread pool).
// 得到底层通知后, 通常会在本次tick执行I/O回调函数
uv__io_poll(loop, timeout);
// 6. 执行check任务
uv__run_check(loop);
uv__run_closing_handles(loop);
// ...
r = uv__loop_alive(loop);
if (mode == UV_RUN_ONCE || mode == UV_RUN_NOWAIT)
break;
}我们着重关注的是步骤1, 3, 5, 6, 暂且看做setTimeout的任务,process.nextTick的任务,I/O任务,setImmediate的任务.
于是我们得到了观察者的执行顺序: timer > I/O > check.
即然这样, 为什么第一个例子结果会不确定呢?
这时Node对setTimeout改动的结果, 记得最开始提到的setTimeout源码中的重点吗?
setTimeout的任务无论如何都会延时入队, 最早也是在1ms之后.
所以对于第一个例子, 由于首次call stack的占用时间没法确定, 在next tick时可能已经过了1ms, 也有可能小于1ms,
所以check和timer的执行先后没法确定.
当我们把process.nextTick加入call stack时, next tick一定最先执行它的任务,
结束后耗时基本上已经超过1ms了, 于是timer的任务先被执行.
最后check的任务得到执行, 这也是为什么会有确定的输出结果.
紧接上文, 在process.nextTick的源码里发现了MicroTask这个东西, 当时并没有解释此为何物,
只描述了行为. 因为提起microTask就不得不回到Browser环境来.
参见 https://html.spec.whatwg.org/multipage/webappapis.html#event-loops
异步任务都需要依赖一个宿主环境, 由它提供一个称之为"事件循环"的机制, 正如Node一样, 浏览器里的async也依赖这么一个event loop.
相比Node, 浏览器里的event loop就简单的多. 这个loop只检查两类queue: macroTaskQueue, microTaskQueue.
分别存放macroTask和microTask.
每个event loop可以有多个macroTask队列, 这类任务和(浏览器中的)setTimeout任务的行为类似,
都是在每个tick执行队列里的一个任务. 相似的特点还有他们都是在每个tick的开始执行的.
包括: timer task, I/O task
每个event loop仅有一个microTask队列, 类似process.nextTick, 一旦执行就一气呵成.
正符合process.nextTick源码里的microtask的行为.
包括: Promise task
每个tick的执行流程:
更多解释参见 https://jakearchibald.com/2015/tasks-microtasks-queues-and-schedules/
以及 https://html.spec.whatwg.org/multipage/webappapis.html#event-loops
这些任务可以是:
setInterval()的问题在定时器的选择上, 有经验的老手会告诉你别用setInterval. 为什么? setInterval的功能是周期性触发定时事件, 而不是周期性执行任务. 比如我们想每隔50ms执行一次syncTask函数, 直觉上告诉我们这样写:
setInterval -> syncTask(), 50但是JavaScript单线程模型告诉你这样不行, 假如syncTask是一个计算量非常大的任务(执行时间远大于50ms), 那么主线程在syncTask结束调用之前是不会交出使用权的, 而计时器的tick是在另一个线程中执行的, 所以计时器依然会生效: 每隔50ms触发定时, 同时将每个任务压入队列等待主线程空闲, 而一旦主线程空闲下来, 队列里的任务将在next tick依次执行掉. 如此往复, 队列里的任务会越积越多, 而我们每隔50ms的预期也就没法实现了. 与其说是不能实现预期功能, 不如说这会带来严重后果: 随着任务的积压, 主线程将马不停蹄的执行syncTask, 这会导致主线程负载过高, 随之而来的就是严重的性能损耗, 无法及时(甚至根本不能)做出响应.
这里要说的不包含上面讲的任务积压导致执行周期不精确问题, 而是计时器本身的_bug_. 众所周知CPU都有个时钟周期, 亦作'tick', 基本上计算机的所有工作都依赖时钟, 它也代表一台计算机所能计量的最小时间单位, 一般计算机大概在3~4ms左右.
所以你把代码写成这个样子然后指望它立马执行是不可能的:
setTimeout -> console.log 'haha', 0为了证明所言不虚, 我们可以写一个这样的代码, 利用累计任务计算一个平均值:
diff = 0
i = 0
test = ->
if i < 10000
i++
initTime = Date.now()
setTimeout ->
startTime = Date.now()
diff += startTime - finishTime
test()
, 0
test()
# 计算平均延时
console.log diff / i单线程事件驱动确实为JavaScript带来了莫大的优势, 然而不能充分利于CPU也常被人诟病.
在浏览器里, js和UI渲染是互斥的线程, 一旦执行点耗时的逻辑, 页面渲染就卡住了, 必须要等到js跑完. 而这种设计是为了保证交互上逻辑正确性: js触发的UI重绘一定要等到js执行完, 一旦js线程与UI线程并行执行可能导致不可预期的后果.
异步事件又称"任务", 即前文提到的macrotask/microtask.
同步事件即"事件".
没有异步事件那么复杂, 他们的执行会在this tick而不用等到next tick, 就是触发即执行. 同步事件是Event Driven Programming(Pub/Sub设计模式)的一个实现, 不需要额外线程或其他底层机制的辅助便可实现, 如Node里的EventEmitter, 触发的都是同步事件, 触发原理就是普通的JavaScript代码遍历一次事件名字对应的数组中保存的回调函数, 很显然这和其他代码并没有什么两样, 所以是同步的.
除了EventEmitter, 浏览器中的大多数DOM事件(比如click事件)都是同步的, 为此可以在浏览器里做个试验:
a = document.querySelector "#a"
a.onclick = -> console.log "SYNC"
for i in [0..100]
setTimeout ->
console.log "ASYNC"
, 0
a.click()
a.click()
console.log i所有的ASYNC会在整个循环结束之后打印, 而SYNC会在每次循环最开始时打印两次, 然后打印当前迭代次数, 这就是同步事件与异步事件的区别.
简记为: 凡是用纯JavaScript实现的事件都是同步的, 只有底层实现的事件才有异步的可能.
但你可能会说在一个循环执行完之前单击几次鼠标, 难道会在循环中间打印SYNC ? 也就是这样:
a = document.querySelector "#a"
a.onclick = -> console.log "SYNC"
for i in [0..10000]
# 在循环结束之间单击鼠标
console.log i你会发现你的单机并没有生效, 而是在整个循环结束之后打印响应次数的SYNC. 不是说click是同步吗, 为什么会出现这种情况?
看了前面的任务自然会明白.
我们谈到同步事件时讲的是DOM上的事件, 第一个a.click()是DOM API提供的, 或者说是和Node EventEmitter的emit()一样的方式实现的, 由于和普通代码没区别, 肯定在循环中被处理了.
然而真正的单机事件是由操作系统触发, 然后传递给浏览器的, 这属于系统级的事件(task), 所以是异步的. 当浏览器拿到单击事件通知, 会在底层的回调里调用DOM API的click()方法来实现DOM click. 这和Node里的异步/同步事件协作方式别无二致, 所有的异步函数都是靠底层异步事件通知上层的同步事件, 再由同步事件触发当前环境的回调函数.
该怎么写? 首先我们要明确问题出现的根源: 定时器不管当前任务是否执行完毕都会周期性添加任务到队列. 若要解决问题, 就该让定时器在任务执行完毕后在开始计时, 这里使用了另一个计时器setTimeout, 以形似递归的手段解决了问题:
task = =>
setTimeout ->
syncTask()
task()
, 50
task()JavaScript的一个遗憾就是不支持尾递归优化, 这给有情怀的函数式追随者泼了一头冷水. 不过好消息是我们可以同过一个小小的hack手段实现"尾递归":setTimeout.
因为setTimeout的异步性, 当调用结束时(调用会立即结束), 整个函数会释放掉当前堆栈(但是依情况可能保留context对象), 因此无论"递归"调用多少次都不会出现'RangeError: Maximum call stack size exceeded'的错误:
# 普通无限递归调用
recu = ->
console.log 1
recu()
# => RangeError: Maximum call stack size exceeded
# 使用setTimeout的模拟"尾递归"
recu = ->
console.log 1
setTimeout recu, 0
# => 1 1 1 1 .....因为timer触发的回调永远是在nextTick里执行的, 所以这就给了程序流程重新调度的机会.
比如在页面的某个div上添加了click监听器执行taskA, 然后因为某个需求又在其子元素(比如一个按钮)上添加了一个click监听器执行taskB. 要求在click按钮时先执行taskA, 再执行taskB.
DOM上的事件模型有一个冒泡过程, 一般都是先从最深层的子节点触发事件, 事件逐层冒泡, 最后才触发最上层的回调, 冒泡是同步的.
btn.onclick = (e) ->
taskB()
div.onclick = (e) ->
taskA()
# 永远都是先taskB()后taskA()用setTimeout把taskB放到next Tick从而改变了执行流程, 所以先执行taskA了:
btn.onclick = (e) ->
setTimeout taskB, 0
div.onclick = (e) ->
taskA()再举一个实际的例子. 把输入框里输入的英文实时地变成大写.
# 貌似该这么写...
input.onchange = (e) ->
@value = @value.toUpperCase()可是并没有达到预期的效果: 总是在输入下一个字符时才会把前一个转大写. 这是因为onchange事件总是在输入框的value赋值前触发. 知道了原理我们就可以搞定了:
input.onchange = (e) ->
setTimeout =>
@value = @value.toUpperCase()
, 0前面提到的JavaScript单线程带来的问题: 跑脚本时DOM无法及时渲染. 这里有个活生生的例子:
实现背景色随时间的灰度渐变. 还是先来一段理想中的代码:
div.background = "rgb(#{i},#{i},#{i})" for i in [0...255]但是循环导致没空渲染UI, 看到的结果就是开始是白色, 突然变成黑色. 这时next tick就能大展身手了:
# 把js放到next tick里,先让UI渲染占用线程
liner = (i) ->
div.background = "rgb(#{i},#{i},#{i})"
setTimeout liner, 0, ++i
liner 0现在就可以看到灰度的渐变过程了, 这也是Worker出现前早先解决密集任务下cpu负载过高问题的思路: 分割任务.
本来懒得记录这种命令介绍类的日志, 都是Google一大把一大把的文章. 但我对分区一向很谨慎, 为了防止今后重蹈覆辙, 还是决定把分区相关的步骤有条理的记一下.
Q: 如何对设备分区?
A:
fdisk <device>命令搞定. 子命令很简单, 忘记如何操作只需m就行,p是最常用的没有之一:查看设备当前的分区表. 现在fdisk很人性化, 分区时可以输入+N<G|M|K>(比如+2G)来确定分区大小.parted命令更强, 支持2T以上的分区. 当然这是题外话, 简单的分区也是可以的. 子命令同样简单, help或者他的alias:m会告诉你想要的.分区之后如果不想重启, 就手动刷新一下内核分区表(就是从硬盘分区表里重读一遍): partprobe.
Q: 如何建立文件系统?
A: 在使用disk之前, 必须格式化, 即建立操作系统能识别的文件系统.假如已经通过上一步划分了分区/dev/sda9, 这一步操作即可将该分区格式化成ext4:
mkfs.ext4 /dev/sda9
其他格式可以键入mkfs并按两次tab键查看.
one more thing, 格式化分区之前别挂载它.
Q: 如何调整文件系统的大小?
A: 目前我所知道的就是resize2fs.如果在上一步你并没有将整个分区格式化, 这样partition可能留有空余. 想把这部分也利用起来, 就可以:
resize2fs /dev/sda9
后面也可以接参数,表示额外需要的新空间大小:
resize2fs /dev/sda9 [Ns|K|M|G]
注意resize大小永远不能超过partition大小.
允许扩增已挂载的文件系统, 但要减小文件系统必须先卸载.
其余注意事项详见man resize2fs
Q: 如何对格式化之后的分区调整大小?
A: 注意与上面的区别. 如果根分区已满, 并且当初安装系统时手残没有为/usr,/var, /home等目录划分独立挂载点. 其实这个问题隐含了两个其他问题:
如何调整已挂载的根目录大小?
最保险也是最通用的做法是livecd, 在livecd下原有设备根分区是unmounted的, 因此可以当做普通分区一样resize.
如果想折腾一下, 也可以用fdisk, fdisk允许在挂载状态下对设备重新分区:
fdisk /dev/sda
# 记住根目录分区的起始柱面
> p
# 删根目录所在分区
> d
# 如果没有空闲空间那就继续删
...
# 从原来根分区起始处重建分区
> n
# 重设大小...
这样一番折腾, 原有的数据会不会被清掉? 答案是不会, 不然我为何会记录这么脑残的做法...
不过为了以防万一也应该备份一下数据.
之后参照上一步, 调整以下分区上的文件系统大小.
如何调整其他文件系统大小?
上面的步骤对这个完全适用. 除了fdisk, 也可以用parted, 或者建立LVM(逻辑卷管理), 很明显后者的做法是一劳永逸的.
这在parted里很简单, 不用删除分区再重建, 直接一个子命令resizepart搞定分区调整:
parted /dev/sda9
# 出于习惯, 可以先看看当前分区表
> p
# 比如调整分区号为 5 的partition, end参数代表硬盘位置, 表示要扩展到哪里, 可正可负, 比如: 4G, 10%, -5G.
> resizepart 5 <end>
记得先卸载目标分区, 调整之后执行partprobe刷新内核分区表.然后用resize2fs重新调整文件系统大小.
今年外卖平台火遍大江南北.诸如饿了么,美团外卖,百度外卖,淘点点,超人外卖等等等等层出不穷,校园周边小餐馆的生意也做的是风生水起.各种打折,各种送饮料,各种首单立减,真让整日宅在寝室和实验室的家伙欲罢不能啊~
不过呢好日子总会有到头哪一天.随着饮料越送越差,折扣也越来越少,我们开始埋怨吃不到物美价廉的美食了. 于是乎,借着某位室友创业的热情,在另一位猥琐室友的怂恿下,走上了一条"革命之路", 因为当时常送果粒橙, 于是我们为这个计划起名为果粒橙保卫战.
不扯淡了,其实就是"外卖比价". 我们设计应用架构, 分解任务模块, 规划一系列前进流程, 差不多当晚就开始敲代码.
...当然,代码还要靠我来写-_-,这是既苦逼又令人兴奋的工作.(你能理解为什么)
我把应用核心逻辑模块分为两部分, 一块是爬虫,用于抓取各大外卖平台的网页数据;另一块是数据处理,把爬虫爬来的数据做清洗,格式转换和聚类.
架构分为定时更新任务和web服务.
后台更新任务单独启用一个进程,定时(根据正常人的进食时间统计, 设定约每3个小时更新一次)向一组外卖平台网站请求所需数据,经过清洗和转化,分类存储到数据库中.
web服务提供一个面向用户的接口,接收用户查询的地点,返回数据库中整理过的周边餐饮.
爬取数据是个体力活, 你首先要打开控制台看着DOM树一个一个的找父子节点,记id,class,tagname.换句话说写出每家平台通用的CSS path,如果是动态加载的数据,就要找到那个请求地址, 如果数据是JavaScript动态生成的, 你还要模拟执行一次以得出想要的结果. 前台测试通过后,还要用curl之类的工具通过non-browser测试,这是个技术活,因为几乎所有网站都对爬虫做了防范,你要想方设法欺骗web服务器,至于如何做就不谈了(详见之前写的一篇"crawl前端攻防战"), 总之,request模块不适用这个抓取过程, 因此我写了一个简版request专门应付我们要爬的网站server.
得到了原始的html,就可以做数据清洗了,这里使用了Node第三方cheerio模块. 提取必要信息形成一个二维数组,每个元素是一个JSON对象:
[
// platform 1
[
// restaurant 11
{
name: '',
proxy: '',
others: ...
},
// restaurant 12
{
name: '',
proxy: '',
others: ...
}, ...
],
// platform 2
[
// restaurant 21
{
name: '',
proxy: '',
others: ...
},
// restaurant 22
{
name: '',
proxy: '',
others: ...
}, ...
],
...
]这个数据结构的核心字段是name和proxy, 分别标识某个餐馆和对应的外卖平台,用于后期的数据处理.
进行数据处理的下一步:格式化. 因为web服务是依据用户的地点查询获取周边餐饮, 所以我们最重要返回一组周边餐饮信息, 那么考虑设计合适的数据存储schema对查询性能的提升十分重要.
我反反复复设计了几种格式,最终综合格式处理的方便和数据库读写操作的方便,我把schema规定为如下:
{
name1: [proxy1, proxy2, ..],
name2: [proxy1, proxy2, ..],
...
}每次抓取的数据经过处理, 得到如上格式存入数据库中, 这样每次查询时直接抽取周边店名,返回为其代理的外卖平台和每个平台的对这家店的优惠信息.
那么如何有效的转化数据呢? 我设计了一个转化算法. 我们通过爬虫和数据清洗,首先得到那个二维数组, 然后去掉对此步骤不重要的信息, 将二维数组的每个元素映射成对应的name字段的值:
var result = restaurants.map(function (proxy) {
return proxy.map(function (restaurant) {
return restaurant.name;
});
});处理后得到如下格式:
[
[
name1, name2, ...
],
[
name1, name2, ...
],
...
]这样看着就方便多了不是? 然后进行reduce操作:
result.reduce(function (a, p, i, map) {
var o = {};
p.forEach(function (n, j) {
o[n] = [ [i, j] ];
for (var l, m = i + 1; m < map.length; m++)
if ((l = map[m].indexOf(n)) != -1)
o[n].push([m, l]);
});
// 合并
var keys = Object.keys(a);
keys.length && keys.forEach(function (k) {
if (o[k])
o[k] = a[k].length > o[k].length ? a[k] : o[k];
else
o[k] = a[k];
});
return o;
}, {});上面这个函数是整个算法的核心. 最外层reduce整个result数组. 每次reduce调用会新建一个JSON对象, 对于每个子数组, 也就是包含一个平台下所有餐馆名字的数组, 遍历他们, 将不同的名字和对应在二维数组中的位置保存在外层建立的JSON对象里, 并循环后面的子数组, 如果子数组中包含重名的元素,也就是同一家店,也把它的位置push到JSON对象的对应名字的数组里. 在这轮reduce的最后, 合并上一次reduce的结果: 向JSON对象中添加不存在的name, 对于已存在的name, 选取数组长度较大的保存, 最后把这个JSON对象作为这轮reduce的结果返回.
这样, 经过几次reduce, 就筛选出所有店家和他们在原始二位数组中所在的位置:
{
name1: [[x1, y1], [x2, y2], ...],
name2: [[x1, y1], [x2, y2], ...],
...
}最后把位置替换成详细信息:
for (var i in result)
result[i] = result[i].reduce(function (arr, b) {
arr.push(restaurants[b[0]][b[1]]);
return arr;
}, []);就得到了我们想要的格式:
{
name1: [proxy1, proxy2, ..],
name2: [proxy1, proxy2, ..],
...
}整个算法代码如下:
function normalize (restaurants, callback) {
var result = restaurants.map(function (proxy) {
return proxy.map(function (restaurant) {
return restaurant.name;
});
}).reduce(function (a, p, i, map) {
var o = {};
p.forEach(function (n, j) {
o[n] = [ [i, j] ];
for (var l, m = i + 1; m < map.length; m++)
if ((l = map[m].indexOf(n)) != -1)
o[n].push([m, l]);
});
// 合并
var keys = Object.keys(a);
keys.length && keys.forEach(function (k) {
if (o[k])
o[k] = a[k].length > o[k].length ? a[k] : o[k];
else
o[k] = a[k];
});
return o;
}, {});
for (var i in result)
result[i] = result[i].reduce(function (arr, b) {
arr.push(restaurants[b[0]][b[1]]);
return arr;
}, []);
return callback(result);
};但是随着我们观察解析结果, 发现有的商家在不同平台上注册的店名是不一样的! 举个栗子: 在饿了么上名为"辣婆婆川味馆"的一家店, 到了美团上是"辣婆婆川菜馆", 而事实上这两个都是同一家,只是注册的名字不同罢了. 那么问题就来了: 通过我们上面的算法无法识别这些名字上的差异, 最终会将诸如"川菜馆"和"川味馆"视为两家店.
这属于字符串近似匹配. 说来也巧, 正在我寻找解决方案时, 算法分析的最后一课恰好提到了"文本的近似匹配问题". PPT里提供了三种思路, 为了尽快实现, 我简单的看了一下基于编辑距离的近似匹配原理.
何为编辑距离? 简单说就是 "由字符串A变换到字符串B需要的最少步数"--wikipadia. 比如:
A = "abcbab"
B = "abcad"
这个变换是单个字符的"添加,剔除,修改", 那么从A到B最少需要两次变换, 描述如下:
function computeEditd(p, t) {
var plen = p.length + 1;
var tlen = t.length + 1;
var i, j;
var matrix = new Array(plen);
// 初始化矩阵
for (i = 0; i < plen; i++)
matrix[i] = new Array(tlen + 1);
// 动态规划方法填充矩阵
for (i = 0; i < plen; i++)
for (j = 0; j < tlen; j++)
if (i == 0)
matrix[i][j] = j;
else if (j == 0)
matrix[i][j] = i;
else
matrix[i][j] = Math.min.apply(null, [
matrix[i][j - 1] + 1,
matrix[i - 1][j] + 1,
(function () {
if (p[i] == t[j])
return matrix[i - 1][j - 1];
else
return matrix[i - 1][j - 1] + 1;
})()
]);
return matrix[p.length][t.length];
};由于满足"优化子结构"与"重叠子问题", 因此算法属于动态规划策略的应用.
采用这个方法修改原有算法:
function normalize(restaurants, callback) {
var result = restaurants.map(function (proxy) {
return proxy.map(function (restaurant) {
return restaurant.name;
});
}).reduce(function (a, p, i, map) {
var o = {};
p.forEach(function (n, j) {
o[n] = [ [i, j] ];
for (var l, m = i + 1; m < map.length; m++) {
// 近似匹配
var likely = map[m].reduce(function (tuple, e, l) {
// 计算并更新编辑距离
var newEditd = editdUpdate(computeEditd(e, n), tuple.editd);
tuple.pair = newEditd < tuple.editd ? [m, l] : tuple.pair;
tuple.editd = newEditd;
return tuple;
}, { editd: Infinity });
// 找到其他组中的近似元素
if (likely.editd < 6)
o[n].push(likely.pair);
}
});
// 合并
var keys = Object.keys(a);
keys.length && keys.forEach(function (k) {
if (o[k])
o[k] = a[k].length > o[k].length ? a[k] : o[k];
else
o[k] = a[k];
});
return o;
}, {});
console.log(result);
for (var i in result)
result[i] = result[i].reduce(function (arr, b) {
arr.push(restaurants[b[0]][b[1]]);
return arr;
}, []);
return callback(result);
};这里面仍有一个问题, 既然新的算法是根据编辑距离来判定商家的, 那究竟如何定义editd的下限? 这个没有固定标准, 取决于实际测试, 根据解析结果手动调整min_editd的大小. 运行了修改后的程序, 果然很多"有绰号"的餐馆都各自归为一类了, 但又发现了新的问题: 有的店名本身就很短, 这样的话如果低于edited, 两家不同的店就会自动被判为同一家店. 还有, 某些店属于那种连锁机构, 比如"枫林黄米饭(工大店)", "枫林黄米饭(贵新店)", 他们本身就差两个字, 这样也很容易被归为同一家, 可是按照地点的不同又不属于同一家. 看来我们的算法还需要进一步改进. 但是就算是改进, 也只能解决第一种问题, 第二个问题不是那么简单就能解决的, 这涉及到了一个智能识别的问题, 甚至还需要人工参与调整. 由于时间关系暂时也没有进一步研究.
经过数据处理阶段的数据, 就可以将其存入数据库了. 我选用leveldb作为数据持久化方案.一是因为小巧,对系统资源占用很少;二是读性能颇高.如何将格式化的数据存入leveldb? 我仍是按照查询性能优先的原则设计了存储方案.:
{
key: location-restaurantName,
value: [proxy1, proxy2, ...]
}
因为value中的值不是经常变化的(与同一家餐馆合作的外卖平台也就那么几家, 基本上不会变, 变化的是各平台的优惠政策),所以直接保存在value的数组里.
到此为止, 整个后台定时任务模块就设计完了.
Web服务上, 我使用了比较熟悉的express框架提供用户接口. 最初的打算是让用户自己输入查询地点, 直接传到server执行查询逻辑, 但这个方法的弊端逐渐显露出来. 一次测试中, 我输入了一个新的查询地点, 按正常的程序逻辑来说, 这一请求首先会到达数据库, 如果未在数据库中找到该地点, 则调用爬虫模块, 执行"抓取-清洗-格式化"流程, 然后把结果数据先返回给客户端, 随后异步写入leveldb.
这一过程看似合情合理: 采用类似DNS服务器的原理, 根据用户的请求缓存新的信息. 但查询某些学校时程序会crash, 有两种情况:
由于周边信息是通过对应平台使用的地图服务获取的, 而这些平台的位置查询服务均是按选项提供的, 也就是说他会对你的输入做近似匹配, 并提供几个地点数据库中相似结果供你选择, 这样就避免了无效输入导致的错误结果. 但是对我们这些靠爬取数据为生的家伙来说, 我们往往会忽视无效输入的后果: 我们潜意识认为地图API会提供给我们需要的一切信息! 而用户输入可能不准确, 当我们用这些不准确的结果调用API时, 就会得到"空结果", 空结果在外卖平台网页端上的呈现为"未找到"等等错误提示. 如果我们对这样一个网页执行"抓取-清洗-格式化", 那么在清洗的过程中就会crash!
我想干脆也模仿那些外卖平台那样, 提供选择性查询, 对于查询结果的差别, 取并集就可以了. 但暂时也是没那工夫, 也怕由此衍生出更多未知的问题. 后来还是启用了HTTP服务器集群, 采用那种经典的"Master-Slaver"架构监听crash情况并平滑重启, 貌似将来也能成为个备选方案啥的~.
有一段时间我几乎每个三小时刷一次, 看看三大外卖主力有木有什么新优惠政策, 心想再做一个trending系统就更好了, 看看外卖优惠哪家强? 找ctheyvs来帮忙啊~
当时列出的还有稳定性,安全性测试以及新功改进/添加什么的, 都还没开始. 前端页面让室友来写, 这都一个多月了还没搞定这让我情何以堪... 我也是醉啦~
跟我料想的差不多, 大多数人都是三分钟热血, 在热血中豪情壮志,指点山河,激扬文字,舍我其谁. 但三分钟过后血压又下来了.. 这尼玛, 哎. 不过也无所谓喽, 我这个人呢很随性, 向来对很多事都无所谓的啦. 不是什么原则问题, 爱干嘛干嘛吧~.
