Comments (12)
 madolson
commented on May 25, 2024
2
madolson
commented on May 25, 2024
2
@touitou-dan was still working on this with @uriyage. I'm planning on syncing with them internally to see what their status is and how we can port the changes here.
from valkey.
 PingXie
commented on May 25, 2024
1
PingXie
commented on May 25, 2024
1
Yeah I will take a look. Btw, a few of us are at the Linux open source summit this week so our response would be a bit slower than usual.
from valkey.
PingXie
commented on May 25, 2024
1
Maybe we could do some prefetch before this line
My understanding is that the slow access is a result of d->ht_table[table][idx] but since it depends on the idx value computed on the line right above, and then the value (he) is used right after, it is not clear to me with which operations we could run the prefetching in parallel?
idx = h & DICTHT_SIZE_MASK(d->ht_size_exp[table]);
he = d->ht_table[table][idx];
while(he) {a new function like dictFindBatch to handle the prefetch work?
Yeah, I also think this will increase the cache hit rate.
from valkey.
 kamulos
commented on May 25, 2024
kamulos
commented on May 25, 2024
We are developing an application that went through a series of big architectural changes. Initially it was many threads, each with its own Redis connection.
-
The first big improvement was switching to Rust (
redis-rs), where in each process the Requests of many concurrent async tasks are routed through a single TCP connection. This works incredibly well, but there is a bit of fear left in terms of head-of-line blocking. The other issue #17 proposed using QUIC. It is a complexity beast, but maybe it fits the use-case well. -
At some point we started collecting requests on the client side for a few microseconds and then sending them as a batch to Redis. This basically doubled the throughput (at the expense of latency). I'll leave the interpretation of this to the experts, but we were really surprised about the big improvement.
-
No we are using Cluster, and the throughput of a single DB instance does not matter that much anymore. But any improvement that is made here, we will try to get into reality in our product.
from valkey.
 mattsta
commented on May 25, 2024
mattsta
commented on May 25, 2024
I think there's a divide between two basic use cases which changes development priorities:
- people who just want a cache and don't truly care about performance or implementation as long as "it just works"
- people who want to do things like a billion requests per second on a 1U 168-core machine with 3 TB RAM (this machine costs about $70k today) connected in a terabit converged ethernet mesh.
Most of the "Redis panic" is around hosting providers just wanting to continue servicing easy use cases, but there's a lot of room for "bug fixes and performance enhancements" too for much more advanced use cases.
Let me continue bringing up the work I've spent 10,000 hours implementing most of these fixes already, but I'm afraid to release publicly because if I see more of my high performance code get deployed on tens of millions of computers without compensation I'll just have to walk into the ocean.
db rewrite details: https://matt.sh/best-database-ever
data structure improvement details: https://matt.sh/trillion-dollar-data-structure
un-maintained demo site with some entry-level docs: https://carrierdb.cloud/
from valkey.
 lipzhu
commented on May 25, 2024
lipzhu
commented on May 25, 2024
Really look forward to this io-threads refactor, speaking of the io-thread, I have an optimization #111 which changed strategy from the threshold to decay rate when enable/disable io-threads, this can help both from high core count and CPU efficiency perspectives. @valkey-io/core-team, do you mind helping this #111 first before io-thread refactor?
Dictionary memory access
BTW, I also noticed the memory latency before, below is the disassembly code of dictFind, we can see the memory access instruction contribute the most cycles, the corresponding code is https://github.com/valkey-io/valkey/blob/unstable/src/dict.c#L743. Maybe we could do some prefetch before this line and a new function like dictFindBatch to handle the prefetch work?

from valkey.
