Comments (12)
 fdegros
commented on May 3, 2024
2
fdegros
commented on May 3, 2024
2
So, what is the correct way of asking
fuse-archivewhether an archive is password protected? Ideally there would be a special exit code to signal this. I am trying to bring up a GUI dialog when the archive is password protected.
Thanks for the question, and thanks Maximilian for the investigation.
fuse-archive should return the following exit codes:
20if a password is required21if the provided password is incorrect22if encrypted archives of the given type are not supported
However, encrypted archives seem only partially supported. For example, encrypted 7Z archives are not supported. Mounting an encrypted 7Z seems to succeed at first, but trying to read any file from the mounted archive then fails with an I/O error.
$ echo password | fuse-archive -f Encrypted.7z mnt --passphrase
fuse-archive: could not serve /Texts/Lorem Ipsum.txt from Encrypted.7z: The file content is encrypted, but currently not supported
fuse-archive: could not serve /Texts/Lorem Ipsum.txt from Encrypted.7z: Damaged 7-Zip archive
$ cat "mnt/Texts/Lorem Ipsum.txt"
cat: 'mnt/Texts/Lorem Ipsum.txt': Input/output error
Encrypted ZIP archives are supported, including AES-encrypted ZIPs.
$ fuse-archive "Encrypted AES-256.zip" mnt ; echo $?
fuse-archive: Encrypted AES-256.zip: Passphrase required for this entry
20
$ echo poipoi | fuse-archive "Encrypted AES-256.zip" mnt --passphrase ; echo $?
fuse-archive: Encrypted AES-256.zip: Incorrect passphrase
21
$ echo password | fuse-archive "Encrypted AES-256.zip" mnt --passphrase ; echo $?
0
$ cat "mnt/Texts/Lorem Ipsum.txt"
Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Donec hendrerit tempor
...
$ fusermount -u mnt
from fuse-archive.
 nigeltao
commented on May 3, 2024
nigeltao
commented on May 3, 2024
- In my opinion, the 58x speedup mentioned in the Github Readme over archivemount is misleading because the mount point is not ready for usage at that point yet! I do not see the importance of daemonizing before or after the bulk of processing has been done.
It is important for me because I have a separate GUI controller program that fork/exec's fuse-archive and synchronously waits for the exit code (e.g. to pop up a password dialog box if the archive is encrypted). Actually listing the archive's contents in the GUI can happen asynchronously, but I still don't want the GUI to block for long when waiting for an exit code (i.e. daemonization). "Wait for the exit code" could admittedly be async but it's simpler to be sync, and it's also nice for the password dialog box to pop up sooner (< 1 second) rather than later (10s of seconds).
- I could not reproduce a general 682x speedup for copying at contents of an uncompressed file (lower left chart).
Can you reproduce the 682x speedup from the example in fuse-archive's top level README.md? It's the section starting with truncate --size=256M zeroes.
But also, that particular example demonstrates archivemount's quadratic O(N*N) versus fuse-archive's linear O(N), which is a ratio of N (ignoring constant factors), 256M in this case. Supplying a different archive file with a different N, larger or smaller, will produce a different speedup ratio, larger or smaller.
- The time for a simple find inside the mount point is similar to ratarmount, which is a magnitude slower than archivemount. This is surprising but exciting because I'm trying to track down why ratarmount is slower than archivemount in that metric since starting work on ratarmount! Do you have an idea, what you might do differently to archivemount? Could it be because archivemount uses the FUSE low-level interface?
I don't have an idea, but I wouldn't rule out the FUSE low-level API or richer readdir hypotheses. Did your further investigations find anything?
from fuse-archive.
 mxmlnkn
commented on May 3, 2024
mxmlnkn
commented on May 3, 2024
It is important for me because I have a separate GUI controller program that fork/exec's fuse-archive and synchronously waits for the exit code (e.g. to pop up a password dialog box if the archive is encrypted). Actually listing the archive's contents in the GUI can happen asynchronously, but I still don't want the GUI to block for long when waiting for an exit code (i.e. daemonization). "Wait for the exit code" could admittedly be async but it's simpler to be sync, and it's also nice for the password dialog box to pop up sooner (< 1 second) rather than later (10s of seconds).