但毕竟这也算一个酷酷的玩意儿, 里面也涉及到不少好玩的东西和技术, 涨涨经验还是不错的嘛~~~ 你说是不?
这是机智的面试官问的第三个问题~
我当时回答的比较含糊,因为毕竟一个网络协议的内容如此之复杂,之前也并没有过于关注掩码这东西究竟起什么作用。出于被自己熟悉领域难住的羞愧,面试后立马去翻看RFC,找到好长一大段的描述。
由于目前网络上还没有关于WebSocet各方面介绍与考量十分详尽的文章(当然英文版的RFC除外),这里我说一下那个神奇的Masking Key是做什么的吧。
首先不要把它与IP网络中的子网掩码弄混,绝壁不是一个概念,后者是用来划分子网的, 而前者是考虑到网络安全问题而设计的。
WebSocket协议规范里讲:“为了避免迷惑网络中介(如代理服务器),以及涉及到安全问题,客户端必须mask所有送给服务器的frame。”
不明白怎么回事?没关系,在此之前先了解下网络上针对基础设施的攻击,然后才能明白掩码的设计道理。
通过WebSocket协议成为被攻击对象的,除了终端设备之外还有其他部分的web基础设施,比如代理服务器就可能成为攻击的对象。
随着websocket协议被开发出来,一项针对代理服务器的攻击(污染那些广泛部署的缓存代理服务器)实验也开始进行。
一般形式的攻击是跟被攻击者控制的服务器建立连接,并构造一个类似WebSocket握手一样的UPGRADE请求,随后通过UPGRADE建立的连接发送看起来就像GET请求的frame去获取一个已知资源(在攻击场景中可能是一个点击跟踪脚本或广告服务网络中的资源)。
之后远程服务器会返回某些东西,就像对于这个伪造GET请求的响应,并且这个响应会被很多广泛部署的网络中间设备缓存,从而达到了污染缓存服务器的目的。对于这个攻击的产生的效应,可能一个用户被诱导访问受攻击者操控的服务器,攻击者就有可能污染这个用户以及其他共享相同缓存服务用户的缓存服务器,并跨域执行恶意脚本,破坏web安全模型。
为了避免面这种针对中间设备的攻击,以非HTTP标准的frame作为用户数据的前缀是没有说服力的,因为不太可能彻底发现并检测每个非标准的frame是否能够被非HTTP标准的中间设施识别并略过,也不清楚这些frame数据是否对中间设施的行为产生错误的影响。
对此,WebSocket的防御措施是mask所有从客户端发往服务器的数据,这样恶意脚本(攻击者)就没法获知网络链路上传输的数据是以何种形式呈现的,所以他没法构造可以被中间设施误解为HTTP请求的frame。
这就是掩码存在的原因。
本来到这里就该结束了, 但是协议很负责的深入说明了掩码选择上的要求~
客户端必须为发送的每一个frame选择新的掩码,要求是这个掩码无法被提供数据的终端应用(即客户端)预测。
算法的选择上,为了保证随机性,可以借助密码学中的随机数生成器生成每个掩码。
倘若使用相同的掩码会有什么后果呢?
假设每次发送frame使用了相同的掩码或下一个掩码如何选择被猜出的话,攻击者就可以发送经过mask后类似HTTP请求的frame(做法很简单:攻击者以希望在网络链路上显示的形式构造数据,然后用下一个掩码mask再发出去)。
至于如何用掩码mask原始数据,在前面的 学习WebSocket协议—从顶层到底层的实现原理(修订版) 中已经说过了——按位做循环异或运算.
除此之外,另一个要求是一旦传输开始,客户端必须不准再修改传输的内容,否则攻击者将会发送一个用已知数据(如全0)初始化的frame,并通过第一部分数据的回执(经过mask的数据)计算本次使用的掩码,然后修改将要发送的frame使之mask后表现的是一个HTTP请求,原理同前面所讲,不再赘述。
上面所描述的安全模型重点关注的是客户端发送类HTTP请求的frame给服务器,所以仅仅需要mask从客户端到服务器的数据,反之则没有mask,但是为了完成请求,前提是客户端必须能够伪造请求。因此,并不强制要求mask双向通信,只要保证一方的数据是经过mask的即可。
尽管掩码提供了保护,但不符合规定的HTTP代理服务器仍是那些“不使用掩码的客户端-服务器”攻击对象!
所有内容归结为一句话:为防止攻击者获知网络链路中传输的原始数据,提供不可预测的掩码至关重要。
涉及源码
src/node_main.cc
src/node.h (src/node.cc)
src/node.js
src/env.h
这篇日志的诞生纯属偶然,我当初只是想寻找NPM上处理底层网络的模块用来处理ARP协议,搜索了半天并没有发现合适的,最贴近的也就是raw_socket模块,但它只能用来处理IP协议上层和ICMP数据报.然后我就开始各种Google各种Baidu,未果.于是想自己扩充一下这个底层功能,便查找C/C++ addon的文档,这就一不小心"误入歧途"了,从学习addon到研究模块加载最后成了源码阅读.
也好,在这个时候从设计和编码的角度重审Node也别有一番体会.
拿来Node的源代码,熟悉源码构建编译的童鞋一眼就会发现src,lib目录.这表示Node的源码结构很清晰,以下是源码目录的主要结构:
deps/ Node核心功能的依赖,包括V8引擎源码,libuv源码,openssl,npm等等lib/ JavaScript核心模块(*.js),如http.js,net.js等src/ Node架构的核心源代码以及C++核心模块/内置模块(*.cc | *.h)tool/ 包含Node的项目构建工具gyp,js2c.py等,用来编译源码生成二进制文件,预处理工作等node.gyp 重要的构建配置文件common.gyp 同样是一个配置文件为了了解Node工作流程,首先进入src目录,找到node_main.cc文件.整个文件的最后几行包含着令人倍感亲切的int main()主函数,进程就从这里开始了:
// UNIX
int main(int argc, char *argv[]) {
return node::Start(argc, argv);
}
#endif我将按照Node进程的真正流程一步步说明,因此下面代码中的嵌套有些地方并不是真实的代码结构,可以通过阅读我的注释明白情况.
接下来是src/node.cc文件,包含了主要的执行逻辑,node_main.cc中调用的Start(argc, argv)函数就是在这里面实现的:
// 源码3581行处:Start函数,这个函数做一些初始化主程序环境变量,配置v8环境,libuv事件循环等基本工作
int Start(int argc, char** argv) {
// ...
// ...
// Hack around with the argv pointer. Used for process.title = "blah".
argv = uv_setup_args(argc, argv);
// This needs to run *before* V8::Initialize(). The const_cast is not
// optional, in case you're wondering.
int exec_argc;
const char** exec_argv;
// 源码 3601行:调用Init.注释里说该函数的调用要在V8::Initialize()之前.
Init(&argc, const_cast<const char**>(argv), &exec_argc, &exec_argv);
// 源码 3360行:声明了Init函数,它接受了初始传递的参数长度,参数指针等.这个函数就是具体的初始化函数
void Init(int* argc,
const char** argv,
int* exec_argc,
const char*** exec_argv) {
// 这里是一些初始化libuv函数的操作.
// Initialize prog_start_time to get relative uptime.
prog_start_time = uv_now(uv_default_loop());
// Make inherited handles noninheritable.
uv_disable_stdio_inheritance();
// init async debug messages dispatching
// FIXME(bnoordhuis) Should be per-isolate or per-context, not global.
uv_async_init(uv_default_loop(),
&dispatch_debug_messages_async,
DispatchDebugMessagesAsyncCallback);
uv_unref(reinterpret_cast<uv_handle_t*>(&dispatch_debug_messages_async));
// 还有几个初始化V8以及处理传入参数的函数
// ...
// ...
// 源码3610行:Init函数执行完毕,执行V8::Initialize()函数,并进入启动的最后阶段
V8::Initialize();
{
Locker locker(node_isolate);
HandleScope handle_scope(node_isolate);
Local<Context> context = Context::New(node_isolate);
// 重要的变量env,代码里很多地方都要用到这个变量.
// 通过createEnvironment函数创建了env对象
Environment* env = CreateEnvironment(
node_isolate, context, argc, argv, exec_argc, exec_argv);
// 源码 3534行:声明了CreateEnvironment函数
Environment* CreateEnvironment(Isolate* isolate,
Handle<Context> context,
int argc,
const char* const* argv,
int exec_argc,
const char* const* exec_argv) {
HandleScope handle_scope(isolate);
Context::Scope context_scope(context);
// 其实在这里创建了env对象
Environment* env = Environment::New(context);
uv_check_init(env->event_loop(), env->immediate_check_handle());
uv_unref(
reinterpret_cast<uv_handle_t*>(env->immediate_check_handle()));
uv_idle_init(env->event_loop(), env->immediate_idle_handle());
// Inform V8's CPU profiler when we're idle. The profiler is sampling-based
// but not all samples are created equal; mark the wall clock time spent in
// epoll_wait() and friends so profiling tools can filter it out. The samples
// still end up in v8.log but with state=IDLE rather than state=EXTERNAL.
// TODO(bnoordhuis) Depends on a libuv implementation detail that we should
// probably fortify in the API contract, namely that the last started prepare
// or check watcher runs first. It's not 100% foolproof; if an add-on starts
// a prepare or check watcher after us, any samples attributed to its callback
// will be recorded with state=IDLE.
uv_prepare_init(env->event_loop(), env->idle_prepare_handle());
uv_check_init(env->event_loop(), env->idle_check_handle());
uv_unref(reinterpret_cast<uv_handle_t*>(env->idle_prepare_handle()));
uv_unref(reinterpret_cast<uv_handle_t*>(env->idle_check_handle()));
if (v8_is_profiling) {
StartProfilerIdleNotifier(env);
}
Local<FunctionTemplate> process_template = FunctionTemplate::New(isolate);
// 然后在这里定义了process类
process_template->SetClassName(FIXED_ONE_BYTE_STRING(isolate, "process"));
// 这里着重注意.因为后面的调js主文件(src/node.js)时传入的就是这个process对象
Local<Object> process_object = process_template->GetFunction()->NewInstance();
// 这里也很重要!以后process对象都是通过env调用的
env->set_process_object(process_object);
// 紧接着这里对process对象进行细节配置
SetupProcessObject(env, argc, argv, exec_argc, exec_argv);
// ...
// 源码2586行:声明了SetupProcessObject函数,你会在这个函数中发现熟悉的身影,没错想就是Node环境中的process对象的那些属性和方法
void SetupProcessObject(Environment* env,
int argc,
const char* const* argv,
int exec_argc,
const char* const* exec_argv) {
HandleScope scope(env->isolate());
// 获取CreateEnvironment函数中创建的process对象
Local<Object> process = env->process_object();
process->SetAccessor(env->title_string(),
ProcessTitleGetter,
ProcessTitleSetter);
// 后面的应该不用说,大家都能看明白
// READONLY_PROPERTY函数设置只读属性
// process.version
READONLY_PROPERTY(process,
"version",
FIXED_ONE_BYTE_STRING(env->isolate(), NODE_VERSION));
// process.moduleLoadList
READONLY_PROPERTY(process,
"moduleLoadList",
env->module_load_list_array());
// process.versions
Local<Object> versions = Object::New(env->isolate());
READONLY_PROPERTY(process, "versions", versions);
const char http_parser_version[] = NODE_STRINGIFY(HTTP_PARSER_VERSION_MAJOR)
"."
NODE_STRINGIFY(HTTP_PARSER_VERSION_MINOR);
READONLY_PROPERTY(versions,
"http_parser",
FIXED_ONE_BYTE_STRING(env->isolate(), http_parser_version));
// +1 to get rid of the leading 'v'
READONLY_PROPERTY(versions,
"node",
OneByteString(env->isolate(), NODE_VERSION + 1));
READONLY_PROPERTY(versions,
"v8",
OneByteString(env->isolate(), V8::GetVersion()));
READONLY_PROPERTY(versions,
"uv",
OneByteString(env->isolate(), uv_version_string()));
READONLY_PROPERTY(versions,
"zlib",
FIXED_ONE_BYTE_STRING(env->isolate(), ZLIB_VERSION));
const char node_modules_version[] = NODE_STRINGIFY(NODE_MODULE_VERSION);
READONLY_PROPERTY(
versions,
"modules",
FIXED_ONE_BYTE_STRING(env->isolate(), node_modules_version));
#if HAVE_OPENSSL
// Stupid code to slice out the version string.
{ // NOLINT(whitespace/braces)
size_t i, j, k;
int c;
for (i = j = 0, k = sizeof(OPENSSL_VERSION_TEXT) - 1; i < k; ++i) {
c = OPENSSL_VERSION_TEXT[i];
if ('0' <= c && c <= '9') {
for (j = i + 1; j < k; ++j) {
c = OPENSSL_VERSION_TEXT[j];
if (c == ' ')
break;
}
break;
}
}
READONLY_PROPERTY(
versions,
"openssl",
OneByteString(env->isolate(), &OPENSSL_VERSION_TEXT[i], j - i));
}
#endif
// process.arch
READONLY_PROPERTY(process, "arch", OneByteString(env->isolate(), ARCH));
// process.platform
READONLY_PROPERTY(process,
"platform",
OneByteString(env->isolate(), PLATFORM));
// 通过进程最开始传入的参数变量argc,argv设置process.argv
// process.argv
Local<Array> arguments = Array::New(env->isolate(), argc);
for (int i = 0; i < argc; ++i) {
arguments->Set(i, String::NewFromUtf8(env->isolate(), argv[i]));
}
process->Set(env->argv_string(), arguments);
// process.execArgv
Local<Array> exec_arguments = Array::New(env->isolate(), exec_argc);
for (int i = 0; i < exec_argc; ++i) {
exec_arguments->Set(i, String::NewFromUtf8(env->isolate(), exec_argv[i]));
}
process->Set(env->exec_argv_string(), exec_arguments);
// create process.env
Local<ObjectTemplate> process_env_template =
ObjectTemplate::New(env->isolate());
process_env_template->SetNamedPropertyHandler(EnvGetter,
EnvSetter,
EnvQuery,
EnvDeleter,
EnvEnumerator,
Object::New(env->isolate()));
Local<Object> process_env = process_env_template->NewInstance();
process->Set(env->env_string(), process_env);
READONLY_PROPERTY(process, "pid", Integer::New(env->isolate(), getpid()));
READONLY_PROPERTY(process, "features", GetFeatures(env));
process->SetAccessor(env->need_imm_cb_string(),
NeedImmediateCallbackGetter,
NeedImmediateCallbackSetter);
// 根据初始传入参数配置process
// -e, --eval
if (eval_string) {
READONLY_PROPERTY(process,
"_eval",
String::NewFromUtf8(env->isolate(), eval_string));
}
// -p, --print
if (print_eval) {
READONLY_PROPERTY(process, "_print_eval", True(env->isolate()));
}
// -i, --interactive
if (force_repl) {
READONLY_PROPERTY(process, "_forceRepl", True(env->isolate()));
}
// --no-deprecation
if (no_deprecation) {
READONLY_PROPERTY(process, "noDeprecation", True(env->isolate()));
}
// --throw-deprecation
if (throw_deprecation) {
READONLY_PROPERTY(process, "throwDeprecation", True(env->isolate()));
}
// --trace-deprecation
if (trace_deprecation) {
READONLY_PROPERTY(process, "traceDeprecation", True(env->isolate()));
}
size_t exec_path_len = 2 * PATH_MAX;
char* exec_path = new char[exec_path_len];
Local<String> exec_path_value;
if (uv_exepath(exec_path, &exec_path_len) == 0) {
exec_path_value = String::NewFromUtf8(env->isolate(),
exec_path,
String::kNormalString,
exec_path_len);
} else {
exec_path_value = String::NewFromUtf8(env->isolate(), argv[0]);
}
process->Set(env->exec_path_string(), exec_path_value);
delete[] exec_path;
process->SetAccessor(env->debug_port_string(),
DebugPortGetter,
DebugPortSetter);
// 定义一系列process的方法
// define various internal methods
NODE_SET_METHOD(process,
"_startProfilerIdleNotifier",
StartProfilerIdleNotifier);
NODE_SET_METHOD(process,
"_stopProfilerIdleNotifier",
StopProfilerIdleNotifier);
NODE_SET_METHOD(process, "_getActiveRequests", GetActiveRequests);
NODE_SET_METHOD(process, "_getActiveHandles", GetActiveHandles);
NODE_SET_METHOD(process, "reallyExit", Exit);
NODE_SET_METHOD(process, "abort", Abort);
NODE_SET_METHOD(process, "chdir", Chdir);
NODE_SET_METHOD(process, "cwd", Cwd);
NODE_SET_METHOD(process, "umask", Umask);
#if defined(__POSIX__) && !defined(__ANDROID__)
NODE_SET_METHOD(process, "getuid", GetUid);
NODE_SET_METHOD(process, "setuid", SetUid);
NODE_SET_METHOD(process, "setgid", SetGid);
NODE_SET_METHOD(process, "getgid", GetGid);
NODE_SET_METHOD(process, "getgroups", GetGroups);
NODE_SET_METHOD(process, "setgroups", SetGroups);
NODE_SET_METHOD(process, "initgroups", InitGroups);
#endif // __POSIX__ && !defined(__ANDROID__)
NODE_SET_METHOD(process, "_kill", Kill);
NODE_SET_METHOD(process, "_debugProcess", DebugProcess);
NODE_SET_METHOD(process, "_debugPause", DebugPause);
NODE_SET_METHOD(process, "_debugEnd", DebugEnd);
NODE_SET_METHOD(process, "hrtime", Hrtime);
// process.dlopen在此绑定,用于加载编译C++ addon模块(动态链接库)
NODE_SET_METHOD(process, "dlopen", DLOpen);
NODE_SET_METHOD(process, "uptime", Uptime);
NODE_SET_METHOD(process, "memoryUsage", MemoryUsage);
// process.binding方法,用于加载C++核心模块
NODE_SET_METHOD(process, "binding", Binding);
NODE_SET_METHOD(process, "_setupAsyncListener", SetupAsyncListener);
NODE_SET_METHOD(process, "_setupNextTick", SetupNextTick);
NODE_SET_METHOD(process, "_setupDomainUse", SetupDomainUse);
// pre-set _events object for faster emit checks
process->Set(env->events_string(), Object::New(env->isolate()));
}
// ...
// SetupProcessObject之后,回到CreateEnvironment函数中,执行Load函数
Load(env);
// 源码 2836行:声明了Load函数,这个函数相当于一个C++和JavaScript环境切换的接口,
// 它加载并解释了src/node.js文件
void Load(Environment* env) {
HandleScope handle_scope(env->isolate());
// Compile, execute the src/node.js file. (Which was included as static C
// string in node_natives.h. 'natve_node' is the string containing that
// source code.)
// The node.js file returns a function 'f'
atexit(AtExit);
TryCatch try_catch;
// Disable verbose mode to stop FatalException() handler from trying
// to handle the exception. Errors this early in the start-up phase
// are not safe to ignore.
try_catch.SetVerbose(false);
// 这里开始准备转向src/node.js文件
Local<String> script_name = FIXED_ONE_BYTE_STRING(env->isolate(), "node.js");
// 获取node.js的源码字符串
Local<Value> f_value = ExecuteString(env, MainSource(env), script_name);
if (try_catch.HasCaught()) {
ReportException(env, try_catch);
exit(10);
}
assert(f_value->IsFunction());
// 将f_value字符串转换为C++函数,就是将JavaScript函数编译成C++函数
Local<Function> f = Local<Function>::Cast(f_value);
// Now we call 'f' with the 'process' variable that we've built up with
// all our bindings. Inside node.js we'll take care of assigning things to
// their places.
// We start the process this way in order to be more modular. Developers
// who do not like how 'src/node.js' setups the module system but do like
// Node's I/O bindings may want to replace 'f' with their own function.
// Add a reference to the global object
Local<Object> global = env->context()->Global();
// ...
// ...
// 注释里已经说的清清楚楚,用前面提到的process对象为参数调用这个编译后的C++函数
Local<Value> arg = env->process_object();
// 下面这段代码的意思是:将f函数作为global对象的方法调用,等价于JavaScript中的.call()
// 从这里开始,进程进入了JavaScript的作用域.
f->Call(global, 1, &arg);
}
// ...
// ...
// 最后CreateEnvironment函数返回新创建的env对象
return env;
}
// ...
// 源码 3626行:再次回到Start函数体,执行下面的代码块,启动事件循环
// This Context::Scope is here so EnableDebug() can look up the current
// environment with Environment::GetCurrentChecked().
// TODO(bnoordhuis) Reorder the debugger initialization logic so it can
// be removed.
{
Context::Scope context_scope(env->context());
bool more;
do {
more = uv_run(env->event_loop(), UV_RUN_ONCE);
if (more == false) {
EmitBeforeExit(env);
// Emit `beforeExit` if the loop became alive either after emitting
// event, or after running some callbacks.
more = uv_loop_alive(env->event_loop());
if (uv_run(env->event_loop(), UV_RUN_NOWAIT) != 0)
more = true;
}
} while (more == true);
code = EmitExit(env);
RunAtExit(env);
}
env->Dispose();
env = NULL;
}
// 如果事件循环引用计数为0,即没有活跃的watchers,就退出事件循环.进程开始善后工作.
// 例如注销事件处理函数,销毁对象/变量,释放系统资源等等.
CHECK_NE(node_isolate, NULL);
node_isolate->Dispose();
node_isolate = NULL;
V8::Dispose();
delete[] exec_argv;
exec_argv = NULL;
// 最后返回结束码,结束进程.
return code;
}ok,还记得上面的整个流程中有一处代码是调用JavaScript文件src/node.js?
f->Call(global, 1, &arg);已经说它是作为global对象的方法调用的,下面来看离我们最近的src/node.js源码:
// 为什么要将整个程序的执行分为两阶段?换句话说,为何偏偏将这部分提取出来?
// Node中可谓是处处体现模块化**,遵循Unix设计哲学,
// 这么做的目的一是为了遵循模块化设计,二是将这部分分离出来,便于JavaScript开发者"私人定制":
// 允许用低门槛的JavaScript重写默认的模块建立流程.
// 用原话说:"Developers who do not like how 'src/node.js' setups the module system but do like
// Node's I/O bindings may want to replace 'f' with their own function."
// 也就是说, 独立出来的这部分JavaScript代码并不包含低层次I/O设计,仅暴露出模块导入系统的设计
(function(process) {
// C++中的global对象编程函数的this
// 这段代码将gloabl变为可循环调用,即global.gloabl.global...
this.global = this;
// 这份源码的核心逻辑,搭建JavaScript执行环境
function startup() {
var EventEmitter = NativeModule.require('events').EventEmitter;
process.__proto__ = Object.create(EventEmitter.prototype, {
constructor: {
value: process.constructor
}
});
EventEmitter.call(process);
process.EventEmitter = EventEmitter; // process.EventEmitter is deprecated
// Setup the tracing module
NativeModule.require('tracing')._nodeInitialization(process);
// do this good and early, since it handles errors.
startup.processFatal();
startup.globalVariables();
startup.globalTimeouts();
startup.globalConsole();
startup.processAssert();
startup.processConfig();
startup.processNextTick();
startup.processStdio();
startup.processKillAndExit();
startup.processSignalHandlers();
startup.processChannel();
startup.processRawDebug();
startup.resolveArgv0();
// There are various modes that Node can run in. The most common two
// are running from a script and running the REPL - but there are a few
// others like the debugger or running --eval arguments. Here we decide
// which mode we run in.
if (NativeModule.exists('_third_party_main')) {
// 注意,如果仅仅想扩展node的功能,那么尽量别在这个地方添加你的私人扩展模块
// 因为这个if里仅有一个nextTick,执行完整个代码就结束了,除非重写这部分
// To allow people to extend Node in different ways, this hook allows
// one to drop a file lib/_third_party_main.js into the build
// directory which will be executed instead of Node's normal loading.
process.nextTick(function() {
NativeModule.require('_third_party_main');
});
} else if (process.argv[1] == 'debug') {
// Start the debugger agent
var d = NativeModule.require('_debugger');
d.start();
} else if (process._eval != null) {
// User passed '-e' or '--eval' arguments to Node.
evalScript('[eval]');
} else if (process.argv[1]) {
// 这里就是正常启动模式,执行你的js文件
// make process.argv[1] into a full path
var path = NativeModule.require('path');
process.argv[1] = path.resolve(process.argv[1]);
// If this is a worker in cluster mode, start up the communication
// channel.
if (process.env.NODE_UNIQUE_ID) {
var cluster = NativeModule.require('cluster');
cluster._setupWorker();
// Make sure it's not accidentally inherited by child processes.
delete process.env.NODE_UNIQUE_ID;
}
// 为使标准的模块加载系统:require可用,
// 这里通过核心模块加载系统NativeModule.require预先加载了核心模块lib/module.js
var Module = NativeModule.require('module');
if (global.v8debug &&
process.execArgv.some(function(arg) {
return arg.match(/^--debug-brk(=[0-9]*)?$/);
})) {
// XXX Fix this terrible hack!
//
// Give the client program a few ticks to connect.
// Otherwise, there's a race condition where `node debug foo.js`
// will not be able to connect in time to catch the first
// breakpoint message on line 1.
