- Neural Networks
- Tasks
- Methods
- Datasets
- Benchmarks
- Applications
- Software
- Overview
- Opinions
- Future of AI
Notations
Checked
To Check
1998 - [LeNet]: Gradient-based learning applied to document recognition
2012 - [AlexNet] ImageNet Classification with Deep Convolutional Neural Networks
2013 - Learning Hierarchical Features for Scene Labeling
2013 - [R-CNN] Rich feature hierarchies for accurate object detection and semantic segmentation
Object detection performance, as measured on the canonical PASCAL VOC dataset, has plateaued in the last few years. The best-performing methods are complex ensemble systems that typically combine multiple low-level image features with high-level context. In this paper, we propose a simple and scalable detection algorithm that improves mean average precision (mAP) by more than 30% relative to the previous best result on VOC 2012---achieving a mAP of 53.3%. Our approach combines two key insights: (1) one can apply high-capacity convolutional neural networks (CNNs) to bottom-up region proposals in order to localize and segment objects and (2) when labeled training data is scarce, supervised pre-training for an auxiliary task, followed by domain-specific fine-tuning, yields a significant performance boost. Since we combine region proposals with CNNs, we call our method R-CNN: Regions with CNN features. We also compare R-CNN to OverFeat, a recently proposed sliding-window detector based on a similar CNN architecture. We find that R-CNN outperforms OverFeat by a large margin on the 200-class ILSVRC2013 detection dataset.

2014 - [OverFeat]: Integrated Recognition, Localization and Detection using Convolutional Networks
2014 - [Seq2Seq]: Sequence to Sequence Learning with Neural Networks
2014 - [VGG] Very Deep Convolutional Networks for Large-Scale Image Recognition
In this work we investigate the effect of the convolutional network depth on its accuracy in the large-scale image recognition setting. Our main contribution is a thorough evaluation of networks of increasing depth using an architecture with very small (3x3) convolution filters, which shows that a significant improvement on the prior-art configurations can be achieved by pushing the depth to 16-19 weight layers. These findings were the basis of our ImageNet Challenge 2014 submission, where our team secured the first and the second places in the localisation and classification tracks respectively. We also show that our representations generalise well to other datasets, where they achieve state-of-the-art results. We have made our two best-performing ConvNet models publicly available to facilitate further research on the use of deep visual representations in computer vision.
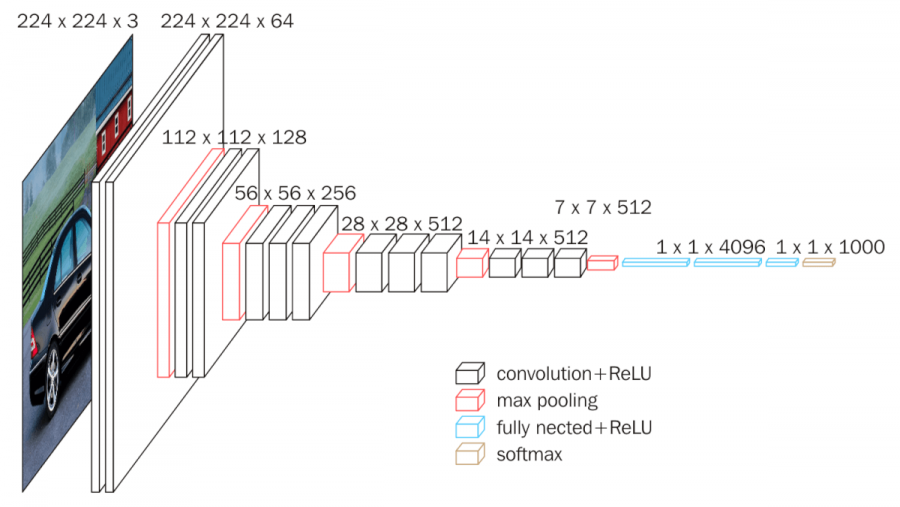
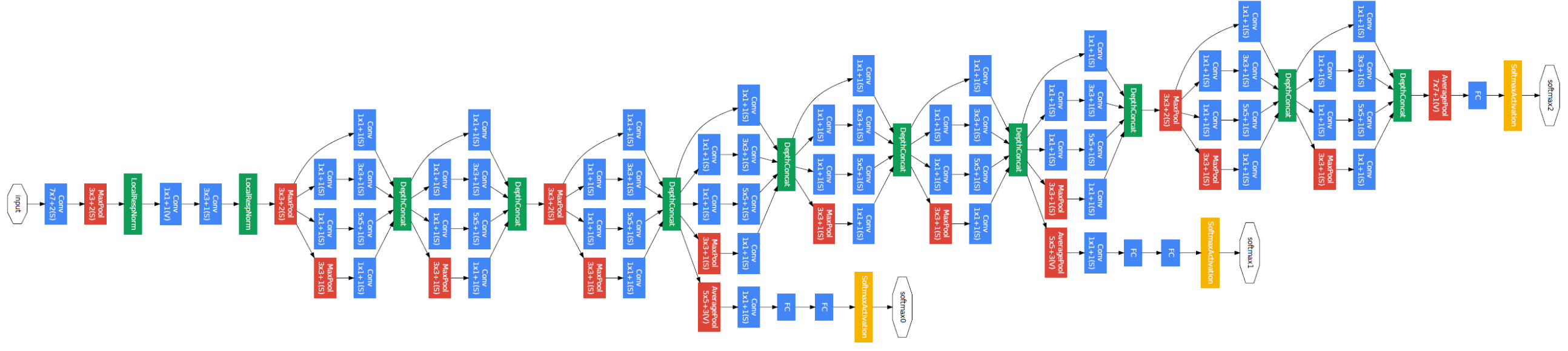
2014 - [GoogleNet] Going Deeper with Convolutions
We propose a deep convolutional neural network architecture codenamed "Inception", which was responsible for setting the new state of the art for classification and detection in the ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC 2014). The main hallmark of this architecture is the improved utilization of the computing resources inside the network. This was achieved by a carefully crafted design that allows for increasing the depth and width of the network while keeping the computational budget constant. To optimize quality, the architectural decisions were based on the Hebbian principle and the intuition of multi-scale processing. One particular incarnation used in our submission for ILSVRC 2014 is called GoogLeNet, a 22 layers deep network, the quality of which is assessed in the context of classification and detection.
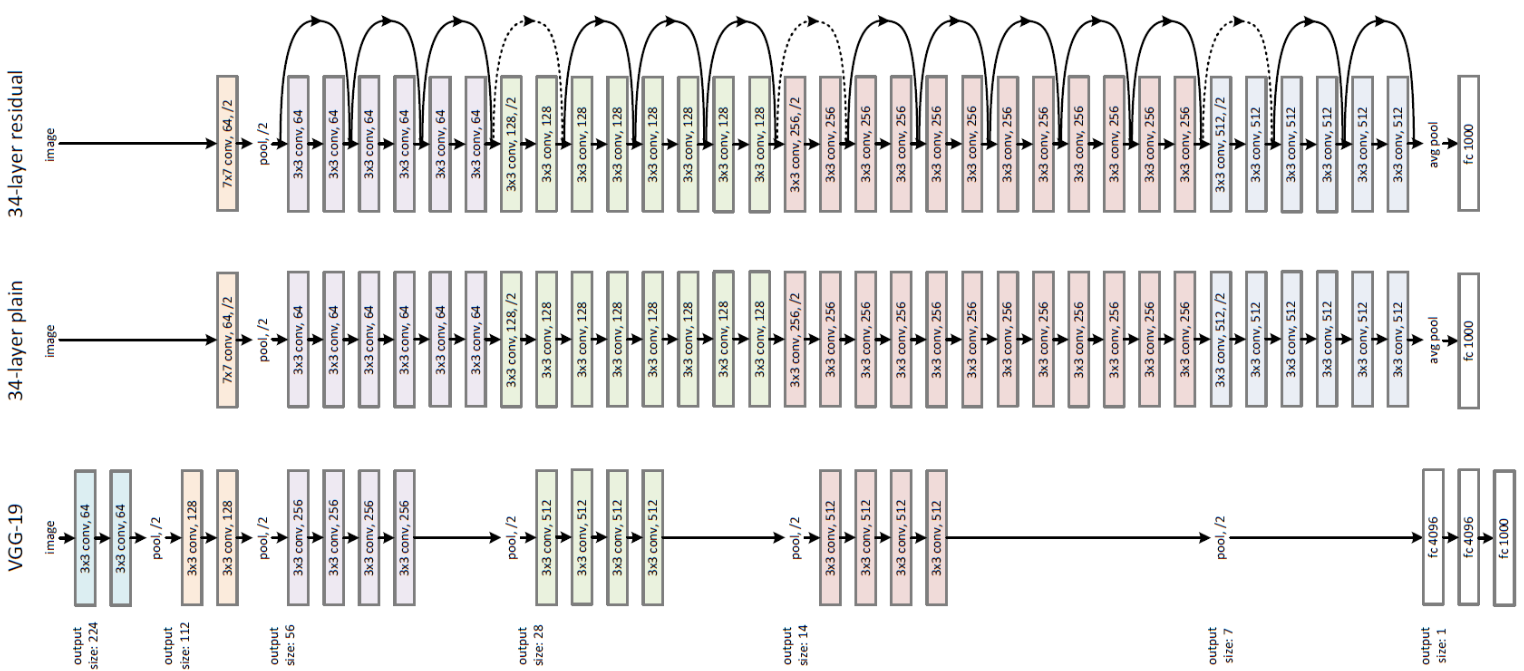
2015 - [ResNet] Deep Residual Learning for Image Recognition
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers---8x deeper than VGG nets but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers. The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.
2015 - Spatial Transformer Networks
Convolutional Neural Networks define an exceptionally powerful class of models, but are still limited by the lack of ability to be spatially invariant to the input data in a computationally and parameter efficient manner. In this work we introduce a new learnable module, the Spatial Transformer, which explicitly allows the spatial manipulation of data within the network. This differentiable module can be inserted into existing convolutional architectures, giving neural networks the ability to actively spatially transform feature maps, conditional on the feature map itself, without any extra training supervision or modification to the optimisation process. We show that the use of spatial transformers results in models which learn invariance to translation, scale, rotation and more generic warping, resulting in state-of-the-art performance on several benchmarks, and for a number of classes of transformations.
2016 - [WRN]: Wide Residual Networks [github]
2015 - [FCN] Fully Convolutional Networks for Semantic Segmentation

2015 - [U-net]: Convolutional networks for biomedical image segmentation
2016 - [Xception]: Deep Learning with Depthwise Separable Convolutions Implementation
2016 - [V-Net]: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation
2017 - [MobileNets]: Efficient Convolutional Neural Networks for Mobile Vision Applications
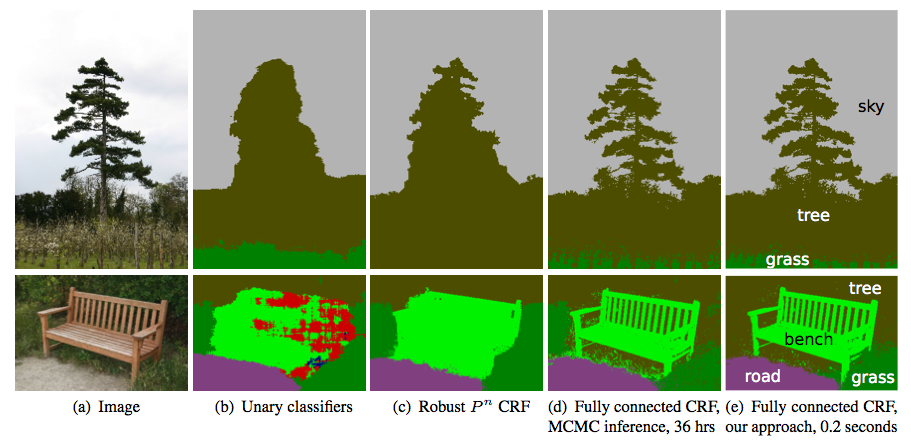
Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials
2018 - [TernausNet]: U-Net with VGG11 Encoder Pre-Trained on ImageNet for Image Segmentation
2018 - CubeNet: Equivariance to 3D Rotation and Translation[github], [video]

2018 - Deep Rotation Equivariant Network[github]

