Comments (30)
 dataabc
commented on June 6, 2024
dataabc
commented on June 6, 2024
你的意思是通过代码实现还是直接修改mysql?
如果是修改代码,这个有点麻烦。需要每个用户创建一个表,表名可以是字符串+用户id,如“user1669879400”。还需要修改创建字段的weibo_to_mysql方法,主要是增加被转发微博的字段,它和微博原创部分的字段差不多。比如原创部分有bid这个字段,那转发部分就可以增加retweet_bid,二者的字符串类型一样,其它字段也进行上述操作。程序的流程是每次结果写入mysql时,先判断"user+user_id"这个表是否存在,不存在就创建。表的字段就是刚刚说的那些原创部分字段+转发部分字段。这个方法需要修改的地方有点多,但是修改完成后就简单了。
另一种是直接修改mysql结果。所有结果都已写入weibo表,需要做的只是把每个用户的数据单独提取出来生成一直新表,每个用户一张。
Create table user1669879400(Select * from weibo where user_id=1669879400);
上面创建的是user_id为1669879400的用户的表。如果你还想要让表包含转发信息,可以这样:
Create table user1669879400(Select t1.id as id, weibo.id as retweet_id from (Select * from weibo where user_id=1669879400) as t1, weibo where t1.retweet_id=weibo.id);
上面是创建一个用户的表,你可以创建多个。为了方便说明,上面字段也仅仅包含了id和retweet_id字段,你可以将需要的字段全部加上。这种方法不需要改代码,但是每增加用户都需要手动创建数据表。
from weibo-crawler.
 Oliviazhl
commented on June 6, 2024
Oliviazhl
commented on June 6, 2024
对于这两种方法有一个疑问:1.我刚刚想要尝试的是第一种方法,但是create table后面的字段,也就是表名如何修改为根据每一次循环进行改变的。 2.第一种方法是不是只需要修改weibo_to_mysql方法,其他函数是不是不用修改了。
3.关于第二种方法也是可以的,但我更希望是直接呈现出来就和分开之后的csv一样~感谢
from weibo-crawler.
Oliviazhl
commented on June 6, 2024
另外就是,我看完代码有一个疑惑就是插入csv也好,插入mysql也好,如何保证header的顺序和内容的顺序一样呀我对wrote_count里提取出来的数据的顺序很好奇
from weibo-crawler.
dataabc
commented on June 6, 2024
1.表名可以设置为变量,如 :
table_name = 'user' + self.user_id
每爬一个用户,user_id都是不同的,用'user' + user_id这种形式就保证了数据表名的唯一性;
2.目前我想到的就是只修改weibo_to_mysql方法,不知道有没有想漏。这个方法就是把微博信息写入mysql的。思路是先创建weibo表(如果weibo表不存在),然后再处理要存的数据,就是把有转发微博的数据拆分,即把一条转发微博拆成两条微博:微博的原创部分是一条,转发部分是一条。最后再将数据写入mysql。你现在要修改两个地方,第一个是创建数据表时添加转发部分的字段;第二个是处理数据。假如微博存在wb变量上,如果是原创微博,就把它的转发数据设为'',如wb['retweet_bid'] = '',等等;如果是转发微博,就把转发数据加到wb上,如wb['retweet_bid']=wb['retweet']['bid'],其它原创微博有的字段也要加上。因为如果是转发微博,wb['retweet']一定存在,而且它也是字典,字段和原创微博字段一样。添加完成后删除wb['retweet']。最后把所有要插入的微博添加到列表里,再用self.mysql_insert方法批量添加。
3.因为数据存储用的不是普通的字典而是OrderedDict,它是有序的,所以顺序不会乱。
from weibo-crawler.
dataabc
commented on June 6, 2024
补充一点,数据表添加的转发字段名要和wb中的一致。比如你在数据表中添加了retweet_bid字段,那wb中就必需存在wb['retweet_bid'],因为程序是根据字段名插入数据的
from weibo-crawler.