//
// A better fix would be to somehow get a message from the
// global.v8debug object about a connection, and runMain when
// that occurs. --isaacs
var debugTimeout = +process.env.NODE_DEBUG_TIMEOUT || 50;
setTimeout(Module.runMain, debugTimeout);
} else {
// Main entry point into most programs:
Module.runMain();
}
} else {
// 最后的选择,也就是什么参数也不加的REPL交互模式
var Module = NativeModule.require('module');
// If -i or --interactive were passed, or stdin is a TTY.
if (process._forceRepl || NativeModule.require('tty').isatty(0)) {
// REPL
var opts = {
useGlobal: true,
ignoreUndefined: false
};
if (parseInt(process.env['NODE_NO_READLINE'], 10)) {
opts.terminal = false;
}
if (parseInt(process.env['NODE_DISABLE_COLORS'], 10)) {
opts.useColors = false;
}
var repl = Module.requireRepl().start(opts);
repl.on('exit', function() {
process.exit();
});
} else {
// Read all of stdin - execute it.
process.stdin.setEncoding('utf8');
var code = '';
process.stdin.on('data', function(d) {
code += d;
});
process.stdin.on('end', function() {
process._eval = code;
evalScript('[stdin]');
});
}
}
}
startup.globalVariables = function() {
// 这里有常见的全局变量定义
global.process = process;
global.global = global;
global.GLOBAL = global;
global.root = global;
global.Buffer = NativeModule.require('buffer').Buffer;
process.domain = null;
process._exiting = false;
};
startup.globalTimeouts = function() {
global.setTimeout = function() {
var t = NativeModule.require('timers');
return t.setTimeout.apply(this, arguments);
};
global.setInterval = function() {
var t = NativeModule.require('timers');
return t.setInterval.apply(this, arguments);
};
global.clearTimeout = function() {
var t = NativeModule.require('timers');
return t.clearTimeout.apply(this, arguments);
};
global.clearInterval = function() {
var t = NativeModule.require('timers');
return t.clearInterval.apply(this, arguments);
};
global.setImmediate = function() {
var t = NativeModule.require('timers');
return t.setImmediate.apply(this, arguments);
};
global.clearImmediate = function() {
var t = NativeModule.require('timers');
return t.clearImmediate.apply(this, arguments);
};
};
startup.globalConsole = function() {
global.__defineGetter__('console', function() {
return NativeModule.require('console');
});
};
startup._lazyConstants = null;
startup.lazyConstants = function() {
if (!startup._lazyConstants) {
startup._lazyConstants = process.binding('constants');
}
return startup._lazyConstants;
};
// 以下省略了一些源码,包括process.nextTick,stream处理,信号接收等初始化函数
// 还有后面提到的核心模块加载系统
// ...
// ...
最后调用startup函数执行这份源码的核心任务
startup();
});以上,就是Node进程的启动流程,接下来的主题是Node中模块(module)的加载过程
涉及源码
src/module.js
src/node.js
src/node_extensions.h
src/node_extensions.cc
模块引用是写Node程序时必有(可以这么说)的一个环节.先来看看高层模块加载系统lib/module.js的一部分源码:
// 先加载了native_module模块,
// 你会发现这个native_module并不存在于lib目录下
// 还有require函数哪里来?
var NativeModule = require('native_module');下面详细分析lib/node.js中的模块加载部分:
// 从这里开始,定义的就是Node的JavaScript核心模块加载系统了
function NativeModule(id) {
this.filename = id + '.js';
this.id = id;
this.exports = {};
this.loaded = false;
}
// 将所有位于lib目录下的js核心模块源代码加载到字符串数组里
// 注意此时这些模块并没有经过编译
NativeModule._source = process.binding('natives');
NativeModule._cache = {};
// require函数的底层调用
NativeModule.require = function(id) {
// 这段代码解决了我们的第一个问题,
// 调用NativeModule.require('native_module')会返回NativeModule本身
if (id == 'native_module') {
return NativeModule;
}
var cached = NativeModule.getCached(id);
if (cached) {
// 如果有该模块的缓存,就直接使用缓存
return cached.exports;
}
if (!NativeModule.exists(id)) {
throw new Error('No such native module ' + id);
}
// 加入已加载模块列表
process.moduleLoadList.push('NativeModule ' + id);
// 新建一个这个模块的NativeModule对象
var nativeModule = new NativeModule(id);
// 缓存这个模块
nativeModule.cache();
// 并对模块源码进行编译
nativeModule.compile();
// 最后返回这个模块内部的导出对象
return nativeModule.exports;
};
NativeModule.getCached = function(id) {
return NativeModule._cache[id];
}
NativeModule.exists = function(id) {
return NativeModule._source.hasOwnProperty(id);
}
NativeModule.getSource = function(id) {
return NativeModule._source[id];
}
NativeModule.wrap = function(script) {
return NativeModule.wrapper[0] + script + NativeModule.wrapper[1];
};
NativeModule.wrapper = [
'(function (exports, require, module, __filename, __dirname) { ',
'\n});'
];
// 模块编译
NativeModule.prototype.compile = function() {
// 先获取模块的源码字符串
var source = NativeModule.getSource(this.id);
// 这一步很重要.将源码字符串进行包装:
// 头部添加:
// "(function (exports, require, module, __filename, __dirname) { "
// 末尾添加:
// "\n});"
// 将源码包在一个函数里
// 函数的参数包含exports,require,module
// 是不是恍然大悟呢?我们的第二个问题解决了:
// 模块中看似全局变量的require函数其实是通过包装函数的参数引入的
source = NativeModule.wrap(source);
// 接下来调用runInThisContext函数解析包装后的源码字符串,返回真正的JavaScript函数
var fn = runInThisContext(source, { filename: this.filename });
// 最后调用这个函数
// 注意传入函数的前三个参数:
// exports: nativemodule.exports
// require: NativeModule.require
// module: nativemodule
// 因此每个模块之间的module被隔离开,而require函数始终是同一个
fn(this.exports, NativeModule.require, this, this.filename);
this.loaded = true;
};
NativeModule.prototype.cache = function() {
NativeModule._cache[this.id] = this;
};看完上面这段源码,我想你会清楚Node环境下module对象的那些成员的来历了.下面同样来自src/node.js,是模块编译中掉用的runInThisContext函数的声明:
var ContextifyScript = process.binding('contextify').ContextifyScript;
// 该函数是NativeModule.require的模块编译过程中调用的重要函数
// 以此函数再次回到C++领域
// 由于使用了process.binding('contextify'),我们就要到src目录下寻找相关文件
function runInThisContext(code, options) {
var script = new ContextifyScript(code, options);
return script.runInThisContext();
}我们再次回到C++的作用域,contextify内置模块的所属文件为src/node_contextify.cc:
// ...
// 哈,在源码433行找到了我们要找的函数定义
class ContextifyScript : public BaseObject {
// ...
// ...
NODE_SET_PROTOTYPE_METHOD(script_tmpl, "runInContext", RunInContext);
// 在这里runInThisContext函数被绑定到了ContextifyScript对象上
// 所以我们要找到RunInThisContext函数/方法的定义!
NODE_SET_PROTOTYPE_METHOD(script_tmpl,
"runInThisContext",
RunInThisContext);
// ...
// ...
// 继续向下,在源码501行找到了RunInThisContext这个函数
// ok,来观摩一下这个函数吧
static void RunInThisContext(const FunctionCallbackInfo<Value>& args) {
Isolate* isolate = args.GetIsolate();
HandleScope handle_scope(isolate);
// Assemble arguments
TryCatch try_catch;
uint64_t timeout = GetTimeoutArg(args, 0);
bool display_errors = GetDisplayErrorsArg(args, 0);
if (try_catch.HasCaught()) {
try_catch.ReThrow();
return;
}
// Do the eval within this context
Environment* env = Environment::GetCurrent(isolate);
// 这就是真正编译我们引入模块的函数!
EvalMachine(env, timeout, display_errors, args, try_catch);
}通过阅读前一部分src/node.js源码不难发现,在初始化环境时(startup函数最后的if分支部分)调用了:
var Module = NativeModule.require('module');也就是说在你的JavaScript代码执行之前,就已经存在了经过编译之后的module模块.
已经分析到这一步了,但是我们的"主模块",也就是通过node app.js执行的app.js是如何加载的呢?
注意src/node.js在条件分支的普通模式最后执行了:
Module.runMain();下面我们继续解读lib/module.js的源码剩余部分:
// module.js模块导出的是Module对象
module.exports = Module;
// 再来看下Module对象的定义,源码38行:
function Module(id, parent) {
this.id = id;
this.exports = {};
this.parent = parent;
if (parent && parent.children) {
parent.children.push(this);
}
this.filename = null;
this.loaded = false;
this.children = [];
}
// Set the environ variable NODE_MODULE_CONTEXTS=1 to make node load all
// modules in their own context.
Module._contextLoad = (+process.env['NODE_MODULE_CONTEXTS'] > 0);
// 将NativeModule的两个`wrap`方法赋值给Module
Module.wrapper = NativeModule.wrapper;
Module.wrap = NativeModule.wrap;
// Module.runMain方法在源码499行定义
Module.runMain = function() {
// Load the main module--the command line argument.
// 加载process.argv[1]提供的模块,也就是你的主模块
// 在刚刚进入普通运行模式时,执行了这么一段代码:
// process.argv[1] = path.resolve(process.argv[1]);
// 因此现在的参数是经过路径解析之后的
Module._load(process.argv[1], null, true);
// Handle any nextTicks added in the first tick of the program
process._tickCallback();
};
// Module._load方法定义在源码的273行
// 由参数可知,Module.runMain方法中调用的确实就是主模块:
// 它被参数isMain标记,而runMain中传入_load的是true,
// parent参数的值为null
Module._load = function(request, parent, isMain) {
if (parent) {
debug('Module._load REQUEST ' + (request) + ' parent: ' + parent.id);
}
// 解析模块的文件名
var filename = Module._resolveFilename(request, parent);
var cachedModule = Module._cache[filename];
if (cachedModule) {
return cachedModule.exports;
}
if (NativeModule.exists(filename)) {
// REPL is a special case, because it needs the real require.
if (filename == 'repl') {
var replModule = new Module('repl');
replModule._compile(NativeModule.getSource('repl'), 'repl.js');
NativeModule._cache.repl = replModule;
return replModule.exports;
}
debug('load native module ' + request);
return NativeModule.require(filename);
}
// 新建一个该模块的module对象
var module = new Module(filename, parent);
// 如果待加载的该模块是主模块
if (isMain) {
// 设置process对象的mainProcess属性
process.mainModule = module;
// 并将主模块的id重置为"."
module.id = '.';
}
Module._cache[filename] = module;
var hadException = true;
try {
// 开始加载这个模块
module.load(filename);
hadException = false;
} finally {
if (hadException) {
delete Module._cache[filename];
}
}
// 最后返回模块内部的导出对象
return module.exports;
};
// 下面是Module.prototype.load原型中方法的定义,源码345行:
// 这个方法将给定的文件名追加合适的扩展名
Module.prototype.load = function(filename) {
debug('load ' + JSON.stringify(filename) +
' for module ' + JSON.stringify(this.id));
assert(!this.loaded);
// 设置module的文件名
this.filename = filename;
// 获取这个模块所在文件的路径
this.paths = Module._nodeModulePaths(path.dirname(filename));
// 获取文件的扩展名,如果没有的话就追加一个.js
var extension = path.extname(filename) || '.js';
// 如果文件扩展名不规范,同样将扩展名定位.js
if (!Module._extensions[extension]) extension = '.js';
// 根据不同扩展名,调用合适的方法加载/编译该模块
Module._extensions[extension](this, filename);
// 最后将该模块的loaded属性设为true
this.loaded = true;
};
// Module._extensions在源码475行定义:
// 对不同种类的模块有不同的加载方法
// Native extension for .js
Module._extensions['.js'] = function(module, filename) {
// .js文件
// 先读取,再编译
var content = fs.readFileSync(filename, 'utf8');
// 编译方式和NativeModule的编译方式基本相同
module._compile(stripBOM(content), filename);
};
// Native extension for .json
Module._extensions['.json'] = function(module, filename) {
var content = fs.readFileSync(filename, 'utf8');
try {
// .json
// 用JSON.parse解析
module.exports = JSON.parse(stripBOM(content));
} catch (err) {
err.message = filename + ': ' + err.message;
throw err;
}
};
//Native extension for .node
// C++ addon扩展模块,又process.dlopen方法加载
Module._extensions['.node'] = process.dlopen;
// 最后看下Module.prototype._compile方法的源码,第378行定义:
Module.prototype._compile = function(content, filename) {
var self = this;
// remove shebang
content = content.replace(/^\#\!.*/, '');
// 注意在module.js这个文件,
// 这里重新定义了require方法,
// 因此今后调用的require全是该方法的引用,
// 而不是NativeModule.require了!
function require(path) {
// 这个是Module.prototype.require
return self.require(path);
}
// 源码 364行
// 这里定义了普通模块中的require方法
// Loads a module at the given file path. Returns that module's
// `exports` property.
Module.prototype.require = function(path) {
assert(path, 'missing path');
assert(util.isString(path), 'path must be a string');
return Module._load(path, this);
};
...
...
// 回到Module.prototype._compile函数的作用域
require.resolve = function(request) {
return Module._resolveFilename(request, self);
};
Object.defineProperty(require, 'paths', { get: function() {
throw new Error('require.paths is removed. Use ' +
'node_modules folders, or the NODE_PATH ' +
'environment variable instead.');
}});
require.main = process.mainModule;
// Enable support to add extra extension types
require.extensions = Module._extensions;
require.registerExtension = function() {
throw new Error('require.registerExtension() removed. Use ' +
'require.extensions instead.');
};
require.cache = Module._cache;
var dirname = path.dirname(filename);
// 如果设置了环境变量NODE_MODULE_CONTEXTS=1, 各模块将在自己的上下文加载.
if (Module._contextLoad) {
// 如果加载的并非主模块,(别忘了主模块的id为".")
// 则在sandbox环境中运行代码
if (self.id !== '.') {
debug('load submodule');
// not root module
var sandbox = {};
for (var k in global) {
sandbox[k] = global[k];
}
sandbox.require = require;
sandbox.exports = self.exports;
sandbox.__filename = filename;
sandbox.__dirname = dirname;
sandbox.module = self;
sandbox.global = sandbox;
sandbox.root = root;
return runInNewContext(content, sandbox, { filename: filename });
}
// 否则就是主模块
debug('load root module');
// root module
global.require = require;
global.exports = self.exports;
global.__filename = filename;
global.__dirname = dirname;
global.module = self;
return runInThisContext(content, { filename: filename });
}
// 正常启动时, 这里包装编译普通模块, 和NativeModule的包装方法一样.
// create wrapper function
var wrapper = Module.wrap(content);
var compiledWrapper = runInThisContext(wrapper, { filename: filename });
if (global.v8debug) {
if (!resolvedArgv) {
// we enter the repl if we're not given a filename argument.
if (process.argv[1]) {
resolvedArgv = Module._resolveFilename(process.argv[1], null);
} else {
resolvedArgv = 'repl';
}
}
// Set breakpoint on module start
if (filename === resolvedArgv) {
global.v8debug.Debug.setBreakPoint(compiledWrapper, 0, 0);
}
}
// 设置模块wrapper函数的参数
var args = [self.exports, require, self, filename, dirname];
// 调用wrapper函数.
return compiledWrapper.apply(self.exports, args);
};到此为止,整个流程分析完毕,Node布置好一切并执行了程序.
前两篇Node学习笔记算是对Linux底层I/O的一个初步认识,但过后发现仍有许多不足和么棱两可之处,借着近日学习Linux系统编程学习的新知识,重新写了这篇日志。
Node最大亮点之一莫过于libuv提供的Async I/O模型了,我也曾在之前介绍过其大概实现原理——多线程模拟,同时谈到了Linux下高效的I/O事件通知机制epoll。epoll就属于这些I/O模型中的一个——I/O多路复用。
不涉及底层细节,这里仅谈Linux中各种I/O技术的差异与特点。
Linux有五大IO模型,分别是阻塞I/O、非阻塞I/O、I/O多路复用、信号驱动I/O以及异步I/O。
先说我们最关心的异步IO。用户空间的进程的IO函数(如read())执行后会立即返回,不管内核采用如何机制,再怎么折腾,都与应用进程无关了,因此可以继续执行后续代码。当内核进程监听到IO可用的事件通知后,会把附加数据从内核空间拷贝到用户空间,然后通知应用进程,应用进程有空时便调用回调函数,收集数据。这是最理想的IO方式,只可惜在Linux内核中原生支持的并不好(aio的性能不行),这也是后来Ryan编写libuv的原因之一。而Windows内核提供了完善的异步IO机制——IOCP模型,这里不作讨论。
借用Unix网络编程中的说法,我们这里将I/O请求到结束这一过程分为两部分:
我们说的阻塞不阻塞全由用户进程是否等待内核进程完成这两部分决定!
之所以说异步IO是最理想的IO模型,因为应用进程不理会这两部分,我们的应用进程完全可以做自己想做的事,然后等操作系统的数据可用信号就行了。
这个IO模型相比异步IO要多一步阻塞过程:IO可用事件的监听交由内核,但内核的工作只是到此为止,接下来,将通知应用进程“IO可用”,将底层事件“冒泡”到用户级,然后应用进程再等待内核完成数据的拷贝。这部分是要阻塞进程的。
你可能不大明白啥叫“IO多路复用”,但类比计算机网络中的多路复用技术:在单一通信线路中传输多种信号…,可能仍然不明白。不过提到select、poll以及epoll我想你会恍然大悟。
是的,select、poll、epoll就是Linux系统的IO多路复用技术。那他们多路复用表现在哪方面呢?
按照manpage上的说法,他们会监听在多个文件描述符上发生的指定I/O相关事件,然后在至少一个事件触发时可处理多个文件描述符。这不同于传统的阻塞IO模型——只能处理一个文件句柄。因此说这是IO多路复用。
IO多路复用属于同步I/O模型。因为他们一直阻塞进程直到得到数据。
那么他们在那里发生的阻塞?其实若要使用这一模型,应用进程的函数调用应该选择非阻塞调用,然后才可进入模型的作用域。和前两种模型的最初阶段相同:IO函数的调用都是非阻塞的!调用了马上返回。但接下来情况有所不同:作为代理人的IO多路复用会将本次调用相关的文件描述符纳入事件监听范畴内,阻塞应用进程,等待IO可用事件(这里具体是监听fd上注册的IO事件),一旦有感兴趣的事件发生:对于select和poll机制来讲,他们会将所有监听的文件描述符遍历一次(不管是否有没有被监听的事件在那个fd上面发生);对于epoll机制,仅仅遍历那些触发了事件的文件描述符。因此说epoll的性能比前两者要高。但是这仅仅是就海量句柄中有少数活跃句柄的情况而言,如果句柄数量不多,或者说活跃的句柄很多的情况下,epoll的性能并不能体现出来,甚至不如poll。
这个IO模型的两部分都是用户进程等待内核进程完成调用,所以说都是阻塞的,但应用很广泛。libuv在Linux平台下就基于epoll机制和线程池在用户空间模拟了异步IO,并且性能很好。
Linux提供的一种可选的I/O方式。用户空间在IO函数调用后立马返回,这的确是非阻塞调用,用户进程也的确可以继续干别的,但为了获取数据,该进程不得不轮询。单单用这种模式的话,不仅性能得不到提升,还白白浪费CPU。
最原始最直接的IO方式。用户进程发起函数调用,函数进行系统调用,陷入内核,此时用户进程将等待内核操作的完成,即进程挂起,这时用户进程并不占用CPU的。直到内核完成了所有操作(上面提到的两步重要操作),然后系统调用返回,紧接着返回用户态,IO函数调用完成返回,用户进程得到数据。
不管怎样,这几种IO模型都是Linux的重要IO方式,各有利弊,大可不必摒弃某某。物尽其用,才是正确的做法。
WebSocket协议的安全设计里规定了基于TLS/SSL的传输. 这种加密形式和HTTPS类似, 称作WSS.
在协议实现上该如何做呢? 其实这部分不是WebSocket要承担的, TLS(传输层加密)/SSL(安全套接层)很明显是在TCP之上做的一层数据加密处理, 即OSI七层模型中的会话层, 而诸如HTTP, WebSocket, FTP等协议则属于应用层, 所以安全不安全不在WebSocket本身.
高层的应用层协议能透明的创建于TLS协议之上。TLS协议在应用层协议通信之前就已经完成加密算法、通信密钥的协商以及服务器认证工作。在此之后应用层协议所传送的数据都会被加密,从而保证通信的私密性. 这正是HTTPS的实现机制.
下图清楚地描述了安全协议的架构:
+-------------------------------------------+
| WebSocket | HTTP | POP | IMAP |
+-------------------------------------------+
| SSL |
| TLS |
+-------------------------------------------+
| Network Layer |
| |
+-------------------------------------------+
为了演示这一过程, 我们利用OpenSSL提供的加密算法可以很容易给自己的服务器颁发一个自签名证书.
签名需要RSA私钥, 先用OpenSSL生成一对RSA密钥:
# 强度2048的RSA密钥
openssl genrsa -out rsa.pem 2048自签名证书:
openssl req -new -x509 -days 365 -out cert.pem借助RocketEngine实现WSS. 启动HTTPS服务器实例:
https = require 'https'
fs = require 'fs'
rocket = require 'rocket-engine'
{RocketServer} = rocket
httpServer = https.createServer
key: fs.readFileSync './rsa.pem'
cert: fs.readFileSync './cert.pem'
, (req, res) ->
# ...
rocketServer = new RocketServer httpServer
.on 'connected', (socket) -> # ...
rocket.listen httpServer, () ->
httpServer.listen 80参考文章:
web标准发展至今,浏览器能干的事越来越多了,各种新鲜技术的出现无疑扩展了客户端app的职能,比如说上一篇po提到的ArrayBuffer、Blob、URL等。这个寒假我写了一個文件拖拽上传的脚本。当时我想毕竟这是一个正经的web应用,就算是前端也一定要做到尽量无可挑剔。因此,新鲜技术终于得以利用。
我们暂且不考虑应用架构和代码风格,怎么做才能无可挑剔呢?答案就是把严格控制工作流程的每一环节:从选择文件到解析文件再到文件上传最后到善后工作。(当然,如果人家禁用JavaScript所有的工作都前功尽弃了。不过为了弥补这一不足,我们在后面会有一个小小的解决方案。)
文件的获取有两个途径:A.上传按钮选择; B.拖拽选择。这没啥可说的,只是为了方便拖放操作额外写了一个拖放事件库,代码就不贴了。
关键是文件解析。或许你要问“上传个文件给服务器,为毛在前端弄那么复杂?”,还是那句话“为了做到应用的完整与无可挑剔”。上传时我们考虑之允许指定格式的文件,如“PDF、DOC、JPEG、CAD”等等能形成人类可读文档的文件,如果文件格式不满足要求则拒绝上传。
要想检测文件类型,至少得把文件头读出来。怎么做?要是以前还真就麻烦了,可是现在web标准给出了FileReader,使用它可以将二进制的blob文件进行转化处理。还记得ArrayBuffer吗?这里我们就用他们来完成文件头的获取:
var typeVerify = function (file) {
var filereader;
var token = true;
// 创建一个FileReader
filereader = new FileReader();
filereader.onload = verify;
// 以异步方式将file转成ArrayBuffer(同步方式只有在Worker线程中才可用)
filereader.readAsArrayBuffer(file.slice(0, 4));
function verify(e) {
var buffer = e.target.result;
// 创建一个DataView对象用来按字节处理结果
var dataView = new DataView(buffer);
// false以大端次序读取2字节(true为小端次序)
var fh = dataView.getUint16(0, false);
// 如果得到的值不在fileHeader里
if (fileHeader.indexOf(fh) == -1) token = false;
return token;
}
};
OK,我们已经把过程封装到函数,用来检测来自用户输入的文件是否满足要求。
WebSocket、Ajax可供选择,鉴于长连接开销问题,选择Ajax吧。新的XMLHttpRequest 2标准中规定了用于文件上传的接口,可用于二进制文件上传以及监测文件上传进度等。
var asyncUpload = function (binfile) {
var xhr = new XMLHttpRequest();
// 注册该事件可用于获取上传进度
xhr.upload.onprogress = updateProcess;
// 上传成功
xhr.upload.onload = success;
// 上传结束(无论成败)
xhr.upload.onloadend = end;
xhr.upload.onerror = error;
// 服务器返回结果
xhr.onreadystatechange = watchState;
xhr.open('POST', '/upload');
// 设置响应类型
xhr.responseType = 'blob';
xhr.send(binfile);
};
大体的架构设计算结束了,最后一步是什么呢?
对了,我们折腾了半天,要是用户不买账,把JavaScript给禁用了或给你改了咋办???……
这个做法着实让人气愤,为了防止自己的成果功亏一亏,我考虑了这种办法:
Header,通常web浏览器最差也得通过表单实现上传,表单上传的缺点之一是没法控制请求头。那么我们就用ajax添加个特殊的请求头。不过呢,尽管是这样做,还是有很多漏洞的,仅仅能打消一下hacking的念头,如果用户真的想整整你,办法还是多的去的。
ES5自从发布到现在已经有几年了,相比ES3确实增加了不少很赞的东西。可是大部分人还没接触到它非常棒的特性,下一代标准就要发布了。我想无论如何应该在ES6出台之前,回顾一下第五代提供的优秀特性。因为ES6的乱搞很有可能将JavaScript毁的面目全非。
getter和setter在ES5中属性值value可以用两个方法getter和setter替代。由这两个方法定义的属性称作存取器属性,而只有一个简单的值的属性被称为数据属性。当查询存取器属性时,自动调用getter方法,当为该属性设置值时,则调用setter方法。
如果存取器属性同时具有setter和getter方法,则该属性可读写;如果只有getter方法,赋值操作将会无效;如果只有setter方法,那么读取属性时返回undefined。
存取器属性也是可以被继承的。
字面量格式:
var obj = {
//普通的数据属性
data_prop: value,
//存取器属性
get accessor_prop() {
console.log("invoke 'getter' prop");
return ++this.data_prop;
},
set accessor_prop(value) {
console.log("invoke 'setter' prop");
this.data_prop = value;
}
};通过Object的方法设置:
//为obj对象添加另一个只写存取器属性accessor2
Object.defineProperty(obj, "accesssor2", {
set: function (value) {
this.y = value;
}
});属性除了名称和值之外,还包括可写性、可枚举性、可配置性等特性。在ES3中所有的属性都是可写,可枚举,可配置的。然而这些特性均不可修改。
为了实现属性特性的查询和设置,ES5中定义了一个名为属性描述符的对象。对于数据属性,他的属性描述符对象包含value、writable、enumerable和configurable;而存取器属性的属性描述符对象包含get、set、enumerable和configurable。
ES5提供了Object.getOwnPropertyDescriptor方法来获得某个对象的指定属性的属性描述符,ex:
//获取对象obj的x属性的属性描述符
Object.getOwnPropertyDescriptor(obj, 'x');
/* 返回
{
get: function(){...},
set: function(value){...},
enumerable: true,
configurable: true
}
*/对于继承的属性或不存在的属性,该方法返回undefined。
正如前一个例子,可以调用Object.defineProperty或Object.defineProperties设置/增加属性的特性。
//传入要修改的对象,要修改/增加的属性名,属性描述符对象
Object.defineProperty(object, property, prop_desp);
//或批量设置属性,其中第二个参数是一个对象,包含要修改的属性及其描述符对象
Object.defineProperties(obj, {
x: {...},
y: {...},
z: {...}
});这两个方法如果违反如下规则,将会抛出错误异常。来自_权威指南_:
- 如果对象 是 不可扩展的,则可以编辑已有的自有属性,但不能给他添加新属性。
- 如果属性是不可配置的,则不能修改它的可配置性和可枚举性。
- 如果存取器属性不可配置,则不能修改其getter和setter方法,也不能将它转换为数据属性。
- 如果数据属性不可配置,则不能将它转换为存取器属性。也不能将它的可写性从false改为true,但可以从true改为false。
- 如果数据属性既不可配置又不可写,则不能修改它的值。
- 如果数据属性可配置但不可写,则可以修改它的值。
上面的列表中提到了可扩展性。对象的可扩展性用以表示是否可以给对象添加新属性。
ES5提供了查询和设置对象可扩展性的方法。一旦将对象变为不可扩展的,则不可能再转换回去了。
不过对象的可扩展性仅仅影响它本身:对于其原型中添加的属性,就算不可扩展的对象也仍然会继承他们。
Object.isExtensions,Object.preventExtensions方法可分别用来检测对象是否可扩展和转换为不可扩展。
对象上的新增特性主要就是这些,我们平常似乎不太关注上面讨论的这些问题,但是ES5偏偏增加了这些新的特性,可见其目是长远的,为开发大型app而做出规范,让开发者能够创建更接近内置原生对象的API。
关于libuv,不必做过多介绍。从Node.js到Luvit,Rust,pyuv等无不体现libuv应用之广泛。
仍然是因“How does it work”的问题促使我去github扒源码。要说现在没有libuv的文档或者参考资料吗?当然有,只不过他们都没有进一步深入介绍,每份参考资料都仅仅停留在API基本使用上,并且还不完整,就像隔着一层窗户纸一样,这难以让人不产生一探究竟的冲动啊。
我想起之前写的那份“阅读Node.js源码”,在写那篇日志前我主要阅读的是多数调用V8相关的源码,而对libuv貌似并没有提及。Node.js的入口源码node.cc中有一段展示Node中是如何使用libuv的最最核心的代码,也是事件循环的起点:
// src/node.cc
// 源码 3626行
{
Context::Scope context_scope(env->context());
bool more;
do {
// 启动event-loop
more = uv_run(env->event_loop(), UV_RUN_ONCE);
if (more == false) {
EmitBeforeExit(env);
// Emit `beforeExit` if the loop became alive either after emitting
// event, or after running some callbacks.