2019 - [PacNet]: Pixel-Adaptive Convolutional Neural Networks
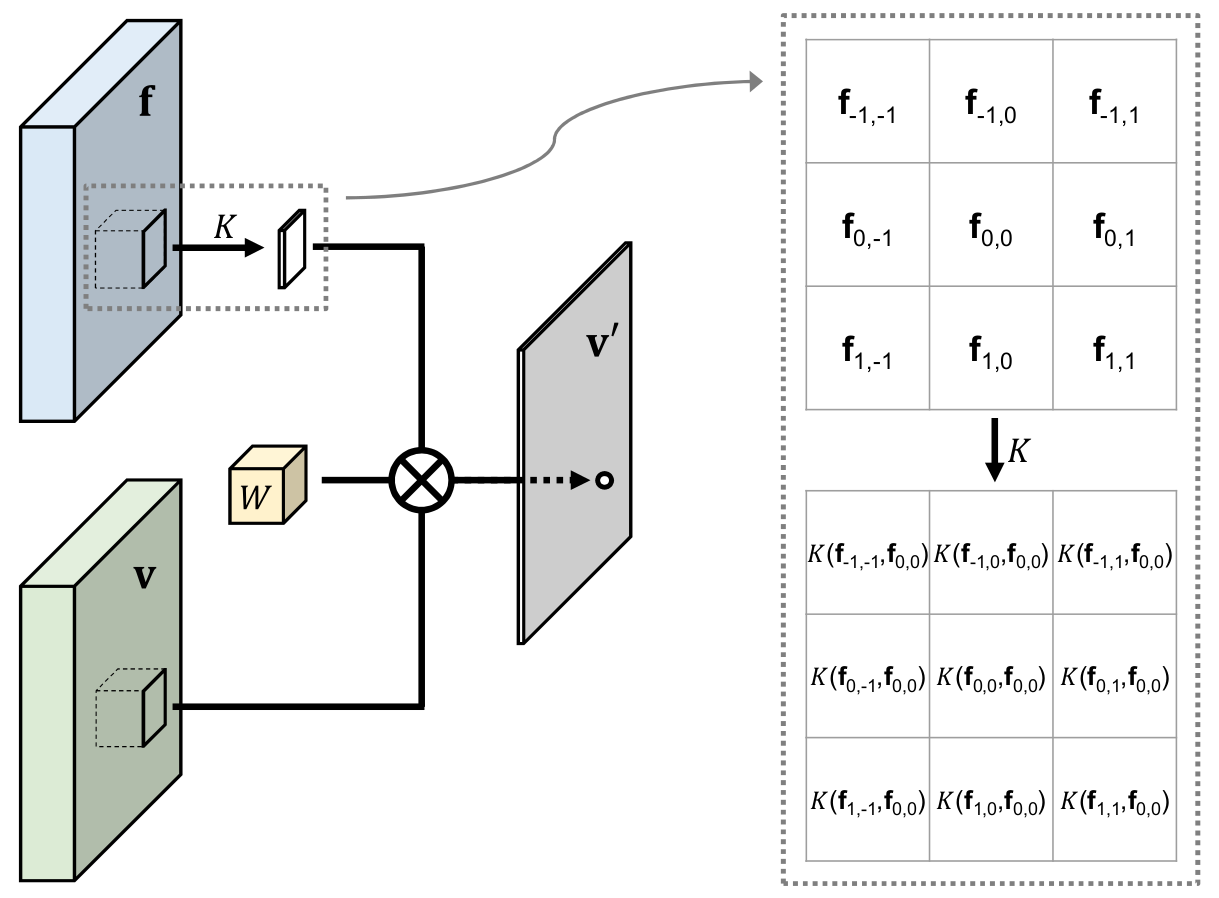
2019 - Decoders Matter for Semantic Segmentation: Data-Dependent Decoding Enables Flexible Feature Aggregation [github]
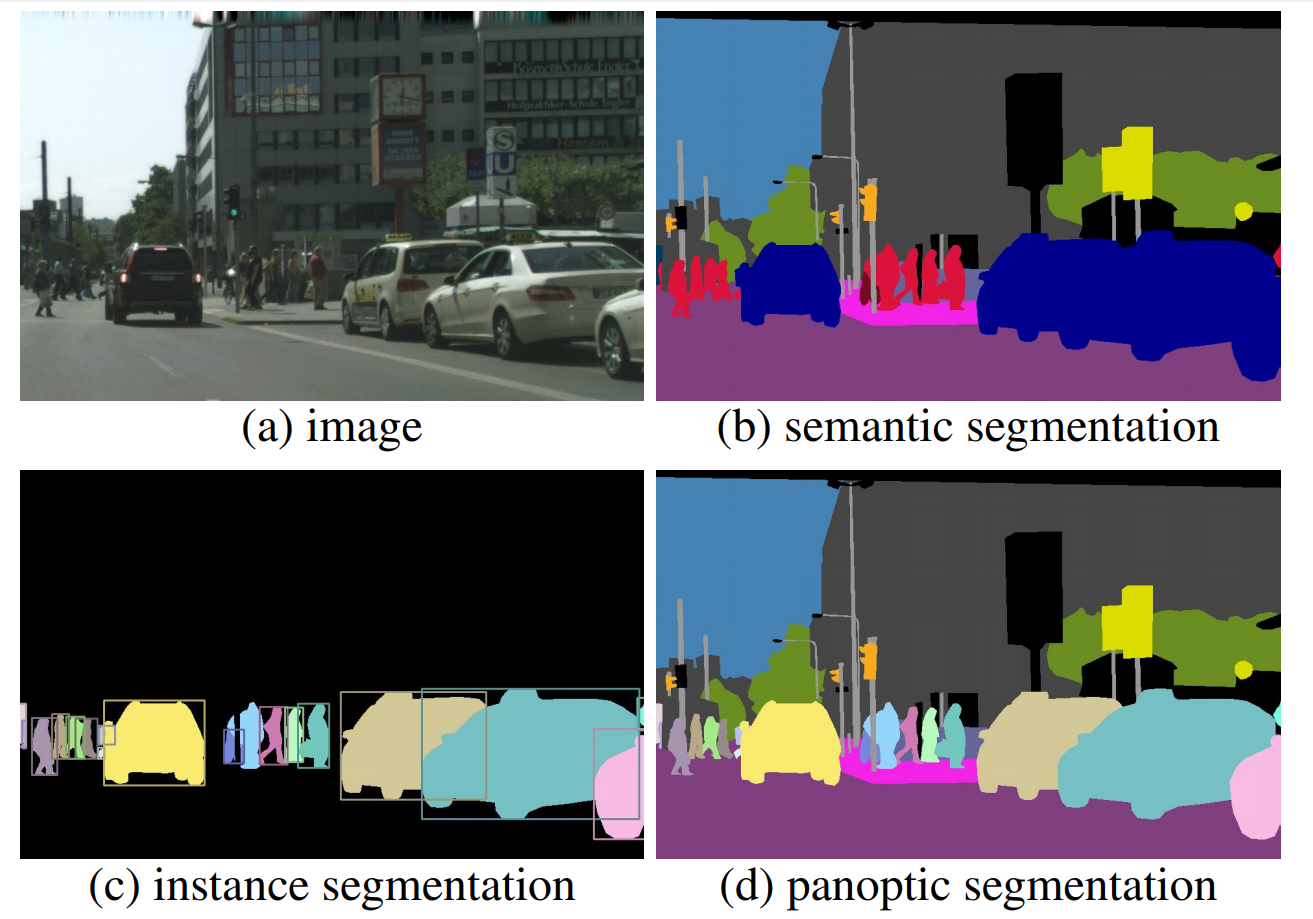
2019 - Panoptic Feature Pyramid Networks
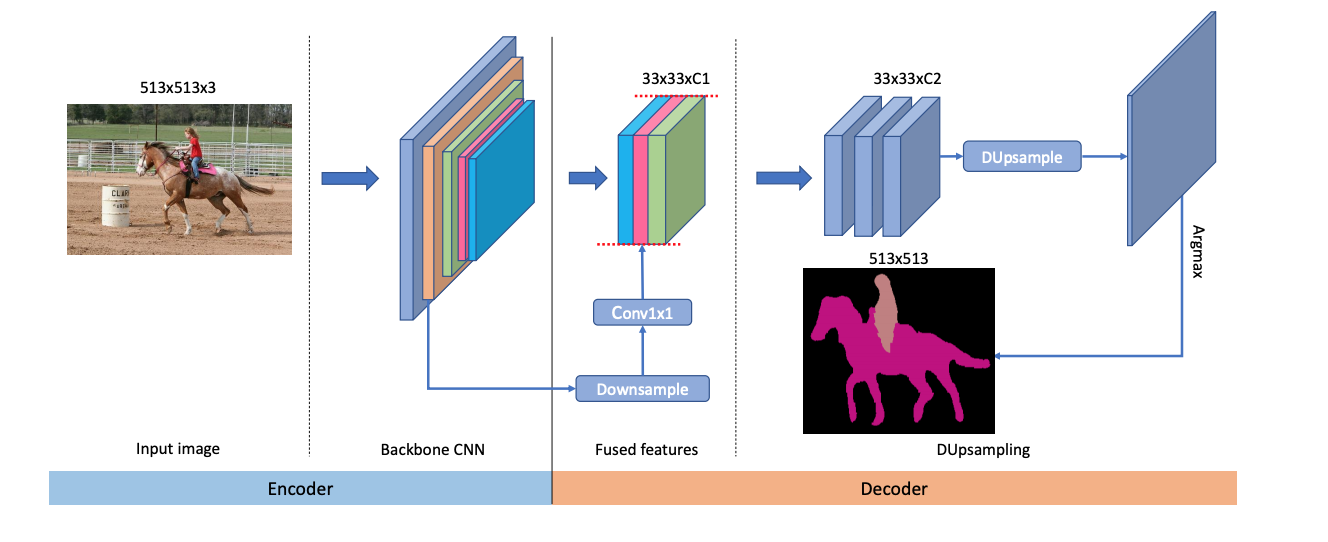
2019 - [DeeperLab]: Single-Shot Image Parser
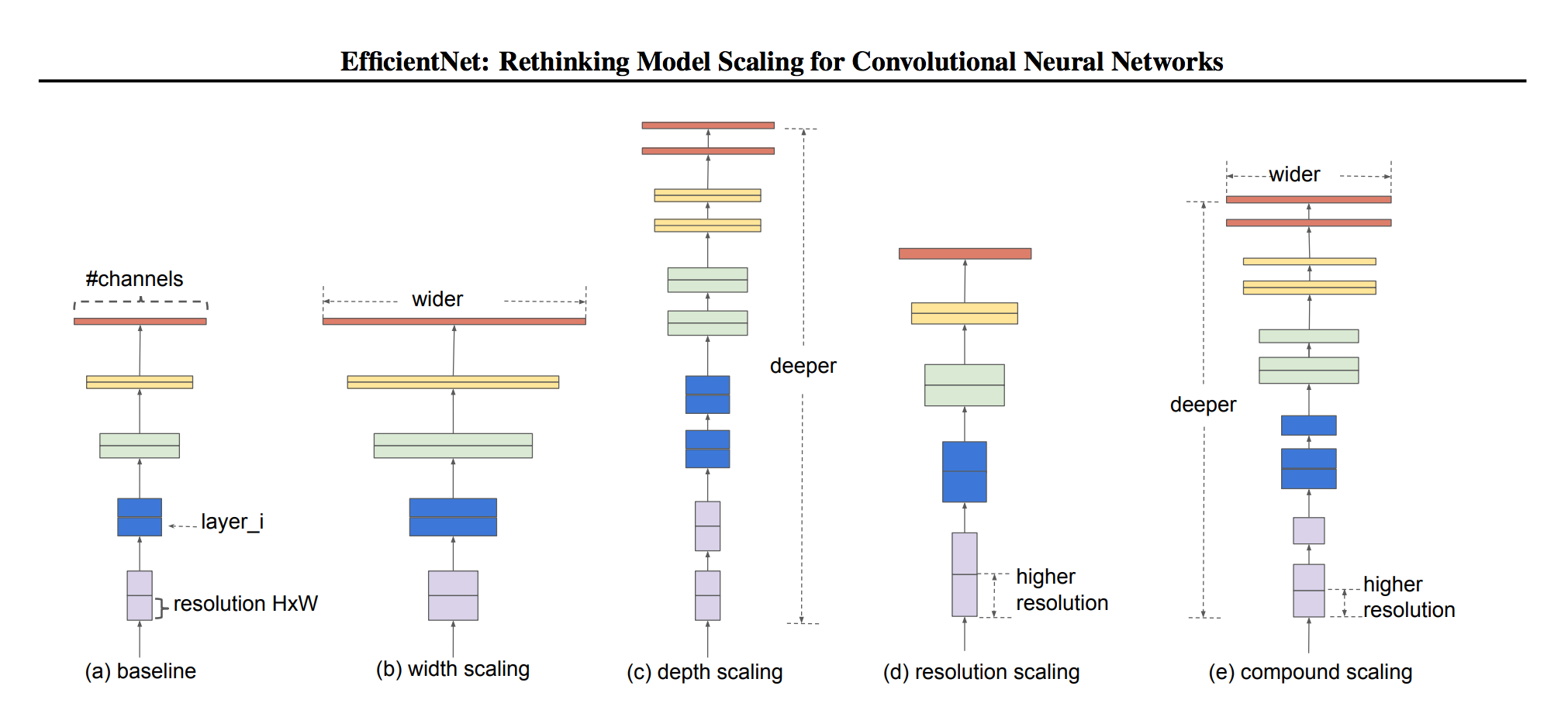
2019 - [EfficientNet]: Rethinking Model Scaling for Convolutional Neural Networks