Ah, ok, so basically you want it to quit fast for integrity checking (including password check). I think this could also be achieved with a --check flag or something like that (I'm also thinking out loud as to how to account for this usecase with ratarmount). However, in both cases, I think it could be possible that mounting fails only after reading over the whole file, e.g., if the archive is truncated / contains invalid data at the end.
- I could not reproduce a general 682x speedup for copying at contents of an uncompressed file (lower left chart).
Can you reproduce the 682x speedup from the example in fuse-archive's top level README.md? It's the section starting with
truncate --size=256M zeroes.
Wow, yes. That is super weird. I did not test with super-compressible files because I would think them to be rather rare usecases. It seems to me like this is a gzip decompressor issue, or do you know why fuse-archive is so much faster? Note that for me the benchmarked values using time cat zeroes | wc -c is 0.5s (on first read) or 0.1s on subsequent reads with fuse-archive vs. 7m46s with archivemount.
But also, that particular example demonstrates archivemount's quadratic O(N*N) versus fuse-archive's linear O(N), which is a ratio of N (ignoring constant factors), 256M in this case. Supplying a different archive file with a different N, larger or smaller, will produce a different speedup ratio, larger or smaller.
What is N in your case? The N, for which I could observe quadratic complexity is the number of files. See the top right plot for this, and compare the blue archivemount line at the bottom (uncompressed empty files) with the others. But, you are only testing with one file. And furthermore, a pretty small one at that. Are you telling me that the complexity is N squared with N being the number of bytes? How does that even happen (in archivemount)? I did miss an explanation in the archivemount issue. It was never mentioned where / what exactly causes the quadratic complexity and I didn't care enough to check the code myself... But if you by chance know this, I'd be interested :).
- The time for a simple find inside the mount point is similar to ratarmount, which is a magnitude slower than archivemount. This is surprising but exciting because I'm trying to track down why ratarmount is slower than archivemount in that metric since starting work on ratarmount! Do you have an idea, what you might do differently to archivemount? Could it be because archivemount uses the FUSE low-level interface?
I don't have an idea, but I wouldn't rule out the FUSE low-level API or richer readdir hypotheses. Did your further investigations find anything?
As mentioned, the richer readdir definitely helped a lot, here are some benchmarks for that change in ratarmount:
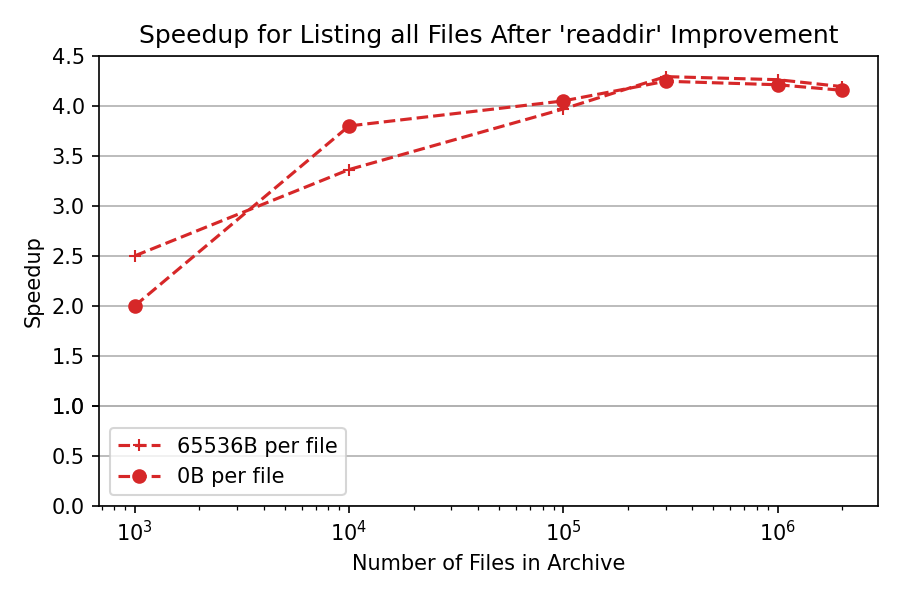
As for the lowlevel API. It is hard to implement that for ratarmount because I don't know how to pair file paths with static inodes in the case of union mounting with folders and other stuff. For pure TAR mounting, I could use the row ID in the SQLite metadata database as an inode number. But it requires some work to test it out. I might come back with results in the future.
