Comments (28)
 rafaelvalle
commented on May 23, 2024
3
rafaelvalle
commented on May 23, 2024
3
replace .byte() with .bool()
https://github.com/NVIDIA/flowtron/blob/master/flowtron.py#L33
from flowtron.
rafaelvalle
commented on May 23, 2024
3
Try adding your speaker to the pre-trained LJS and LibriTTS, fine-tune them and evaluate which sounds better on your data by looking at the validation loss on your data.
from flowtron.
rafaelvalle
commented on May 23, 2024
1
Combine your speaker with data from other speakers and train again.
Can you share inference mel-spectrograms and alignment plots for your speaker with your fine-tuned model?
from flowtron.
 KingStorm
commented on May 23, 2024
1
KingStorm
commented on May 23, 2024
1
@rafaelvalle Thanks. Yes, I got the idea now. it was indeed a display issue, since I was working on LJS data and got reasonable voice quality. And some of gate display has that value 1.
from flowtron.
 wietsedv
commented on May 23, 2024
wietsedv
commented on May 23, 2024
It does not work properly with the latest PyTorch version (I have not searched for exact problems yet). PyTorch 1.0.0 works for me. I have some edge case problems with 1.0.1 so I would install 1.0.0.
from flowtron.
 asmodaay
commented on May 23, 2024
asmodaay
commented on May 23, 2024
ty, i will try!
from flowtron.
asmodaay
commented on May 23, 2024
replace .byte() with .bool()
https://github.com/NVIDIA/flowtron/blob/master/flowtron.py#L33
This helps me, and i got this attention plot, but inference samples on this speaker doesnt have any meaningful speech. Is attention ok?
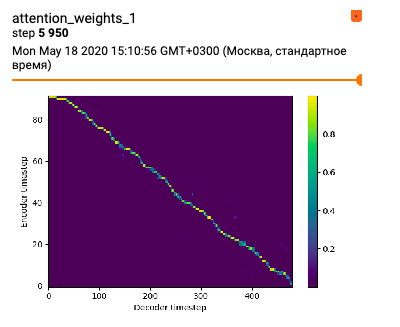
from flowtron.
rafaelvalle
commented on May 23, 2024
This attention plot looks really good!
Can you show both attention layers? This is only layer 1.
from flowtron.
asmodaay
commented on May 23, 2024
This attention plot looks really good!
Can you show both attention layers? This is only layer 1.
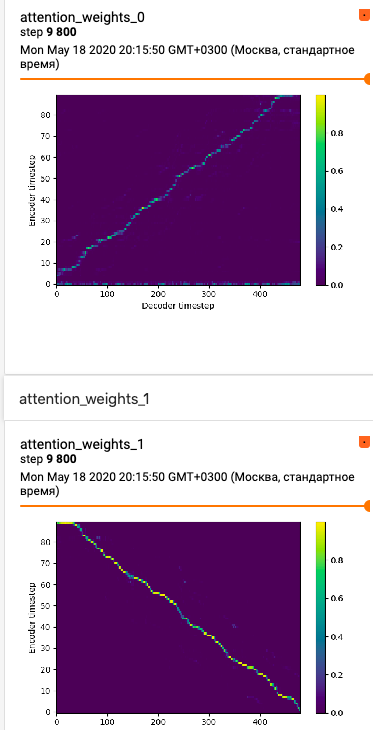
I have ok quality on LJ speaker and shit quality on my own speaker(~60 min data)
from flowtron.
rafaelvalle
commented on May 23, 2024
Both alignment plots look good.
Can you perform inference on your speaker and share the alignment plots and audio?
from flowtron.
asmodaay
commented on May 23, 2024

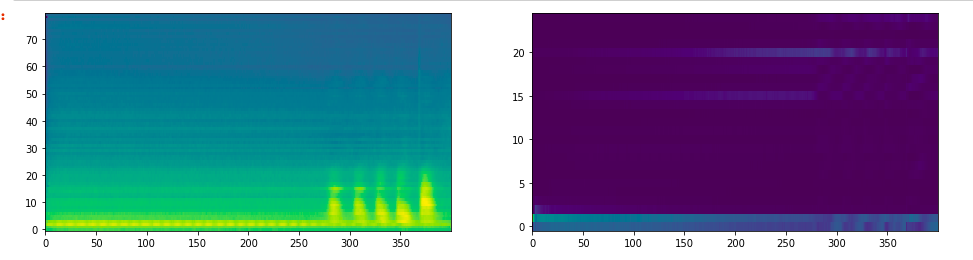
samples.zip
Here is 2 sample with lj speaker and another
1st plot lj
2nd not lj
from flowtron.
rafaelvalle
commented on May 23, 2024
Looks like the model hasn't learned to attend on your speaker.
from flowtron.
asmodaay
commented on May 23, 2024
Looks like the model hasn't learned to attend on your speaker.