Oliviazhl
commented on June 6, 2024
对,有两个点,一个是OrderDict里面具体的顺序不是很清楚,那数据表添加字段的时候顺序是否要按照OrderDict的顺序来?第二是正如你所说的retweet里面的要按照wb中的字段名添加,但是我也不知道具体里面字段名是啥字母?这两个要怎么看呢感谢
from weibo-crawler.
dataabc
commented on June 6, 2024
1.添加数据表时字段的顺序是数据库中的顺序,插入时不用担心顺序问题,程序会自动按照(key1,key2,key3):(value1,value2,value3)插入,只要key与value对应就可以,即便(key3,key2,key1):(value3,value2,value1)也可以正确插入,这个已经在mysql_insert方法中实现了,应该不需要修改;
2.retweet的字段除了它本身外,完全和wb一样。假如wb存了一条微博数据,它是一个字典。如果是原创微博,它就有
id、bid 、user_id、 screen_name、text、topics、at_users、pics、video_url 、 location、、 created_at 、 source、 attitudes_count 、 comments_count、reposts_count
这些key,所以wb['id']、wb['bid']、wb['screen_name']等等值也是存在的;如果是转发微博,wb除了上述字段外,它还有一个retweet字段,wb['retweet']包含了所有转发信息,wb['retweet']也是一个字典,它和wb原创微博拥有相同的字段,即
id、bid 、user_id、 screen_name、text、topics、at_users、pics、video_url 、 location、、 created_at 、 source、 attitudes_count 、 comments_count、reposts_count
wb['retweet'][id]、wb['retweet']['bid']、wb['retweet']['screen_name']等等值也是存在的,含义与wb中的是一样的。不同的是wb如果是转发微博会有retweet字段,即wb['retweet']存在,但wb['retweet']中却没有这个字段,即wb['retweet']['retweet']是不存在的,因为wb['retweet']肯定是原创微博,假如用户A发了一条原创微博,B转发了A的这条微博,C又转发了B的这条,在C发的这条转发微博中,C的转发理由和B的转发理由都存在wb['text']中,A的那条微博存在wb['retweet']中。
因为你想按照csv形式保存在mysql中,所以你需要把wb['retweet']中的数据展开,加到wb中,如
wb['retweet_bid'] = wb['retweet']['bid']
其它字段也一样,最后把wb['retweet']删除。
from weibo-crawler.
Oliviazhl
commented on June 6, 2024
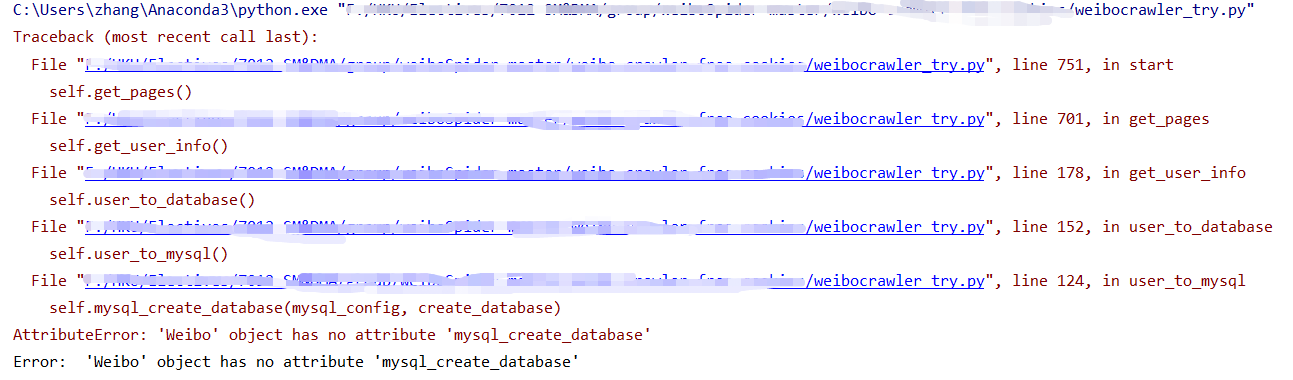
感谢你的解答,我修改好了,但是这边报这个错~因为我这边运行一次比较久,所以我暂时不想覆盖原来的数据库的内容,就把database名字改为了weibo2。这边是否是由于这个原因报错,要把代码里所有的weibo改成weibo2吗?