// 检测event-loop是否需要继续存活
more = uv_loop_alive(env->event_loop());
if (uv_run(env->event_loop(), UV_RUN_NOWAIT) != 0)
more = true;
}
} while (more == true);
code = EmitExit(env);
RunAtExit(env);
}
env->Dispose();
env = NULL;
}
CHECK_NE(node_isolate, NULL);
node_isolate->Dispose();
node_isolate = NULL;
V8::Dispose();
delete[] exec_argv;
exec_argv = NULL;
return code;
}在Node的启动中有三处调用了libuv的API,我们得去libuv的源码中找找看,那些参数代表什么。官方文档中提到uv.h包含了libuv API,所以应该从uv.h入手:
// includes/uv.h
// 源码 302行
// 这里声明了uv_run函数.注释给的很清楚,这个函数的功能是启动事件循环,同时有三种不同启动模式可供选择:
UV_RUN_DEFAULT: 默认的循环模式,将会不断重复这个循环,直到"循环引用计数器(ref)"减为0.
UV_RUN_ONCE: 在没有待处理事件时uv_run将会阻塞,但这个事件循环仅仅轮询一次新触发的事件.当没有活跃的监听器或请求,函数返回0,否则返回非0值,表示还有更多待处理事件.
UV_RUN_NOWAIT: 即使没有待处理事件也不会阻塞uv_run函数,其余和UV_RUN_ONCE相同.
/*
* This function runs the event loop. It will act differently depending on the
* specified mode:
* - UV_RUN_DEFAULT: Runs the event loop until the reference count drops to
* zero. Always returns zero.
* - UV_RUN_ONCE: Poll for new events once. Note that this function blocks if
* there are no pending events. Returns zero when done (no active handles
* or requests left), or non-zero if more events are expected (meaning you
* should run the event loop again sometime in the future).
* - UV_RUN_NOWAIT: Poll for new events once but don't block if there are no
* pending events. Returns zero when done (no active handles
* or requests left), or non-zero if more events are expected (meaning you
* should run the event loop again sometime in the future).
*/
UV_EXTERN int uv_run(uv_loop_t*, uv_run_mode mode);uv_run函数的实现在src/unix/core.c中:
// src/unix/core.c
// 源码 304行
int uv_run(uv_loop_t* loop, uv_run_mode mode) {
int timeout;
int r;
// 在进入函数时首先检查该循环是否存货,
// 言外之意:是否有活跃的监听器或请求或者是否有关闭回调函数
// 这是uv__loop_alive函数的作用
r = uv__loop_alive(loop);
if (!r)
uv__update_time(loop);
// 如果事件循环是alive的,就进入这个while循环
while (r != 0 && loop->stop_flag == 0) {
// 这里表示每次while循环都是一个Tick
// 该宏相当于注释
UV_TICK_START(loop, mode);
uv__update_time(loop);
uv__run_timers(loop);
uv__run_pending(loop);
uv__run_idle(loop);
uv__run_prepare(loop);
timeout = 0;
if ((mode & UV_RUN_NOWAIT) == 0)
timeout = uv_backend_timeout(loop);
uv__io_poll(loop, timeout);
uv__run_check(loop);
uv__run_closing_handles(loop);
if (mode == UV_RUN_ONCE) {
/* UV_RUN_ONCE implies forward progess: at least one callback must have
* been invoked when it returns. uv__io_poll() can return without doing
* I/O (meaning: no callbacks) when its timeout expires - which means we
* have pending timers that satisfy the forward progress constraint.
*
* UV_RUN_NOWAIT makes no guarantees about progress so it's omitted from
* the check.
*/
uv__update_time(loop);
uv__run_timers(loop);
}
// 一次Tick结束之前再次检查事件循环是否仍是alive的
r = uv__loop_alive(loop);
// 下面同样是个注释,表示本次Tick结束了
UV_TICK_STOP(loop, mode);
if (mode & (UV_RUN_ONCE | UV_RUN_NOWAIT))
break;
}
/* The if statement lets gcc compile it to a conditional store. Avoids
* dirtying a cache line.
*/
if (loop->stop_flag != 0)
loop->stop_flag = 0;
return r;
}上面所用的uv__loop_alive函数定义在同一文件的292行:
// src/unix/core.c
// 源码 292行
// 如何判断一个事件循环是否时是存活的?
// 这个函数简洁明了
static int uv__loop_alive(const uv_loop_t* loop) {
return uv__has_active_handles(loop) ||
uv__has_active_reqs(loop) ||
loop->closing_handles != NULL;
}uv__has_active_handles函数和uv__has_active_reqs函数的实现在src/uv-common.h中:
// src/uv-common.h
//源码 114行
// 原来这两个'函数'是两个宏定义
// 分别定义了active_reqs和active_handles的各种操作
#define uv__has_active_reqs(loop) \
(QUEUE_EMPTY(&(loop)->active_reqs) == 0)
#define uv__req_register(loop, req) \
do { \
QUEUE_INSERT_TAIL(&(loop)->active_reqs, &(req)->active_queue); \
} \
while (0)
#define uv__req_unregister(loop, req) \
do { \
assert(uv__has_active_reqs(loop)); \
QUEUE_REMOVE(&(req)->active_queue); \
} \
while (0)
#define uv__has_active_handles(loop) \
((loop)->active_handles > 0)
#define uv__active_handle_add(h) \
do { \
(h)->loop->active_handles++; \
} \
while (0)
#define uv__active_handle_rm(h) \
do { \
(h)->loop->active_handles--; \
} \
while (0)下面是循环引用计数器的部分代码:
// src/uv-common.c
// 源码 374行
void uv_ref(uv_handle_t* handle) {
uv__handle_ref(handle);
}
void uv_unref(uv_handle_t* handle) {
uv__handle_unref(handle);
}
int uv_has_ref(const uv_handle_t* handle) {
return uv__has_ref(handle);
}具体仍以宏定义形式实现的:
// src/uv-common.h
// 源码 169行
#define uv__handle_ref(h) \
do { \
if (((h)->flags & UV__HANDLE_REF) != 0) break; \
(h)->flags |= UV__HANDLE_REF; \
if (((h)->flags & UV__HANDLE_CLOSING) != 0) break; \
if (((h)->flags & UV__HANDLE_ACTIVE) != 0) uv__active_handle_add(h); \
} \
while (0)
#define uv__handle_unref(h) \
do { \
if (((h)->flags & UV__HANDLE_REF) == 0) break; \
(h)->flags &= ~UV__HANDLE_REF; \
if (((h)->flags & UV__HANDLE_CLOSING) != 0) break; \
if (((h)->flags & UV__HANDLE_ACTIVE) != 0) uv__active_handle_rm(h); \
} \
while (0)
#define uv__has_ref(h) \
(((h)->flags & UV__HANDLE_REF) != 0)用于退出事件循环的函数是这样定义的:
// src/uv-common.c
// 源码 389行
// 仅仅把事件循环的stop_flag置1
void uv_stop(uv_loop_t* loop) {
loop->stop_flag = 1;
}以上这些仅仅是libuv的一个初探,至于说能让不理解Node.js的事件循环运作原理的人大彻大悟,那是说笑了.因为在uv_run中调用的好多其他重要函数这里还没做介绍解释.
下篇日志仍会从uv_run函数开始,详细而有条理的剖析事件循环的初始化,事件触发及监视器的工作流程,事件循环的退出.
该PO为#26 续, 之前有一些重要内容没提到, 比如epoll在libuv中是如何使用的, 观察者函数定义等.
首先回顾事件循环的入口函数uv_run:
(注: libuv v0.10.x)
// src/unix/core.c: line 304
// uv_run
int uv_run(uv_loop_t* loop, uv_run_mode mode) {
int timeout;
int r;
int ran_pending;
r = uv__loop_alive(loop);
if (!r)
uv__update_time(loop);
while (r != 0 && loop->stop_flag == 0) {
// 更新当前时间
uv__update_time(loop);
// 执行到期的定时器
uv__run_timers(loop);
ran_pending = uv__run_pending(loop);
// 执行idle的回调
uv__run_idle(loop);
uv__run_prepare(loop);
timeout = 0;
if ((mode == UV_RUN_ONCE && !ran_pending) || mode == UV_RUN_DEFAULT)
timeout = uv_backend_timeout(loop);
// epoll wait & thread pool
// 执行IO的回调
uv__io_poll(loop, timeout);
// 执行check的回调
uv__run_check(loop);
uv__run_closing_handles(loop);
if (mode == UV_RUN_ONCE) {
/* UV_RUN_ONCE implies forward progress: at least one callback must have
* been invoked when it returns. uv__io_poll() can return without doing
* I/O (meaning: no callbacks) when its timeout expires - which means we
* have pending timers that satisfy the forward progress constraint.
*
* UV_RUN_NOWAIT makes no guarantees about progress so it's omitted from
* the check.
*/
uv__update_time(loop);
uv__run_timers(loop);
}
r = uv__loop_alive(loop);
if (mode == UV_RUN_ONCE || mode == UV_RUN_NOWAIT)
break;
}
/* The if statement lets gcc compile it to a conditional store. Avoids
* dirtying a cache line.
*/
if (loop->stop_flag != 0)
loop->stop_flag = 0;
return r;
}调用uv_run时需要传入一个uv_loop_t*类型的参数, 拿一个官方例子来看:
#include <stdio.h>
#include <uv.h>
int64_t counter = 0;
void wait_for_a_while(uv_idle_t* handle, int status) {
counter++;
if (counter >= 10e6)
uv_idle_stop(handle);
}
int main() {
uv_idle_t idler;
// 初始化并启动idle观察者
uv_idle_init(uv_default_loop(), &idler);
uv_idle_start(&idler, wait_for_a_while);
printf("Idling...\n");
// 通过uv_default_loop()函数获取默认事件循环
// uv_default_loop()返回一个uv_loop_t*类型对象
uv_run(uv_default_loop(), UV_RUN_DEFAULT);
return 0;
}uv_default_loop函数的实现如下:
// src/unix/loop.c: 37
// uv_default_loop
uv_loop_t* uv_default_loop(void) {
if (default_loop_ptr != NULL)
return default_loop_ptr;
// 主要是uv__loop_init函数发挥的作用
if (uv__loop_init(&default_loop_struct, /* default_loop? */ 1))
return NULL;
default_loop_ptr = &default_loop_struct;
return default_loop_ptr;
}uv__loop_int函数:
// src/unix/loop.c: 101
// uv__loop_int
static int uv__loop_init(uv_loop_t* loop, int default_loop) {
int err;
uv__signal_global_once_init();
memset(loop, 0, sizeof(*loop));
heap_init((struct heap*) &loop->timer_heap);
QUEUE_INIT(&loop->wq);
QUEUE_INIT(&loop->active_reqs);
QUEUE_INIT(&loop->idle_handles);
QUEUE_INIT(&loop->async_handles);
QUEUE_INIT(&loop->check_handles);
QUEUE_INIT(&loop->prepare_handles);
QUEUE_INIT(&loop->handle_queue);
loop->nfds = 0;
loop->watchers = NULL;
loop->nwatchers = 0;
QUEUE_INIT(&loop->pending_queue);
QUEUE_INIT(&loop->watcher_queue);
loop->closing_handles = NULL;
uv__update_time(loop);
uv__async_init(&loop->async_watcher);
loop->signal_pipefd[0] = -1;
loop->signal_pipefd[1] = -1;
loop->backend_fd = -1;
loop->emfile_fd = -1;
loop->timer_counter = 0;
loop->stop_flag = 0;
// uv__platform_loop_init函数定义在linux-core.c文件中
// 内部调用了epoll create函数创建文件描述符
// 从而将事件循环与epoll关联起来
err = uv__platform_loop_init(loop, default_loop);
if (err)
return err;
uv_signal_init(loop, &loop->child_watcher);
uv__handle_unref(&loop->child_watcher);
loop->child_watcher.flags |= UV__HANDLE_INTERNAL;
QUEUE_INIT(&loop->process_handles);
if (uv_rwlock_init(&loop->cloexec_lock))
abort();
if (uv_mutex_init(&loop->wq_mutex))
abort();
if (uv_async_init(loop, &loop->wq_async, uv__work_done))
abort();
uv__handle_unref(&loop->wq_async);
loop->wq_async.flags |= UV__HANDLE_INTERNAL;
return 0;
}// src/unix/linux-core.c: 77
// uv__platform_loop_init
int uv__platform_loop_init(uv_loop_t* loop, int default_loop) {
int fd;
// 这里调用了epoll_create
fd = uv__epoll_create1(UV__EPOLL_CLOEXEC);
/* epoll_create1() can fail either because it's not implemented (old kernel)
* or because it doesn't understand the EPOLL_CLOEXEC flag.
*/
if (fd == -1 && (errno == ENOSYS || errno == EINVAL)) {
// 这里调用了epoll_create
fd = uv__epoll_create(256);
if (fd != -1)
uv__cloexec(fd, 1);
}
loop->backend_fd = fd;
loop->inotify_fd = -1;
loop->inotify_watchers = NULL;
if (fd == -1)
return -errno;
return 0;
}src/unix/linux-syscalls.c实现了uv__epoll_*函数, 并在src/unix/linux-core.c中实现了高层封装.
int uv__epoll_create(int size) {
#if defined(__NR_epoll_create)
return syscall(__NR_epoll_create, size);
#else
return errno = ENOSYS, -1;
#endif
}
int uv__epoll_create1(int flags) {
#if defined(__NR_epoll_create1)
return syscall(__NR_epoll_create1, flags);
#else
return errno = ENOSYS, -1;
#endif
}
int uv__epoll_ctl(int epfd, int op, int fd, struct uv__epoll_event* events) {
#if defined(__NR_epoll_ctl)
return syscall(__NR_epoll_ctl, epfd, op, fd, events);
#else
return errno = ENOSYS, -1;
#endif
}
int uv__epoll_wait(int epfd,
struct uv__epoll_event* events,
int nevents,
int timeout) {
#if defined(__NR_epoll_wait)
return syscall(__NR_epoll_wait, epfd, events, nevents, timeout);
#else
return errno = ENOSYS, -1;
#endif
}
int uv__epoll_pwait(int epfd,
struct uv__epoll_event* events,
int nevents,
int timeout,
uint64_t sigmask) {
#if defined(__NR_epoll_pwait)
return syscall(__NR_epoll_pwait,
epfd,
events,
nevents,
timeout,
&sigmask,
sizeof(sigmask));
#else
return errno = ENOSYS, -1;
#endif
}linux内核头文件中定义的宏以__NR_为前缀
系统调用编号定义在: /usr/include/i386-linux-gnu/asm/unistd_32.h
cat -n unistd_32.h | grep epoll:
// =>
255 #define __NR_epoll_create 254
256 #define __NR_epoll_ctl 255
257 #define __NR_epoll_wait 256
319 #define __NR_epoll_pwait 319
329 #define __NR_epoll_create1 329由此可知, libuv中调用epoll不是通过#include<sys/epoll>, 而是通过系统调用实现的!
剩下的是一些uv_run中涉及的watchers等函数.
src/unix/core.c: 697, uv__run_pending
static int uv__run_pending(uv_loop_t* loop) {
QUEUE* q;
uv__io_t* w;
if (QUEUE_EMPTY(&loop->pending_queue))
return 0;
while (!QUEUE_EMPTY(&loop->pending_queue)) {
q = QUEUE_HEAD(&loop->pending_queue);
QUEUE_REMOVE(q);
QUEUE_INIT(q);
w = QUEUE_DATA(q, uv__io_t, pending_queue);
w->cb(loop, w, UV__POLLOUT);
}
return 1;
}src/unix/core.c: 250, uv__run_closing_handles
static void uv__run_closing_handles(uv_loop_t* loop) {
uv_handle_t* p;
uv_handle_t* q;
p = loop->closing_handles;
loop->closing_handles = NULL;
while (p) {
q = p->next_closing;
uv__finish_close(p);
p = q;
}
}src/unix/linux-core.c: 138, uv__io_poll
// 事件循环的奥秘, 大多能在这个函数里找到答案:
void uv__io_poll(uv_loop_t* loop, int timeout) {
struct uv__epoll_event events[1024];
struct uv__epoll_event* pe;
struct uv__epoll_event e;
QUEUE* q;
uv__io_t* w;
uint64_t sigmask;
uint64_t base;
uint64_t diff;
int nevents;
int count;
int nfds;
int fd;
int op;
int i;
static int no_epoll_wait;
if (loop->nfds == 0) {
assert(QUEUE_EMPTY(&loop->watcher_queue));
return;
}
while (!QUEUE_EMPTY(&loop->watcher_queue)) {
q = QUEUE_HEAD(&loop->watcher_queue);
QUEUE_REMOVE(q);
QUEUE_INIT(q);
w = QUEUE_DATA(q, uv__io_t, watcher_queue);
assert(w->pevents != 0);
assert(w->fd >= 0);
assert(w->fd < (int) loop->nwatchers);
e.events = w->pevents;
e.data = w->fd;
if (w->events == 0)
op = UV__EPOLL_CTL_ADD;
else
op = UV__EPOLL_CTL_MOD;
/* XXX Future optimization: do EPOLL_CTL_MOD lazily if we stop watching
* events, skip the syscall and squelch the events after epoll_wait().
*/
if (uv__epoll_ctl(loop->backend_fd, op, w->fd, &e)) {
if (errno != EEXIST)
abort();
assert(op == UV__EPOLL_CTL_ADD);
/* We've reactivated a file descriptor that's been watched before. */
if (uv__epoll_ctl(loop->backend_fd, UV__EPOLL_CTL_MOD, w->fd, &e))
abort();
}
w->events = w->pevents;
}
sigmask = 0;
if (loop->flags & UV_LOOP_BLOCK_SIGPROF)
sigmask |= 1 << (SIGPROF - 1);
assert(timeout >= -1);
base = loop->time;
count = 48; /* Benchmarks suggest this gives the best throughput. */
for (;;) {
if (no_epoll_wait || sigmask) {
nfds = uv__epoll_pwait(loop->backend_fd,
events,
ARRAY_SIZE(events),
timeout,
sigmask);
} else {
nfds = uv__epoll_wait(loop->backend_fd,
events,
ARRAY_SIZE(events),
timeout);
if (nfds == -1 && errno == ENOSYS) {
no_epoll_wait = 1;
continue;
}
}
/* Update loop->time unconditionally. It's tempting to skip the update when
* timeout == 0 (i.e. non-blocking poll) but there is no guarantee that the
* operating system didn't reschedule our process while in the syscall.
*/
SAVE_ERRNO(uv__update_time(loop));
if (nfds == 0) {
assert(timeout != -1);
return;
}
if (nfds == -1) {
if (errno != EINTR)
abort();
if (timeout == -1)
continue;
if (timeout == 0)
return;
/* Interrupted by a signal. Update timeout and poll again. */
goto update_timeout;
}
nevents = 0;
assert(loop->watchers != NULL);
loop->watchers[loop->nwatchers] = (void*) events;
loop->watchers[loop->nwatchers + 1] = (void*) (uintptr_t) nfds;
for (i = 0; i < nfds; i++) {
pe = events + i;
fd = pe->data;
/* Skip invalidated events, see uv__platform_invalidate_fd */
if (fd == -1)
continue;
assert(fd >= 0);
assert((unsigned) fd < loop->nwatchers);
w = loop->watchers[fd];
if (w == NULL) {
/* File descriptor that we've stopped watching, disarm it.
*
* Ignore all errors because we may be racing with another thread
* when the file descriptor is closed.
*/
uv__epoll_ctl(loop->backend_fd, UV__EPOLL_CTL_DEL, fd, pe);
continue;
}
/* Give users only events they're interested in. Prevents spurious
* callbacks when previous callback invocation in this loop has stopped
* the current watcher. Also, filters out events that users has not
* requested us to watch.
*/
pe->events &= w->pevents | UV__POLLERR | UV__POLLHUP;
/* Work around an epoll quirk where it sometimes reports just the
* EPOLLERR or EPOLLHUP event. In order to force the event loop to
* move forward, we merge in the read/write events that the watcher
* is interested in; uv__read() and uv__write() will then deal with
* the error or hangup in the usual fashion.
*
* Note to self: happens when epoll reports EPOLLIN|EPOLLHUP, the user
* reads the available data, calls uv_read_stop(), then sometime later
* calls uv_read_start() again. By then, libuv has forgotten about the
* hangup and the kernel won't report EPOLLIN again because there's
* nothing left to read. If anything, libuv is to blame here. The
* current hack is just a quick bandaid; to properly fix it, libuv
* needs to remember the error/hangup event. We should get that for
* free when we switch over to edge-triggered I/O.