Do u have any ideas how to fix it? more data or smth like that, ill try to add my speaker in libri group and finetune lj checkpoint
from flowtron.
 daun-io
commented on May 23, 2024
daun-io
commented on May 23, 2024
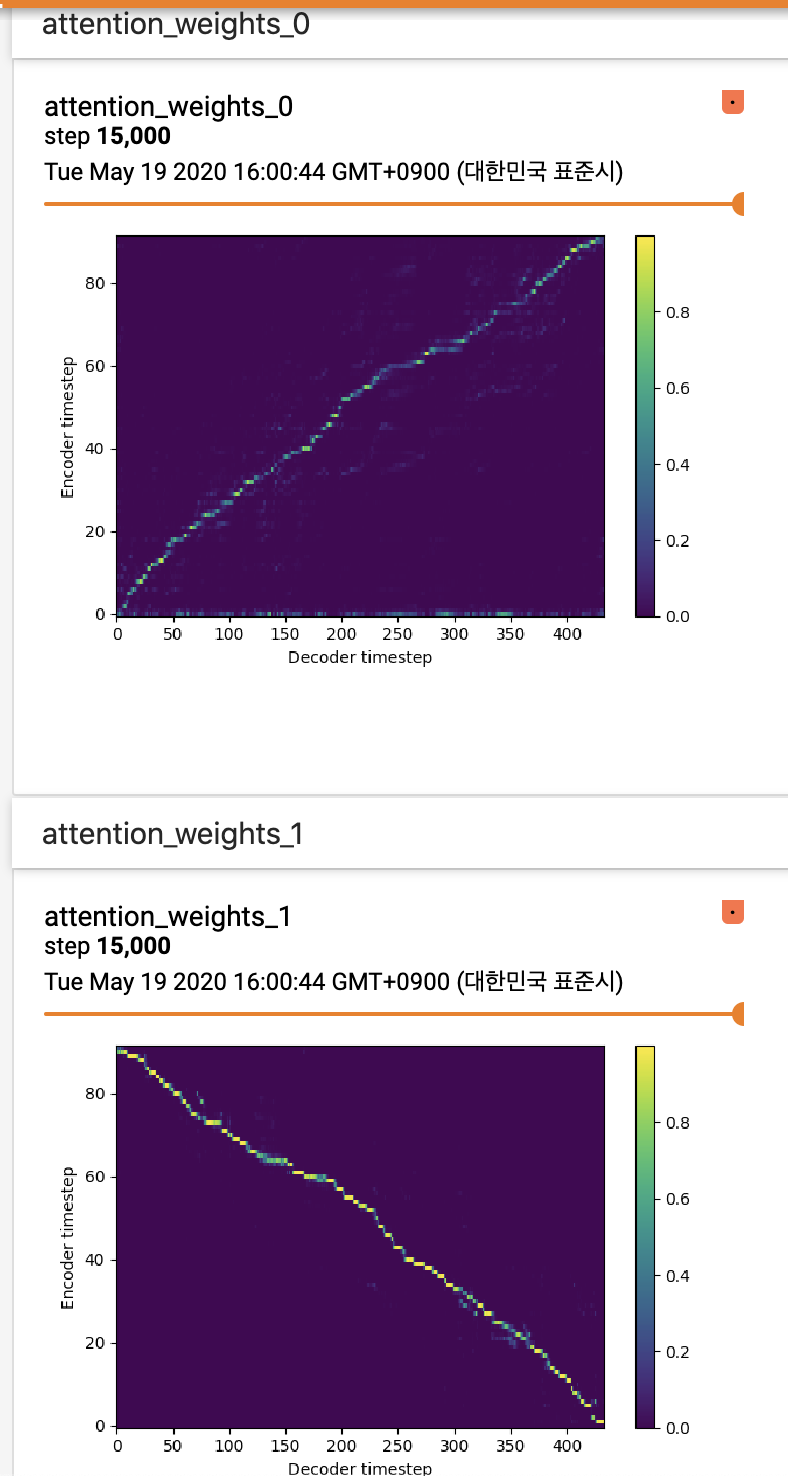
I'm currently training my own data (~2hrs) from LibriTTS pretrained model and looks like the model hasn't learned to attend yet too.


This is my configuration.