from weibo-crawler.
dataabc
commented on June 6, 2024
报错的提示是没有mysql_create_database,是不是这个方法被删啦?
from weibo-crawler.
Oliviazhl
commented on June 6, 2024
是的,我一开始以为这个方法是验证有没有install pymysql,就把它删除啦~
现在有两个新问题。
1.这个报错不是很明白是什么意思,为什么mysql插入不了
2.我的database里没有weibo2只有weibo但是显示无法建,因为存在,这个也很奇怪~
想问一下应该怎么解决,感谢~
pymysql.err.ProgrammingError: (1064, "You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'UPDATEid = values(id),screen_name = values(screen_name),gender = values(gender),' at line 1")
Progress: 0%| | 0/108 [00:00<?, ?it/s]The 1 page
pymysql.err.ProgrammingError: (1064, "You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'carchar(2000),\n retweet_topics varchar(200),\n retw' at line 21")
Progress: 13%|█▎ | 14/108 [00:38<04:20, 2.77s/it]
Error: (1064, "You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'carchar(2000),\n retweet_topics varchar(200),\n retw' at line 21")
Warning: (1007, "Can't create database 'weibo2'; database exists")
result = self._query(query)
from weibo-crawler.
dataabc
commented on June 6, 2024
1.错误提示是sql语法有问题,不知道是不是你修改过mysql_insert方法,还有就是在创建s数据 表时,不要把新加的转发字段设成NOT NULL。
2.应该是weibo2数据库已经存在了,你看到的可能是weibo表。程序是先创建weibo数据库,然后在weibo库中创建weibo表。你的程序是创建weibo2数据库,如果插入成功里面会有weibo表
from weibo-crawler.
Oliviazhl
commented on June 6, 2024
weibo database那个解决了,因为我把表名改成 screen_name了这样就可以一个一张表了,但是mysql语句一直报错。这是我修改过的weibo_to_mysql方法
def weibo_to_mysql(self, wrote_count):
# Write the information in the database
mysql_config = {
'host': 'localhost',
'port': 3306,
'user': 'root',
'password': '123456',
'charset': 'utf8mb4'
}
# Create Table
table_name = self.user['screen_name']
create_table = """
CREATE TABLE IF NOT EXISTS table_name (
id varchar(20) NOT NULL,
bid varchar(12) NOT NULL,
user_id varchar(20),
screen_name varchar(20),
text varchar(2000),
topics varchar(200),
at_users varchar(200),
pics varchar(1000),
video_url varchar(300),
location varchar(100),
created_at DATETIME,
source varchar(30),
attitudes_count INT,
comments_count INT,
reposts_count INT,
is_original TINYINT(1),
retweet_id varchar(20),
retweet_bid varchar(12),
retweet_screen_name varchar(20),
retweet_text carchar(2000),
retweet_topics varchar(200),
retweet_at_users varchar(200),
retweet_pics varchar(1000),
retweet_video_url varchar(300),
retweet_location varchar(100),
retweet_created_at DATETIME,
retweet_source varchar(30),
retweet_attitudes_count INT,
retweet_comments_count INT,
retweet_reposts_count INT,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4"""
self.mysql_create_table(mysql_config, create_table)
weibo_list = []
retweet_list = []
for w in self.weibo[wrote_count:]:
if 'retweet' in w:
w['retweet']['retweet_id'] = ''