Here are some actual numbers in a much smaller test I did for the ratarmount++ prototype. Embarrassingly, this C++ implementation is slower than the Python version ... It still does not implement the rich readdir interface but even then it is slower:
ratarmount tar-with-100-folders-with-1000-files-0B-files.tar mountPoint
time find mountPoint/ | wc -l # 5.444s, 4.369s, 4.715s for ratarmount 0.9.3
time find mountPoint/ | wc -l # 1.003s, 1.015s, 1.000s for ratarmount 0.10.0
fusermount -u mountPoint
src/ratarmount++ tar-with-100-folders-with-1000-files-0B-files.tar mountPoint
time find mountPoint/ | wc -l # 19.771s, 21.062s, 20.595s for ratarmount++ b2a03491e7f
archivemount tar-with-100-folders-with-1000-files-0B-files.tar mountPoint
time find mountPoint/ | wc -l # 0.150s, 0.090s, 0.075s for archivemount 0.8.7 using FUSE 2.9.9 internally
fuse-archive tar-with-100-folders-with-1000-files-0B-files.tar mountPoint
time find mountPoint/ | wc -l # 1.518s, 1.683s, 1.364s for fuse-archive 0.1.8 (4d5f3b0)Edit: fusepy doesn't ship with the fusell module even though it exists, which makes me lose my motivation to test it out because I can't even use it in ratarmount. And testing the lowlevel API out in ratarmount++ also doesn't appeal to me because it is much slower in the first place and any performance improvements caused by using the low level API might be questionable whether they stem from the API change alone, I think. So yeah, I won't be able to test out this hypothesis anytime soon as fusepy is basically dead and so are its forks like refuse.
from fuse-archive.
nigeltao
commented on May 3, 2024
do you know why fuse-archive is so much faster?
What is N in your case?
N is the total decompressed size (in bytes) of the tar or tar.gz file. The number of files isn't that important, other than being correlated with the size in bytes.
As mentioned, the richer readdir definitely helped a lot,
Sorry, I missed that you already mentioned that. I assume that mxmlnkn/ratarmount@e84ce39 is the relevant git commit.
Is "a simple find" still slower (by an order of magnitude??) for ratarmount, compared to archivemount, even after your richer readdir?
from fuse-archive.
nigeltao
commented on May 3, 2024
tar-with-100-folders-with-1000-files-0B-files.tar
It should be easy enough to do in bash, but for exact reproducibility, do you have a script to generate that tar file? I didn't see it explicitly listed in https://github.com/mxmlnkn/ratarmount/tree/master/tests
from fuse-archive.
nigeltao
commented on May 3, 2024
fuse-archive tar-with-100-folders-with-1000-files-0B-files.tar mountPoint time find mountPoint/ | wc -l # 1.518s, 1.683s, 1.364s for fuse-archive 0.1.8 (4d5f3b0)
I'm curious if this improves with the freshly-tagged fuse-archive v0.1.9 (978c540).
from fuse-archive.
mxmlnkn
commented on May 3, 2024
N is the total decompressed size (in bytes) of the tar or tar.gz file. The number of files isn't that important, other than being correlated with the size in bytes.
That can't be the only factor. I tested gzip-compressed archives far larger than 256MiB and they could be accessed faster than 7 minutes unlike that particular super-compressed gzip. I use base64 encoded random content for the file contents to ensure that they are at least somewhat (~30%) compressible. But using that kind of data only really makes use of the Huffman compression in gzip while the LZ77 back-references are rarely used because at its core it's random data.
It should be easy enough to do in bash, but for exact reproducibility, do you have a script to generate that tar file? I didn't see it explicitly listed in https://github.com/mxmlnkn/ratarmount/tree/master/tests
That file is too large to push directly into my repository, so I'm creating it on-the-fly inside benchmarkMounting.sh. This file in particular does compress from 49MiB down to 178kiB (282x) with xz though, so I could add a compressed version to the tests folder as I too need that file frequently for testing. I'm specifically generating relatively long filenames because string lookup times in the SQLite database partially depends on the string size.
I'm curious if this improves with the freshly-tagged fuse-archive v0.1.9 (978c540).
fuse-archive tar-with-100-folders-with-1000-files-0B-files.tar mountPoint
time find mountPoint/ | wc -l # 0.073s 0.060s 0.059s 0.069s 0.074s for fuse-archive 0.1.9 (978c540)Just wow! I had to triple check because now the timings are as fast if not twice as fast as archivemount and the achieved speedup is far larger than the 4x I observed in Python. So it doesn't seem to be necessary to use FUSE low level to fill the last remaining gap... Seems like the remaining gap is caused by using SQLite + Python or I don't know anymore...