*/
if (pe->events == UV__EPOLLERR || pe->events == UV__EPOLLHUP)
pe->events |= w->pevents & (UV__EPOLLIN | UV__EPOLLOUT);
if (pe->events != 0) {
w->cb(loop, w, pe->events);
nevents++;
}
}
loop->watchers[loop->nwatchers] = NULL;
loop->watchers[loop->nwatchers + 1] = NULL;
if (nevents != 0) {
if (nfds == ARRAY_SIZE(events) && --count != 0) {
/* Poll for more events but don't block this time. */
timeout = 0;
continue;
}
return;
}
if (timeout == 0)
return;
if (timeout == -1)
continue;
update_timeout:
assert(timeout > 0);
diff = loop->time - base;
if (diff >= (uint64_t) timeout)
return;
timeout -= diff;
}
}src/unix/loop-watcher.c, 定义watchers的相关操作
#define UV_LOOP_WATCHER_DEFINE(name, type) \
int uv_##name##_init(uv_loop_t* loop, uv_##name##_t* handle) { \
uv__handle_init(loop, (uv_handle_t*)handle, UV_##type); \
handle->name##_cb = NULL; \
return 0; \
} \
\
int uv_##name##_start(uv_##name##_t* handle, uv_##name##_cb cb) { \
if (uv__is_active(handle)) return 0; \
if (cb == NULL) return -EINVAL; \
QUEUE_INSERT_HEAD(&handle->loop->name##_handles, &handle->queue); \
handle->name##_cb = cb; \
uv__handle_start(handle); \
return 0; \
} \
\
int uv_##name##_stop(uv_##name##_t* handle) { \
if (!uv__is_active(handle)) return 0; \
QUEUE_REMOVE(&handle->queue); \
uv__handle_stop(handle); \
return 0; \
} \
\
void uv__run_##name(uv_loop_t* loop) { \
uv_##name##_t* h; \
QUEUE* q; \
QUEUE_FOREACH(q, &loop->name##_handles) { \
h = QUEUE_DATA(q, uv_##name##_t, queue); \
h->name##_cb(h); \
} \
} \
\
void uv__##name##_close(uv_##name##_t* handle) { \
uv_##name##_stop(handle); \
}
UV_LOOP_WATCHER_DEFINE(prepare, PREPARE)
UV_LOOP_WATCHER_DEFINE(check, CHECK)
UV_LOOP_WATCHER_DEFINE(idle, IDLE)src/queue.h: 定义了libuv中队列的操作
#ifndef QUEUE_H_
#define QUEUE_H_
typedef void *QUEUE[2];
/* Private macros. */
#define QUEUE_NEXT(q) (*(QUEUE **) &((*(q))[0]))
#define QUEUE_PREV(q) (*(QUEUE **) &((*(q))[1]))
#define QUEUE_PREV_NEXT(q) (QUEUE_NEXT(QUEUE_PREV(q)))
#define QUEUE_NEXT_PREV(q) (QUEUE_PREV(QUEUE_NEXT(q)))
/* Public macros. */
#define QUEUE_DATA(ptr, type, field) \
((type *) ((char *) (ptr) - ((char *) &((type *) 0)->field)))
#define QUEUE_FOREACH(q, h) \
for ((q) = QUEUE_NEXT(h); (q) != (h); (q) = QUEUE_NEXT(q))
#define QUEUE_EMPTY(q) \
((const QUEUE *) (q) == (const QUEUE *) QUEUE_NEXT(q))
#define QUEUE_HEAD(q) \
(QUEUE_NEXT(q))
#define QUEUE_INIT(q) \
do { \
QUEUE_NEXT(q) = (q); \
QUEUE_PREV(q) = (q); \
} \
while (0)
#define QUEUE_ADD(h, n) \
do { \
QUEUE_PREV_NEXT(h) = QUEUE_NEXT(n); \
QUEUE_NEXT_PREV(n) = QUEUE_PREV(h); \
QUEUE_PREV(h) = QUEUE_PREV(n); \
QUEUE_PREV_NEXT(h) = (h); \
} \
while (0)
#define QUEUE_SPLIT(h, q, n) \
do { \
QUEUE_PREV(n) = QUEUE_PREV(h); \
QUEUE_PREV_NEXT(n) = (n); \
QUEUE_NEXT(n) = (q); \
QUEUE_PREV(h) = QUEUE_PREV(q); \
QUEUE_PREV_NEXT(h) = (h); \
QUEUE_PREV(q) = (n); \
} \
while (0)
#define QUEUE_INSERT_HEAD(h, q) \
do { \
QUEUE_NEXT(q) = QUEUE_NEXT(h); \
QUEUE_PREV(q) = (h); \
QUEUE_NEXT_PREV(q) = (q); \
QUEUE_NEXT(h) = (q); \
} \
while (0)
#define QUEUE_INSERT_TAIL(h, q) \
do { \
QUEUE_NEXT(q) = (h); \
QUEUE_PREV(q) = QUEUE_PREV(h); \
QUEUE_PREV_NEXT(q) = (q); \
QUEUE_PREV(h) = (q); \
} \
while (0)
#define QUEUE_REMOVE(q) \
do { \
QUEUE_PREV_NEXT(q) = QUEUE_NEXT(q); \
QUEUE_NEXT_PREV(q) = QUEUE_PREV(q); \
} \
while (0)
#endif /* QUEUE_H_ */(完)
如果说ES5中“对象“的新特性让你略有失望,那么”数组“上的特性绝对能让你兴奋不已。
数组的操作应该是新增特性中最多的,总体来讲,给人的感觉有些** 函数式 *味道:大多以函数作为参数,且函数的参数一般为 元素,索引,数组本身 *。
他们能够对数组元素进行** 遍历、映射、过滤、检测、简化、搜索 **。我暂且引用一下权威指南的内容:
该方法接受一个函数作为参数,从头到尾遍历数组同时为每个元素调用这个函数。但这个方法无法在数组遍历完之前停止,方法的返回值永远为undefined。
简单说就是映射:将每个元素传递给这个函数,并在最后返回一个新的数组,函数的返回值作为新数组中的元素。
[1, 2, , 3].map(function (elem) {
return elem + 1;
});
// [2, 3, , 4]map并不会改变数组的长度,也就是说,如果原数组是个稀疏数组,经过map后仍是稀疏数组(不会操作不存在的索引)。
他返回原数组的一个子集:对于数组中某个元素,如果传入的函数返回值能转化为true,那么该元素将成为新数组中的一员。
[1, 2, 3, , 4].filter(function (elem) {
return elem;
});
// [1, 2, 3, 4]需要注意的是,forEach、map和filter方法均** 不会处理不存在的索引及其元素 **。
forEah和filter只是简单的跳过未定义索引;map同样跳过未定义索引,但最后会将未定义索引的元素原封不动映射下来。
这两个方法用于数组元素的逻辑判定,他们对数组元素应用指定的函数来进行判定,返回true和false。
every判断等价于”对于数组中所有元素“some判断等价于”对于数组中存在一个满足条件的元素“一旦确定了该返回true还是false,就会自动停止遍历数组。
[1, 2, 3, 4].every(function (elem) {
return elem > 3;
});
// false他们使用指定的函数将数组元素进行组合,生成单个值。这一操作也称为”注入“/”折叠“。这两个方法可传入两个参数,第一个是用于折叠操作的的函数,这个函数的返回值作为折叠后的值。第二个参数为可选参数,用于初始化折叠操作的值(如果未指定该参数,默认将使用数组内第一个元素作为初始值)。作为第一个参数的函数,与前几个方法中使用的函数略有差异:
function (accumulator, elem, i, arr) { }该函数的第一个参数是每次折叠后的值,开始时使用初始值填充。
reduceRight方法是按照从右向左的顺序处理数组的,与reduce处理顺序相反。
如果对一个空数组调用不带初始值参数的reduce/reduceRight方法,将会抛出类型错误异常。
高并发和大数据里面挑战无处不在, 花样层出不穷, 总能从中挖掘出新的知识,获得新的技能. 因此也成为架构师和追求程序性能的黑客津津乐道的话题. 再加上"实时"这一前卫特性, 整个程序就更加暗流涌动,险象迭生了.
所谓险象迭生包括内存占用,核心架构,内存泄露,CPU占用和程序耗时. 大数据算法就对内存占用和程序耗时要求特别严格, 而高并发一定会挑战资源占用的极限.
今年10月份有一段时间我集中精力处理Bitcoin Address的提取与更新问题. 提取到levledb中的数据集大概有2GB, 全都是BTC地址, 目的是方便后续基于账户地址的数据分析, 比如最简单的"统计Top 100 BTC Address", 我需要对数据集中的每条地址做更新, 这需要调用insight-api的计算函数填充空白地址的balance等等详细信息, 而这个函数内部又需要查询两个数据库, 在经过层层回调和数学计算才能得到一条地址的信息. 其实单看这个问题并不复杂. 有不错的解决方案,比如并行查询更新, 但对当前情况并不适用.
Insight内部使用的是leveldb, 分别为区块和交易各建立一个数据库, key有不同的几种, 包含各种不同的元信息的组合, 每次查询时, 首先要对key的元信息进行检索, 然后截取这个元信息或者获取对应的value. 你可能会问为什么弄得这么繁琐? 主要因为这样做能减小数据库尺寸降低硬盘空间的占用, 但这么做导致的后果就是性能打了折扣. 除此之外, leveldb本身并不支持一个进程多次打开同一实例, Insight为了解决Node.js模块调用导致的多次打开同一实例的问题, 给出了一个即巧妙又蛋疼的方案, 巧妙的是这样的确避免了多次打开,蛋疼的是给功能的扩展带来极大的麻烦. 我从提取地址到更新地址有一般时间花在这上面. 后来找到了多进程访问leveldb的模块, 然后对Insight的设计大换血... 但仍是multi-leveldb模块却带来了性能瓶颈以及更多让人崩溃的问题. 也就是说, 好的方案需要我对Insight原有的代码改头换面才行!
说了这么多, 最核心的问题是什么? 仅仅是性能? 当然不. 在写代码的过程中, 我发现对数据库的遍历会引起内存占用的不断增长, 理论上来说遍历每条数据, 内存占用应该基本不变,并且很低很低, 因为数据库设计上不应该在内存中缓存遍历过的数据. 莫非是内存泄露? 经过反复的检查和测试了代码, 我否定了内存泄露的可能. 那究竟是怎么回事, 想了很久, 推测是因为长时间的循环导致JavaScript主线程一直被占用, 因而垃圾回收机制无法发挥功效. 也就是说, 垃圾回收的速度赶不上内存申请的速度. 这种情况在我换用了MongoDB后效果更加显著...
但是内存调整到16GB后, 新的问题又出现了. leveldb的单个数据库会将数据分散到分片文件中存储, 而数据集过快的遍历导致leveldb需要不断打开新的文件分片. 这些分片有57W个, 打开的这些分片为了其他时候使用而不会关闭. 想想60多W个文件描述符啊. 出现IO Error是迟早的事了.为此我把ulimit的最大文件打开数设置了很大, 大到系统拒绝设置, 但是仍旧抵不过文件描述符疯狂的增长...
这个月初考完编译和算法, 清闲的很, 于是答应帮人做一个Demo, 顺便赚点外快. 其中一个功能是类似微信的chat. 大二曾设计过基于WebSocket的web聊天应用, 其应用逻辑处理的难点无非是身份确认, 消息提醒外加历史记录. 而穿插在这些业务逻辑之间的realTime协议已经有现成的库了. 我原计划直接上Socket.IO, 但碍于Socket.IO没法传输二进制数据, 并且使用的不太熟练, 所以我把自己写的websocket库用上去了, 这样业务层面的逻辑写起来就容易多了.(现在Socket.IO支持二进制数据了, 刚看到最新说明)
不过在大文件大传送过程中出现的bug使我重新思考了这个库的核心设计. 如果所有实时应用都像这个demo一样只是交换一些少量文本和不超过10M的图片, 那么整个世界都"real-time"起来也没问题了, 但产品环境下的realTime免不了巨大而频繁的数据交互, 一个应用底层的库是否经得起考验就要看它在极端环境下的性能(响应速度)以及对系统资源(如内存,CPU,fd,外设I/O)的占用情况.
就拿这个demo来说, 单次传输400MB左右的blob, 内存占用疯狂的上涨, 粗略的内存检测如下:
从应用启动到开始传输:

可以看到Node进程的内存占用从27MB很快蹿升到420MB, 而后:

更是达到了难以想象的1.67GB, top的实时检测也显示了这一问题, 作为JavaScript写手我的直觉告诉我一定是内存泄露:

从大上一幅图中可以看出, 当400MB的文件全部传完, 进程的内存占用居高不下, 但请注意图中最下方的log信息, 内存占用变成了700MB, 而恰恰在此时我上传了第二个文件, 大小是20MB. 随后的跟踪日志显示如下:

在20MB文件上传完毕之后, 内存占用变成了600MB并保持不变了. 又经过了几个小文件的测试, 内存占用降低到了500多MB, 这就直接否定了"内存泄露"的猜测, 因为内存泄露往往不能回收内存空间.
遇到内存占用不断提升这种情况, 你肯定在最开始想到的是文件缓存到内存中了, 因为这很正常, 如果你把所有数据都放到buffer里必然会导致内存占用量暴增并居高不下. 但注意图中的日志信息: 如果真的是内存中缓存文件导致的, 结果未免太离谱了吧. 一个400MB的文件会让内存占用从27MB增长到1.7GB?
在后续的测试中, 我注释掉了回传那部分代码(因为这部分是面临高度写压力的模块, 为了防止排除影响所以暂时关掉), 但效果仍是一样的, 这就说明了导致内存占用突变的是读模块. 这让我不得不重审源码, 一步步跟踪内存的申请情况.
这个读模块类似transform stream, 作为TCP socket的'data'事件回调函数而存在, 每次data事件事件触发, transformer都会被调用, 然后不断的从底层缓存中抽取完整的websocket frame进行解析.
若是单个frame大小超过了分片大小(默认1KB), 则分片发送. 而经过分析发现, 问题也就出现在这里. 下面是v0.3.x版本中数据接收部分出现问题的代码:
/* fslider_ws - Rainy部分源码 */
// data_recv()
// 内部读缓冲区
_buffer.r_queue = Buffer.concat([_buffer.r_queue, data]);
// the "while loop" gets and parses every entire frame remain in buffer
// 循环调用解析器
while (readable_data = wsframe.parse(_buffer.r_queue)) {
FIN = readable_data['frame']['FIN'],
Opcode = readable_data['frame']['Opcode'],
MASK = readable_data['frame']['MASK'],
Payload_len = readable_data['frame']['Payload_len'];
// if recive frame is in fragment
if (!FIN) {
// save the first fragment's Opcode
if (Opcode) _buffer.Opcode = Opcode;
// 处理分片
_buffer.f_payload_data.push(readable_data['frame']['Payload_data']);
} else {
payload_data = readable_data['frame']['Payload_data'];
// don't fragment or the last fragment
// translate raw Payload_data
switch (Opcode) {
// continue frame
// the last fragment
case 0x0:
// 最后一个分片
_buffer.f_payload_data.push(payload_data);
payload_data = Buffer.concat(_buffer.f_payload_data);
// when the whole fragment recived
// get the Opcode from _buffer
Opcode = _buffer.Opcode;
// init the fragment _buffer
_buffer.f_payload_data = [];
// system level binary data
case 0x2:
head_len = payload_data.readUInt8(0);
event = payload_data.slice(1, head_len + 1).toString();
rawdata = payload_data.slice(head_len + 1);
//client.sysEmit(event, rawdata);
break;
}
}
// the rest buffered data
// 每轮解析后余下的数据(每次解析一个frame)
_buffer.r_queue = readable_data.r_queue;
}问题就出现在我附加中文注释的地方, 下面分析内存的申请和释放情况:
每当'data'事件触发, 假设均能提取出来至少一个frame. 首先data_recv函数会concat一个新的buffer,就是原有缓存加上新的数据, 设它为buf_1.
随后进入循环阶段,wsframe.parse()函数经过解析会返回结果数据和余下的缓存, 设他们为buf_2,buf_3. 从而有buf_1 ≈ buf_2 + buf_3. 紧接着, 如果buf_2属于分片, 则把他缓存到另一个分片队列f_payload里,否则经过第二次解析, 生成一个新的rawdata.我们可以认为rawdata = buf_2
这样下来, 每轮循环会得到: 余下数据的拷贝buf_3, 新的framebuf_2, buf_2的拷贝rawdata或新的f_payload.
如果没有分片的话, 那么一次传输的内存占用就是buf2 * 3, 如果有分片, 那么每次frame的解析占用的内存将会增加buf_2 * 2 + buf_3 + f_payload, 假设一帧的大小是120KB, 剩余缓存是360KB, 那么第一次解析下来的增量就是5 * buf_2, 下一次的增量就是buf_2 * 2 + buf_2 * 2 + buf_2 * 2 = 6 * buf_2... 你可能会质疑, 每一轮buf_2不是可以被内存回收的么, 但请注意f_payload的缓存机制导致在整个帧接受完之前是不会释放的! 也就是每次分片会创建一个新的更大的缓存.我们忽略data事件触发时新申请的内存, 仅凭f_payload就足够说明问题了.
类比"等差数列的前N项和",内存的占用也是这个道理.这也就解释了为何上传一个400MB的文件内存能增长到1个多GB.
问题明晰之后, 我重构了核心代码, 移除v0.3.x版本中的缓存机制(store mode), 在v0.4.x版本中默认换做outflow mode(流失模式), 也就是仅仅触发分片事件, 并不在内部缓存他们, 这也使整个框架更简洁更灵活:
/* v0.4.x - RocketEngine */
// transformer
self.r_queue = Buffer.concat([self.r_queue, chunk]);
// the "while loop" gets and parses every entire frame remain in buffer
while (readable_data = wsframe.parse(self.r_queue)) {
FIN = readable_data['frame']['FIN'],
Opcode = readable_data['frame']['Opcode'],
MASK = readable_data['frame']['MASK'],
Payload_len = readable_data['frame']['Payload_len'];
payload_data = readable_data['frame']['Payload_data'];
// if recive frame is in fragment
if (!FIN) {
// save the first fragment's Opcode
if (Opcode) {
switch (Opcode) {
case 0x1:
type = 'text';
break;
case 0x2:
type = 'binary';
}
// 反注释这里就会开启缓存模式
//self.handleFragment(dispatch);
client.sysEmit('firstfragment', { type: type, f_data: payload_data });
}
else
client.sysEmit('fragment', payload_data);
} else {
// don't fragment or the last fragment
// translate raw Payload_data
switch (Opcode) {
// continue frame
// the last fragment
case 0x0:
client.sysEmit('lastfragment', payload_data);
break;
// system level binary data
case 0x2:
subParser.binaryParser(payload_data, dispatch);
break;
}
}
// the rest buffered data
self.r_queue = readable_data.r_queue;
}经过改进后, 测试结果如下:

仍旧是上传400MB的文件, 从开始到上传结束内存占用始终在150MB左右:

之后的多终端同时上传也能让内存控制在200MB左右, 这说明数据接收的内存占用问题得以解决.
了解Node.js的运行机理之后就有能力对其进行custom了,我们可以尝试着DIY一个node-v0.10.31.(1)
涉及源码
node.gyp: Node.js构建编译所用配置文件lib/我要custom那些东西呢? 我尚未拜读v8的API,况且C++水平略渣,因此暂且不理会deps和src/*.cc这两个目录,从最贴近现实处入手: lib/和src/node.js.
修改src/node.js最合适不过了,因为这是官方推荐的自定义Node核心功能的方法.其实还可以扩充Node的JavaScript核心模块组,我这次玩的就是这个.
我向lib目录里添加了read.i和websocket,这两个是我之前写的Node扩展模块,这次把他们跟Node核心模块整合,哈哈.
read.i用于增强Node.js的接受用户输入的能力, websocket用于扩展Node.js的应用层协议,提供websocket协议支持.
准备read.i的源码read.i.js,拷贝到lib目录下. 既然read是提供读取,我们不妨让他使用的便捷一些:
// 这里我修改了src/node.js中初始化全局变量的函数
// 将read.i模块添加到gloabl变量中
startup.globalVariables = function() {
global.process = process;
global.global = global;
global.GLOBAL = global;
global.root = global;
global.Buffer = NativeModule.require('buffer').Buffer;
process.binding('buffer').setFastBufferConstructor(global.Buffer);
process.domain = null;
process._exiting = false;
// 添加read变量
global.read = NativeModule.require('read');
};ok,编译一下
./configure
sudo make && ./node然后你惊讶的发现报错了是吧,Node根本没找到你的模块! 原因是你并没有在node.gyp中添加新的模块,下面修改以下node.gyp:
{
'variables': {
'v8_use_snapshot%': 'true',
'node_use_dtrace%': 'false',
'node_use_etw%': 'false',
'node_use_perfctr%': 'false',
'node_has_winsdk%': 'false',
'node_shared_v8%': 'false',
'node_shared_zlib%': 'false',
'node_shared_http_parser%': 'false',
'node_shared_cares%': 'false',
'node_shared_libuv%': 'false',
'node_use_openssl%': 'true',
'node_use_systemtap%': 'false',
'node_shared_openssl%': 'false',
'library_files': [
'src/node.js',
'lib/_debugger.js',
'lib/_linklist.js',
'lib/assert.js',
'lib/buffer.js',
'lib/child_process.js',
'lib/console.js',
'lib/constants.js',
'lib/crypto.js',
'lib/cluster.js',
'lib/dgram.js',
'lib/dns.js',
'lib/domain.js',
'lib/events.js',
'lib/freelist.js',
'lib/fs.js',
'lib/http.js',
'lib/https.js',
'lib/module.js',
'lib/net.js',
'lib/os.js',
'lib/path.js',
'lib/punycode.js',
'lib/querystring.js',
'lib/readline.js',
'lib/repl.js',
'lib/stream.js',
'lib/_stream_readable.js',
'lib/_stream_writable.js',
'lib/_stream_duplex.js',
'lib/_stream_transform.js',
'lib/_stream_passthrough.js',
'lib/string_decoder.js',
'lib/sys.js',
'lib/timers.js',
'lib/tls.js',
'lib/tty.js',
'lib/url.js',
'lib/util.js',
'lib/vm.js',
'lib/zlib.js',
# 这里添加新的模块路径
'lib/read.js',
],
},
....
....
}再次编译,执行./node,就能调用我们的read模块了,同时也可以直接使用,当然这个模块在REPL环境中是无效的,仅作用于普通模式.
下面添加websocket模块.过程类似,只不过我的这个模块是由多个相互依赖的文件组成.
注: 每个通过require或NativeModule.require的模块,其文件必须首先添加进node.gyp的library_files子节点下.并且在Node编译时,会将这个节点数组中所有文件均编译成独立的核心模块!
因此,如果有多个依赖的话,就一个不剩的添加到node.gyp里,经过编译之后,这些模块的名称就是它的文件名.所以不能有两个index.js,在添加时一定要注意.
然后修改依赖文件和主文件中的require,把所有require的文件路径统统改成模块的文件名(不包含扩展名). like this:
var utils = require('index');
var Client = require('client');
var datarecv_handler = require('datarecv_handler');经过编译,我们的node-v10.31.1私人定制版就新鲜出炉了.
当然,除了添加模块之外还有好多事可以做,比如修改模块加载方式,Node的运行模式等等.
所谓signaling说白了就是外带的一个消息传递通道, 像polling, long-polling, long-connection, WebSocket等都可以做到. 至于signal服务具体要传递什么格式的消息, 下面有个signaling流程抽象, 来自HTML5ROCKs:
// 用WebSocket构建signalingChannel最为直观
var signalingChannel = new SignalingChannel();
// call start() to initiate
function start() {
pc = new RTCPeerConnection(configuration);
// send any ice candidates to the other peer
pc.onicecandidate = function (evt) {
if (evt.candidate)
// 这里发送signal
signalingChannel.send(JSON.stringify({
'candidate': evt.candidate
}));
};
// let the 'negotiationneeded' event trigger offer generation
pc.onnegotiationneeded = function () {
pc.createOffer(localDescCreated, logError);
}
// once remote stream arrives, show it in the remote video element
pc.onaddstream = function (evt) {
remoteView.src = URL.createObjectURL(evt.stream);
};
// get a local stream, show it in a self-view and add it to be sent
navigator.getUserMedia({
'audio': true,
'video': true
}, function (stream) {
selfView.src = URL.createObjectURL(stream);
pc.addStream(stream);
}, logError);
}
function localDescCreated(desc) {
pc.setLocalDescription(desc, function () {
// 这里也要发送signal
signalingChannel.send(JSON.stringify({
'sdp': pc.localDescription
}));
}, logError);
}
// 收到对方发来的signal.
signalingChannel.onmessage = function (evt) {
if (!pc)
start();
var message = JSON.parse(evt.data);
if (message.sdp)
pc.setRemoteDescription(new RTCSessionDescription(message.sdp), function () {
// if we received an offer, we need to answer
if (pc.remoteDescription.type == 'offer')
pc.createAnswer(localDescCreated, logError);
}, logError);
else
pc.addIceCandidate(new RTCIceCandidate(message.candidate));
};
function logError(error) {
log(error.name + ': ' + error.message);
}STUN是为了获取位于NAT背后节点的公开可访问IP和端口而存在的. 而且:
Most WebRTC calls successfully make a connection using STUN: 86%
TURN在之前也介绍过. WebRTC传输层默认使用UDP协议来建立peer, 如果失败的话换用TCP直连, 再不行就让TURN接手, 通过外部TURN服务器转发两个节点的流量了.
这幅图说明了signaling, STUN, TURN的关系:
在构建WebRTC应用时, 为了方便可以选择公共的STUN服务器. 当然, 最好是能部署在可信任的环境下.
WebRTC允许通过浏览器建立多对peers. 如果一个网络中有数量很多的终端建立多方呼叫, 应该在链路上部署MCU设备.
多端控制器(Multipoint Control Unit (MCU))是一种用于多媒体视讯会议(Video Conference)的装置系统,主要功能是在控制多个终端间的视讯传输。
终于到实际应用了, 来看下前面说的那些流程怎么用真实代码写出来. 下面是一个最简单的连接建立过程:
浏览器对开发者暴露了一个接口RTCPeerConnection函数. 要使用WebRTC, 最先通过它:
var peer = new RTCPeerConnection(servers)
// servers是一个可选的配置对象, 表示要为peer使用的STUN/TURN服务器:
/*
{
'iceServers': [ { "urls": "stun:stun1.example.net" }, { "urls": "turn:turn.example.org", "username": "user", "credential": "myPassword" } ]
}
*/Note: 由于目前各大浏览器厂商竞争不断, 导致这个API一直没有遵循W3C规范, 比如在Chrome下需要加webkit前缀, FireFox需要moz前缀
然后连接另一个对等方.
// peer需要首先发送一个offer报文
peer.createOffer(function (desc){
// 设置本地sessionDescription
peer.setLocalDescription(desc);
signalchannel.send({sdp: peer.localDescription})
});
peer.onicecandidate = function (e) {
signalchannel.send({candidate: e.candidate});
};
signalchannel.onMessage = function (e) {
peer.setRemoteDescription(new RTCSessionDescription(JSON.parse(e.data.sdp)));
}对等方:
signalchannel.onMessage = function (e) {
// 对等方设置发送offer的远程sessionDescription
dstpeer.setRemoteDescription(new RTCSessionDescription(JSON.parse(e.data.sdp)), function () {
if (dstpeer.remoteDescription.type == 'offer')
dstpeer.createAnswer(cb);
dstpeer.addIceCandidate(new RTCIceCandidate(JSON.parse(e.data.candidate)));
});
};sessionDescription设置完毕, offer/answer报文发送并且ICE探测成功, WebRTC通信就可以真正开始了. 至于MediaStream和DataChannel等多媒体Web的内容, 等到后面再讲.
详细的API参看W3C WebRTC API
JS除了有函数式编程、事件驱动编程、命令式编程的泛式之外,更支持面向对象编程这一泛式。
谈到OOP,当然少不了“继承”这一特性。
在JavaScript中没有类的概念,这句话也是各种教程中常说但常常自相矛盾的一句。
没有类该如何继承?
这就是原型(prototype)出现的原因。JavaScript中继承的实现是通过设置原型完成的。原型是一个对象 ,同时也是每个JS对象的一个隐性的属性,也就是说在遍历对象的全部属性时不会显示这个原型。对象会自动获取原型中的属性并允许直接使用。
其实继承可以选择类式继承 或 原型继承。
对于熟悉Java/C++的人选择类式继承会感觉更容易理解。不过原型继承更容易实现。
var object = {}; //定义一个空对象
object._proto_ = { //直接为其设置原型
name: "Ran Aizen",
age: 19
};
console.log(object.name); // "Ran Aizen"
var Foo = function () {}; //构造函数
Foo.prototype = { private: fasle }; //构造函数的原型
var repo = new Foo(); //实例化为一个对象
console.log(repo.private); //false
请看以上两部分代码,第一部分是为单个对象设置了原型;第二部分是通过在构造函数中添加原型从而使实例化结果继承了原型。
这里不推荐使用_proto_ 属性,这个属性是存在于每个对象中的隐藏属性,代表了该对象的原型,如果对其进行修改不当可能会影响到constructor 的指向和 instanceof的返回结果的问题。
而prototype属性时推荐使用的,他被用来给实例化对象设置原型。
对于_proto_ 和 prototype可以这么理解:
prototype属性是构造函数内使用的,用来设置原型继承的不可枚举属性。
_proto_属性是所有对象内使用的,用来指向其原型并构成原型链的不可枚举属性。
刚才上面提到了原型链一词。他是JavaScript实现面向对象的核心中的核心,同时也是公认的最难理解的特性之一。
这里给出一段官方的解释:
继承方面,JavaScript中的每个对象都有一个内部私有的链接指向另一个对象 (或者为 null),这个对象就是原对象的原型. 这个原型也有自己的原型, 直到对象的原型为null为止. 这种一级一级的链结构就称为原型链.
Object.prototype他是原型链的最顶端,所有对象的基本属性(例如:toString()、valueOf())全部继承自Object.prototype对象,而 Object.prototype的原型—— Object.prototype.__proto__对象则是整个原型链的终点,他的指向是关键字null。(还记得对null的描述吗?)