w['retweet']['retweet_bid'] = ''
w['retweet']['retweet_screen_name'] = ''
w['retweet']['retweet_text'] = ''
w['retweet']['retweet_topics'] = ''
w['retweet']['retweet_at_users'] = ''
w['retweet']['retweet_pics'] = ''
w['retweet']['retweet_video_url'] = ''
w['retweet']['retweet_location'] = ''
w['retweet']['retweet_created_at'] = ''
w['retweet']['retweet_source'] = ''
w['retweet']['retweet_attitudes_count'] = ''
w['retweet']['retweet_comments_count'] = ''
w['retweet']['retweet_reposts_count'] = ''
retweet_list.append(w['retweet'])
w['retweet_id'] = w['retweet']['id']
w['retweet_bid'] = w['retweet']['bid']
w['retweet_screen_name'] = w['retweet']['screen_name']
w['retweet_text'] = w['retweet']['text']
w['retweet_topics'] = w['retweet']['topics']
w['retweet_at_users'] = w['retweet']['at_users']
w['retweet_pics'] = w['retweet']['pics']
w['retweet_video_url'] = w['retweet']['video_url']
w['retweet_location'] = w['retweet']['location']
w['retweet_created_at'] = w['retweet']['created_at']
w['retweet_source'] = w['retweet']['source']
w['retweet_attitudes_count'] = w['retweet']['attitudes_count']
w['retweet_comments_count'] = w['retweet']['comments_count']
w['retweet_reposts_count'] = w['retweet']['reposts_count']
del w['retweet']
else:
w['retweet_id'] = ''
w['retweet_bid'] = ''
w['retweet']['retweet_screen_name'] = ''
w['retweet']['retweet_text'] = ''
w['retweet']['retweet_topics'] = ''
w['retweet']['retweet_at_users'] = ''
w['retweet']['retweet_pics'] = ''
w['retweet']['retweet_video_url'] = ''
w['retweet']['retweet_location'] = ''
w['retweet']['retweet_created_at'] = ''
w['retweet']['retweet_source'] = ''
w['retweet']['retweet_attitudes_count'] = ''
w['retweet']['retweet_comments_count'] = ''
w['retweet']['retweet_reposts_count'] = ''
weibo_list.append(w)
# Insert or update tweet in the table'weibo'
self.mysql_insert(mysql_config, table_name, retweet_list)
self.mysql_insert(mysql_config, table_name, weibo_list)
print(u'%d tweets are written into table weibo' % self.got_count)
from weibo-crawler.
Oliviazhl
commented on June 6, 2024
而且我查看了数据库的情况是,连user表也没有插入,正常来说我
只修改了原来的weibo表~ 我这边因为只需要mysql就删掉了一些函数,也不知道有没有影响~
weibocrawler_try.zip
from weibo-crawler.
dataabc
commented on June 6, 2024
这样肯定出错啊
我之所以有weibo_list、retweet_list两个list是因为要把retweet的信息也写到数据表里,你的是把这些数据扩展开,不应该有retweet_list。
数据表中没有retweet字段,weibo_list却有,在数据表中插入不存在的字段会出错
from weibo-crawler.
Oliviazhl
commented on June 6, 2024
其实我不是很明白。因为你原来weibo表里是把转发微博和原微博分开爬的,我想要的是和csv里的一样,就是都是直接只有一条显示每一条微博,如果是转发的直接再后面增加源微博的相关信息。但是你说你有两个list是因为要把retweet的信息也写到数据表里,那我也是要把retweet的信息写到数据表里,其实我们并不矛盾,所以我不知道问题出在哪里。
是我只要把展开那部分删除就可以了吗?
from weibo-crawler.