2014 - [SPP-Net] Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition

2016 - [ParseNet]: Looking Wider to See Better
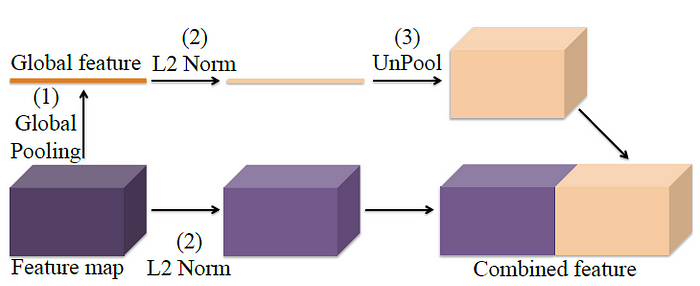
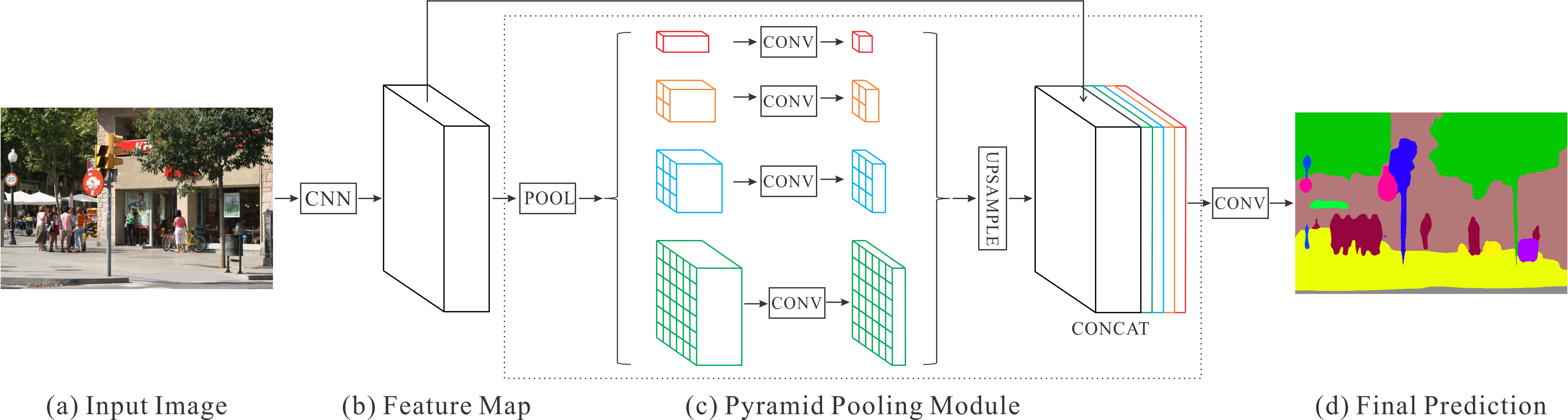
2016 - [PSPNet]: Pyramid Scene Parsing Network [github]
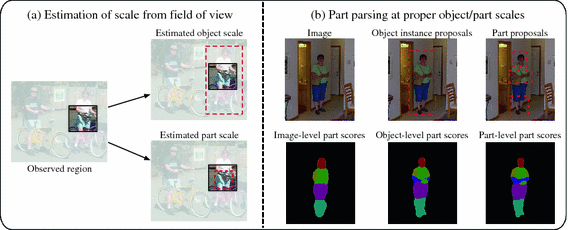
2015 - Zoom Better to See Clearer: Human and Object Parsing with Hierarchical Auto-Zoom Net
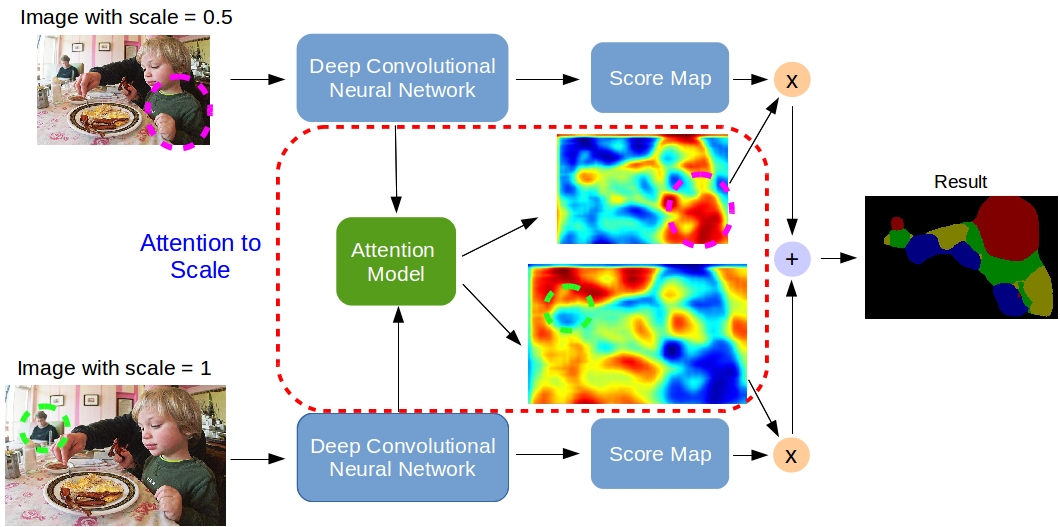
2016 - Attention to Scale: Scale-aware Semantic Image Segmentation
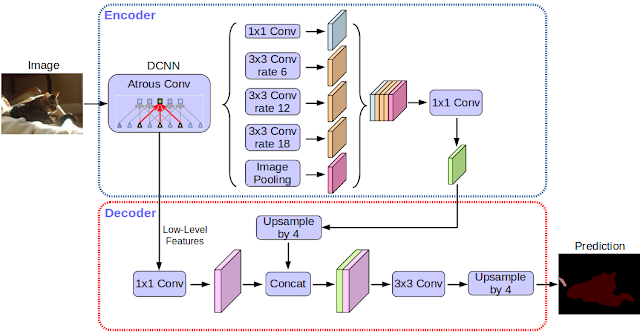
2017 - Rethinking Atrous Convolution for Semantic Image Segmentation
2017 - Feature Pyramid Networks for Object Detection
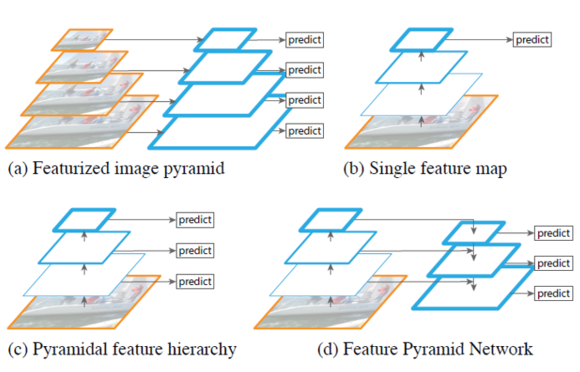
2019 - [FastFCN]: Rethinking Dilated Convolution in the Backbone for Semantic Segmentation [github]

2019 - Making Convolutional Networks Shift-Invariant Again

2019 - [LEDNet]: A Lightweight Encoder-Decoder Network for Real-Time Semantic Segmentation

2019 - Feature Pyramid Encoding Network for Real-time Semantic Segmentation

2019 - Efficient Segmentation: Learning Downsampling Near Semantic Boundaries

2019 - PointRend: Image Segmentation as Rendering

2019 - Fixing the train-test resolution discrepancy

This paper first shows that existing augmentations induce a significant discrepancy between the typical size of the objects seen by the classifier at train and test time.
We experimentally validate that, for a target test resolu- tion, using a lower train resolution offers better classification at test time.
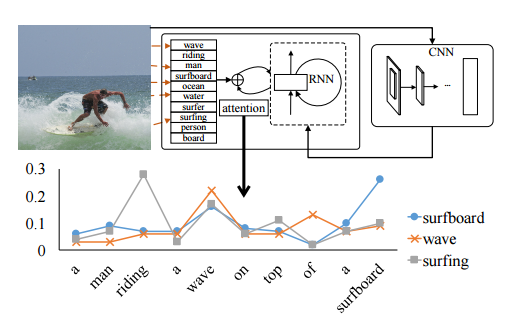
2016 - Image Captioning with Semantic Attention
2018 - [EncNet] Context Encoding for Semantic Segmentation [github]
2018 - Tell Me Where to Look: Guided Attention Inference Network

2005 - Image Parsing: Unifying Segmentation, Detection, and Recognition
2013 - Complexity of Representation and Inference in Compositional Models with Part Sharing
2017 - Interpretable Convolutional Neural Networks
2019 - Local Relation Networks for Image Recognition

2017 - Teaching Compositionality to CNNs

2017 - Dynamic Routing Between Capsules

Random search for hyper-parameter optimisation
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
[Adam]: A Method for Stochastic Optimization
[Dropout]: A Simple Way to Prevent Neural Networks from Overfitting
Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks
Multi-Scale Context Aggregation by Dilated Convolutions https://arxiv.org/abs/1511.07122

2017 - The Marginal Value of Adaptive Gradient Methods in Machine Learning
(i) Adaptive methods find solutions that generalize worse than those found by non-adaptive methods.
(ii) Even when the adaptive methods achieve the same training loss or lower than non-adaptive methods, the development or test performance is worse.
(iii) Adaptive methods often display faster initial progress on the training set, but their performance quickly plateaus on the development set.
(iv) Though conventional wisdom suggests that Adam does not require tuning, we find that tuning the initial learning rate and decay scheme for Adam yields significant improvements over its default settings in all cases.
DARTS: Differentiable Architecture Search https://arxiv.org/abs/1806.09055
Bag of Tricks for Image Classification with Convolutional Neural Networks
2018 - Tune: A Research Platform for Distributed Model Selection and Training [github]
2017 - Equilibrium Propagation: Bridging the Gap Between Energy-Based Models and Backpropagation
2017 - Understanding deep learning requires rethinking generalization
2018 - An Empirical Model of Large-Batch Training

2019 - Training Neural Networks with Local Error Signals [github]
2019 - Switchable Normalization for Learning-to-Normalize Deep Representation

