經過softmax運算
=
- gamma负责降低简单样本的损失值, 以解决加总后负样本loss
- alpha调和正负样本的不平均,如果设置0.25, 那么就表示负样本为0.75, 对应公式
控制样本权重的为
当p_t越大,赋予的权重就越小, p_t越小,赋予的权重就越大
基于原来多分类損失函數CrossEntropy进行改进,最初one-stage目标检测框架有easy-example(背景) 和 hard-example(前景)严重样本分布不均的问题,往往easy-example的loss与hard-example的存在极大的不平衡(1:1000),导致模型都在学习easy-example而忽略了hard-example
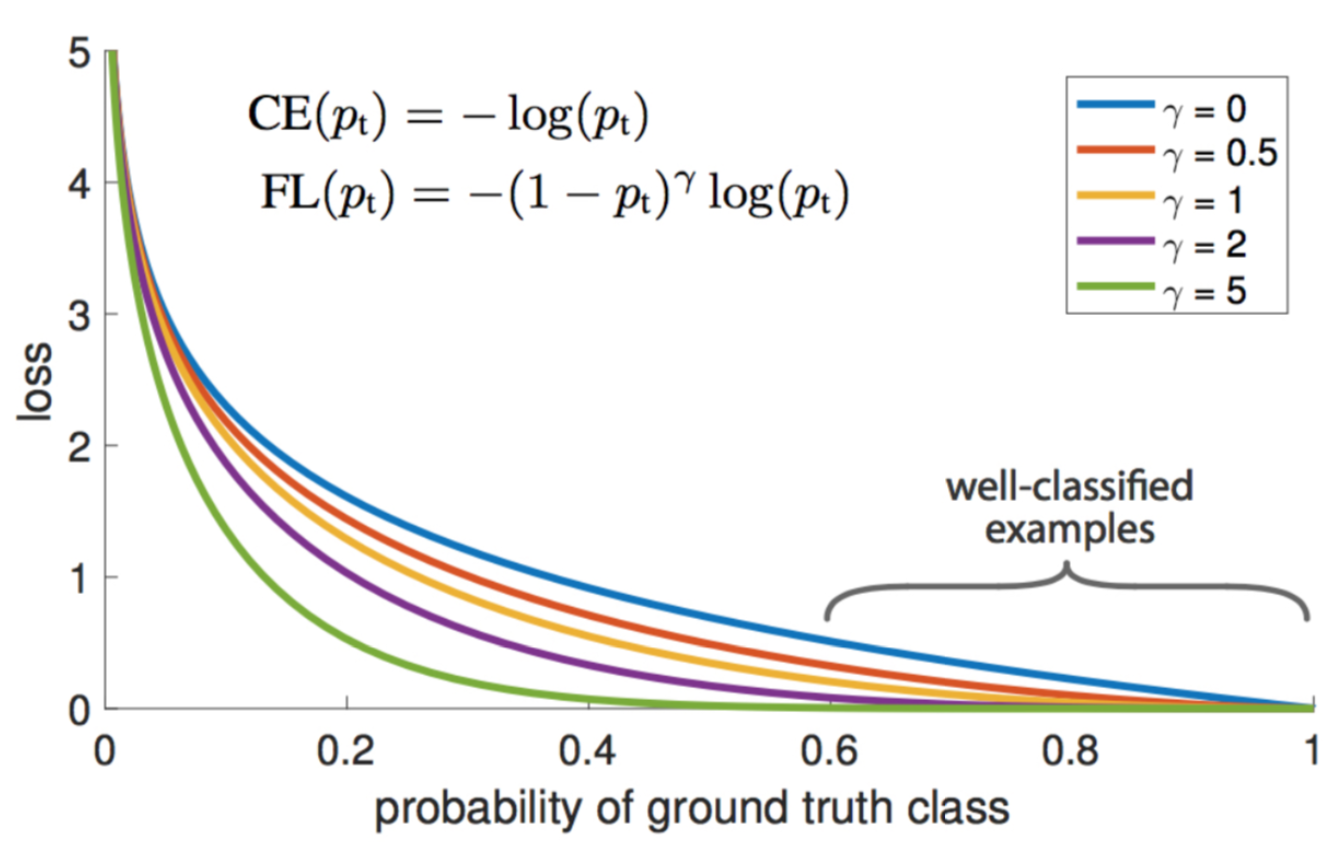
根据图表,基于CE的公式, 提出了新的因子 , 当 gamma 值>0, 减低了easy_example(pt>0.5)的loss值,因此模型能够更专注在学习hard_example
PS. 作者发现 gamma 的初始值2为最佳
假设我们模型分类负样本10000笔资料,probability(pt) = 0.95, 这边可以理解为easy-example因为概率高
正样本10笔资料, probability(pt) = 0.05, 可以理解为hard-example 概率低
直接带入CE和FL
-
带入CrossEntropy
- 负样本 : log(p_t) * 样本数(100000) = 0.02227 * 100000 = 2227 - 正样本 : log(p_t) * 样本数(10) = 1.30102 * 10 = 13.0102 total loss = 2227+13.0102 = 2240 正样本占比:13.0102 / 2240 = 0.0058
- 带入Focalloss
假设alpha = 0.25(正样本, gamma=2
- 负样本 : 0.75*(1-0.95)^2 * 0.02227 *样本数(100000) = 0.00004176 * 100000 = 4.1756
- 正样本 : 0.25* (1-0.05)^2 * 1.30102 *样本数(10)= 0.29354264 * 10 = 2.935
total loss = 4.175 + 2.935 = 7.110
正样本占比:2.935/7.110 = 0.4127(与0.0058差距甚大)
- gamma = 2时候, 负样本
= 0.0025, 正样本
= 0.9025, 负样本损失值明显比正样本小很多
- alpha与gamma是一种相互平衡的值,虽然就理论上来看,alpha值设定为0.75(因为正样本通常数量小)是比较合理, 但是配合gamma值已经将负样本损失值降低许多,可理解为alpha和gamma相互牵制,alpha也不让正样本占比太大,因此最终设定为0.25
论文连接 https://arxiv.org/abs/1708.02002
pytorch源碼实践 https://github.com/marvis/pytorch-yolo2/blob/master/FocalLoss.py