Oliviazhl
commented on June 6, 2024
我刚刚试了一下把我展开的都去掉,只运行原来的你写的部分,仍然报同样的错~
def mysql_insert(self, mysql_config, table, data_list):
# Insert or update data into Weibo
import pymysql
if len(data_list) > 0:
keys = ', '.join(data_list[0].keys())
values = ', '.join(['%s'] * len(data_list[0]))
if self.mysql_config:
mysql_config = self.mysql_config
mysql_config['db'] = 'weibo2'
connection = pymysql.connect(**mysql_config)
cursor = connection.cursor()
sql = "INSERT INTO {table}({keys}) VALUES ({values}) ON DUPLICATE KEY UPDATE".format(table=table, keys=keys, values=values)
update = ','.join(["{key} = values({key})".format(key=key) for key in data_list[0]])
sql += update
try:
cursor.executemany(
sql, [tuple(data.values()) for data in data_list])
connection.commit()
except Exception as e:
connection.rollback()
print('Error: ', e)
traceback.print_exc()
finally:
connection.close()
def weibo_to_mysql(self, wrote_count):
# Write the information in the database
mysql_config = {
'host': 'localhost',
'port': 3306,
'user': 'root',
'password': '123456',
'charset': 'utf8mb4'
}
# Create Table
table_name = self.user['screen_name']
create_table = """
CREATE TABLE IF NOT EXISTS table_name (
id varchar(20) NOT NULL,
bid varchar(12) NOT NULL,
user_id varchar(20),
screen_name varchar(20),
text varchar(2000),
topics varchar(200),
at_users varchar(200),
pics varchar(1000),
video_url varchar(300),
location varchar(100),
created_at DATETIME,
source varchar(30),
attitudes_count INT,
comments_count INT,
reposts_count INT,
is_original TINYINT(1),
retweet_id varchar(20),
retweet_bid varchar(12),
retweet_screen_name varchar(20),
retweet_text carchar(2000),
retweet_topics varchar(200),
retweet_at_users varchar(200),
retweet_pics varchar(1000),
retweet_video_url varchar(300),
retweet_location varchar(100),
retweet_created_at DATETIME,
retweet_source varchar(30),
retweet_attitudes_count INT,
retweet_comments_count INT,
retweet_reposts_count INT,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4"""
self.mysql_create_table(mysql_config, create_table)
weibo_list = []
retweet_list = []
for w in self.weibo[wrote_count:]:
if 'retweet' in w:
w['retweet']['retweet_id'] = ''
# w['retweet']['retweet_bid'] = ''
# w['retweet']['retweet_screen_name'] = ''
# w['retweet']['retweet_text'] = ''
# w['retweet']['retweet_topics'] = ''
# w['retweet']['retweet_at_users'] = ''
# w['retweet']['retweet_pics'] = ''
# w['retweet']['retweet_video_url'] = ''
# w['retweet']['retweet_location'] = ''
# w['retweet']['retweet_created_at'] = ''
# w['retweet']['retweet_source'] = ''
# w['retweet']['retweet_attitudes_count'] = ''
# w['retweet']['retweet_comments_count'] = ''
# w['retweet']['retweet_reposts_count'] = ''
retweet_list.append(w['retweet'])
w['retweet_id'] = w['retweet']['id']
# w['retweet_bid'] = w['retweet']['bid']
# w['retweet_screen_name'] = w['retweet']['screen_name']
# w['retweet_text'] = w['retweet']['text']
# w['retweet_topics'] = w['retweet']['topics']
# w['retweet_at_users'] = w['retweet']['at_users']
# w['retweet_pics'] = w['retweet']['pics']
# w['retweet_video_url'] = w['retweet']['video_url']
# w['retweet_location'] = w['retweet']['location']
# w['retweet_created_at'] = w['retweet']['created_at']
# w['retweet_source'] = w['retweet']['source']
# w['retweet_attitudes_count'] = w['retweet']['attitudes_count']
# w['retweet_comments_count'] = w['retweet']['comments_count']
# w['retweet_reposts_count'] = w['retweet']['reposts_count']
del w['retweet']
else:
w['retweet_id'] = ''
# w['retweet_bid'] = ''
# w['retweet']['retweet_screen_name'] = ''
# w['retweet']['retweet_text'] = ''
# w['retweet']['retweet_topics'] = ''
# w['retweet']['retweet_at_users'] = ''
# w['retweet']['retweet_pics'] = ''
# w['retweet']['retweet_video_url'] = ''
# w['retweet']['retweet_location'] = ''
# w['retweet']['retweet_created_at'] = ''
# w['retweet']['retweet_source'] = ''
# w['retweet']['retweet_attitudes_count'] = ''
# w['retweet']['retweet_comments_count'] = ''
# w['retweet']['retweet_reposts_count'] = ''
weibo_list.append(w)
# Insert or update tweet in the table'weibo'
self.mysql_insert(mysql_config, table_name, retweet_list)
self.mysql_insert(mysql_config, table_name, weibo_list)
print(u'%d tweets are written into table weibo' % self.got_count)
from weibo-crawler.