我们先声明一个空对象:
var obj = {};
并且obj相当于:
var obj = new Object();
所以obj是一个由Object构造函数实例化的一个普通对象,那么他应该直接继承自Object.prototye对象。因此:
obj.__proto__ === Object.prototype
//返回true
再比如说:
var arr = [];
//声明一个数组
arr.__proto__ === Array.prototype
//返回true
arr.__proto__ === Object.prototype
//返回false
var func = function () {};
//声明一个函数表达式
func.__proto__ === Function.prototype
//返回true
func.__proto__ === Object.prototype
//返回false
上面我举了两个特殊对象(函数和数组)的例子。很明显间接的原型不被认可。虽然所有对象无论直接间接都继承自Object.prototype,但是对象的__proto__属性仅指它向直接继承的对象。
不知大家能否从中得出这个结论:
对象的constructor属性取决于对象的__proto__属性。
其实在运算符instanceof内部就是依据对象的__proto__属性来判断该对象是否是某个构造函数的实例。
在引擎内部,每当构造函数实例化了一个对象时,构造函数内部返回的对象的__proto__就会自动指向构造函数的prototype,从而将构造函数的原型继承下来。然后对象的constructor属性改写为指向构造函数。
我曾经为了弄懂原型链而做过一个测试,然后得出这么一个结论(别喷我。。):
undefined总结的很潦草,也没抓住本质。我们已经知道,Object.prototype是原型链的最高级,不过为什么在Function.prototype中添加的成员能被Object访问?为什么Object和Function能够直接访问各自prototype中的成员?
Object能够访问Function.prototype让我们百思不得解时,我们可能忽略了一个重要的因素:Object、Array、Date等等,还有Function,他们不仅仅是对象,还是一个函数,而函数的原型__proto__ 是来自Function.prototype的!
情况一下子明朗了~原来Object.__proto__是指向Function.protorype的。并且,Function也是一个函数,所以Function.__proto__也指向Function.prototype。
而普通对象统统继承自Object.prototype,所以Function.prototype.__proto__就指向Object.prototype。
于是,Function与Object之间的相互继承形成了一个环形的引用。
这样我们就能够解释上面提出的两个问题了:
由于Function.prototype.__proto__继承Object.prototype,来自Object.prototype的成员就能够被Function.prototype访问到;Function等构造函数继承了Function.prototype ,Function.prototype的内容(也就是Object.prototype)便能被Function等构造函数对象直接访问。
由于Object.__proto__继承了Function.prototype,所以Object可以直接调用Function.prototype的成员。并且从上面的分析可知,Function.prototype.__proto__继承了Object.prototype,所以Object不仅可以通过prototype调用Object.prototype的成员,还可以直接访问。
最近一直在忙, 闲暇之余也是东瞧西看, 涉略了不少新鲜的东西, 也无一例外都在广度而非深度. 我工的大三课程安排让生活很惬意, 今早刷了一圈全球最大的同性交友网站github, 偶遇event-stream, 将stream和functional programming结合, 充分发挥了Node stream和event driven pattern的优势和特点, 也体现了Unix中经典的设计哲学"do one thing and it well".
我喜欢这种编程方式, 这是一种符合人类原始思维的线性模式, 也就是说它属于synchronization. 并不是说我讨厌Node的asynchronous, 相反, 我觉得它(后者)更符合世界的本质(正如朴灵所言), 而事件恰巧就是连结异步空间的"虫洞", 把某一次元发生的情况直接传送到另一次元. 二者的有机结合成就了Node在I/O上的高效.
然而总是事与愿违, 纯粹异步编程并不是那么容易掌握的, 事件有可能在任意时间发生, 为了组织程序的逻辑, 你不得不在每个事件触发点上挂载庞杂的处理逻辑甚至进一步的事件监听. 能想象那些古早的黑暗年代里人们是怎么进行异步编程的吗?... 是的, 不能清晰的组织异步逻辑将使programming陷入地狱.
要同步还是要异步? 换句话说如何更好的利用事件和异步? 然而聪明的coder早已享受过诸如async, Q, promise, generator, coroutine等辅助带来的便利了. 从某种意义上讲, 这些宝贝已经解决了厄运金字塔和混乱的异步逻辑带来的痛苦: 化异步为同步. 其实Node中的pipe就是多数异步流次序控制的原型. 很多人喜爱管道设计模式, 因为这让开发者更专注于代码的核心逻辑而非前奏和尾声, 也让程序的职能划分的更加清楚.
管道连接一切, 这是美好的夙愿, 更让人兴奋的是去年已经有人开始将streaming programming作为标准编程范式代入一门新的语言了: matz的streem, 其中融入了管道, 流, 函数式编程的**. 想象一下这种代码: (取自streem example)
# unix cat
STDIN | STDOUT
# simple echo server on port 8007
tcp_server(8007) | {s ->
s | s
}
# seq(100) returns a stream of numbers from 1 to 100.
# A function object in pipeline works as a map function.
# STDOUT is an output destination.
seq(100) | {x ->
if x % 15 == 0 {
"FizzBuzz"
}
else if x % 3 == 0 {
"Fizz"
}
else if x % 5 == 0 {
"Buzz"
}
else {
x
}
} | STDOUT
换成Lisp系的函数式写法可能是这样:
(output (fizzbuzz (seq 100)))函数式编程在解决许多问题上已经很直接了, 但我觉得相比管道的写法仍偏晦涩, 类Shell pipeline的写法无疑更易懂易写.
相比Node的I/O pipeline, streem把pipeline带到整个程序而不仅仅局限在I/O上. 看着仍处于开发中的streem, Noder们可能相视一笑了, 因为Node这边蓬勃的社区里, 早已经有这方面的实现了: eventstream库, 这是一种典型的用管道控制异步流工作次序的思路.
var es = require('event-stream')
var inspect = require('util').inspect
process.stdin //connect streams together with `pipe`
.pipe(es.split()) //split stream to break on newlines
.pipe(es.map(function (data, cb) { //turn this async function into a stream
cb(null
, inspect(JSON.parse(data))) //render it nicely
}))
.pipe(process.stdout) (代码摘自eventstream第一个示例)
与streem相比, eventstream有点更偏函数式了, 不过仍然很好的诠释了streaming + functional programming的力量.
从我个人角度确实很看好pipe, 然而时刻记住误用会让你对其产生厌恶, 而厌恶将使你失去学习的机会!, 它对于coding而言也仅仅是一种design pattern, 不可能是万能药, 对不同的场景应用合适的模式才能极尽其能.
to all my friends
对最近周围的所见所闻发表一些看法。
我只想说,别当码农,也别把Geek当码农
除了会用C++/Java写非常非常牛逼的xxx管理系统,你还应该:
最后附赠《黑客与画家》中的几段话:
如果你不爱一件事,你不可能把它做得真正优秀。
坚持一丝不苟,因为那些看不见的细节累加起来,就变得可见了。
你往往受到巨大诱惑,去解决那些能够用数学公式处理的问题,而不是去解决真正重要的问题。
他们接受流行,不是因为想要与众不同,而是因为害怕与众不同
大学和实验室强迫黑客成为科学家,企业强迫黑客成为工程师。
黑客更像是创作者,而不是科学家
画家学习绘画的主要方式是动手去画。学习编程的方法,应该是通过自己写程序,从实践中学习,而不是通过大学课程。
黑客的出发点是原创,最终得到一个优美的结果;而科学家的出发点是从别人优美的结果,最终得到原创性。
如果你把一个画家的作品按照时间顺序排列,就会发现每幅画所用的技巧,都是建立在上一幅作品学到的东西之上。某幅作品如果有特别出色之处,你往往能在更早的作品上发现一个小规模的初期版本。
对于黑客来说,采取像画家这种做法很有好处:应该定期的从头开始,而不是长年累月的在一个项目上不断工作,并且试图把所有最新想法都以修订版的形式包括进去。
key words:
去中心化,自由货币体制,无金融危机、通货膨胀风险
随着BitCoins越来越受人欢迎,其应用价值变得越来越大。对BitCoins的把玩之道更加值得探索也更能发掘有趣的东西。
比如说分析一个账户的消费情况、挖掘某些账户之间千丝万缕的关联、挖矿赚币、加密与解密的研究等等等等。
在对BitCoins的了解过程中,萌生了一个想法incbrain,这个构想也是借鉴了比特币的设计哲学。
无论是想写基于BitCoins的app还是做各种数据分析,首先应该将整个网络上的区块链(blockchain)获取下来并与网络保持同步。说的简单点,就是“成为BitCoins网络的一个节点”,没错,挖矿之前也要做这些。
第一步,到BitCoins的官网下载BitCoins挖矿程序——bitcoind。它运行在各个节点上,将会开启一个长期的后台服务进程,用来与全网络的BlockChain保持同步。
Bitcoind is a program that implements the Bitcoin protocol for command line and remote procedure call (RPC) use. It is also the first Bitcoin client in the network's history.
在启动之前需要对其进行一些必要的配置,主要是一个配置文件bitcoin.conf,下面是比较重要的字段:
# 加密 JSON-RPC api 用的id和密码
rpcuser = rpcID
rpcpassword = rpc密码
# 默认情况下允许从localhost发起的RPC连接.
# 也可以通过下面的字段指定其他的host地址,可以使用通配符*
rpcallowip = 192.168.1.*
这个配置文件并不会自动生成,需要手动创建。
写好了bitcoin.conf,就可以启动比特币客户端服务进程了:
# 这里假设解压后的目录为bitcoin,系统为64位
cd ~/bitcoin/bin/64
./bitcoind
不过回车之后可能会返回一些信息并终端进程,原因是还需要选择性指定一些参数:
-conf=<file> 设置配置文件(default: bitcoin.conf)
-datadir=<dir> 指定区块存放路径
-testnet 使用测试网络
-daemon 以守护进程启动(等价于nohup &)
-loadblock=<file> 从blk000??.dat文件导入区块信息
-reindex 从当前索引处重建区块
_Note:默认情况下,bitcoind会在数据目录中寻找名为 _bitcoin.conf* 的文件。*
|操作系统| |默认数据目录| |配置文件|
------------------------------------------------------------------------
Windows %APPDATA%\Bitcoin\ (XP) C:\Documents and Settings\username\Application Data\Bitcoin\bitcoin.conf
(Vista, 7) C:\Users\username\AppData\Roaming\Bitcoin\bitcoin.conf
Linux $HOME/.bitcoin/ /home/username/.bitcoin/bitcoin.conf
Mac OSX $HOME/Library/Application Support/Bitcoin/ /Users/username/Library/Application Support/Bitcoin/bitcoin.conf
Note: 如果在testnet测试网络环境下运行bitcoind, 将会自动在数据目录下创建testnet文件夹
为了方便起见,可以将bitcoind添加到alias:
echo "alias runbtc=$HOME/bitcoind -conf=$HOME/bitcoin.conf -daemon -datadir=$HOME/block " >> .bashrcOK~,现在跑起bitcoind:
sudo runbtc [ -loadblock=$HOME/block/blocks/blk***.dat ]当终端提示success的时候说明bitcoind已经顺利启动了。
Note:关于配置文件编写以及bitcoind参数设置详见https://en.bitcoin.it/wiki/Running_Bitcoin
datadir里都是些什么呢?
文件
数据、索引与日志文件以Key-Value的形式存储于Berkeley DB中。
database 目录
包含BDB journaling文件
testnet3 目录
(如果指定参数-testnet)包含测试网络testnet中的文件
blocks 目录
[v0.8 and above] 存储区块链blockchain数据.
chainstate 目录
[v0.8 and above] leveldb数据库,存储当前所有未使用的交易输出的简洁表示,还有一些包含这些tx来源的元信息。这些数据对于验证新到来的blocks和txs来说是很重要的。理论上,它可以从block数据进行重建(-reindex bitcoind参数),但是这会花费更长的时间。
locks 目录
[v0.8 and above] Contains "undo" data(未完成的数据).
个人标识数据
[v0.8 and above] This section may be of use to you if you wish to send a friend the blockchain, avoiding them a hefty download.
其他(blocks, blocks/index, chainstate)
may be safely transferred/archived as they contain information pertaining only to the public blockchain.
RPC,(远程过程调用),一种应用层协议。
基于JSON数据交换格式的RPC是bitcoind进程与其他hosts进程进行信息交换的一种渠道。下面是一个来自官方的简易描述:
The general mechanism consists of two peers establishing a data connection. During the lifetime of a connection, peers may invoke methods provided by the other peer. To invoke a remote method, a request is sent. Unless the request is a notification it must be replied to with a response.
这个技术可以类比JSONP:客户端提供参数,包含请求的函数和参数;服务器接收并用请求参数调用请求函数,将结果返回给客户端。
当我们已经同步了网络上的BitCoins区块——Block Chain之后,就可以对这些原始数据进行“应用级别”的使用了。
作为JavaScript + Node.js发烧友,自然要用JS的方式去完成这一步了~。目前开源社区中有几个比较受欢迎的BitCoins项目,像“bitcoinjs”、“insight”等,可以借助他们的模块实现数据可读性。
他们两个的共同之处是:实时展示block chain中人类可读的交易信息。
考虑代码的质量、结构以及方便今后的修改,我们选择了insight。按照官方的usage,将项目clone下来。如果想直接使用insight就克隆insight项目,如果仅仅是需要RESTful的API,仅克隆insight-api就可以了。
首先确保Node版本 > 0.10.*
这里假设使用了insight。进入项目目录,安装包依赖,
cd insight && sudo npm install
Note:此步若出现问题,详情查看文章最后的解决方案
确保bitcoind已经正确启动。
然后可以现在testnet环境下启动insight,
npm start
报错?没关系。看看提示信息会发现,datadir没有指定。
如果你已经准备好投入使用了,那就换入livenet吧~
在启动之前,我们需要配置一下insight的环境变量和参数,
# 配置信息主要在insight-api的config目录下:
cd node_modules/insight-bitcore-api/config
# 编辑config.js文件
下面是一个完整的config.js:
'use strict';
var path = require('path'),
rootPath = path.normalize(__dirname + '/..'),
env,
db,
port,
b_port,
p2p_port;
if (process.env.INSIGHT_NETWORK === 'livenet') {
env = 'livenet';
db = rootPath + '/db';
port = '3000';
b_port = '8332';
p2p_port = '8333';
}
else {
env = 'testnet';
db = rootPath + '/db/testnet';
port = '3001';
b_port = '18332';
p2p_port = '18333';
}
switch(process.env.NODE_ENV) {
case 'production':
env += '';
break;
case 'test':
env += ' - test environment';
break;
default:
env += ' - development';
break;
}
var network = process.env.INSIGHT_NETWORK || 'testnet';
var dataDir = process.env.BITCOIND_DATADIR;
var isWin = /^win/.test(process.platform);
var isMac = /^darwin/.test(process.platform);
var isLinux = /^linux/.test(process.platform);
if (!dataDir) {
if (isWin) dataDir = '%APPDATA%\\Bitcoin\\';
if (isMac) dataDir = process.env.HOME + '/Library/Application Support/Bitcoin/';
if (isLinux) dataDir = process.env.HOME + '/.bitcoin/';
}
dataDir += network === 'testnet' ? 'testnet3' : '';
module.exports = {
root: rootPath,
publicPath: process.env.INSIGHT_PUBLIC_PATH || false,
appName: 'Insight ' + env,
apiPrefix: '/api',
port: port,
leveldb: db,
bitcoind: {
protocol: process.env.BITCOIND_PROTO || 'http',
user: process.env.BITCOIND_USER || 'user',
pass: process.env.BITCOIND_PASS || 'pass',
host: process.env.BITCOIND_HOST || '127.0.0.1',
port: process.env.BITCOIND_PORT || b_port,
p2pPort: process.env.BITCOIND_P2P_PORT || p2p_port,
dataDir: dataDir,
// DO NOT CHANGE THIS!
disableAgent: true
},
network: network,
disableP2pSync: false,
disableHistoricSync: false,
poolMatchFile: rootPath + '/etc/minersPoolStrings.json',
// Time to refresh the currency rate. In minutes
currencyRefresh: 10,
keys: {
segmentio: process.env.INSIGHT_SEGMENTIO_KEY
}
};其实也可以通过命令参数来启动insight,不过要是闲启动命令太麻烦,就可以改写上面的文件,
# 注释掉使用环境判断
# 保留livenet的配置:
env = 'livenet';
db = rootPath + '/db'; //leveldb的数据存放位置
port = '3000'; //insight服务进程端口号
b_port = '8332';
p2p_port = '8333';
# network改为livenet
var network = 'livenet';
# 最后在module.exports导出对象中修改
module.exports = {
root: rootPath,
publicPath: process.env.INSIGHT_PUBLIC_PATH || false,
appName: 'Insight ' + env,
apiPrefix: '/api',
port: port,
leveldb: db,
bitcoind: {
protocol: process.env.BITCOIND_PROTO || 'http',
// 这里修改为上面提到的bitcoin.conf中的rpcuser和rpcpassword
user: process.env.BITCOIND_USER || rpcuser,
pass: process.env.BITCOIND_PASS || rpcpassword,
host: process.env.BITCOIND_HOST || '127.0.0.1',
port: process.env.BITCOIND_PORT || b_port,
p2pPort: process.env.BITCOIND_P2P_PORT || p2p_port,
// 如果手动指定过,则改为真实的数据目录位置
dataDir: "xxxx/blocks",
// DO NOT CHANGE THIS!
disableAgent: true
},
network: network,
disableP2pSync: false,
disableHistoricSync: false,
poolMatchFile: rootPath + '/etc/minersPoolStrings.json',
// Time to refresh the currency rate. In minutes
currencyRefresh: 10,
keys: {
segmentio: process.env.INSIGHT_SEGMENTIO_KEY
}
};改写config.js后就可以启动啦~
npm start
各种同步信息开始滚动了~~,在浏览器里访问:localhost:3000,即可看到实时的blockchains变化情况。
这部分记录了我在以上过程中遇到的troubles以及解决方案。
通常情况下,按照上面的操作一步步进行,应该没问题。问题如果有,最可能出现在**安装包依赖#npm install#**那里。由于网络的原因,会导致包下载过程中文件损坏。这是大概是本周最蛋疼的问题没有之一。
当我第一次npm install时,下载了一小半,突然throw出来几个error,并在结尾有稀里糊涂的报了几个错,总之最后是以not ok结尾的。
error通常如下:
我一直纠结问题究竟出现在哪里。因为一是报错不在同一位置(不在同一个包下),二是几乎每次的报错类型都不同!
开始我们怀疑是我的Node版本太高或者是操作系统环境的问题,于是换了台虚拟机,结果同样报错。后来我甚至怀疑起insight包的质量问题了。
但在另外几个师兄的机子上测试却一点问题没有! 十几次的尝试后,基本上就打算放弃了。不过突然发现,问题大多数时候都是与node-gyp相关的!看来事情略有些眉目了~
好几次install时,会停在gyp:GET nodejs.org/dist/node.tar.gz这里,卡个一两天都不是问题。
经过Google和GitHub的搜索,得知node-gyp需要将一部分C/C++ addon编译成内置模块。
再看提示的错误信息“gyp configure error …… common.gypi not found …… binging.gyp not found”,也就是说在编译之前的configure阶段就出了问题。那这个common.gypi和binging.gyp又是个什么呢?
再次经过Google,排除了bingding.gyp的问题:它是动态生成的。应该不会产生这种错误。而common.gypi是Node源码中的一个文件,用于GYP项目构建过程中(v8)的配置参数设定。
莫非node-gyp会需要node源码?果不其然,仔细查看错误信息,configure error 一般发生在 “gyp: GET http://nodejs.org/dist/node源码.tar.gz” 之后!
当时还真没有考虑到这个问题,后再在GitHub一个NPM的issues上发现有人提到了gyp下载node源码时网络的错误导致后续编译过程出错。
这就很有可能是下载文件不全造成的了,可是如何定位下载的node源码的位置呢?我查看了node-gyp的几行源码,没法找啊… 问题的解决还得感谢ak——何不手动修改host来做域名重定向呢? 卧槽!这办法太妙了!既然我的机器里已经有现成的node源码,它还非要从网络上下载,那就把URL重定向到localhost不就成了:
sudo echo "127.0.0.1 nodejs.org" >> /etc/hosts然后用node写一个简单的静态资源服务器:
require('http').createServer(function(req, res){
require('fs').readFile('node-v0.10.26.tar.gz', function (err, file) {
res.setHeader('Content-Type', 'application/x-compressed-tar');
res.setHeader('Content-Disposition', 'attachment; filename="node-v0.10.26.tar.gz"');
res.writeHead(200, 'OK');
res.end(file);
});
})listen(80);在本地启动服务器,然后回到insight目录下,重新sudo npm install
这次node-gyp很快完成了node源码的下载,并开始configure & build一些之前下载的模块,终于看到了点曙光。不过插曲还可能会有的,npm install很可能会安装不全,并没有按照package.json描述中的依赖去下载所有包,手动下载没有安装全的包吧。
一切就绪,再次执行npm start,got it。
享受胜利的喜悦吧~
今天访问web页面时,查找了一个block,突然就崩了,查看一下日志,竟然是语法错误。。
insight-api的lib目录下TransactionsDB.js文件里的223行:
ret.multipleSpentAttempts.each(function(mul) {改为:
ret.multipleSpentAttempts.forEach(function(mul) {
这个问题在官方的更新中修复了~:
bitpay/insight-api@0d30356#diff-2529a889507f364f72e28b86bfda7954R222
对于函数来说,ES5并没有多大改动,主要是因为JavaScript里的函数本身就足够强大。不过这里增加了一些简单却又十分实用的内容。
arguments标示符作为函数的实参列表,在ES5版本下有了改动。
arguments[i]往往和实参互为别名,修改了二者中任意一个都会影响到另一个。而ES5移除了这一特性。
并且如果使用了"use stricts"语句(严格模式),arguments会变成保留字,也就是说不能将arguments当做变量名使用,不能给其赋值。
bind方法是一个我认为最棒的新特性之一,因为它大大增强了函数的功能。其用法很简单:
var newfunc = func.bind(obj, arg1, arg2, ...);意思是将函数func作为obj对象的方法(func的this绑定至obj),并传入预设参数arg1,arg2...,最后返回一个经过配置后的新函数newfunc。
这在函数式编程领域里被称作“Currying”(“柯里化”),也叫“惰性求值”或“部分求值”,是一种应用极广的概念。
该方法的用处很大,在实际应用中我们可用它来做函数的“预配置”、优化层层嵌套的代码结构:
function foo(s) {
var c, a;
// 这里使用了bind方法,
// 将c和a预填充到handler函数的前两个参数中
s.on('event', handler.bind(s, c, a));
}
function handler(c, a, err, arg) {
// handle arguments
arg.on('e', cb.bind(null, c, a, err, arg));
}
function cb(c, a, err, arg, arg1) {
// ...
}如果不用绑定,代码就会变成这种模样:
function foo(s) {
var c, a;
s.on('event', function handler( err, arg) {
// handle c, a, err, arg
arg.on('e', function (arg1) {
// handle arg1, err, arg
});
});
}这里看起来还算好,不过一旦嵌套和函数数量一多,代码结构就变混乱了
定义嵌套函数的原因往往是因为要使用外部作用域的变量,bind方法的这种技术允许函数不必嵌套定义,在闭包上调用bind,绑定需要的参数即可。
当然,bind并非ES5的专利。在ES3中就可以通过函数的apply方法和返回闭包来模拟这种技术。
不过经过bind返回的函数与模拟出来的bind返回值有本质上的不同:bind方法返回的函数,形参长度是原长度 - 预填充实参个数,就像预填充的参数原本不存在一样。除此之外,返回的这个函数并** 不像其它函数一样包含prototype属性 **,但如果将其作为构造函数调用,则实例化的对象将使用原始函数的prototype属性作为自己的原型__proto__。
近期在学习Bash的时候读到了输入/输出和命令行处理部分,我本以为讲的不过是I/O重定向、文件读写、输入输出命令之类的东西。事实并非如此,被我忽视的命令行处理才是文章的精华所在。虽说我以前写过不少Shell脚本,也感觉那东西很简单好学,不过读完这部分我才发现我一直忽略了一个重要问题:“Shell是如何处理你输入的命令行?”。
现在网上的Shell教程很多,但深入学习的很少,即便有也鲜为人知,在此我将这部分重要的内容加上自己的理解记录下来,方便日后查看。
当你敲入一行代码并交给Shell执行时,命令行处理就开始发挥作用了。
shell从标准输入或脚本中读取的每行称为一个管道行,它包含一个或多个由0个或多个管道字符|分割的命令。shell会对其读取的每个管道行执行以下操作,也称作命令行处理:
这个过程可分为12个阶段:
空格、制表符、换行符、;、(、)、<、>、|、&。if等控制结构起始字符串、function、{、(。则该命令为复合命令,shell将读取下一条命令,并重复这一过程。else、then、fi等或逻辑操作符,则shell给出语法错误。~位于单词头,则使用用户的主目录替换~单词$开头的表达式执行变量替换。$(string)进行命令替换$((string))算术表达式$IFS。*、?、[、]执行路径名扩展。函数 > 内置命令 > $PATH里的脚本的优先级查找第一个命令。这个过程复杂难记,我们可以挑选出容易搞混的几条,把他们的处理优先级记下来:
别名替换、大括号扩展、~扩展、变量替换、命令替换、算术替换、路径扩展、命令查找
上面个的12个步骤其实是可以被改变的,其中引号就可以忽略某些步骤。
',忽略前10个步骤,也就是把整个字符串当做一个单词,直接进行命令查找并执行。",只保留6、7、8以及11、12。命令查找顺序
shell默认的命令查找顺序是:
- 函数
- 内置命令
- 脚本
而command可以忽略别名替换和函数查找:
cd () {
command cd
}bulitin只会查找内置命令。
enable能屏蔽内置命令:
enable -n cd内置命令eval的作用就是重新执行命令行处理,表面上看起来像在程序运行时执行动态生成的字符串。eval和JavaScript中的eval一样。
一个使用eval的例子:
list="ls | more"
$list
# 一定会提示找不到那个文件,很明显,管道字符|在第六步才被解析出来,
# 结果|和more都被当成ls的参数了。
# eval这里派上了用场
eval $list
# 被解析的$list将重新进入命令行解析流程,因此会正确执行。先来说说为什么会有前两种观点。将Script标签放到哪里并不绝对,两种方式都没有错,要说错就错在乱放上。
最原始的head法是为脚本优先而生的。众所周知,放在head标签里的东西无一例外优先于body加载。 但缺点是太大的文件会增加页面的加载时间(也就是用户等待时问),这多影响人的心情啊!