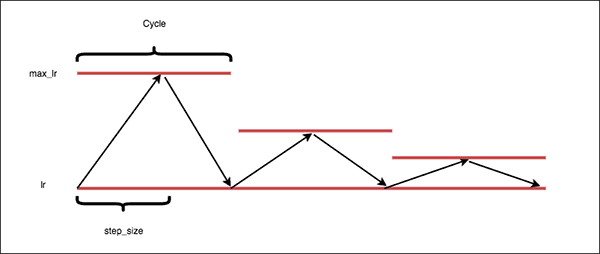
2019 - Cyclical Learning Rates for Training Neural Networks
2020 - Fantastic Generalization Measures and Where to Find Them
The most direct and principled approach for studying generalization in deep learning is to prove a generalization bound which is typically an upper bound on the test error based on some quantity that can be calculated on the training set.
Kendall’s Rank-Correlation Coefficient: Given a set of models resulted by training with hyperparameters in the set Θ, their associated generalization gap {g(θ)| θ ∈ Θ}, and their respective values of the measure {µ(θ)| θ ∈ Θ}, our goal is to analyze how consistent a measure (e.g. L2 norm of network weights) is with the empirically observed generalization. If complexity and generalization are independent, the coefficient becomes zero
VC-dimension as well as the number of parameters are negatively correlated with generalization gap which confirms the widely known empirical observation that overparametrization improves generalization in deep learning.
These results confirm the general understanding that larger margin, lower cross-entropy and higher entropy would lead to better generalization
we observed that the initial phase (to reach cross-entropy value of 0.1) of the optimization is negatively correlated with the ??speed of optimization?? (error?) for both τ and Ψ. This would suggest that the difficulty of optimization during the initial phase of the optimization benefits the final generalization.
Towards the end of the training, the variance of the gradients also captures a particular type of “flatness” of the local minima. This measure is surprisingly predictive of the generalization both in terms of τ and Ψ, and more importantly, is positively correlated across every type of hyperparameter.
There are mixed results about how the optimization speed is relevant to generalization. On one hand we know that adding Batch Normalization or using shortcuts in residual architectures help both optimization and generalization.On the other hand, there are empirical results showing that adaptive optimization methods that are faster, usually generalize worse (Wilson et al., 2017b).
Based on empirical observations made by the community as a whole, the canonical ordering we give to each of the hyper-parameter categories are as follows:
- Batchsize: smaller batchsize leads to smaller generalization gap
- Depth: deeper network leads to smaller generalization gap
- Width: wider network leads to smaller generalization gap
- Dropout: The higher the dropout (≤ 0.5) the smaller the generalization gap
- Weight decay: The higher the weight decay (smaller than the maximum for each optimizer) the smaller the generalization gap
- Learning rate: The higher the learning rate (smaller than the maximum for each optimizer) the smaller the generalization gap
- Optimizer: Generalization gap of Momentum SGD < Generalization gap of Adam < Generalization gap of RMSProp
2013 - Do Deep Nets Really Need to be Deep?
2015 - Learning both Weights and Connections for Efficient Neural Networks
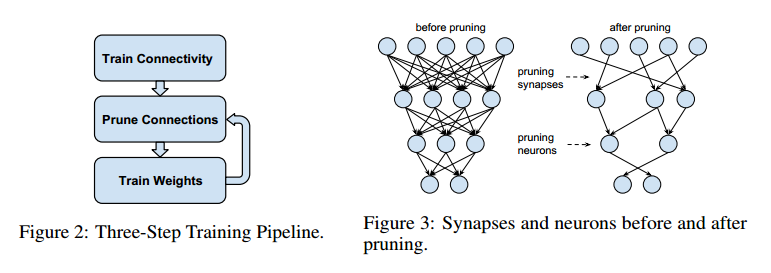

2015 - Distilling the Knowledge in a Neural Network
2017 - Learning Efficient Convolutional Networks through Network Slimming - [github]

2018 - Rethinking the Value of Network Pruning
For all state-of-the-art structured pruning algorithms we examined, fine-tuning a pruned model only gives comparable or worse performance than training that model with randomly initialized weights. For pruning algorithms which assume a predefined target network architecture, one can get rid of the full pipeline and directly train the target network from scratch.
Our observations are consistent for multiple network architectures, datasets, and tasks, which imply that:
- training a large, over-parameterized model is often not necessary to obtain an efficient final model
- learned “important” weights of the large model are typically not useful for the small pruned model
- the pruned architecture itself, rather than a set of inherited “important” weights, is more crucial to the efficiency in the final model, which suggests that in some cases pruning can be useful as an architecture search paradigm.
2018 - Slimmable Neural Networks
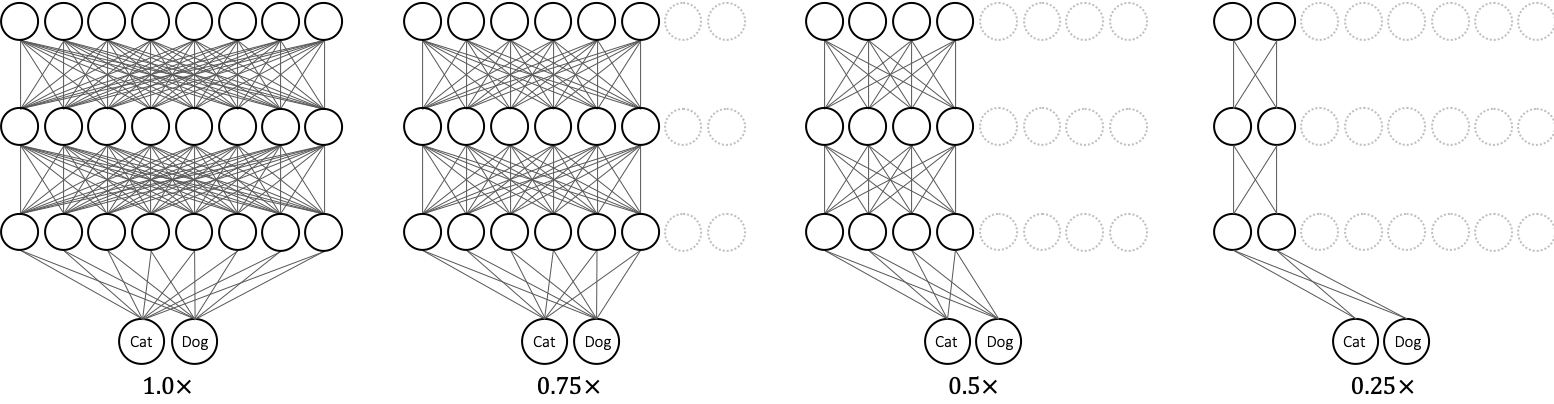
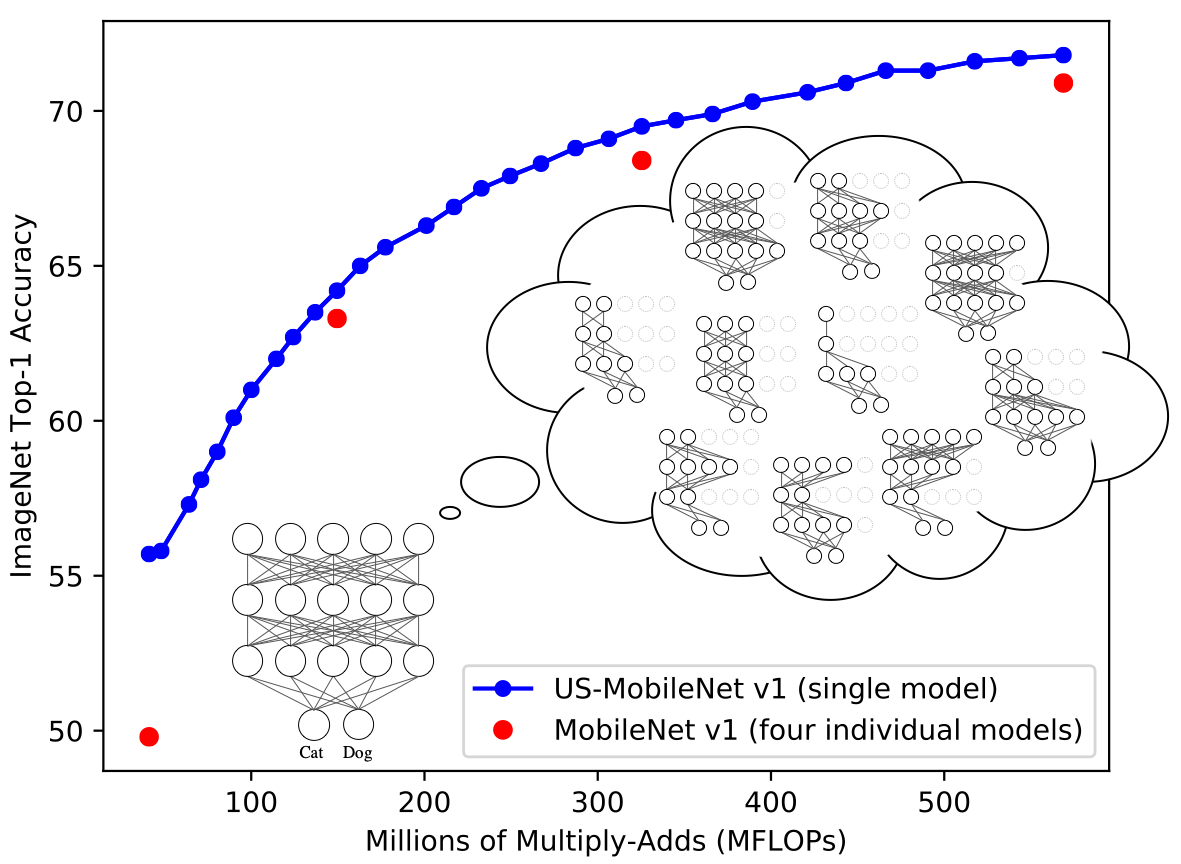
2019 - Universally Slimmable Networks and Improved Training Techniques
2019 - The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
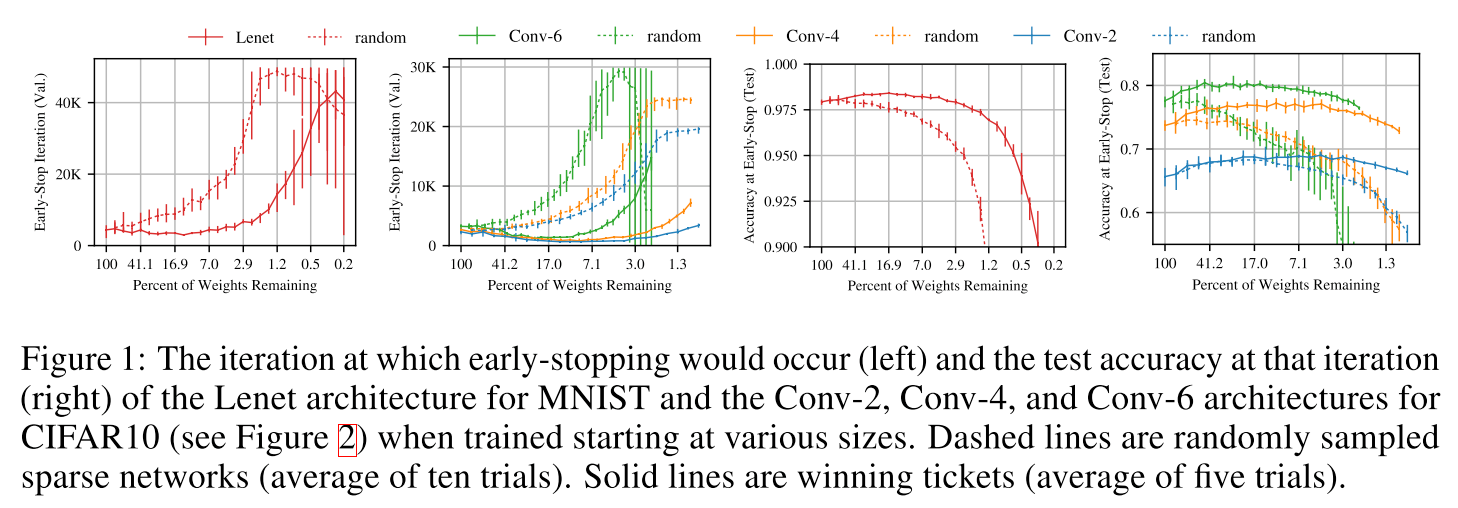
Based on these results, we articulate the lottery ticket hypothesis: dense, randomly-initialized, feed-forward networks contain subnetworks (winning tickets) that—when trained in isolation— reach test accuracy comparable to the original network in a similar number of iterations.
The winning tickets we find have won the initialization lottery: their connections have initial weights that make training particularly effective.
2019 - AutoSlim: Towards One-Shot Architecture Search for Channel Numbers