dataabc
commented on June 6, 2024
转发微博的wb大概是这样:
{'id':1,'text':'test','retweet':{'id':2,'text':'test2'}}
我的思路是把上面的wb分成两个字典:{'id':1,'text':'test'}和{'id':2,'text':'test2'},前者加到weibo_list里,后者加到retweet_list,所以需要两个list。
你现在想要的是把wb改成{'id':1,'text':'test','retweet_id':2,'retweet_text':'test2'},所有的信息都写到一块了,只需要一个list就可以了
from weibo-crawler.
Oliviazhl
commented on June 6, 2024
那我可以理解为我根本不需要建立weibo_list和retweet_list,直接在self.mysql_insert里直接插入self.weibo吗?
self.mysql_insert(mysql_config, table_name, [self.weibo])
from weibo-crawler.
dataabc
commented on June 6, 2024
需要建立weibo_list,它存储多个wb。mysql_insert插入时需要的是一个list,这样做的目的是既可以插入一个wb(如list就包含一个微博),也可以批量插入多条微博
from weibo-crawler.
Oliviazhl
commented on June 6, 2024
好的,但是我刚刚运行了还没修改weibo_to_mysql的版本也出现了这个错误,所以这个报错可能不是由于list不同导致的。不知道是不是前面哪些函数的缺失导致的
from weibo-crawler.
Oliviazhl
commented on June 6, 2024
没修改weibo_to_mysql的版本可以建weibo表和user表,但两张表都为空。修改之后的版本是只能建立user表,没有具体的用户信息表,但是user表也为空
from weibo-crawler.
dataabc
commented on June 6, 2024
把数据库或数据表删除重建呢,也会报错吗?还有你的数据表名可能会有中文,有时候也会有问题。
from weibo-crawler.
dataabc
commented on June 6, 2024
weibo_list = []
for w in self.weibo[wrote_count:]:
if 'retweet' in w:
w['retweet_id'] = w['retweet']['id']
w['retweet_bid'] = w['retweet']['bid']
w['retweet_screen_name'] = w['retweet']['screen_name']
w['retweet_text'] = w['retweet']['text']
w['retweet_topics'] = w['retweet']['topics']
w['retweet_at_users'] = w['retweet']['at_users']
w['retweet_pics'] = w['retweet']['pics']
w['retweet_video_url'] = w['retweet']['video_url']
w['retweet_location'] = w['retweet']['location']
w['retweet_created_at'] = w['retweet']['created_at']
w['retweet_source'] = w['retweet']['source']
w['retweet_attitudes_count'] = w['retweet']['attitudes_count']
w['retweet_comments_count'] = w['retweet']['comments_count']
w['retweet_reposts_count'] = w['retweet']['reposts_count']
del w['retweet']
else:
w['retweet_id'] = ''
w['retweet_bid'] = ''
w['retweet_screen_name'] = ''
w['retweet_text'] = ''
w['retweet_topics'] = ''
w['retweet_at_users'] = ''
w['retweet_pics'] = ''
w['retweet_video_url'] = ''
w['retweet_location'] = ''
w['retweet_created_at'] = '1900-01-01'
w['retweet_source'] = ''
w['retweet_attitudes_count'] = 0
w['retweet_comments_count'] = 0
w['retweet_reposts_count'] = 0
weibo_list.append(w)
# Insert or update tweet in the table'weibo'
self.mysql_insert(mysql_config, table_name, weibo_list)
print(u'%d tweets are written into table weibo' % self.got_count)
拆分转发数据我是这样写的,不知道会不会出错
from weibo-crawler.