PingXie
commented on May 25, 2024
@lipzhu, I am still waiting for the detailed design. Here is my understanding of what we are trying to achieve here (but @madolson @touitou-dan can let me know if I am mistaken). With this proposal,
- We will have per-thread epoll loop
- As a result, user connections will be affinitized to the worker thread
- If the connection is ready for read
a. read from the socket
b. parse the command into the executable format (argv[] array)
c. add the parsed command to a global command queue - there will be a main thread, which pulls the commands queued in step 3.c, executes them (in batches potentially to take advantage of the parallel execution enabled by the CPU), generates the output (an array of robj?) but don't encode the output, and finally queues the output (array) into the per connection output queue.
a. we will also queue the parsed/rewritten commands for replication to the output queue associated with the replication connection - If the connection is ready for write
a. pulls the output array out of the corresponding connection queue
b. encodes it into the output buffer
c. releases the args and output arrays
IF this is the proposal (even with just step 1 and 2), I don't see the optimization proposed in #111 getting carried over.
from valkey.
lipzhu
commented on May 25, 2024
@PingXie Maybe I confused you, #111 is inspired from redis/redis#12305 (comment).
For existing io-threads implementation, user may found that with the same client requests pressure, server with more CPU allocated and io-threads number configured have lower QPS than server with little io-threads configured, this doesn't make sense. Test scenario is updated in #111 (comment)
from valkey.
mattsta
commented on May 25, 2024
Those are all logical steps. Very similar to when I worked out a multi-threaded archietcture a couple years ago:
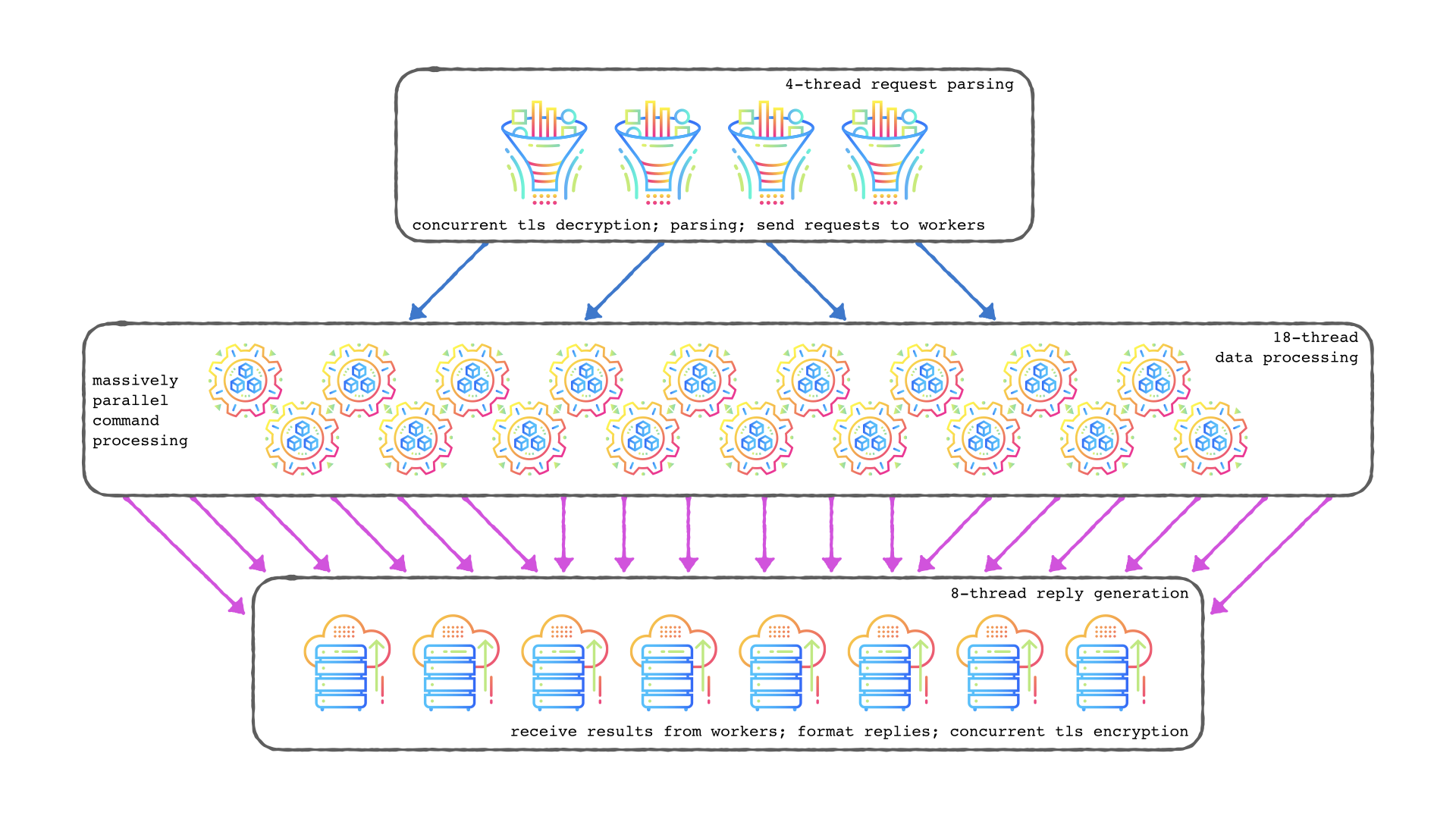
Be careful though because eventually you just end up implementing a full programming language virtual machine to solve the problem.