2015 - Visualizing and Understanding Recurrent Networks
2016 - Discovering Causal Signals in Images
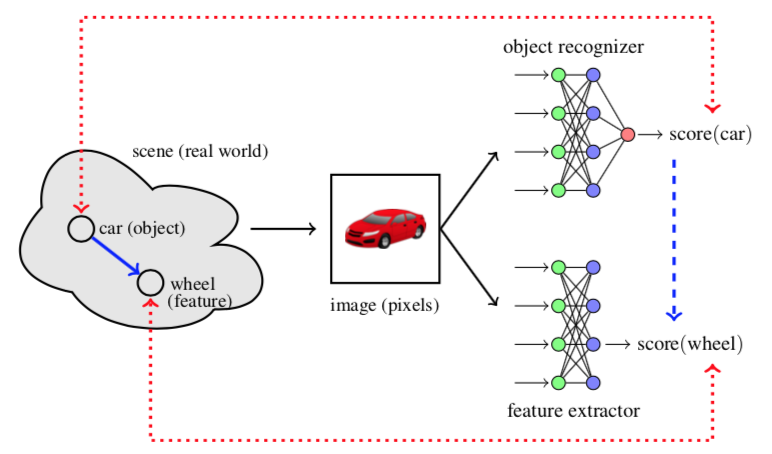
2016 - [Grad-CAM]: Why did you say that? Visual Explanations from Deep Networks via Gradient-based Localization [github]
2017 - Visualizing the Loss Landscape of Neural Nets

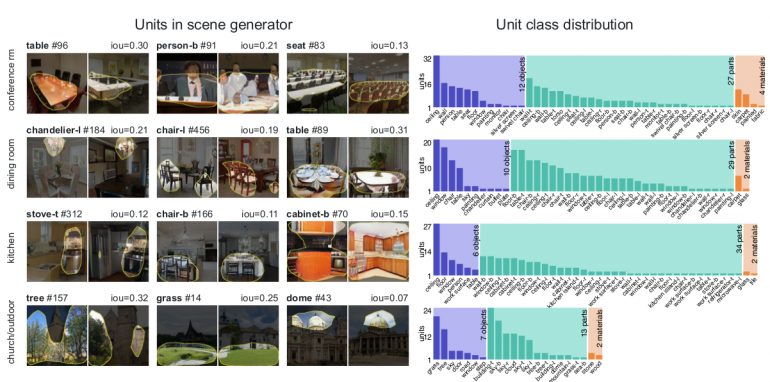
2018 - GAN Dissection: Visualizing and Understanding Generative Adversarial Networks

[Netron ] Visualizer for deep learning and machine learning models

2019 - [Distill]: Computing Receptive Fields of Convolutional Neural Networks

Recognizing unseen objects is a challenging perception task since the robot needs to learn the concept of “objects” and generalize it to unseen objects
An ideal method would combine the generalization capability of training on synthetic depth and the ability to produce sharp masks by training on RGB.
Training DSN with depth images allows for better generalization to the real world data
We posit that mask refinement is an easier problem than directly using RGB as input to produce instance masks.
For the semantic segmentation loss, we use a weighted cross entropy as this has been shown to work well in detecting object boundaries in imbalanced images [29].
In order to train the RRN, we need examples of perturbed masks along with ground truth masks. Since such perturbations do not exist, this problem can be seen as a data augmentation task where we augment the ground truth mask into something that resembles an initial mask
In order to seek a fair comparison, all models trained in this section are trained for 100k iterations of SGD using a fixed learning rate of 1e-2 and batch size of 8.
2019 - ShapeMask: Learning to Segment Novel Objects by Refining Shape Priors

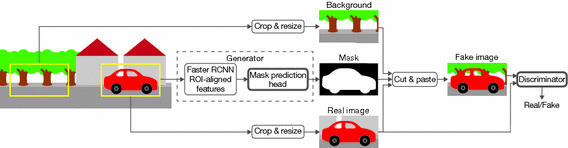
2019 - Learning to Segment via Cut-and-Paste
2019 - YOLACT Real-time Instance Segmentation[github]

2009 - Anomaly Detection: A Survey
2017 - Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery
2015 - Constrained Convolutional Neural Networks for Weakly Supervised Segmentation

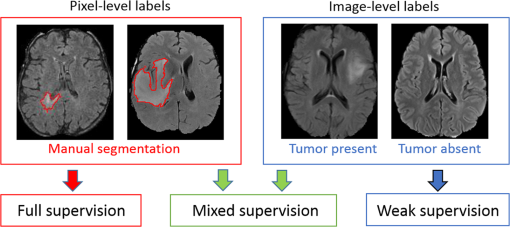
2018 - Deep Learning with Mixed Supervision for Brain Tumor Segmentation
2019 - Localization with Limited Annotation for Chest X-rays
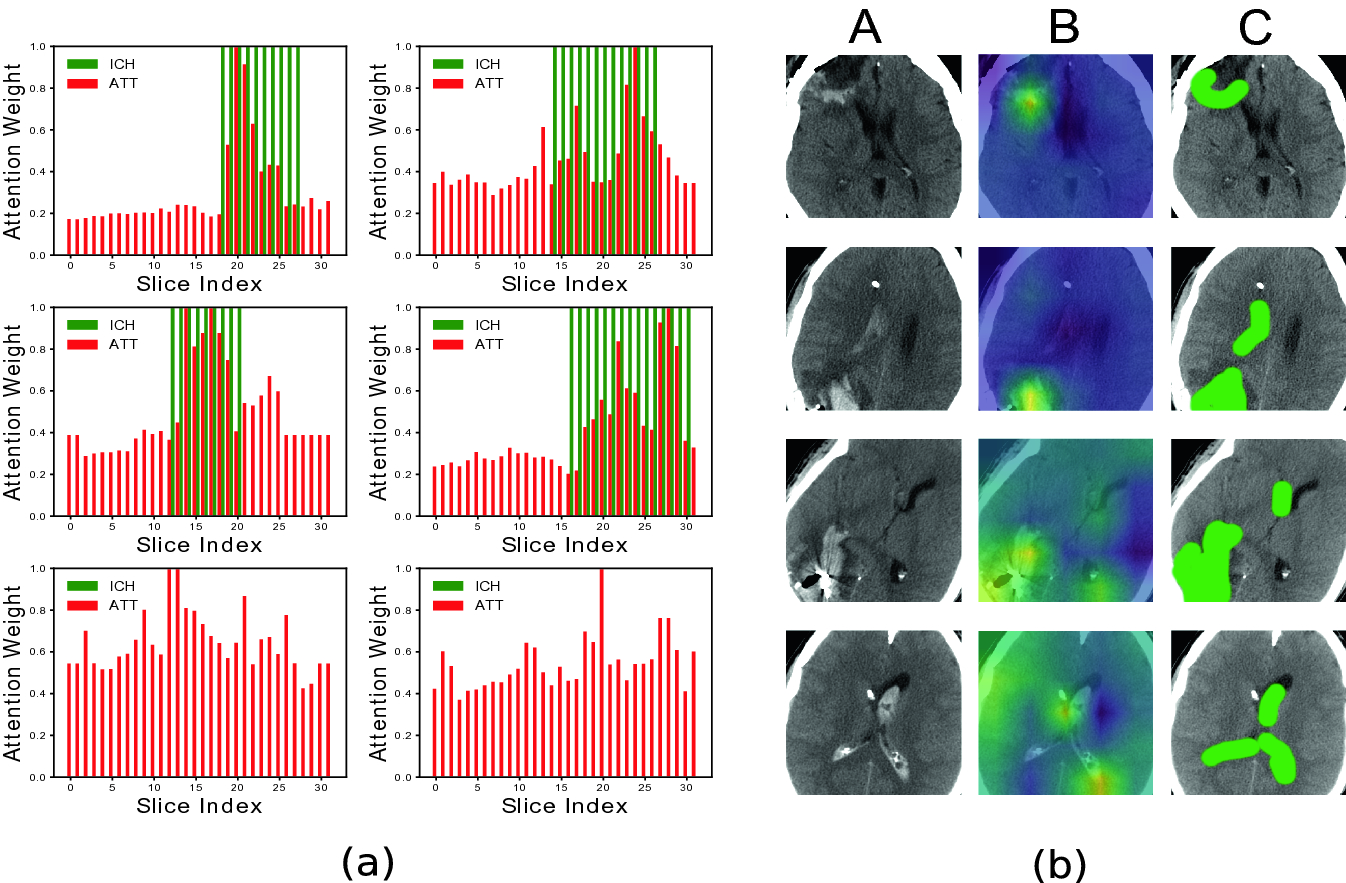
2019 - Doubly Weak Supervision of Deep Learning Models for Head CT
2019 - Training Complex Models with Multi-Task Weak Supervision
As machine learning models continue to increase in complexity, collecting large hand-labeled training sets has become one of the biggest roadblocks in practice. Instead, weaker forms of supervision that provide noisier but cheaper labels are often used. However, these weak supervision sources have diverse and unknown accuracies, may output correlated labels, and may label different tasks or apply at different levels of granularity. We propose a framework for integrating and modeling such weak supervision sources by viewing them as labeling different related sub-tasks of a problem, which we refer to as the multi-task weak supervision setting. We show that by solving a matrix completion-style problem, we can recover the accuracies of these multi-task sources given their dependency structure, but without any labeled data, leading to higher-quality supervision for training an end model. Theoretically, we show that the generalization error of models trained with this approach improves with the number of unlabeled data points, and characterize the scaling with respect to the task and dependency structures. On three fine-grained classification problems, we show that our approach leads to average gains of 20.2 points in accuracy over a traditional supervised approach, 6.8 points over a majority vote baseline, and 4.1 points over a previously proposed weak supervision method that models tasks separately.

2020 - Fast and Three-rious: Speeding Up Weak Supervision with Triplet Methods
2014 - Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks

2017 - Random Erasing Data Augmentation[github]

2017 - Smart Augmentation - Learning an Optimal Data Augmentation Strategy
2017 - Population Based Training of Neural Networks
2018 - Albumentations: fast and flexible image augmentations - [github]
2018 - Data Augmentation by Pairing Samples for Images Classification
2018 - [AutoAugment]: Learning Augmentation Policies from Data
2018 - Synthetic Data Augmentation using GAN for Improved Liver Lesion Classification
2018 - GAN Augmentation: Augmenting Training Data using Generative Adversarial Networks
2019 - [UDA]: Unsupervised Data Augmentation for Consistency Training - [github]
Common among recent approaches is the use of consistency training on a large amount of unlabeled data to constrain model predictions to be invariant to input noise. In this work, we present a new perspective on how to effectively noise unlabeled examples and argue that the quality of noising, specifically those produced by advanced data augmentation methods, plays a crucial role in semi-supervised learning. Our method also combines well with transfer learning, e.g., when finetuning from BERT, and yields improvements in high-data regime, such as ImageNet, whether when there is only 10% labeled data or when a full labeled set with 1.3M extra unlabeled examples is used.
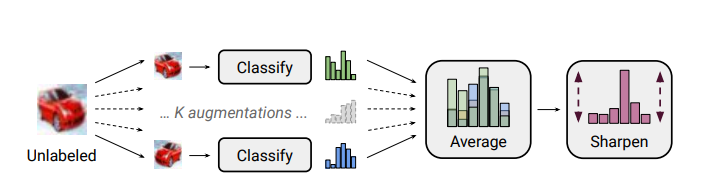
2019 - [MixMatch]: A Holistic Approach to Semi-Supervised Learning
Semi-supervised learning has proven to be a powerful paradigm for leveraging unlabeled data to mitigate the reliance on large labeled datasets. In this work, we unify the current dominant approaches for semi-supervised learning to produce a new algorithm, MixMatch, that works by guessing low-entropy labels for data-augmented unlabeled examples and mixing labeled and unlabeled data using MixUp. We show that MixMatch obtains state-of-the-art results by a large margin across many datasets and labeled data amounts.
2019 - [RealMix]: Towards Realistic Semi-Supervised Deep Learning Algorithms

2019 - Population Based Augmentation: Efficient Learning of Augmentation Policy Schedules [github]
2019 - [AugMix]: A Simple Data Processing Method to Improve Robustness and Uncertainty [github]

2019 - Self-training with [Noisy Student] improves ImageNet classification
We present a simple self-training method that achieves 88.4% top-1 accuracy on ImageNet, which is 2.0% better than the state-of-the-art model that requires 3.5B weakly labeled Instagram images. On robustness test sets, it improves ImageNet-A top-1 accuracy from 61.0% to 83.7%. To achieve this result, we first train an EfficientNet model on labeled ImageNet images and use it as a teacher to generate pseudo labels on 300M unlabeled images. We then train a larger EfficientNet as a student model on the combination of labeled and pseudo labeled images. We iterate this process by putting back the student as the teacher. During the generation of the pseudo labels, the teacher is not noised so that the pseudo labels are as accurate as possible. However, during the learning of the student, we inject noise such as dropout, stochastic depth and data augmentation via RandAugment to the student so that the student generalizes better than the teacher.