Oliviazhl
commented on June 6, 2024
我的表名没有中文,你刚刚提到中文我想起来我删掉了这个函数。是不是只有csv才调用了它?

from weibo-crawler.
dataabc
commented on June 6, 2024
是只有csv调用的它,你的表名用的是用户昵称,可能有中文
from weibo-crawler.
Oliviazhl
commented on June 6, 2024
weibocrawler_try.zip
还是不行,我实在是找不到原因了,我把代码打包了,可以麻烦你帮忙看一下嘛感谢
from weibo-crawler.
dataabc
commented on June 6, 2024
1.mysql_insert中
sql = "INSERT INTO {table}({keys}) VALUES ({values}) ON DUPLICATE KEY UPDATE ".format(table=table, keys=keys, values=values)
UPDATE后加个空格;
2.weibo_to_mysql方法,建议
table_name = 'user' + self.user['id']
3.weibo_to_mysql方法中
retweet_text carchar(2000),
错误,应为
retweet_text varchar(2000),
4.创建数据表的语句错误,这样成了创建一个名为table_name的表了,应该改成变量,如:
create_table = """
CREATE TABLE IF NOT EXISTS %s (
......
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4""" % table_name
from weibo-crawler.
Oliviazhl
commented on June 6, 2024
感谢,bug已修复,还有一个小问题就是导出的列表中is_original这一列为空的,是不是因为这个本身不是weibo_list里有的数据呢?
from weibo-crawler.
Oliviazhl
commented on June 6, 2024
在运行中一切正常,突然出现这个错误~是因为爬取sleep时间不够长吗?
Error: HTTPSConnectionPool(host='m.weibo.cn', port=443): Max retries exceeded with url: /api/container/getIndex?containerid=1076031192329374&page=291 (Caused by SSLError(SSLError("bad handshake: SysCallError(-1, 'Unexpected EOF')")))
from weibo-crawler.
dataabc
commented on June 6, 2024
可以把is_original删除,它是冗余字段。
应该是爬的时间太长,被限制了,可以适当加长sleep时间或加快等待频率。
from weibo-crawler.
Related Issues (20)
- 你好,我想下载所有微博正文,该怎么设置呢? HOT 3
- docker镜像 HOT 1
- 某行是一条独立换行内容的时候这个换行最终读取到MYSQL会被省略掉
- 微博内容(Weibo.text)最大长度报错问题 HOT 1
- 求助-爬微博进度100%,但是数量明显跟实际数量不一致有可能是何原因? HOT 3
- 如何爬取微博正文时展开全文爬取到完整内容 HOT 1
- COOKIES没有失效,但是Progress: 19%就结束了,可能是什么原因? HOT 3
- 当单个微博图片超过9张时,weibo-crawler只能下载9张 HOT 2
- 爬取的图片名字里有一个奇怪的T HOT 1
- “检测cookie是否有效”的功能失效 HOT 2
- 怎么爬取用户的ip归属地呢? HOT 7
- 请问下载的评论在哪 HOT 1
- 转发和评论好像出现了奇怪的问题 HOT 1
- csv中抓取的用户头像链接有时候会失效怎么解决? HOT 1
- sqlite储存数据非常大 HOT 1
- Docker 定时跑时,图片和视频是否是反复下载?
- since_date 格式不正确,请确认配置是否正确 HOT 6
- 被ban了 HOT 1
- 无法爬取地区、学校、生日相关信息 HOT 3
- 微博爬取截止时间 HOT 1
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from weibo-crawler.