因此有了在body末尾放脚本一说。对于页面内容优先的网页来说,这的确大大减少了等待时间,不过对于富客户端的Web2.0 app来说,这种选择也是种煎熬:丑陋的框框早早摆在那里,然后等着美化页面和提供交互能力的脚本慢吞吞能加载。特别是对于那些完美主义者们,如果你当真把这种页面给他们看,那就别奢望他们会用你的app了。
那该怎么办?下面就来说说第三类方法:
首先确认你的网站类型:信息资讯?社交网络?游戏?博客、首页?实用工具app、云计算服务平台(网盘、聊天室、在线翻译、云办工、项目管理协作等重量级应用)
不同目地的网站逻辑复杂度亦不同,对交互能力的要求也千差万别。拿云办工为例,它提供在线编辑文档、实时同步备份数据,外加一大堆其它功能。这是一个本地桌面应用的Web版,也就说它对交互能力的要求极高,且基本上90%的交互逻辑都在浏览器中,这就完全依赖脚本了。这种应用级网站的脚本加载异常重要,没了脚本的支持活不了。而像提供资讯那种以信息传播为目的网站却对交互能力要求不高:没了脚本我照样能跑。
所以这里我们只谈以应用为主的网站。为了满足尽快显示该有的元素,先将脚本模块化:负责页面显示的脚本按Level依次穿插到body中,或者某些小脚本必须提前加载那就干脆把它放到head里。这里不免要说网络请求的问题,如果模块太多,每个小脚本都请求一次,这样很不划算,要知道网络I/O是特耗时的。有时在脚本大小很小的时候,可以将这些小脚本合并为一个文件以减少HTTP请求的次数。最后把允许等待的脚本放到body尾。也可以利用ajax异步请求脚本字符串并用eval()执行或者用DOM API 动态创建script标签,随时请求需要的脚本。
好像挺完美。madei!?我们刚才只讨论了脚本的加载,那它们究竟何时执行?lt’s a serious question !
刚才的方法中我们提到“将脚本模块化并依次插入到各元素之间”。不过在老式浏览器中并不会产生多大改变:脚本加载后并不会马上执行,而是继续加载DOM向下完善整个文档树直到最后一个元素加载完毕。
所幸HTML5中为script标签提供了 async 和 defer 属性。
大多数现代浏览器都支持这两个标签。指定了defer属性的标签会进行异步加载:在加载脚本的同时无阻塞地加载body内的其它元素,等到之前指定了aSync属性的标签全部加载完毕后脚本开始执行。而async属性比defer更无限制:异步无阻塞加载并立那执行脚本。一旦带有该属性的标签加载完毕便立即运行,不管其它元素和脚本是否加载完。这点很像Node中的异步无阻塞模型。
OK!现在有了这两个强大的功能,就可以完美地实现我们的目地啦!
BitCoin Explorer环境配置就绪,下一步就可以利用Blocks做任何想做的了。
insight-api和bitcoinjs都使用Google出品的LevelDB作Transaction持久化。因此有必要了解一下LevelDB。
Key Words:
关键词中描述了LevelDB的主要特性。很明了,这里不再赘述。
作为一个嵌入式数据库,像SQLite和Node embed nosql database一样。没有服务进程一说,这也恰恰凸显embed database目标——轻量级。
虽说是小型的数据库,但从关键词描述中可以看出——其性能仍很强劲。Google的一个benchmarks给出了levelDB和SQLite的性能测试图表。
作为一个开源项目,levelDB自然提供了不同编程语言的Wrapper。这里有两种基本使用方式:
为了尽快了解它,可以先用用它的lib。
过程与其他项目大同小异。
git clone https://code.google.com/p/leveldb/ && cd leveldb
其Makefile将它编译为静态链接库.a,也可以选择编译为动态链接库.so,这就需要修改一下Makefile:_CTRL + F_查找:
LIBRARY = libleveldb.a
$(AR) -rs $@ $(LIBOBJECTS)
分别改为:
LIBRARY = libleveldb.so
gcc -shared -fPIC -o $@ $(LIBOBJECTS)
开始编译:
make
cp libleveldb.so /usr/local/lib/
cp -r include/leveldb /usr/local/include/
sudo ldconfig
这时就可以在C/C++ 代码中引用libleveldb了:
#include "leveldb/db.h"
Note:g++需要包含-lleveldb和-lpthread参数编译程序:
g++ -o leveldbtest leveldbtest.cc -lleveldb -lpthread
之后可以写个test练习练习什么的~ example可以参见Quick Guide或Google官方示例
自从即时Web的概念提出后,RealTime便成为了web开发者们津津乐道的话题。实时化的web应用,凭借其响应迅速、无需刷新、节省网络流量的特性,不仅让开发者们眼前一亮,更是为用户带来绝佳的网络体验。
近年来关于RealTime的实现,主要还是基于Ajax的拉取和Comet的推送。大家都知道Ajax,这是一种借助浏览器端JavaScript实现的异步无刷新请求功能:要客户端按需向服务器发出请求,并异步获取来自服务器的响应,然后按照逻辑更新当前页面的相应内容。但是这仅仅是拉取啊,这并不是真正的RealTime:缺少服务器端的自动推送!因此,我们不得不使用另一种略复杂的技术Comet,只有当这两者配合起来,这个web应用才勉强算是个RealTime应用!

不过随着HTML5草案的不断完善,越来越多的现代浏览器开始全面支持WebSocket技术了。至于WebSocket,我想大家或多或少都听说过。
这个WebSocket是一种全新的协议。它将TCP的Socket(套接字)应用在了web page上,从而使通信双方建立起一个保持在活动状态连接通道,并且属于全双工(双方同时进行双向通信)。
其实是这样的,WebSocket协议是借用HTTP协议的101 switch protocol来达到协议转换的,从HTTP协议切换成WebSocket通信协议。
再简单点来说,它就好像将Ajax和Comet技术的特点结合到了一起,只不过性能要高并且使用起来要方便的多(当然是之指在客户端方面。。)
RFC草案中已经说明,WebSocket的目的就是为了在基础上保证传输的数据量最少。
这个协议是基于Frame而非Stream的,也就是说,数据的传输不是像传统的流式读写一样按字节发送,而是采用一帧一帧的Frame,并且每个Frame都定义了严格的数据结构,因此所有的信息就在这个Frame载体中。(后面会详细介绍这个Frame)
下面我先用自然语言描述一下WebSocket的工作原理:
若要实现WebSocket协议,首先需要浏览器主动发起一个HTTP请求。
这个请求头包含“Upgrade”字段,内容为“websocket”(注:upgrade字段用于改变HTTP协议版本或换用其他协议,这里显然是换用了websocket协议),还有一个最重要的字段“Sec-WebSocket-Key”,这是一个随机的经过base64编码的字符串,像密钥一样用于服务器和客户端的握手过程。一旦服务器君接收到来自客户端的upgrade请求,便会将请求头中的“Sec-WebSocket-Key”字段提取出来,追加一个固定的“魔串”:258EAFA5-E914-47DA-95CA-C5AB0DC85B11,并进行SHA-1加密,然后再次经过base64编码生成一个新的key,作为响应头中的“Sec-WebSocket-Accept”字段的内容返回给浏览器。一旦浏览器接收到来自服务器的响应,便会解析响应中的“Sec-WebSocket-Accept”字段,与自己加密编码后的串进行匹配,一旦匹配成功,便有建立连接的可能了(因为还依赖许多其他因素)。
这是一个基本的Client请求头:(我只写了关键的几个字段)
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Key: ************==
Sec-WebSocket-Version: **
Server正确接收后,会返回一个响应头:(同样只有关键的)
Upgrade:websocket
Connnection: Upgrade
Sec-WebSocket-Accept: ******************
这表示双方握手成功了,之后就是全双工的通信。
当你看完上面一节后一定会质疑该协议的保密性和安全性,看上去任何客户端都能够很容易的向WS服务器发起请求或伪装截获数据。WebSocket协议规定在连接建立时检查Upgrade请求中的某些字段(如Origin),对于不符合要求的请求立即截断;在通信过程中,也对Frame中的控制位做了很多限制,以便禁止异常连接。
对于握手阶段的检查,这种限制仅仅是在浏览器中,对于特殊的客户端(non-browser,如编码构造正确的请求头发送连接请求),这种源模型就失效了。
(后面会介绍通信过程中的连接关闭种类与流程。)
除此之外,WebSocket也规定了加密数据传输方法,允许使用TLS/SSL对通信进行加密,类似HTTPS。默认情况下,ws协议使用80端口进行普通连接,加密的TLS连接默认使用443端口。
WebSocket是基于TCP的独立的协议。
和HTTP的唯一关联就是HTTP服务器需要发送一个“Upgrade”请求,即101 Switching Protocol到HTTP服务器,然后由服务器进行协议转换。
客户端向服务器发起握手请求的header中可能带有“Sec-WebSocket-Protocol”字段,用来指定一个特定的子协议,一旦这个字段有设置,那么服务器需要在建立连接的响应头中包含同样的字段,内容就是选择的子协议之一。
子协议的命名应该是注册过的(有一套规范)。
为了避免潜在的冲突,建议子协议的源(发起者)使用ASCII编码的域名。
例子:
一个注册过的子协议叫“chat.xxx.com”,另一个叫“chat.xxx.org”。这两个子协议都会被server同时实现,server会动态的选择使用哪个子协议(取决于客户端发送过来的值)。
扩展是用来增加ws协议一些新特性的,这里就不详细说了。
上面说的仅仅是个概述,重要的是该如何在我们的web应用中使用或者说该如何建立一个基于WebSocket的应用呢?
我直说了,客户端使用WebSocket简直易如反掌,服务端实现WebSocket真是难的一B啊!尤其是我们现在还没有学过计算机网络,对一些网络底层的(如TCP/IP协议)知识了解的太少,理解并实现WebSocket确实不太容易。所以这次我先把WebSocket用提供一部分接口的高级语言来实现。
Node.js的异步I/O模型实在是太适合这种类型的应用了,因此我选择它作为I/O编程的首选。来看下面的JavaScript代码~:
Note:以下代码仅用于阐明原理,不可用于生产环境!
var http = require('http');
var crypto = require('crypto');
var MAGIC_STRING = "258EAFA5-E914-47DA-95CA-C5AB0DC85B11";
// HTTP服务器部分
var server = http.createServer(function (req, res) {
res.end('websocket test\r\n');
});
// Upgrade请求处理
server.on('upgrade', callback);
function callback(req, socket) {
// 计算返回的key
var resKey = crypto.createHash('sha1')
.update(req.headers['sec-websocket-key'] + MAGIC_STRING)
.digest('base64');
// 构造响应头
resHeaders = ([
'HTTP/1.1 101 Switching Protocols',
'Upgrade: websocket',
'Connection: Upgrade',
'Sec-WebSocket-Accept: ' + resKey
]).concat('', '').join('\r\n');
// 添加通信数据处理
socket.on('data', function (data) {
// ...
});
// 响应给客户端
socket.write(resHeaders);
}
server.listen(3000);上面的代码是等待客户端与之握手,当有客户端发出请求时,会按照“加密-编码-返回”的流程与之建立通信通道。既然连接已建立,接下来就是双方的通信了。为了让大家明白WebSocket的全程使用,在此之前有必要提一下支持WebSocket的底层协议的实现。
协议这种东西就像某种魔法,赋予了计算机之间各种神奇的通信能力,但对用户来说却是透明的。
不过对于WebSocket协议,我们可以透过IETF的RFC规范,看到关于实现WebSocket细节的每次变更与修正。
前面已經说过了WebSocket在客户端与服务端的“Hand-Shaking”实现,所以这里讲数据传输。
WebSocket传输的数据都是以Frame(帧)的形式实现的,就像TCP/UDP协议中的报文段Segment。下面就是一个Frame:(以bit为单位表示)
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-------+-+-------------+-------------------------------+
|F|R|R|R| opcode|M| Payload len | Extended payload length |
|I|S|S|S| (4) |A| (7) | (16/64) |
|N|V|V|V| |S| | (if payload len==126/127) |
| |1|2|3| |K| | |
+-+-+-+-+-------+-+-------------+ - - - - - - - - - - - - - - - +
| Extended payload length continued, if payload len == 127 |
+ - - - - - - - - - - - - - - - +-------------------------------+
| |Masking-key, if MASK set to 1 |
+-------------------------------+-------------------------------+
| Masking-key (continued) | Payload Data |
+-------------------------------- - - - - - - - - - - - - - - - +
: Payload Data continued ... :
+ - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +
| Payload Data continued ... |
+---------------------------------------------------------------+
按照RFC中的描述:
FIN: 1 bit
表示这是一个消息的最后的一帧。第一个帧也可能是最后一个。
%x0 : 还有后续帧
%x1 : 最后一帧
RSV1、2、3: 1 bit each
除非一个扩展经过协商赋予了非零值以某种含义,否则必须为0
如果没有定义非零值,并且收到了非零的RSV,则websocket链接会失败
Opcode: 4 bit
解释说明 “Payload data” 的用途/功能
如果收到了未知的opcode,最后会断开链接
定义了以下几个opcode值:
%x0 : 代表连续的帧
%x1 : text帧
%x2 : binary帧
%x3-7 : 为非控制帧而预留的
%x8 : 关闭握手帧
%x9 : ping帧
%xA : pong帧
%xB-F : 为非控制帧而预留的
Mask: 1 bit
定义“payload data”是否被添加掩码
如果置1, “Masking-key”就会被赋值
所有从客户端发往服务器的帧都会被置1
Payload length: 7 bit | 7+16 bit | 7+64 bit
“payload data” 的长度如果在0~125 bytes范围内,它就是“payload length”,
如果是126 bytes, 紧随其后的被表示为16 bits的2 bytes无符号整型就是“payload length”,
如果是127 bytes, 紧随其后的被表示为64 bits的8 bytes无符号整型就是“payload length”
Masking-key: 0 or 4 bytes
所有从客户端发送到服务器的帧都包含一个32 bits的掩码(如果“mask bit”被设置成1),否则为0 bit。一旦掩码被设置,所有接收到的payload data都必须与该值以一种算法做异或运算来获取真实值。(见下文)
Payload data: (x+y) bytes
它是"Extension data"和"Application data"的总和,一般扩展数据为空。
Extension data: x bytes
除非扩展被定义,否则就是0
任何扩展必须指定其Extension data的长度
Application data: y bytes
占据"Extension data"之后的剩余帧的空间
注意:这些数据都是以二进制形式表示的,而非ascii编码字符串
Frame的结构已经清楚了,我们就构造一个Frame。
在构造时,我们可以把Frame分成两段:控制位和数据位。其中控制位就是Frame的前两字节,包含FIN、Opcode等与该Frame的元信息。
Note:网络中使用大端次序(Big endian)表示大于一字节的数据,称之为网络字节序。
Node.js中提供了Buffer对象,专门用来弥补JavaScript在处理字节数据上的不足,这里正好可以用它来完成这个任务:
// 控制位: FIN, Opcode, MASK, Payload_len
var preBytes = [],
payBytes = new Buffer('test websocket'),
mask = 0;
masking_key = Buffer.randomByte(4);
var dataLength = payBytes.length;
// 构建Frame的第一字节
preBytes.push((frame['FIN'] << 7) + frame['Opcode']);
// 处理不同长度的dataLength,构建Frame的第二字节(或第2~第8字节)
// 注意这里以大端字节序构建dataLength > 126的dataLenght
if (dataLength < 126) {
preBytes.push((frame['MASK'] << 7) + dataLength);
} else if (dataLength < 65536) {
preBytes.push(
(frame['MASK'] << 7) + 126,
(dataLength & 0xFF00) >> 8,
dataLength & 0xFF
);
} else {
preBytes.push(
(frame['MASK'] << 7) + 127,
0, 0, 0, 0,
(dataLength & 0xFF000000) >> 24,
(dataLength & 0xFF0000) >> 16,
(dataLength & 0xFF00) >> 8,
dataLength & 0xFF
);
}
preBytes = new Buffer(preBytes);
// 如果有掩码,就对数据进行加密,并构建之后的控制位
if (mask) {
preBytes = Buffer.concat([preBytes, masking_key]);
for (var i = 0; i < dataLength; i++)
payBytes[i] ^= masking_key[i % 4];
}
// 生成一个Frame
var frame = Buffer.concat([preBytes, payBytes]);按照这种格式,就定义好了一个帧,客户端或者服务器就可以用这个帧来互传数据了。既然数据已经接收,接下来看看如何处理这些数据。
规范里解释了Masking-key掩码的作用了:就是当mask字段的值为1时,payload-data字段的数据需要经这个掩码进行解密。
在处理数据之前,我们要清楚一件事:服务器推送到客户端的消息中,mask字段是0,也就是说Masking-key为空。这样的话,数据的解析就不涉及到掩码,直接使用就行。
但是我们前面提到过,如果消息是从客户端发送到服务器,那么mask一定是1,Masking-key一定是一个32bit的值。下面我们来看看数据是如何解析的:
当消息到达服务器后,服务器程序就开始以字节为单位逐步读取这个帧,当读取到payload-data时,首先将数据按byte依次与Masking-key中的4个byte按照如下算法做异或:
//假设我们发送的"Payload data"以变量`data`表示,字节(byte)数为len;
//masking_key为4byte的mask掩码组成的数组
//offset:跳过的字节数
for (var i = 0; i < len; i++) {
var j = i % 4;
data[offset + i] ^= masking_key[j];
}上面的JavaScript代码给出了掩码Masking-key是如何解密Payload-data的:先对i取模来获得要使用的masking-key的索引,然后用data[offset + i]与masking_key[j]做异或,从而得到真实的byte数据。
控制帧用来说明WebSocket的状态信息,用来控制分片、连接的关闭等等。所有的控制帧必须有一个小于等于125字节的payload,并且control Frames不允许被分片。Opcode为0x0(持续的帧),0x8(关闭连接),0x9(Ping帧)和0xA(Pong帧)代表控制帧。
一般Ping Frame用来对一个有超时机制的套接字keepalive或者验证对方是否有响应。Pong Frame就是对Ping的回应。
前面我们总是谈到“控制帧”和“非控制帧”,想必大家已經看出来一些门路。其实数据帧就是非控制帧。因为这个帧并不是用来提供协议连接状态信息的。数据帧由最高符号位是0的Opcode确定,现在可用的几个数据帧的Opcode是0x1(utf-8文本)、0x2(二进制数据)。
理论上来说,每个帧(Frame)的大小是没有限制的,因为payload-data在整个帧的最后。但是发送的数据有不能太大,否则 WebSocket 很可能无法高效的利用网络带宽。那如果我们想传点大数据该怎么办呢?WebSocket协议给我们提供了一个方法:分片,将原本一个大的帧拆分成数个小的帧。下面是把一个大的Frame分片的图示:
编号: 0 1 .... n-2 n-1
分片: |——|——|......|——|——|
FIN: 0 0 .... 0 1
Opcode: !0 0 .... 0 0
由图可知,第一个分片的FIN为0,Opcode为非0值(0x1或0x2),最后一个分片的FIN为1,Opcode为0。中间分片的FIN和Opcode二者均为0。
Note1:消息的分片必须由发送者按给定的顺序发送给接收者。
Note2:控制帧禁止分片
Note3:接受者不必按顺序缓存整个frame来处理
Close Frame(Opcode为0x8)。一旦一端发送/接收了一个Close Frame,就开始了Close Handshake,并且连接状态变为Closing。Closed。如果TCP连接在Close handshake完成之后关闭,就表示WebSocket连接已经clean closed(彻底关闭)了。
如果WebSocket连接并未成功建立,状态也为连接已关闭,但并不是clean closed。
正常关闭过程属于clean close,应当包含close handshake。
通常来讲,应该由服务器关闭底层TCP连接,而客户端应该等待服务器关闭连接,除非等待超时的话,那么自己关闭底层TCP连接。
服务器可以随时关闭WebSocket连接,而客户端不可以主动断开连接。
由于某种算法或规范要求指定连接失败。这时,客户端和服务器必须关闭WebSocket连接。当一端得知连接失败时,不准再处理数据,包括响应close frame。
为了防止海量客户端同时发起重连请求(reconnect),客户端应该推迟一个随机时间后重新连接,可以选择回退算法来实现,比如截断二进制指数退避算法。
这两篇blog里主要用自然语言讲了WebSocket的实现。代码的细节操作(例如:处理数据、安全处理等)并没有给出,因为核心实现原理已经阐明。
因为近期写了一个比较完整的WebSocket库RocketEngine,在编码过程中发现了好多需要注意的问题,特此加以补充和修正,增加了部分章节,改正了一些不精确的说法,同时将两篇日志合并。
如需详细学习,请戳=> RocketEngine(附详细注释与wiki)
(2014.12.28 修改补充)
第二个针对性问题,很明显考的是对传输层TCP协议的理解程度。如何做呢?可能是对自己的计网知识过于自信了,当时想都没想就说res.end(),紧接着发现自己脑残了,如果能end掉底层socket的话,"Connection: keep-alive" 还起个毛作用啊?不对。明知道不对,可是我仍然朝错误的方向去考虑了问题:我在想如何在server的"request"事件回调里处理这个逻辑,并给出了好几种方案,然而这绝壁是做无用功啊。。,面试官都笑了。
为啥?现在就来谈谈因简单而常被忽视的HTTP。
可能Web开发做久了的工程师都会产生这样一种错觉:把无连接的HTTP当成一种连接。毕竟Web接触的大都是应用层协议并且主要为HTTP协议,其他少的可怜。但是现在头脑冷静一下,HTTP怎么会和connection establish联系在一起?不是,当然不是,别忘了HTTP是一种无连接,无状态协议,它只负责HTTP报文,真正维护那个连接的是传输层的TCP协议啊。
“request”事件对应的是HTTP的request,而“connect/connection”事件才对应着TCP connection。这些概念本应该是了然于胸的,可能是所学知识碎片化导致的后果吧。
下面写了一个例子,和我一样健忘的同学打开浏览器,注意控制台。加深一下印象吧~
{createServer} = require 'http'
createServer (req, res) ->
res.end ''
# req.socket.end()
console.log "new HTTP Request"
.on "connection", () ->
console.log "new TCP connection established"
.listen 80HTTP 1.1是默认设置keep-alive的,所以控制台会得到一个"new TCP connection established"和一堆"new HTTP Request"。这说明keep-alive确实是几个对同一主机的HTTP请求共享一个TCP socket。
那么仍是最初的问题,如何做到第七层防止非法数据以及及时处理正确数据?或许这么问有一种误导作用,让你偏偏往在应用层如何做这条路想。其实这是一个很简单的问题,发现有问题当然是end掉,不过要做到胸有成竹的回答,前提是必须了解TCP的特点,特别是可靠传输,TCP提供了一种保证传输数据可靠性的机制,也就是说,就算浏览器的几个页面同时对同一个Socket写入,到另一端的这些HTTP报文也不会出现差错的。所以end掉当前HTTP Request不会影响其他请求的正确性。
作为一个变革Web2.0的主力军, WebRTC赋予了浏览器之间实时通信(Real Time Communication)的能力, 提供了比WebSocket更加丰富的展现形式: 实时媒体流. 再去看看HTML5带来的Media API, 不难得出多媒体网络的特性正在逐渐与传统的Web融合的结论. 所以现在有必要研究一下多媒体Web的载体WebRTC了.
首先, 它是做什么的? 这里引用来自WebRTC官网的一段话:
WebRTC offers web application developers the ability to write rich, realtime multimedia applications (think video chat) on the web, without requiring plugins, downloads or installs. It's purpose is to help build a strong RTC platform that works across multiple web browsers, across multiple platforms.
顺便再盗他们一张图:
这个图画的不错, 很直观地告诉我们WebRTC的宏观工作原理与技术栈的划分. 并说明一件事: WebRTC并非单一协议, 而是一种综合的技术!
只要支持WebRTC的浏览器都实现了WebRTC的底层系统. 包括:
有了这些保障, 浏览器之间就可以毫无阻碍的直接交流了.
没错. 浏览器之间确实可以点对点连接, 也确实符合P2P体系结构. 那么上面怎么提到需要STUN/TURN, ICE服务器? 答案是"为了获取端系统的IP地址以便开始P2P连接".
先来看看STUN, TURN和ICE都能做什么, 以下引用自Wikipedia
首先是STUN:
STUN(Session Traversal Utilities for NAT,NAT会话传输应用程序)是一种网络协议,它允许位于NAT(或多重NAT)后的客户端找出自己的公网地址,查出自己位于哪种类型的NAT之后以及NAT为某一个本地端口所绑定的Internet端端口。这些信息被用来在两个同时处于NAT 路由器之后的主机之间建立UDP通信。
其次TURN:
TURN(全名 Traversal Using Relay NAT),是一种资料传输协议(data-transfer protocol)。允许在TCP或UDP的连线上跨越 NAT 或防火墙。
TURN是一个client-server协议。TURN的NAT穿透方法与STUN类似,都是通过取得应用层中的公有地址达到NAT穿透。但实现TURN client的终端必须在通讯开始前与TURN server进行交互,并要求TURN server产生"relay port", 也就是relayed-transport-address。这时 TURN server会建立peer, 即远端端点(remote endpoints), 开始进行中继(relay)的动作,TURN client利用relay port将资料传送至peer, 再由peer转传到另一方的TURN client。
还有一段对STUN和TURN比较清楚的描述:
- A STUN server is used to get an external network address.
- TURN servers are used to relay traffic if direct (peer to peer) connection fails.
Every TURN server supports STUN: a TURN server is a STUN server with added relaying functionality built in.
最后是ICE:
交互式连接建立(Interactive Connectivity Establishment),一种综合性的NAT穿越的技术。
交互式连接建立是由IETF的MMUSIC工作组开发出来的一种framework,可整合各种NAT穿透技术,如STUN、TURN(Traversal Using Relay NAT,中继NAT实现的穿透)、RSIP(Realm Specific IP,特定域IP)等。该framework可以让SIP的客户端利用各种NAT穿透方式打穿远程的防火墙.
我们能从上面的引用中总结如下信息:
这说明直连是有代价的. 在进行实际通讯之前, 可能需要外部STUN等服务器的帮助.
RT, 回答是"No". 下面来看看完成一个peer的建立还要有什么保障.
WebRTC need server for clients to exchange metadata to coordinate communication.
如果了解多媒体网络, 你应该已经猜到了这一环节, 它被称做signaling(信令交换).