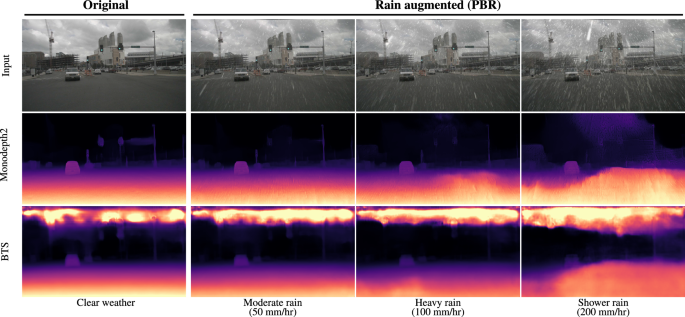
2020 - Rain rendering for evaluating and improving robustness to bad weather
2019 - Greedy InfoMax for Biologically Plausible Self-Supervised Representation Learning
2019 - Unsupervised Learning via Meta-Learning
2019 - Representation Learning with Contrastive Predictive Coding
2019 - MoCo: Momentum Contrast for Unsupervised Visual Representation Learning
We present Momentum Contrast (MoCo) for unsupervised visual representation learning. From a perspective on contrastive learning as dictionary look-up, we build a dynamic dictionary with a queue and a moving-averaged encoder. This enables building a large and consistent dictionary on-the-fly that facilitates contrastive unsupervised learning. MoCo provides competitive results under the common linear protocol on ImageNet classification. More importantly, the representations learned by MoCo transfer well to downstream tasks. MoCo can outperform its supervised pre-training counterpart in 7 detection/segmentation tasks on PASCAL VOC, COCO, and other datasets, sometimes surpassing it by large margins. This suggests that the gap between unsupervised and supervised representation learning has been largely closed in many vision tasks.
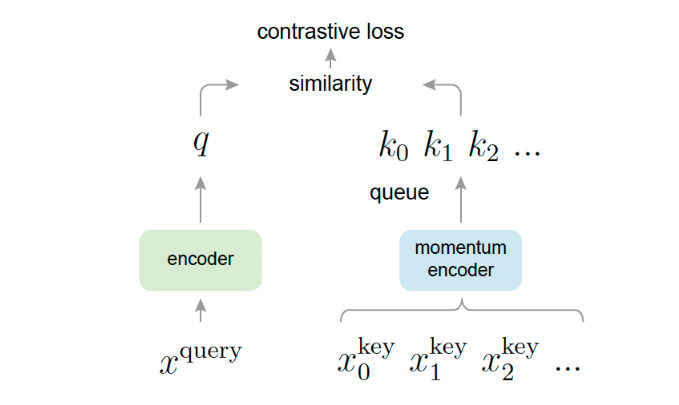
2020 - A Simple Framework for Contrastive Learning of Visual Representations

2019 - Feature Fusion for Online Mutual Knowledge Distillation

2017 - An Overview of Multi-Task Learning in Deep Neural Networks
Multi-task learning (MTL) has led to successes in many applications of machine learning, from natural language processing and speech recognition to computer vision and drug discovery. This article aims to give a general overview of MTL, particularly in deep neural networks. It introduces the two most common methods for MTL in Deep Learning, gives an overview of the literature, and discusses recent advances. In particular, it seeks to help ML practitioners apply MTL by shedding light on how MTL works and providing guidelines for choosing appropriate auxiliary tasks.
An Introduction to Deep Reinforcement Learning https://arxiv.org/abs/1811.12560
Deep Reinforcement Learning https://arxiv.org/abs/1810.06339
Playing Atari with Deep Reinforcement Learning https://arxiv.org/pdf/1312.5602.pdf
Key Papers in Deep Reinforcment Learning https://spinningup.openai.com/en/latest/spinningup/keypapers.html
Recurrent Models of Visual Attention https://arxiv.org/abs/1406.6247
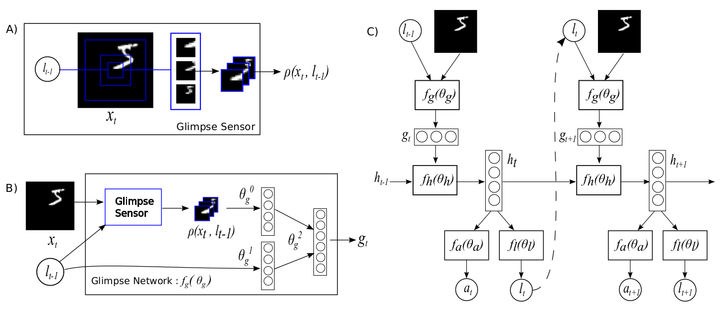
2019 - On the Feasibility of Learning, Rather than Assuming, Human Biases for Reward Inference

2015 - Natural Language Object Retrieval
2019 - CLEVR-Ref+: Diagnosing Visual Reasoning with Referring Expressions
[ADE20K Dataset]: Semantic Segmentation [website]
Scene Parsing through ADE20K Dataset http://people.csail.mit.edu/bzhou/publication/scene-parse-camera-ready.pdf

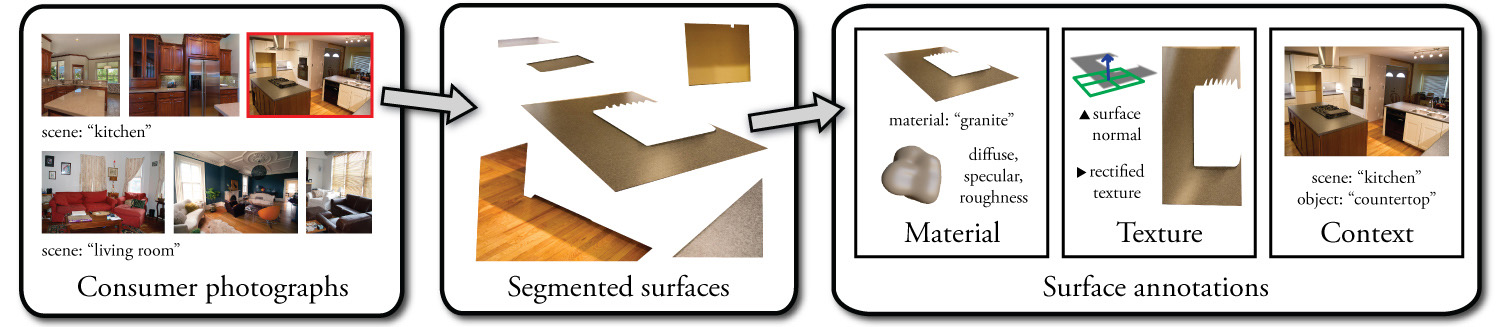
[OPENSURFACES]: A Richly Annotated Catalog of Surface Appearance
https://www.cs.cornell.edu/~paulu/opensurfaces.pdf
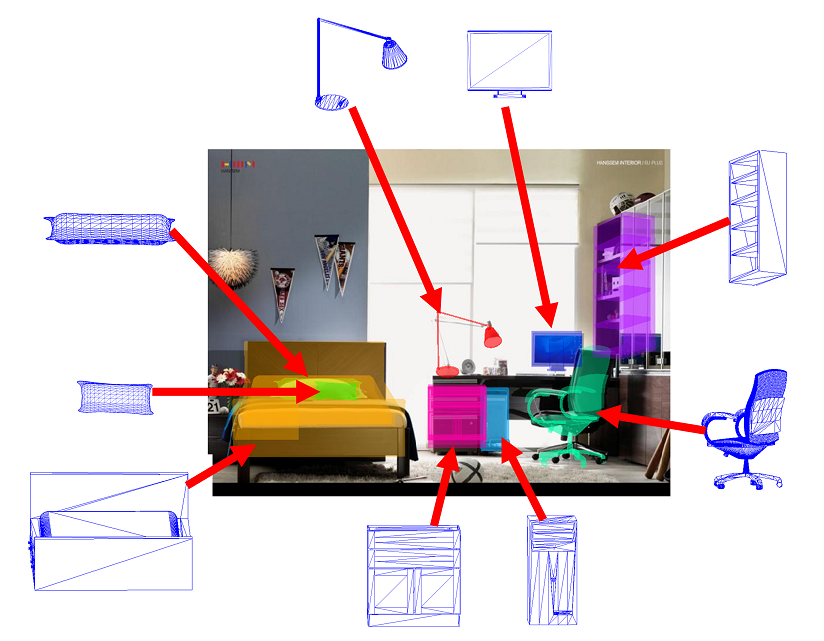
[ShapeNet] - a richly-annotated, large-scale dataset of 3D shapes [website]
ShapeNet: An Information-Rich 3D Model Repository
Beyond PASCAL: A Benchmark for 3D Object Detection in the Wild [website] [paper]
[ObjectNet3D]: A Large Scale Database for 3D Object Recognition
[ModelNet]: a comprehensive clean collection of 3D CAD models for objects [website]

[3D ShapeNets]: A Deep Representation for Volumetric Shapes (2015)
[DTD]: Describable Textures Dataset

[MegaDepth]: Learning Single-View Depth Prediction from Internet Photos

Microsoft [COCO]: Common Objects in Context[website]

DAWNBench: is a benchmark suite for end-to-end deep learning training and inference.
DAWNBench: An End-to-End Deep Learning Benchmark and Competition (paper) (2017)
Material Recognition in the Wild with the Materials in Context Database http://opensurfaces.cs.cornell.edu/publications/minc/
tempoGAN: A Temporally Coherent, Volumetric GAN for Super-resolution Fluid Flow https://ge.in.tum.de/publications/tempogan/

BubGAN: Bubble Generative Adversarial Networks for Synthesizing Realistic Bubbly Flow Images

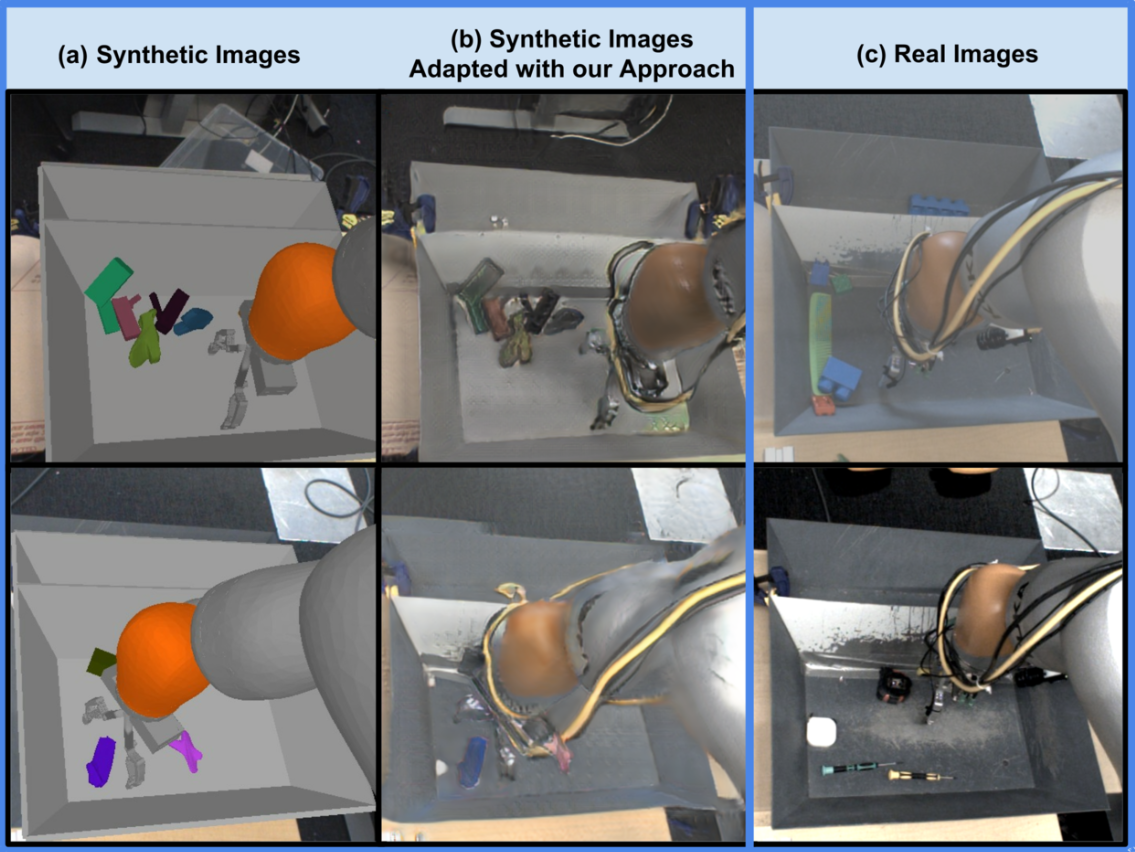
Using Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping (2018)
Generative adversarial networks for specular highlight removal in endoscopic images
https://doi.org/10.1117/12.2293755