In the tests in your newest commit, you seemed to have not even a speedup of two. But I think the tests might be too short and the long filenames I used probably exacerbated the speedup I could see. But the number of getattr calls is 7x smaller, so that looks good.
I assume that mxmlnkn/ratarmount@e84ce39 is the relevant git commit.
Yes
Is "a simple find" still slower (by an order of magnitude??) for ratarmount, compared to archivemount, even after your richer readdir?
Unfortunately, yes, as can be seen in the up-to-date benchmark's lower right plot in my first post. It's also shown in the manual timings in my last post where ratarmount 0.9.3 is ~50x slower than archivemount and ratarmount 0.10.0 is ~10x slower. I had my hopes on FUSE low-level for that last magnitude but it might just be caused by the rather large software stack, I don't know.
Plus, I stored the matadata non-hierarchically. That might also slow things down although the search is O(log(#files)) and therefore should be pretty fast no matter the size.
from fuse-archive.
mxmlnkn
commented on May 3, 2024
do you know why fuse-archive is so much faster?
Ah! I see. I only tested with rather small files (up to 64kiB), which is below the 128kiB chunk size. So the quadratic complexity is O( (sizeOfFileToBeCopiedFromArchive / readChunkSize)^2 ) for streaming / copying a file outside the archive. Thanks! I really need to add a "bandwidth" benchmark, i.e., copy a larger file outside of the archive and time that. This would not only show the fuse-archive improvement over archivemount (I hope) but also (hopefully) highlight the performance of my parallelized compression backends like xz and bz2 and, hopefully to come soon / this year, parallelized gzip.
from fuse-archive.
mxmlnkn
commented on May 3, 2024
All my initial and further questions are solved. In short, I benchmarked something different. And fuse-archive even got faster thanks to the rich readdir interface. I think this can issue has been closed.
from fuse-archive.
 probonopd
commented on May 3, 2024
probonopd
commented on May 3, 2024
So, what is the correct way of asking fuse-archive whether an archive is password protected? Ideally there would be a special exit code to signal this. I am trying to bring up a GUI dialog when the archive is password protected.
from fuse-archive.
 louies0623
commented on May 3, 2024
louies0623
commented on May 3, 2024
@mxmlnkn This needs your help, because some compressed files require a password to decompress.
from fuse-archive.
mxmlnkn
commented on May 3, 2024
@louies0623 I'm confused. Why ask me and why in this closed issue instead of making a new one? I'm not a developer of fuse-archive, @nigeltao is. I'm the developer of the competing ratarmount, which accepts a list of passwords to try for each archive via --password or --password-file. fuse-archive also has a --passphrase option.
As to how to check whether it needs a password, according to the code it already should output an error for incorrect passphrases. But all encrypted test archives for ratarmount that I tried with fuse-archive, didn't work / printed unexpected error message without a passphrase such as:
> fuse-archive encrypted-headers-nested-tar.rar mounted; echo Exit Code: $?
fuse-archive: invalid archive encrypted-headers-nested-tar.rar: Encryption is not supported
Exit Code: 31
> fuse-archive encrypted-nested-tar.7z mounted; echo Exit Code: $?
fuse-archive: passphrase not supported for encrypted-nested-tar.7z
Exit Code: 22
So it seems to me that there is already error handling and proper exit codes.
from fuse-archive.
Related Issues (15)
- Security Policy violation Binary Artifacts HOT 2
- Feature request: mount directories containing archive files HOT 4
- Unable to compile it on ubuntu 22.04 HOT 1
- fuse-archive reports the number of blocks taken by each file as zero
- Nonstandard-C++ in src/main.cc HOT 1
- migrate to fuse3 HOT 1
- Empty folders not mounted HOT 2
- Hard links not mounted HOT 1
- fuse-archive silently fails for paths beginning with './'
- Cannot Mount Archive Generated From 7-Zip-ZSTD HOT 4
- decompressing individual .gz files in a directory (compression without tar envelope) HOT 4
- No way to get fuse-archive version
- Support for indexed tar.xz file from pixz tool
- C implementation HOT 3
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from fuse-archive.