You'll end up with a full internal bytecode/IR mapping for translating all client commands into more detailed internal features because you need to manage: command distribution, a work queue, letting some workers sleep (so then you also need to implement a scheduler), then the replies have to be happy; then you also have to check if your TLS library supports isolating readers and writers concurrently or if you have to lock them all down simultaneously, etc.
from valkey.
PingXie
commented on May 25, 2024
@PingXie Maybe I confused you, #111 is inspired from redis/redis#12305 (comment).
For existing io-threads implementation, user may found that with the same client requests pressure, server with more CPU allocated and io-threads number configured have lower QPS than server with little io-threads configured, this doesn't make sense. Test scenario is updated in #111 (comment)
Understood. I was thinking more along the line of "longevity" for #111. From a quick look at the PR, I think it is pretty contained and the change makes sense to me. If it doesn't increase our tech debts (which doesn't look like the case right now), I agree it makes sense to continue improving the status quo. I will take a close look at #111 next.
from valkey.
PingXie
commented on May 25, 2024
Be careful though because eventually you just end up implementing a full programming language virtual machine to solve the problem.
Good point @mattsta. I wonder if there is a way to materialize this proposal in phases. We will need a more concrete design first.
from valkey.
lipzhu
commented on May 25, 2024
@PingXie Maybe I confused you, #111 is inspired from redis/redis#12305 (comment).
For existing io-threads implementation, user may found that with the same client requests pressure, server with more CPU allocated and io-threads number configured have lower QPS than server with little io-threads configured, this doesn't make sense. Test scenario is updated in #111 (comment)Understood. I was thinking more along the line of "longevity" for #111. From a quick look at the PR, I think it is pretty contained and the change makes sense to me. If it doesn't increase our tech debts (which doesn't look like the case right now), I agree it makes sense to continue improving the status quo. I will take a close look at #111 next.
Look forward to your help :)
from valkey.
Related Issues (20)
- Introduce PR templates HOT 3
- Hoping for Valkey "Cluster" architecture option HOT 3
- [NEW] add a management-port HOT 13
- [BUG] - Coverage target fails to build because of failing test HOT 4
- [NEW] Add eol data to endoflife.date HOT 2
- [NEW] Add keyspace_hit_ratio metric in info stats
- [Feature-Request]: Cross-Slot Command Execution in ValKey Cluster HOT 2
- [NEW] Support for Active/Active replication HOT 6
- [NEW] Compacting the output of topology commands for for fragmented clusters HOT 1
- Revert mmap_rnd bits back to default value
- [NEW] Support different bind addresses for plain TCP and TLS port
- Deprecate MacOS 11 build target
- New MPUBLISH command to publish multiple messages. HOT 5
- Replace CentOS 7 image with CentOS Stream 9 HOT 1
- Handling edge cases on connSet(Read/Write)Handler
- Validate format of YAML files HOT 2
- [Improvement][Cluster Mode] Remove Unowned Keys After Loading Persistence Files At Server Startup HOT 3
- [NEW] Limit maximum size on disk of AOF files. Avoid disk full, long load times.
- [BUG] Inaccurate total_active_defrag_time calculation?
- [LEGAL] Please remove my copyright notice from the source code HOT 6
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from valkey.