{
"train_config": {
"output_directory": "/some_output_directory/",
"epochs": 10000000,
"learning_rate": 1e-4,
"weight_decay": 1e-6,
"sigma": 1.0,
"iters_per_checkpoint": 5000,
"batch_size": 4,
"seed": 1234,
"checkpoint_path": "/some_checkpoint_path/",
"ignore_layers": [],
"include_layers": ["speaker", "encoder", "embedding"],
"warmstart_checkpoint_path": "",
"with_tensorboard": true,
"fp16_run": true
},
"data_config": {
"training_files": "../../path_to_datasets/train_filelist.txt",
"validation_files": "../../path_to_datasets/val_filelist.txt",
"text_cleaners": ["flowtron_cleaners"],
"p_arpabet": 0.5,
"cmudict_path": "data/cmudict_dictionary",
"sampling_rate": 22050,
"filter_length": 1024,
"hop_length": 256,
"win_length": 1024,
"mel_fmin": 0.0,
"mel_fmax": 8000.0,
"max_wav_value": 32768.0
},
"dist_config": {
"dist_backend": "nccl",
"dist_url": "tcp://localhost:54321"
},
"model_config": {
"n_speakers": 1,
"n_speaker_dim": 128,
"n_text": 185,
"n_text_dim": 512,
"n_flows": 2,
"n_mel_channels": 80,
"n_attn_channels": 640,
"n_hidden": 1024,
"n_lstm_layers": 2,
"mel_encoder_n_hidden": 512,
"n_components": 0,
"mean_scale": 0.0,
"fixed_gaussian": true,
"dummy_speaker_embedding": false,
"use_gate_layer": true
}
}
from flowtron.
rafaelvalle
commented on May 23, 2024
Rule of thumb is to train the model until it starts overfitting or the loss plateaus.
from flowtron.
daun-io
commented on May 23, 2024
Yeah I have trained several tacotron 2 networks(nvidia implementation) before with pretrained models and my own datasets. I tend to see the trend that since my dataset is relatively small (~1hours or ~2hours) the validation loss shows overfitting in very early stage of training (like 1k steps). However the results generated by the model tends to get better even after overfitting is started and the alignments looked fine.