Deep learning with domain adaptation for accelerated projection‐reconstruction MR (2017)
Synthetic Data Augmentation using GAN for Improved Liver Lesion Classification (2018)
GAN Augmentation: Augmenting Training Data using Generative Adversarial Networks (2018)
Abdominal multi-organ segmentation with organ-attention networks and statistical fusion (2018)
Prior-aware Neural Network for Partially-Supervised Multi-Organ Segmentation (2019)


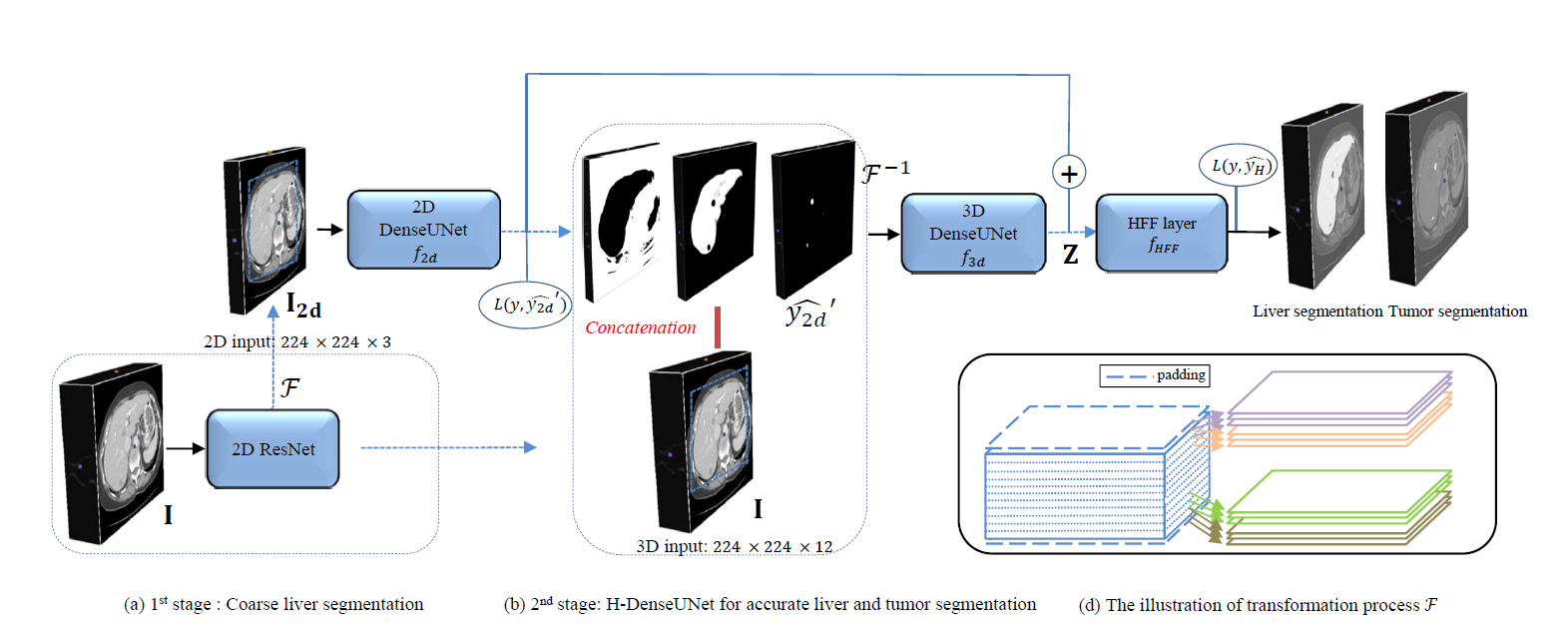
2019 - H-DenseUNet: Hybrid Densely Connected UNet for Liver and Tumor Segmentation from CT Volumes
2020 - [TorchIO]: a Python library for efficient loading, preprocessing, augmentation and patch-based sampling of medical images in deep learning [github]
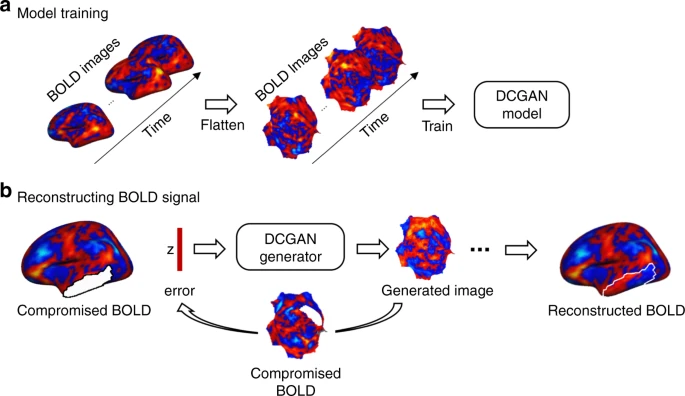
2020 - Reconstructing lost BOLD signal in individual participants using deep machine learning
Low-dose X-ray tomography through a deep convolutional neural network https://www.nature.com/articles/s41598-018-19426-7
In synchrotron-based XRT, CNN-based processing improves the SNR in the data by an order of magnitude, which enables low-dose fast acquisition of radiation-sensitive samples
2014 - Do Convnets Learn Correspondence?

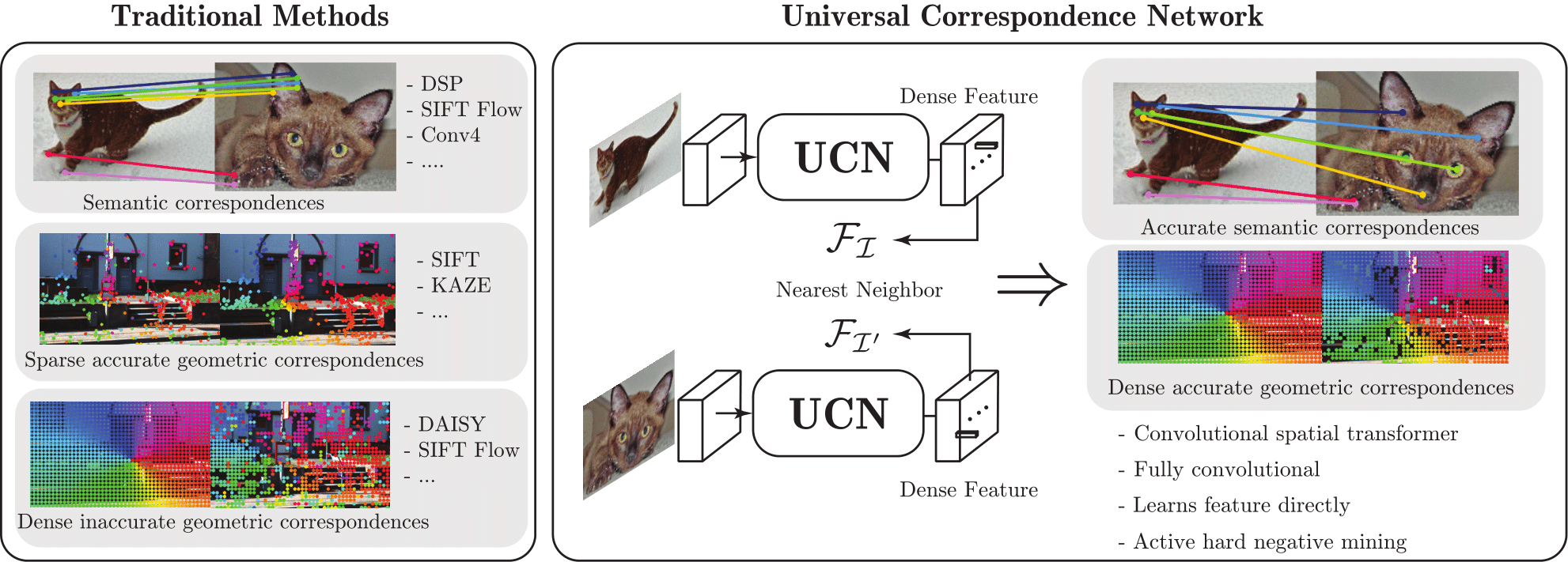
2016 - Universal Correspondence Network
We present a deep learning framework for accurate visual correspondences and demonstrate its effectiveness for both geometric and semantic matching, spanning across rigid motions to intra-class shape or appearance variations. In contrast to previous CNN-based approaches that optimize a surrogate patch similarity objective, we use deep metric learning to directly learn a feature space that preserves either geometric or semantic similarity. Our fully convolutional architecture, along with a novel correspondence contrastive loss allows faster training by effective reuse of computations, accurate gradient computation through the use of thousands of examples per image pair and faster testing with O(n) feed forward passes for n keypoints, instead of O(n2) for typical patch similarity methods. We propose a convolutional spatial transformer to mimic patch normalization in traditional features like SIFT, which is shown to dramatically boost accuracy for semantic correspondences across intra-class shape variations. Extensive experiments on KITTI, PASCAL, and CUB-2011 datasets demonstrate the significant advantages of our features over prior works that use either hand-constructed or learned features.
2016 - Learning Dense Correspondence via 3D-guided Cycle Consistency
Discriminative deep learning approaches have shown impressive results for problems where human-labeled ground truth is plentiful, but what about tasks where labels are difficult or impossible to obtain? This paper tackles one such problem: establishing dense visual correspondence across different object instances. For this task, although we do not know what the ground-truth is, we know it should be consistent across instances of that category. We exploit this consistency as a supervisory signal to train a convolutional neural network to predict cross-instance correspondences between pairs of images depicting objects of the same category. For each pair of training images we find an appropriate 3D CAD model and render two synthetic views to link in with the pair, establishing a correspondence flow 4-cycle. We use ground-truth synthetic-to-synthetic correspondences, provided by the rendering engine, to train a ConvNet to predict synthetic-to-real, real-to-real and real-to-synthetic correspondences that are cycle-consistent with the ground-truth. At test time, no CAD models are required. We demonstrate that our end-to-end trained ConvNet supervised by cycle-consistency outperforms state-of-the-art pairwise matching methods in correspondence-related tasks.