信令交换都做些什么?
- Session control messages used to open or close communication.
Error messages.- Media metadata such as codecs and codec settings, bandwidth and media types.
- Key data, used to establish secure connections.
- Network data, such as a host's IP address and port as seen by the outside world.
由此可见, signaling的目的和SIP协议类似, 负责会话建立与管理等控制性工作, 属于"out-of-band communication"(带外通信).
但遗憾的是, WebRTC标准中并未实现signaling, 而是把他交给了应用开发者去实现. 与其说是遗憾, 不如说是灵活, 因为这样就允许我们自己选择合适的协议或技术来完成信令交换.
different applications may prefer to use different protocols, such as the existing SIP or Jingle call signaling protocols, or something custom to the particular application.
JSEP就是完成这个目的的一个信令协议. 盗HTML5Rocks一张图, 说明了JSEP及信令交换的体系结构:
JSEP需要一对peer之间交换"offer"数据和"answer"数据, 对应呼叫发起者和被叫者. 两种报文以SDP协议描述的指定格式封装, 例如:
v=0
o=- 7614219274584779017 2 IN IP4 127.0.0.1
s=-
t=0 0
a=group:BUNDLE audio video
a=msid-semantic: WMS
m=audio 1 RTP/SAVPF 111 103 104 0 8 107 106 105 13 126
c=IN IP4 0.0.0.0
a=rtcp:1 IN IP4 0.0.0.0
a=ice-ufrag:W2TGCZw2NZHuwlnf
a=ice-pwd:xdQEccP40E+P0L5qTyzDgfmW
a=extmap:1 urn:ietf:params:rtp-hdrext:ssrc-audio-level
a=mid:audio
a=rtcp-mux
a=crypto:1 AES_CM_128_HMAC_SHA1_80 inline:9c1AHz27dZ9xPI91YNfSlI67/EMkjHHIHORiClQe
a=rtpmap:111 opus/48000/2
SDP格式的信息允许开发者在设置SessionDescription前修改的, 例如改变视频/音频编码格式.
说了这么多, 还有一个关键问题尚未解决: 对等设备是如何找到目标的呢? IP地址? alias? 其实没有明确的规定. 为了说明peer发现的手段, 这里借用SIP的peer发现流程解释一下.
如果呼叫方已经知道了对方的IP地址, 那么一切好办. 但是这个假设很不现实, 不仅因为IP地址是动态分配的, 而且对方可能有多个网络设备, 更何况如何在茫茫大海中寻找那个独一无二的IP呢? 最好有一种办法, 使用对方的"别名"就能够达到寻址的目的.
幸运的是, 这个想发是可以实现的. 在SIP中, 呼叫方可以创建一个包含对方的别名的SIP报文, 发送到SIP代理, 该代理将以一个SIP回答来响应.回答可能包含对方正在使用设备的IP或其他设备IP, 也可以是其他信息, 就像DNS服务器一样.
那么SIP代理服务器是如何做到IP地址解析的呢? 为了解决这个问题, 需要一个SIP注册器. 每个用户都有一个SIP注册器, 任何时候用户在设备上发起SIP应用时, 会给该注册器发送一个SIP注册报文, 向注册器通知其IP地址. 任何时候更换一个新的设备, 都会再次向SIP注册器发送一个新的注册报文. 如果长时间使用一个设备, 设备将周期性发送刷新报文, 以指示发送的地址仍然有效.
(signal服务器, 多播, 浏览器API将在下一篇里说明.)
单线程世界里如何处理大量并发任务而不阻塞主线程的执行在做JavaScript开发时显得尤为重要。不过这不是今天的主题。既然浏览器中常常因为滥用JavaScript的事件而导致主线程阻塞,那我们就先来看看客户端JavaScript中的线程。
setTimeout 和 setInterval是JavaScript中的两个定时器,指定一定时间过后触发某某动作,常用于JavaScript制作的动画效果中。或许你尝试过这样用:
setTimeout(function () {}, 0);
假如你想通过这种方式来实现在0ms之后执行函数,那么你会发现往往事与愿违:函数并没有立即执行。
为什么?这种方式和:
(function () {})();
有什么区别吗?
乍看似乎是一样:直接执行那个函数。不过第一段代码中的函数若想和第二个效果一样,要基于两个前提:时钟周期、代码上下文。
时钟周期:你无法改变,这是有你的机器硬件所决定的,你的函数执行的最小延时时间取决于系统时钟的最小周期,所以即便是你把setTimeOut的延时参数设为0毫秒,触发也不会是即刻的,因为他永远大于系统的时钟周期。一般计算机的最小时钟周期在4ms~15ms左右,所以就算是3ms的延时,函数也不会再3ms之后被触发,而是等到最小时钟周期到了之后。
代码上下文:这个是可以改变的,因为setTimeout的执行环境由你而定,你想让他在那里执行都可以。如果整个代码的末尾执行了setTimeout,handle函数会在最小时钟周期一过便立即执行了,但是如果setTimeOut还有后文(下面还有其他要执行的代码),则首先会将handle函数依次压入事件队列,然后继续向下执行其他代码,等到所有代码都执行完毕,再将事件队列中的事件依次出队列进入事件轮询并执行。因此你会发现:
var arr = [];
setTimeout(function () {
console.log('fired!');
}, 0);
for (var i = 0; i < 10000000; i++) {
arr[i] = new String(i);
console.log(i);
}
这段代码经过了一段时间的控制台疯狂输出从0到10000000的数值后,才打印了“fired!”。其实就算延时稍长一些(假如2ms)也没关系,一样会在超过你设定的延时之后才触发函数的。因为主线程的控制权在这个代码手里,总是先执行完所有的代码,再去理会事件队列,尽管你的延时时间已到,可你也得等在队列里直到所有代码执行完毕,因此特点,setTimeOut常被用作“前端的异步函数”的核心,我写过一个js模块:event.js,用来实现PubSub模式,就是利用了这一特性。
所以,不要幻想0ms会立刻执行代码,也不要奢望指定代码一定会在一段时间后运行!setTimeout在某些情况下的作用仅仅是将handle压入事件队列而已。
弹出框系列:alert() confirm() prompt() 会启动一个模态对话框,等待你确认。这里我们要讨论的是使用这些弹出框后究竟会对线程的执行和事件的响应有何影响。
可以做一个小测试:
setTimeout("console.log('fired!')", 1000);
alert('线程挂起!');
这段代码中,注册在1秒之后控制台打印'fired!'事件,然后alert弹出警告框。会发生什么?
alert弹出了一个'线程挂起!'警告框。等待几秒钟,然后点击确认。注意此时控制台什么都没做!随后在点击确认的一秒钟后,控制台打印出了'fired!'。
原因就是alert挂起了主线程。一旦主线程被挂起,整个程序就处于等待状态,不论是事件的触发还是代码的执行都被中断了,是彻彻底底的被打断了,并且就连计时器也被迫暂停计时,直到恢复主线程的使用权为止,余下的代码才继续执行,计时器按照时钟周期重新计时。
这也就解释了为什么即使alert对话框关闭,也要等一秒钟过后控制台才给出响应。
流(stream)是Unix中的一个古老概念. 它的出现解决了I/O上的许多问题.
流是数据源的抽象, 内部有一个缓冲区, 所有输入/输出的数据都要经过这个内部缓冲区. 最简单的讲, 他的作用就是减少内存驻留数据和速率控制.
要理解流的第一个作用, 需要清楚一点: 对于送来的数据, 我们有两种处理方式. 一种是直接送达目标(空目的地/socket/硬盘/显卡等外设), 另一种是经过某些处理(如解析器)之后再送达目标. 因此我们不会希望大量数据长久驻留在内存中.
回忆一下计算机网络里, 路由器的存储转发和直通交换概念. 所谓存储转发, 就是每经过一跳都需要等待所有分片的数据报全部接收到(也就是需要经过重组). 而无需等待其他分片的就是采用直通交换技术了. 我认为这是对stream的轮廓最形象的刻画. 流在这里就是路由器的直通交换功能.
拿Node.js中的文件读写举例.
读取文件最简单的API是fs.readFile, 他会一次性把整个文件读入内存中. 如果文件特别大, 那么内存的开销也相当可观.
Node也提供了流式读取APIfs.createReadStream.
调用之后会返回一个可读流(readable stream)而不是数据, 你可以通过这个流一点一点抽取数据而不是把他们全部读入内存. 至于目标, 可以是网络socket, 也可以是协议解析器. 这样内存中就不会有过多数据驻留.
当你准备把文件上传到网络时, 系统调用把内存中的数据copy到网卡驱动接口函数. 而在网络状况不佳的时候, 物理链路上就会发生排队, 一旦文件系统层写入一大块数据, 可能直接填满链路缓冲区, 然后丢掉多余的数据或覆盖之前的数据.
流在这种情况下就派上用场了, 将原本一整块数据分成更小的几块, 缓存到内部缓冲区里, 再向底层写入. 因而也就有了改变传输速率的功能.
于是乎, 出现了基于流而设计的管道(pipe), 能够自动调控双方数据传输速率, 使消费速率较低的消费者不至于被过快产生的数据淹没(数据丢失).
RocketEngine经过几次重构, 加深了我对流本质的理解.
先上一张图:

Node中的流分为Readable Stream和Writable Stream.
可读流对象依赖于_readableState对象, 它有几个重要的属性:
_readableState: {
highWaterMark: 16384,
buffer: [],
flowing: false,
ended: false,
endEmitted: false,
reading: false,
needReadable: false,
emittedReadable: false,
readableListening: false,
objectMode: false
}可读流有两种模式: flowing, non-flowing. 我在图中右下角直接标注了两种模式对应的事件和方法.
可读流默认处于non-flowing模式, 所以'data'事件默认是不会触发的, 因此即便不添加监听器也不会有数据流失.
而一旦调用了.resume(), 就开启了flowing模式, 这时如果不绑定data的回调函数,数据就跑掉. 当然, 可以在flowing模式中调用.pause(). 这并不会让流进入non-flowing模式, 他只是禁止data事件的触发, 并把数据缓存起来, 这样就不有丢失数据的现象出现了.
每个可读流都需要实现_read函数, 其作用是告知Node这个流从数据源获取数据的方式. push是_read的具体动作, 其调用就在_read函数里发生, 将数据从源拉取到可读流的内部缓存中. 如果_read中没有再次调用pull, 那么流在下一次就不会调用_read了.
push()中断可读流的消费, 即reading属性从true变为false.
push(null)表示再没有数据可拉取了. 它的调用会使属性.ended变为true, 意味着这个流将关闭. 但如果此时内部缓冲区中仍有尚未消费的数据, 流将等到数据被完全消费后, 触发"end"事件, 同时endEmitted属性变为true.
对于可读流的消费者, read()是公开的API,
可写流对象依赖于_writableState对象:
_writableState: {
highWaterMark: 16384,
objectMode: false,
needDrain: false,
ending: false,
ended: false,
finished: false,
writing: false,
buffer: []
}从图中可以看出, 可写流是可读流的"逆过程". 可写流需要实现_write函数, 把内部缓冲区的数据写入数据源. 给流的消费者暴露了write函数, 和_read是一个道理, 但有如下不同:
_read: 只要buffer属性缓存的数据大小严格小于highWaterMark, push的返回值就是truewrite: 只要buffer属性里面的数据超过highWaterMark, write就返回false, 且needDrain属性变为true. 一旦buffer再次清空, 便会触发"drain"事件highWaterMark=0也是有意义的阈值, 表示一旦有数据缓存write就返回false.
为何如此设计呢?
因为write在内部调用的是_write, 如果buffer中缓存了数据, 说明底层目标的写入速度比较慢, 返回false的作用就是告知上层数据源先别发数据了, 等到下面都写完("drain")后继续写.
比如TCP Socket中, 对write的说明是这样的:
Returns true if the entire data was flushed successfully to the kernel buffer. Returns false if all or part of the data was queued in user memory. 'drain' will be emitted when the buffer is again free.
而可读流就是需要把底层数据缓存到buffer中, 以便消费者消费, 但为了提醒流不要占用过多内存, push才会在缓冲大小达到highWaterMark时返回false.
这是个很有意思的问题. Node在V0.10中增加"readable"事件, 为流提供了non-flowing模式. 但并没有明确表示'readable'何时触发, 不过多数人应该清楚在readable事件回调里一定能得到期望的东西.
substack在他的"stream-handbook"里提到:
process.stdin.on('readable', function () { process.stdin.read(3); process.stdin.read(0) });
这就说明read(0)一定会再次触发标准输入流的readable事件码? 除此之外, push, _read, read都和"readable"有联系.
这个问题如何回答? 源码中清清楚楚解释了一切, SO
just go and read the fu*king source code :)
你或许考虑过这个问题. 可是我曾用一个十分粗暴地办法"解决"了这个问题: 每生成一个序列检测是否有重复, 如果有,重新生成再进入这个检测, 否则存储在hash的一个位置.
这学期春季面试时, 当和面试官谈起Yinle.me在提取码生成过程中无碰撞4位随机数如何高效生成的问题, 我才发现不经意间错过了一个值的思考的问题. 我可以把这个问题描述为: "对于Event Driven的Web Server, 如果需要处理上千上万的并发连接, 怎么高效的为每个连接分配UUID (就是在这个server生存周期内无碰撞的数)?", 我脑海中立刻闪现第二个简单粗暴的办法: 预先生成一个bitmap, 记录所有可能的值, 再由主线程顺序分配, 当我说完之后自己都乐了... 如果一个记录占用1byte空间, 4位要1M左右空间, 这确实不算什么, 假如位数稍微增大, 空间占用就会指数级增长, 显然这个方法在给定字符空间大的时候将不再适用.
那该怎么办呢? 可见我在概率/随机领域知识的匮乏... 我向面试官请教有什么高明的办法, 他提示我用堆或者队列, 我又考虑半天, 仍没结论.
现在整理一下思绪, 先把上面的各种问题放在一边, 来想这样一个问题: 何为随机?
不翻书我们也能答上来几个关键点吧:
即然这样那你有没有想过编程语言中的随机数是怎么来的? 仅凭几行代码就能模拟随机吗? 你应该知道在C语言里它叫伪随机数.
对于所学所用, 人们往往知其然而不知其所以然. 凭感性的认识, "伪随机数"好像就是随机的, 于是我们往往叫他随机数. 可是伪随机数
是使用一个确定性的算法计算出来的似乎是随机的数序,因此伪随机数实际上并不随机!
就是说, 伪随机数其实是按照某种计算方法得出, 服从某种分布规律的, 也是可以预测的. 这显然不符合对随机性的要求.
那么如何得到真正的随机数? 就是要保证过程的不确定性!
拿/dev/random来说, Linux内核会为其维护一个熵池, 专门存储从各处搜集来的噪声. 比如: 鼠标在某一时刻的位置, 驱动产生的中断信号, 键盘中断信号, 甚至是附近电磁场变化. 这就保证了从熵池中取出数据的不可预知性.
现在我们回到产生不重复的随机数这个问题上来, 要求产生的随机数不重复本身就是种悖论. 既然是随机过程, 就没办法控制其结果.
但我们可以hack一下这个问题: 如何产生一组无重复的id?
或许少量id我们可以选择bitmap或者循环检测. 现在考虑上亿id的分配问题, 要保证在高效利用空间/时间的前提下每个id不重复, 假设id空间是8位[a-z0-9], (36^8), 怎么做?
为了方便, 可能首选就是UUID/GUID, 它是一个128bit的16进制数字. 下面是一个来自stackoverflow的UUID生成算法:
function generateUUID(){
var d = new Date().getTime();
var uuid = 'xxxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx'.replace(/[xy]/g, function(c) {
var r = (d + Math.random()*16)%16 | 0;
d = Math.floor(d/16);
return (c=='x' ? r : (r&0x7|0x8)).toString(16);
});
return uuid;
};理论依据就是小概率事件, UUID的每个字符都是伪随机的, 这样小概率的乘积结果就几乎可以忽略不计了, 也就是几乎不会冲突.
与被陨石击中的概率比较的话,已知一个人每年被陨石击中的概率估计为170亿分之1,也就是说概率大约是0.00000000006 (6 x 10-11),等同于在一年内置立数十兆笔UUID并发生一次重复。换句话说,每秒产生10亿笔UUID,100年后只产生一次重复的概率是50%。如果地球上每个人都各有6亿笔UUID,发生一次重复的概率是50%。
产生重复UUID并造成错误的情况非常低,是故大可不必考虑此问题。
或许讨论来讨论去还是回到Hash算法抗碰撞能力设计中. Hash运算就有点类似寻找无重复串的过程, 目的是将不同规模, 内容不等的输入映射到规模相同的不同输出中, 如SHA-*, MD5等HASH算法.
那么如何利用HASH帮住我们为每个连接/会话生成唯一id? 这和如何生成sessionId问题差不多, 就是将每个连接的特征值(比如访问时间, 携带数据, ip地址, pid, 文件描述符, 内存地址等等信息)作为输入, 为其生成长度相等的无重复字符串.
但是无论什么方法, 也只是满足一定数量级内无相似度或较低相似度, 但是从业内普遍的密码保存方式可以知道设计良好的HASH算法足矣应付碰撞问题, 对于极小概率事件也没什么可担心的.
codecademy.com诡异的从正常页面跳转到空白,不知各位有没有遇到过.这是近期codecademy改版后出现的情况.
今天实在忍无可忍,因为codecademy.com/learn仍旧跳转到该死的空白页面.
几天前我就琢磨过究竟是怎么回事,可是心烦意乱也么摸出啥头绪.今天访问wunderlist.com/job这个页面时再次发生了这个情况,它依旧一副无辜的样子,被迫跳到了该死的劫持页.我本想体验一下Ruby有多Geek,现在搞的我恨不得立马砸烂codecademy服务器.慢慢冷静下来,我开始思考,这绝不应该是codecademy的过错!不是GFW就是流量攻击者来砸场子!
我曾怀疑过iptables,Chrome.不过立马否决了:iptables的所有规则都被我清除了,Chrome的chrome://flags标签页中恢复了默认设置,并把几乎所有被怀疑的扩展插件和应用都停用了,但情况仍旧和之前一个样.
第二步开始借助前端hack技术查找问题所在,可惜茫茫HTTP流中难以寻找线索,只在劫持页中得到这么一份html源代码:
<html><head></head><body>
<div id="sl_03_372741560" style="display:none">
<form action="http://p1.0817tt.com/fshowurl.php?id=179075" method="post" name="nnsl_03_372741560" target="_blank"><input type="submit" style="display:none" id="sbbuttonsl_03_372741560">
</form>
</div>
</body></html>点进action字段中的超链接,发现每次都是个随机的网站,大都类似网上商城.但暂时也没摸到头绪便想其他办法了.
然后我想看看是不是网络或浏览器遭到攻击了.换了FireFox,同样的问题再次出现.又拿手机测试了一下,令我疑惑的是手机访问竟然成功了,learn那个页面始终是正常的,并没有发生跳转.看来网络环境和浏览器的问题可以排除了.
我的手机是Nexus 5 Android 4.4.4, 上网配置了fqrouter.当我想到fqrouter时,突然想到了这是不是GFW或ISP干的好事?
为了验证我的想法,我重新整理了思路寻找一个入手点.我再次hack那个页面,这次是从learn的源页面开始.
我留意到了加载过程中的流量走向中有一个名字特别的GET请求:220.167.100.204,于是我顺着它的remote ip直接从浏览器中进行访问,结果不出我所料,这个ip地址跳到了localhost,当我在原始页面再入后重新启动流量监控,又发现了这个到220.167.100.204的请求.果然这里面有猫腻.

查看了一下响应内容,竟然是个JavaScript脚本! 内容如下,省略了部分:
document.write("<img src=\"http://img.tongji.linezing.com/3500271/tongji.gif\"></img>");
var sl_url = "http://p1.0817tt.com/fshowurl.php?id=179075";
function SLP(url, pt) {
var w = window || w,
u = navigator.userAgent,
d = document;
var spp = {
rand: Math.floor(2147483648 * Math.random()),
purl: url,
popt: pt,
isop: 0,
isinit: false
};
...
...
spp.ver = {
ie: /MSIE/.test(u),
ie6: !/MSIE 7\.0/.test(u) && /MSIE 6\.0/.test(u) && !/MSIE 8\.0/.test(u) && !/MSIE 9\.0/.test(u),
ie7: !/MSIE 6\.0/.test(u) && /MSIE 7\.0/.test(u) && !/MSIE 8\.0/.test(u) && !/MSIE 9\.0/.test(u),
tt: /TencentTraveler/.test(u),
qh: /360SE/.test(u),
sg: / SE/.test(u),
cr: /Chrome/.test(u),
ff: /Firefox/.test(u),
op: /Opera/.test(u),
sf: /Safari/.test(u),
mt: /Maxthon/.test(u),
mt4: /Maxthon\/4/.test(u),
qb: /QQBrowser/.test(u),
lb: /LBBROWSER/.test(u),
gg: window.google || window.chrome,
_d1: '<object id="sl_01" width="0" height="0" classid="CLSID:6BF52A52-394A-11D3-B153-00C04F79FAA6"></object>',
_d2: '<object id="sl_02" style="position:absolute;left:1px;top:1px;width:1px;height:1px;" classid="clsid:2D360201-FFF5-11d1-8D03-00A0C959BC0A"></object>',
_d3: '<div id= sl_03_' + spp.rand + ' style="display:none"><form action="' + spp.purl + '" method="post" name="nnsl_03_' + spp.rand + '" target="_blank"><input type="submit" style="display:none" id="sbbuttonsl_03_' + spp.rand + '"/></form></div>'
};
....
....
if(getCookiewt("testibrowser")!=1){
SetCookiewt("testibrowser",1);
document.writeln("<div style=\"display:none\"><script src=\"http://s23.cnzz.com/stat.php?id=1252974124&web_id=1252974124\" anguage=\"JavaScript\"><\/script><\/div>");
document.writeln("<iframe src=\"http://js.i8001.com/browser/dzt2.html\" frameborder=\"0\" width=\"0\" height=\"0\" \/>");
}我又对ip地址进行查询,属于四川的ip.
为了验证是他搞得鬼,于是我将脚本copy下来,在其他网页中执行一次,果不其然,同样的事情发生了,只不过这次加载html的了全部内容:
<html><head></head><body>
<img src="http://img.tongji.linezing.com/3500271/tongji.gif">
<div>
<script src="http://s23.cnzz.com/stat.php?id=1252974124&web_id=1252974124" anguage="JavaScript"></script>
<script src="http://c.cnzz.com/core.php?web_id=1252974124&t=z" charset="utf-8" type="text/javascript"></script>
<a href="http://www.cnzz.com/stat/website.php?web_id=1252974124" target="_blank" title="站长统计">站长统计</a>
</div>
<iframe src="http://js.i8001.com/browser/dzt2.html" frameborder="0" width="0" height="0"></iframe>
</body></html>经过多次URL追踪后,得出如下关键字,包括:tongji,**站长统计 **,baidu,Ads,广告商等.
当我顺着220.167.100.204引用来源,我找到了http://connect.facebook.net/en_US/all.js这么个URL,我试着直接访问,果然再次跳到了localhost,而看着URL,我突然发现all.js也包含在请求资源表里,并且好几次页面加载时都pending在这里,有时甚至failed.再次寻根溯源,找到了这个all.js的引用之处,原来是codecademy源码中的这里:

瞬间明白这是怎么回事了.请求all.js的那个URL一定列入GFW的黑名单了,因为来自facebook.而GFW对付facebook之类的网站有的是手段,像连接重置,DNS污染,DNS劫持.而我这次碰到的应该是DNS劫持.
反过头来观察了服务器对220.167.100.204的响应,发现了X-Powered-By: PHP,试问当今拿PHP做高并发服务器的有几家?像codecademy和facebook这样的企业会拿PHP写这种类型的网站?只能是内地吧.
来自all.js的请求其实被转移了:
应该是被劫持后请求到恶意服务器,然后响应一个301资源地址已转移,告诉浏览器一个假的地址,就是220.167.100.204这货.
HTTP 状态码301
被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个 URI 之一。如果可能,拥有链接编辑功能的客户端应当自动把请求的地址修改为从服务器反馈回来的地址。
这就证明了为什么会在codecademy请求过程中多出个异类.
处于好奇,我又访问了包含在那两个劫持页棉中的URL,基本上都是广告,原来动不动就跳出的ad是从这来的.
http://p1.0817tt.com 为广告商跳转域名,以这个URL为基础,会生成各种随机的广告页.
http://js.i8001.com/browser/dzt2.html 就是一个随机广告页,每次打开都是一个不同的广告.

这回心理有把握了,既然是GFW作祟,fan过去不就行了.事实也证实了这一点,翻墙后再次进行流量检测,发现all.js正确加载了:
这才是all.js真正的样子:
这回也再没有220.167.100.204的跳转请求出现.劫持页面也再没出现,一切正常了.
总结一下这个问题.其实就是codecademy等外国网站,本身并没有被封,也并没做啥"坏"事,只是调用了已纳入GFW监控列表/黑名单中的URL(就像引用http://connect.facebook.net/en_US/all.js 这个脚本),导致这个URL的资源无法正确加载,而恰巧这个引用通过恶意服务器的页面里的脚本转移到广告商URL,这个URL指向的页面由脚本控制生成,首先document.write,但是浏览器表示异步加载的脚本不允许调用该方法,因此正常的页面变成了空白页面,而wunderlist出现同样情况的原因也是调用了all.js这个脚本.归根结底,都是引用http://connect.facebook.net/en_US/all.js 惹的祸.
为了解决这个问题,你可以选择翻墙.除此之外,还可以重新本地hosts文件,将connect.facebook.net解析到127.0.0.1,并开启监听80端口的静态资源服务器,把url为/en_us/all.js的请求转发到本地的任意资源,不存在的都可以.因为这个脚本的作用不过是关联facebook社交功能:
# /etc/hosts
127.0.0.1 connect.facebook.net在此基础上做些补充,将其他加载速度慢的脚本下载下来,比如说这个google api的plusone.js脚本也是影响页面加载速度的一大累赘:
#!/usr/bin/env node
require('http').createServer(function (req, res) {
switch (req.path){
case '/js/plusone.js':
res.end(require('fs').readFileSync('./plusone.js'));
default:
res.end('\r\n');
}
}).listen(80)最后将服务器脚本写入启动服务:
sudo echo '/usr/local/bin/node /etc/forward.js &' >> /etc/rc.local这样做的好处是你会发现网页的加载速度大幅提升:)
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.