In this training I found that flowtron model also overfits really fast (like in several thousand steps) and in that stage of training the model couldn't really reconstruct the features of my datasets. When I test the overfitted model (trained more than 100k steps) it shows poor results on alignment for new sentences. Is there any empirical way to figure this out?
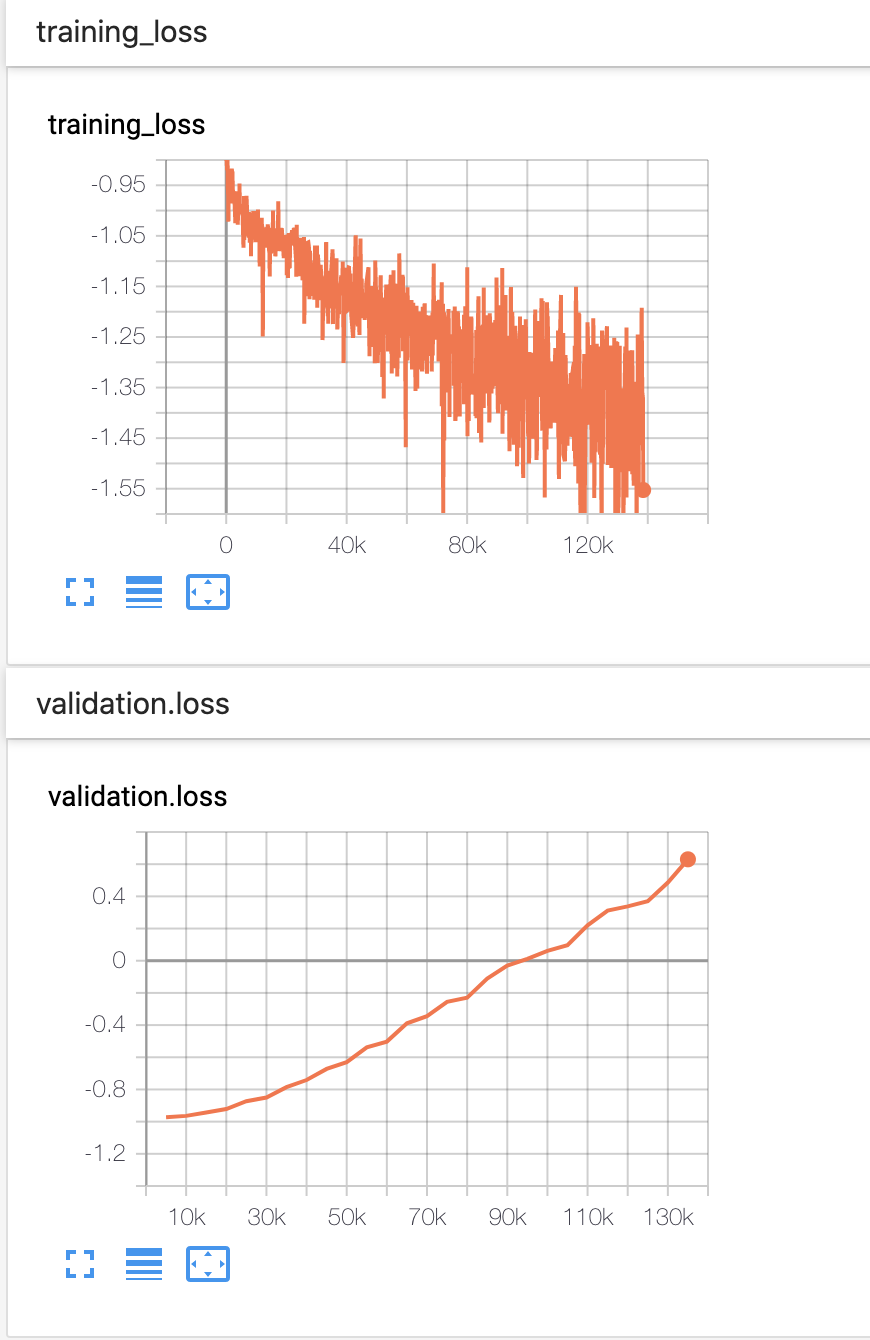
from flowtron.
daun-io
commented on May 23, 2024
I've currently combined my speaker data with libritts-100 and training it from scratch without pretrained model with batch size of 1 and I haven't seen any sign of alignments from the results yet.
Do you know the empirical steps or epochs needed to see the alignments from tensorboard?
And here's my previous model's (the one adaptated from the pretrained model) mel-spectrograms and alignment plots.
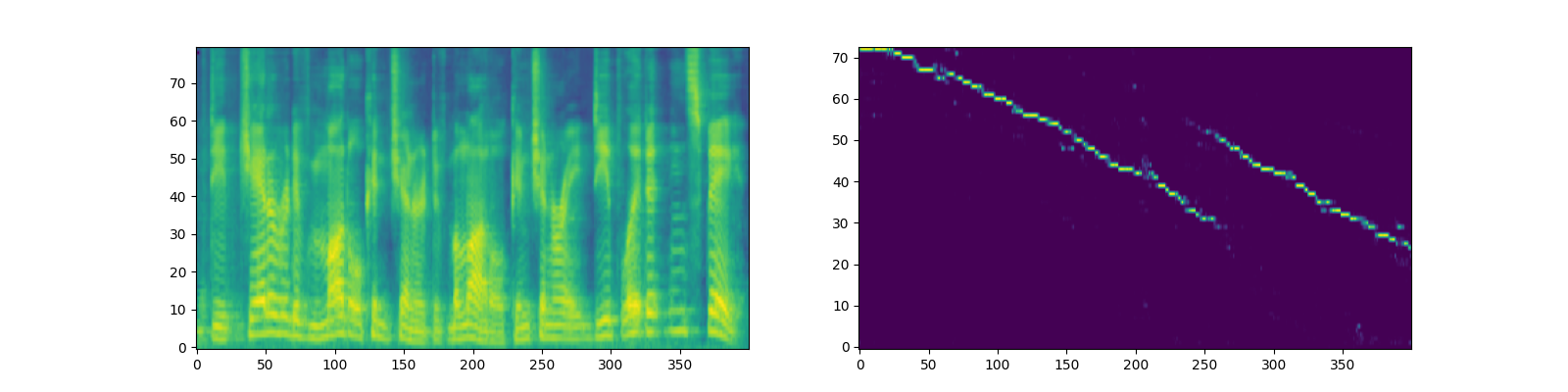

You can also hear it, The sentence is "It is well know that deep generative models have a deep latent space!"
sid0_sigma0.5.wav.zip
from flowtron.
daun-io
commented on May 23, 2024
Thank you for helping me rafael :) I've read your paper again and finally understood that the model requires long amount of time and resource (1000 Epochs for NVIDIA's proprietary datasets and 500 epochs for LibriTTS datasets to adapt) to check the best results and I was too impatient!
from flowtron.
 singhaki
commented on May 23, 2024
singhaki
commented on May 23, 2024
Hi, i tried to train model with only LJ data, and with only own data, with fp16 and with fr32, with 1 gpu and with 3 gpu, but everywhere i have this
Always los is Nan.
When i start with pretrained chekpoint your code return this:
I solve it by changingdef load_checkpoint, but loss is nan(do u have any ideas what am i doing wrong?


how did you solve the key error? as in pretrained model only state_dict is present and not these
{'model': model_for_saving,
'iteration': iteration,
'optimizer': optimizer.state_dict(),
'learning_rate': learning_rate}
from flowtron.
 CookiePPP
commented on May 23, 2024
CookiePPP
commented on May 23, 2024
This works 🤷♂️
if 'optimizer' in checkpoint_dict.keys(): optimizer.load_state_dict(checkpoint_dict['optimizer'])
if 'amp' in checkpoint_dict.keys(): amp.load_state_dict(checkpoint_dict['amp'])
if 'learning_rate' in checkpoint_dict.keys(): learning_rate = checkpoint_dict['learning_rate']
if 'hparams' in checkpoint_dict.keys(): hparams = checkpoint_dict['hparams']
if 'best_validation_loss' in checkpoint_dict.keys(): best_validation_loss = checkpoint_dict['best_validation_loss']
if 'average_loss' in checkpoint_dict.keys(): average_loss = checkpoint_dict['average_loss']
if 'iteration' in checkpoint_dict.keys(): iteration = checkpoint_dict['iteration']
from flowtron.
asmodaay
commented on May 23, 2024
Hi, i tried to train model with only LJ data, and with only own data, with fp16 and with fr32, with 1 gpu and with 3 gpu, but everywhere i have this
Always los is Nan.
When i start with pretrained chekpoint your code return this:
I solve it by changingdef load_checkpoint, but loss is nan(
do u have any ideas what am i doing wrong?how did you solve the key error? as in pretrained model only state_dict is present and not these
{'model': model_for_saving,
'iteration': iteration,
'optimizer': optimizer.state_dict(),
'learning_rate': learning_rate}
Also u can use this:

from flowtron.
rafaelvalle
commented on May 23, 2024
@singhaki you need to change this line such that the function returns an object of type bool instead of byte.
mask = (ids < lengths.unsqueeze(1)).bool()
from flowtron.
KingStorm
commented on May 23, 2024

Is it normal for the target gate always being 0? I suppose it would be something like voice activity detection tag: [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 ....... 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
from flowtron.
rafaelvalle
commented on May 23, 2024
There should be one value equal to 1.
Can you confirm on the data itself? It could be a plotting issue.
from flowtron.
rafaelvalle
commented on May 23, 2024
@asmodaay adding your speaker to LibriTTS sounds like a good idea. let us know how it goes.
from flowtron.
rafaelvalle
commented on May 23, 2024
Closing due to inactivity. Please re-open if needed.
from flowtron.
 blx0102
commented on May 23, 2024
blx0102
commented on May 23, 2024
@asmodaay adding your speaker to LibriTTS sounds like a good idea. let us know how it goes.
@rafaelvalle Sorry for adding comment in the closed issue. I'm just confused how to deal with the speaker embedding when "adding speaker to LibriTTS". Should I just put the speaker embedding into the ignore layers?
from flowtron.
 serg06
commented on May 23, 2024
serg06
commented on May 23, 2024
replace .byte() with .bool()
https://github.com/NVIDIA/flowtron/blob/master/flowtron.py#L33
@rafaelvalle This fixed the issue for me with FP16 disabled, but when I enabled FP16 my training loss becomes NaN again.
Edit: Latest code seems to work for me even with FP16 enabled!
from flowtron.
Related Issues (20)
- Inference starting repeat itself. HOT 5
- List index out of range
- Request for clarification on some of the readme scripts. HOT 8
- Custom model resumed from pre-trained model has a stuttering problem.
- How would one keep the model loaded for immediate synthesis? HOT 17
- Inference on pre-trained model (flowtron_ljs) speaking nonsense. HOT 4
- Inference Demo "Hitting gate limit" HOT 2
- .
- inference speed on CPU
- Accelerated inference with TensorRT HOT 2
- Single word input leads to ValueError: Expected more than 1 spatial element when training, got input size torch.Size([1, 512, 1]) HOT 1
- Error on loading training model "_pickle.UnpicklingError: invalid load key, '<'"
- Custom trained model and dataset problem
- Index out of range for custom dataset.
- value error while training custom dataset
- TypeError: guvectorize() missing 1 required positional argument 'signature' HOT 1
- _pickle.UnpicklingError: invalid load key, '<'. in inference.py in colab HOT 3
- What's the filelist used to train LibriTTS2k pretrained embedding?
- Unable to train on custom data with multiple speakers HOT 6
- Which torch version to use?
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from flowtron.