2017 - Convolutional neural network architecture for geometric matching[github]
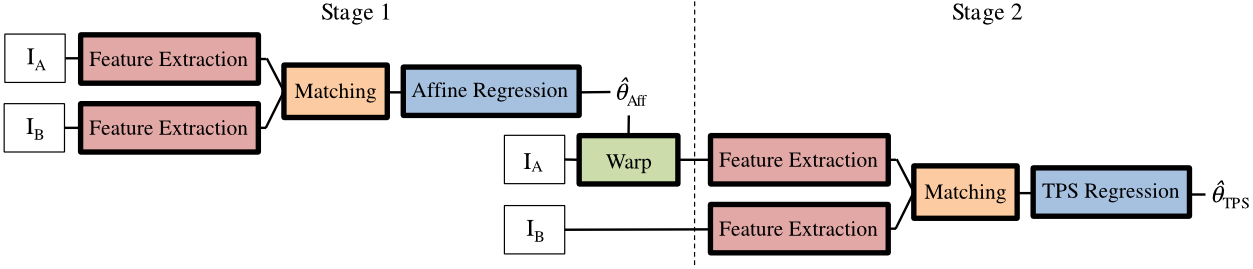
2018 - [DGC-Net]: Dense Geometric Correspondence Network [github]

2018 - An Unsupervised Learning Model for Deformable Medical Image Registration
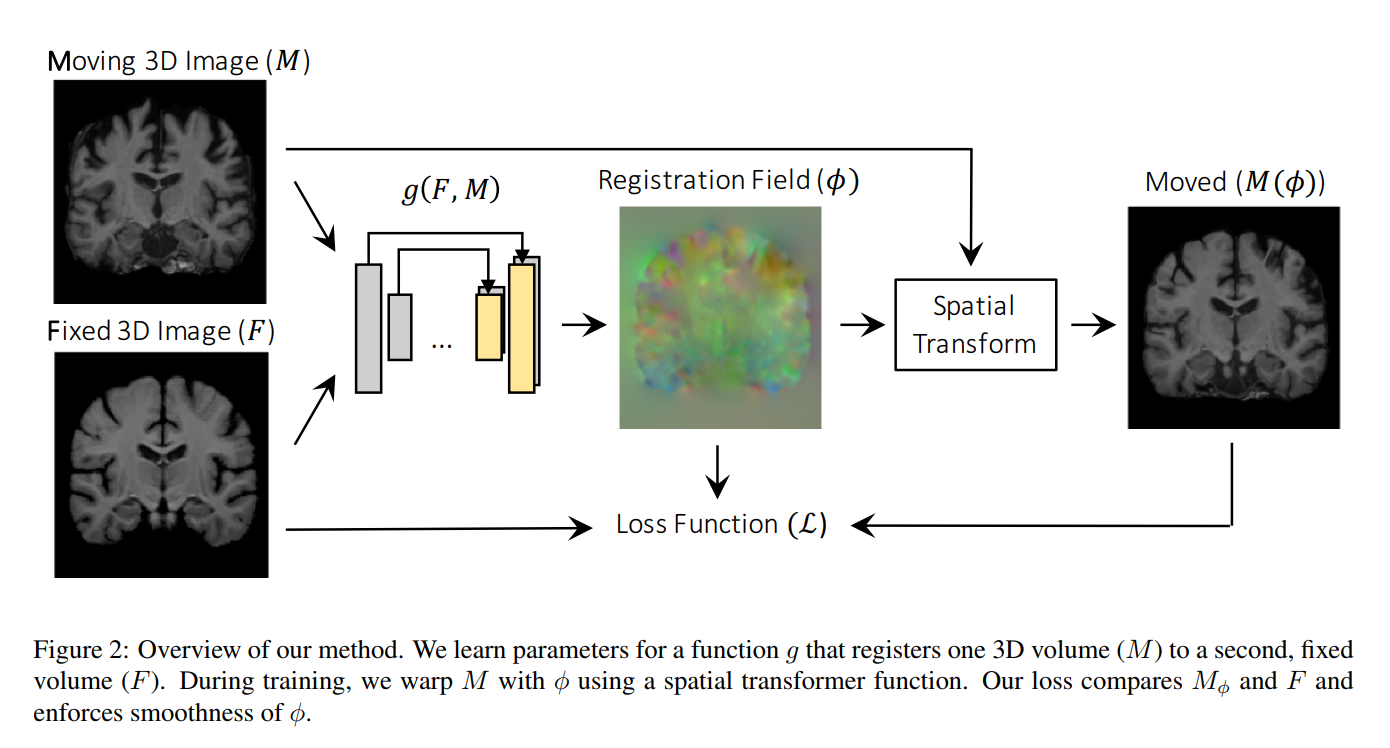
2018 - VoxelMorph: A Learning Framework for Deformable Medical Image Registration [github]

2019 - A Deep Learning Framework for Unsupervised Affine and Deformable Image Registration

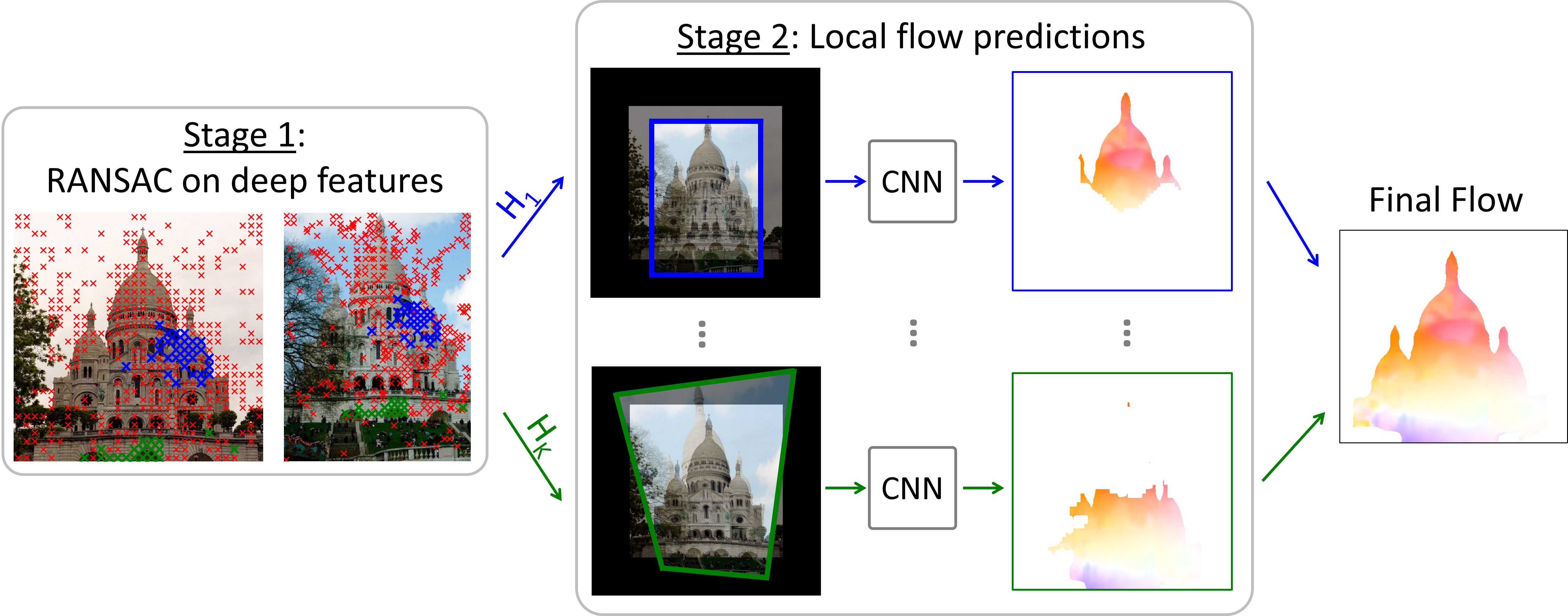
2020 - RANSAC-Flow: generic two-stage image alignment
Flow-Guided Feature Aggregation for Video Object Detection https://arxiv.org/abs/1703.10025
Deep Feature Flow for Video Recognition https://arxiv.org/abs/1611.07715
Video-to-Video Synthesis (2018) [github]
2017 - "Zero-Shot" Super-Resolution using Deep Internal Learning

2018 - Residual Dense Network for Image Restoration [github]

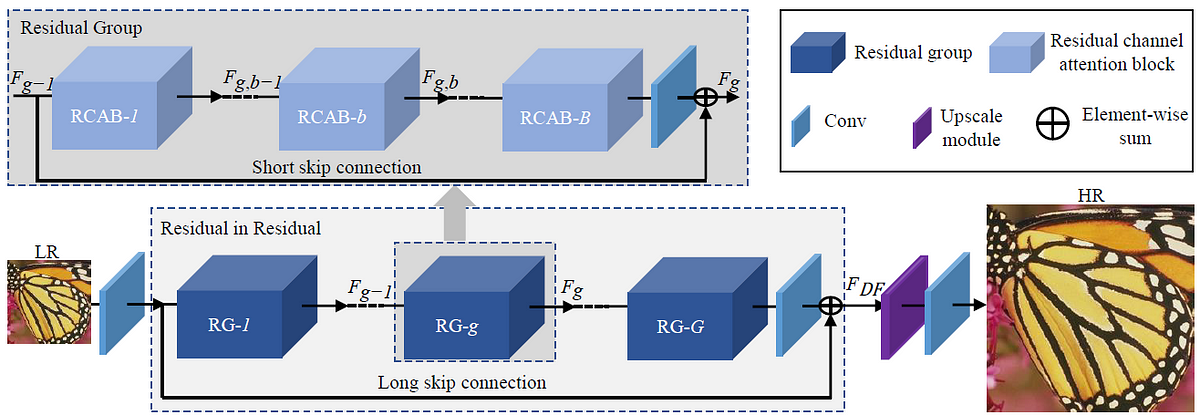
2018 - Image Super-Resolution Using Very Deep Residual Channel Attention Networks
2018 - Image Inpainting for Irregular Holes Using Partial Convolutions[github official], [github]

2017 - Globally and Locally Consistent Image Completion[github]

2017 - Generative Image Inpainting with Contextual Attention[github]

2018 - Free-Form Image Inpainting with Gated Convolution

Photo-realistic single image super-resolution using a generative adversarial network (2016)[github]

A Closed-form Solution to Photorealistic Image Stylization (2018)[github]

[pix2code]: Generating Code from a Graphical User Interface Screenshot [github]

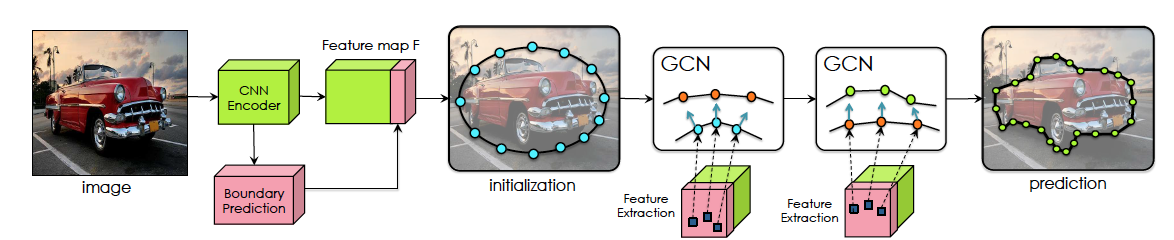
Fast Interactive Object Annotation with Curve-GCN (2019)
2017 - Learning Fashion Compatibility with Bidirectional LSTMs[github]

2020 - A Systematic Literature Review on the Use of Deep Learning in Software Engineering Research
Caffe: Convolutional Architecture for Fast Feature Embedding
Tune: A Research Platform for Distributed Model Selection and Training (2018) [github]
Glow: Compiler for Neural Network hardware accelerators

Lucid: A collection of infrastructure and tools for research in neural network interpretability
PySyft: A generic framework for privacy preserving deep learning [github]
Crypten: A framework for Privacy Preserving Machine Learning [github]
[Snorkel]: Programmatically Building and Managing Training Data
[Netron ] Visualizer for deep learning and machine learning models
[Interactive Tools] for ML, DL and Math
2016 - An Analysis of Deep Neural Network Models for Practical Applications
2017 - Revisiting Unreasonable Effectiveness of Data in Deep Learning Era
2019 - High-performance medicine: the convergence of human and artificial intelligence
2020 - Maithra Raghu, Eric Schmidt. A Survey of Deep Learning for Scientific Discovery
2016 - Building Machines That Learn and Think Like People
2016 - A Berkeley View of Systems Challenges for AI
2018 - Deep Learning: A Critical Appraisal
2018 - Human-level intelligence or animal-like abilities?
2019 - Deep Nets: What have they ever done for Vision?
This is an opinion paper about the strengths and weaknesses of Deep Nets for vision. They are at the center of recent progress on artificial intelligence and are of growing importance in cognitive science and neuroscience. They have enormous successes but also clear limitations. There is also only partial understanding of their inner workings. It seems unlikely that Deep Nets in their current form will be the best long-term solution either for building general purpose intelligent machines or for understanding the mind/brain, but it is likely that many aspects of them will remain. At present Deep Nets do very well on specific types of visual tasks and on specific benchmarked datasets. But Deep Nets are much less general purpose, flexible, and adaptive than the human visual system. Moreover, methods like Deep Nets may run into fundamental difficulties when faced with the enormous complexity of natural images which can lead to a combinatorial explosion. To illustrate our main points, while keeping the references small, this paper is slightly biased towards work from our group.
2020 - State of AI Report 2020
2018 - When Will AI Exceed Human Performance? Evidence from AI Experts

2018 - The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation

