shen1992 / blog Goto Github PK
View Code? Open in Web Editor NEWshen的博客
shen的博客
可以想象一下我们在房间内,房间是一个立方体,如果你有生活品味,可能会在房间内贴上壁纸,three.js可以很方便的创建一个立方体,并且给它的周围贴上纹理,让照相机在立方体之中,照相机可以360旋转,就模拟了一个真实的场景。
const path = 'assets/image/'
const format = '.jpg'
const urls = [
`${path}px${format}`, `${path}nx${format}`,
`${path}py${format}`, `${path}ny${format}`,
`${path}pz${format}`, `${path}nz${format}`
]
const materials = []
urls.forEach(url => {
const textureLoader = new TextureLoader()
textureLoader.setCrossOrigin(this.crossOrigin)
const texture = textureLoader.load(url)
materials.push(new MeshBasicMaterial({
map: texture,
overdraw: true,
side: BackSide
}))
})
const cube = new Mesh(new CubeGeometry(9000, 9000, 9000), new MeshFaceMaterial(materials))
this.scene.add(cube)
一个3d模型是由点,线,面组成的,可以遍历模型的每一个点,把每一个点转换为几何模型,并且给它贴上纹理,拷贝每一个点的位置,用这些几何模型重新构成一个只有点的模型,这就是粒子效果的基本原理。
this.points = new Group()
const vertices = []
let point
const texture = new TextureLoader().load('assets/image/dot.png')
geometry.vertices.forEach((o, i) => {
// 记录每个点的位置
vertices.push(o.clone())
const _geometry = new Geometry()
// 拿到当前点的位置
const pos = vertices[i]
_geometry.vertices.push(new Vector3())
const color = new Color()
color.r = Math.abs(Math.random() * 10)
color.g = Math.abs(Math.random() * 10)
color.b = Math.abs(Math.random() * 10)
const material = new PointsMaterial({
color,
size: Math.random() * 4 + 2,
map: texture,
blending: AddEquation,
depthTest: false,
transparent: true
})
point = new Points(_geometry, material)
point.position.copy(pos)
this.points.add(point)
})
return this.points
three.js的点击事件需要借助光线投射器(Raycaster),为了方便理解,请先看一张图:
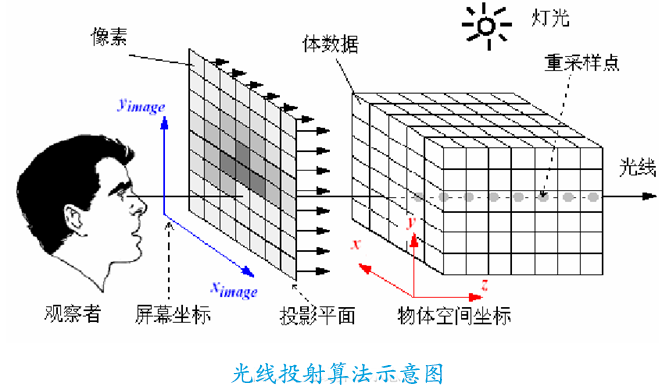
Raycaster发射一个射线,intersectObject监测射线命中的物体
this.raycaster = new Raycaster()
// 把你要监听点击事件的物体用数组储存起来
this.seats.push(seat)
onTouchStart(event) {
event.preventDefault()
event.clientX = event.touches[0].clientX;
event.clientY = event.touches[0].clientY;
this.onClick(event)
}
onClick(event) {
const mouse = new Vector2()
mouse.x = ( event.clientX / this.renderer.domElement.clientWidth ) * 2 - 1
mouse.y = - ( event.clientY / this.renderer.domElement.clientHeight ) * 2 + 1;
this.raycaster.setFromCamera(mouse, this.camera)
// 检测命中的座位
const intersects = this.raycaster.intersectObjects(this.seats)
if (intersects.length > 0) {
intersects[0].object.material = new MeshLambertMaterial({
color: 0xff0000
})
}
}
着色器分为顶点着色器和片元着色器,用GLSL语言编写,是一种和GPU沟通的的语言,这里只讲如何使用
const vertext = `
void main()
{
gl_Position = projectionMatrix * modelViewMatrix * vec4(position,1.0);
}
`
const fragment = `
uniform vec2 resolution;
uniform float time;
vec2 rand(vec2 pos)
{
return fract( 0.00005 * (pow(pos+2.0, pos.yx + 1.0) * 22222.0));
}
vec2 rand2(vec2 pos)
{
return rand(rand(pos));
}
float softnoise(vec2 pos, float scale)
{
vec2 smplpos = pos * scale;
float c0 = rand2((floor(smplpos) + vec2(0.0, 0.0)) / scale).x;
float c1 = rand2((floor(smplpos) + vec2(1.0, 0.0)) / scale).x;
float c2 = rand2((floor(smplpos) + vec2(0.0, 1.0)) / scale).x;
float c3 = rand2((floor(smplpos) + vec2(1.0, 1.0)) / scale).x;
vec2 a = fract(smplpos);
return mix(
mix(c0, c1, smoothstep(0.0, 1.0, a.x)),
mix(c2, c3, smoothstep(0.0, 1.0, a.x)),
smoothstep(0.0, 1.0, a.y));
}
void main(void)
{
vec2 pos = gl_FragCoord.xy / resolution.y;
pos.x += time * 0.1;
float color = 0.0;
float s = 1.0;
for(int i = 0; i < 8; i++)
{
color += softnoise(pos+vec2(i)*0.02, s * 4.0) / s / 2.0;
s *= 2.0;
}
gl_FragColor = vec4(color);
}
`
// 设置物体的质材为着色器质材
let material = new ShaderMaterial({
uniforms: uniforms,
vertexShader: vertext,
fragmentShader: fragment,
transparent: true,
})
由于是模拟电影院,我想做一个投影仪,模拟投影仪射出的光线。
// 光晕效果必须设置alpha = true
const renderer = this.renderer = new WebGLRenderer({alpha: true, antialias: true})
let textureFlare = new TextureLoader().load('assets/image/lensflare0.png')
let textureFlare3 = new TextureLoader().load('assets/image/lensflare3.png')
let flareColor = new Color(0xffffff)
let lensFlare = new LensFlare(textureFlare, 150, 0.0 , AdditiveBlending, flareColor)
lensFlare.add(textureFlare3, 60, 0.6, AdditiveBlending);
lensFlare.add(textureFlare3, 70, 0.7, AdditiveBlending);
lensFlare.add(textureFlare3, 120, 0.9, AdditiveBlending);
lensFlare.add(textureFlare3, 70, 1.0, AdditiveBlending);
lensFlare.position.set(0, 150, -85)
原创不易,辛苦各位大大点个star
react给自己下的定义是:用于构建用户界面的javascript库。
但是在开发中,我们要面对的问题往往比较复杂,为了解决这些问题,诞生了react全家桶。
在项目的开发中,我们往往会有一些数据是在多个组件之间甚至多个页面之间共享的,实现共享数据一个最简单粗暴的办法就是使用全局变量比如。
let appState = {
name: 'shenyuan'
}
这样,所有的组件都可以访问到appState里面的name。
但是全局变量有一个缺点:人人都可以访问,人人都可以修改,那么在某个组件中把name修改为null,我们一点脾气都没有,而且当项目十分庞大,debug起来就会变得很困难。在这里我们用redux解决这个问题。
redux规定,要修改appState里面的数据,必须通过dispatch方法。
用一张图片来说明:
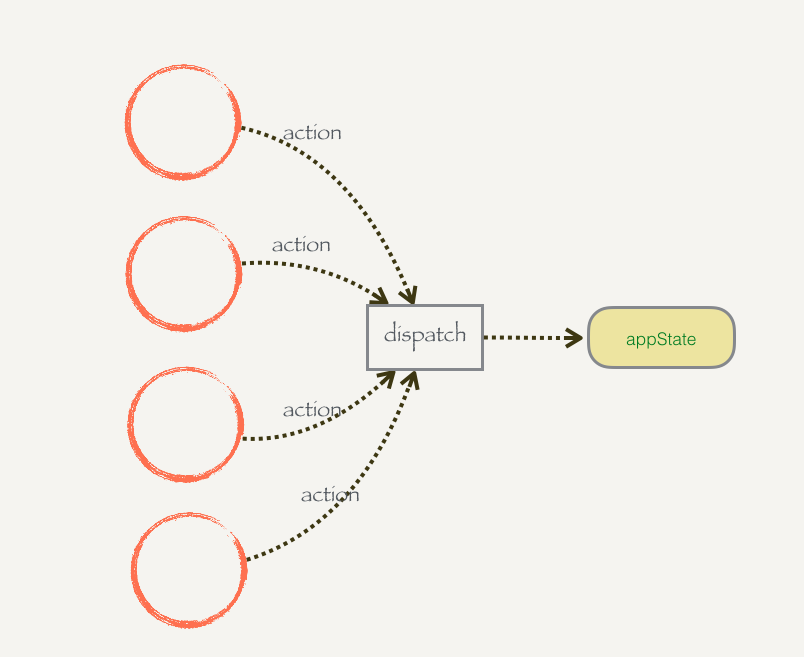
发起一个actions,指明你要对数据进行一个什么样的修改,然后dispatch这个actions。
dispatch({type: 'UPDATE_NAME', name: 'shen'})
然后在reducer中实际修改
function reducer(action) {
switch (action.type) {
case 'UPDATE_NAME':
return Object.assign({}, state, {name: action.name})
break;
}
通过subscribe方法订阅事件,当store里面的元素变化,则更新组件
store.subscribe(() => renderApp(store.getState()))
reducer不会直接修改store里面的数据,而是通过新属性覆盖旧属性的方式进行修改,这样做的目的是为了提高性能,比如store里面有2个属性:title,name,当name发生改变的时候我们只希望包含name的组件重新渲染,包含title的组件不变,那么我们可能会在订阅事件里做一些优化
function renderTitle(newTile, oldTile) {
if (newTitle === oldTitle) return
....
}
function renderName(newName, oldName) {
if (newName === oldName) return
....
}
直接修改store里面的name属性,因为对象属于同一个引用,所以判断相等的条件其实是不生效的。使用对象浅复制,name被一个新的对象覆盖了,他们的引用不同,就可以进行条件判断了。
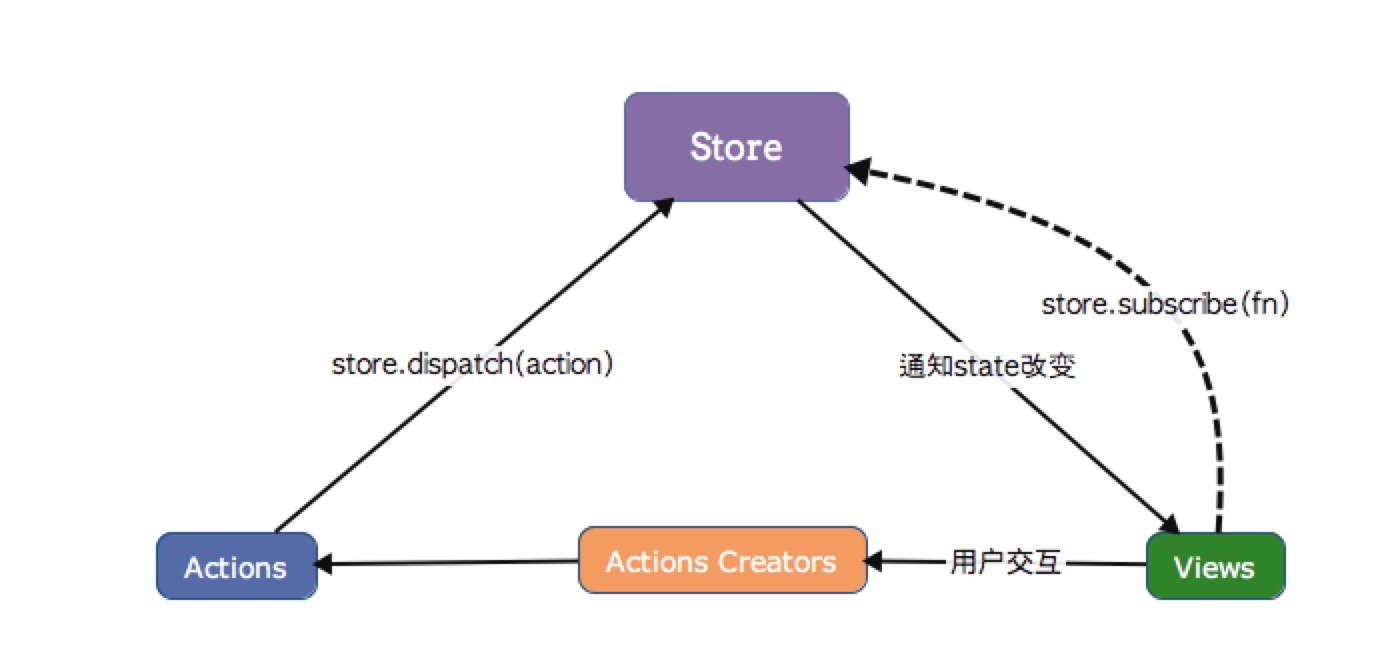
看看其实现原理
function createStore (state, reducer) {
const listeners = []
const subscribe = (listener) => listeners.push(listener)
const getState = () => state
const dispatch = (action) => {
reducer(state, action)
listeners.forEach((listener) => listener())
}
return { getState, dispatch, subscribe }
}
其实就是观察者模式:通过subscribe订阅更新事件,把事件push到listeners数组里,当dispatch的时候遍历listeners数组触发更新事件。
借助一个中间件,会让每一次修改都有迹可循
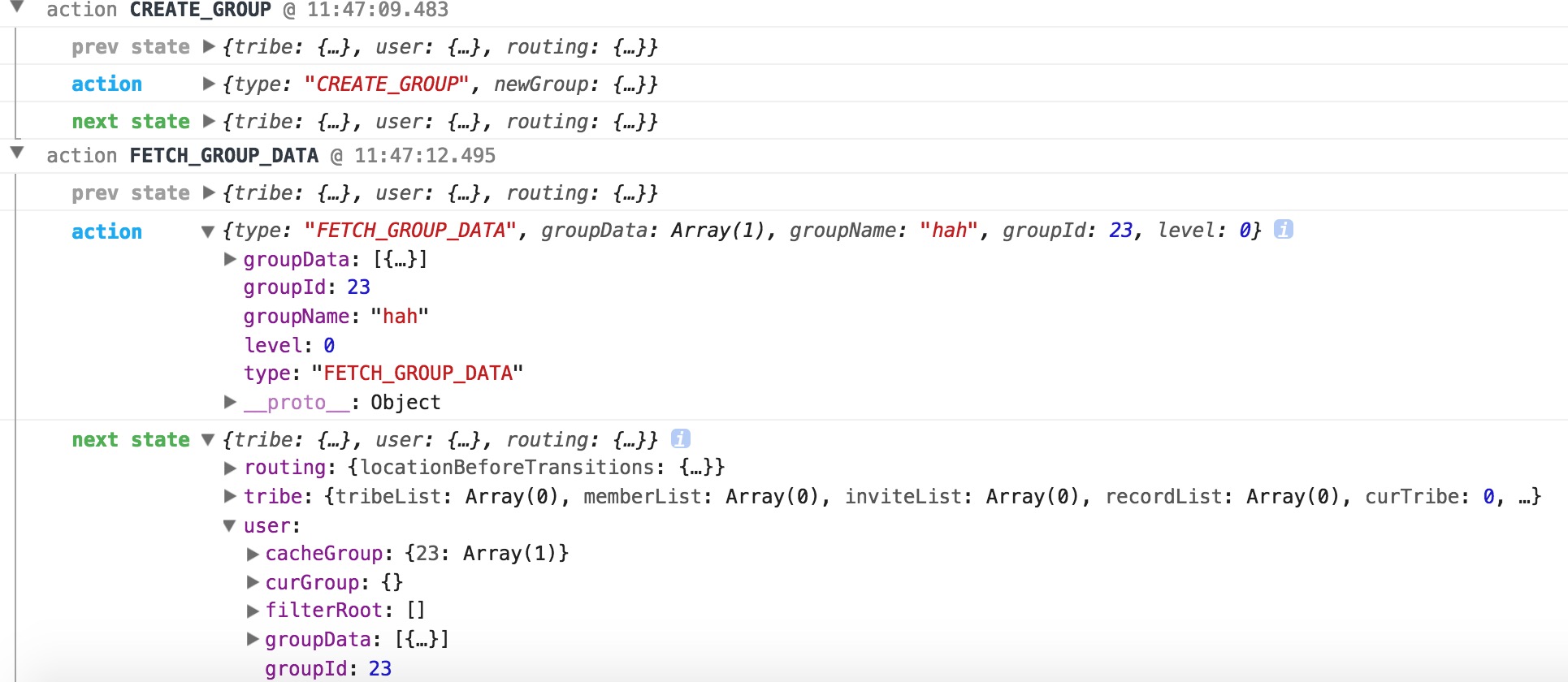
所以redux给自己下的定义就是:可预测的状态管理器。
redux适合复杂应用,两个兄弟组件需要通讯,就会采用状态提升的方式,把状态提升至父组件。试想一下如果业务比较复杂,react组件拆分得比较细,组件之间的讯通就不太好做了,这种时候可以把共享状态放在store里,如果状态只在当前组件中维持,那么就没必要放入store,这样就明白了什么时候该用redux了吧!
在开发的时候当组件的层级过多,数据一层一层的往下传递,当层级超过3层,数据传输的体验就会变得很糟糕!
react本身有一个解决的办法:使用context!在父组件定义了context,无论组件的层级有多深,子孙组件都可以通过this.context访问context中的数据。
但是这样会带来一个问题:组件与组件之间的耦合性太强。试想一下,当我们有另一个组件想复用这个子组件,那么我们还得先定义一个context,这显然不是一种优雅的做法!
我们希望我们所写的组件是一个纯组件,他不会带来任何副作用,使用者传入什么样的数据,组件就会渲染什么样的UI,于是就有人把context的部分抽象出去,就形成了react-redux。
import {Provider} form 'react-redux'
ReactDom.render(
<Provider store={store}>
<Home />
<User />
...
</Provider>, document.getElementById('app')
)
我们来看一下它内部是怎么实现的
export class Provider extends Component {
static childContextTypes = {
store: PropTypes.object
}
getChildContext() {
return {
store: this.props.store
}
}
render() {
return (
<div>{this.props.children}</div>
)
}
}
它其实就是把store放进context里面了,下面再看看connect的实现就知道它为什么要这样做了
用法:
class Switch extends React.Component {
render() {
...
}
}
Switch = connect(mapStateToProps, mapDispatchToProps)(Switch)
通过mapStateToProps筛选store里面的数据,通过mapDispatchToProps筛选store里面的actions
然后我们来看一下它内部是怎么实现的
export const connect = (mapStateToProps, mapDisPatchToProps) => (WrappedComponent) => {
class Connect extends Component {
static contextTypes = {
store: PropTypes.object
}
constructor() {
super()
this.state = {allProps: {}}
}
componentWillMount() {
const {store} = this.context
this._updateProps()
store.subscribe(() => this._updateProps())
}
_updateProps() {
const {store} = this.context
let stateProps = mapStateToProps ?
mapStateToProps(store.getState(), this.props) : {}
let dispatchProps = mapDisPatchToProps ?
mapDisPatchToProps(store.dispatch, this.props) : {}
this.setState({
allProps: {
...stateProps,
...this.props,
...dispatchProps
}
})
}
render() {
return <WrappedComponent {...this.state.allProps} />
}
}
return Connect
}
在_updateProps方法里面通过this.context拿到store里面的数据,放到this.state.allProps里面,在render方法里把this.state.allProps作为属性传递给WrappedComponent,这样在组件WrappedComponent就可以通过this.props拿到store里面的数据了。
再看willMount方法,通过store提供的subscribe订阅了一个更新事件(_updateProps),所以当store里面的数据改变了,connect组件就会更新,WrappedComponent也就随之更新了。
这样做的好处就是把context和WrappedComponent组件分离出来,WrappedComponent就成了一个纯组件了,如同上文所说,提供什么样的数据,WrappedComponent就会渲染什么样的UI。
react-router可以实现一个单页面的应用,它主要的方法有Link和Route。
<Link to="/about" replace="false" >About</Link>
看看其内部的实现原理
class Link extends Component {
handleClick = (event) => {
const { replace, to } = this.props
event.preventDefault()
replace ? historyReplace(to) : historyPush(to)
}
render() {
const { to, children} = this.props
return (
<a href={to} onClick={this.handleClick}>
{children}
</a>
)
}
}
const historyReplace = (path) => {
window.history.replaceState({}, null, path)
}
const historyPush = (path) => {
window.history.pushState({}, null, path)
}
用法:
<Route path="/about" component={About}/>
内部实现原理:
class Route extends Component {
componentWillMount() {
window.addEventListener("popstate", this.handlePop)
}
componentWillUnmount() {
window.removeEventListener("popstate", this.handlePop)
}
handlePop = () => {
this.forceUpdate()
}
render() {
const {
path,
exact,
component,
render,
} = this.props
const match = matchPath(window.location.pathname, { path, exact })
if (!match)
return null
if (component) {
return React.createElement(component, { match })
}
return null
}
}
const matchPath = (pathname, options) => {
const { path } = options
const match = new RegExp(`^${path}`).exec(pathname)
if (!match) return null
const url = match[0]
return {
path,
url
}
}
使用全家桶是为了解决我们在项目中所遇到的困难,请根据实际情况酌情使用
单页应用还是需要一个状态管理器,之前尝试过redux,后来觉得它的写法太繁琐了,还需要装各种依赖,弃之,使用一个较为简单的freactal。
providerState({
initialState,
effects,
computed,
})
不同于redux,freactal可以设置多个store,所以providerState有一个特性:在某个先加载的组件使用providerState提供了数据,那么后加载的组件使用providerState传入一个空对象,也可以拿到之前存入store里面的数据,比如:
providerState({})
可以理解为freactal虽然支持书写多个store,但是数据的来源是唯一的,只是写法上可以书写多个store.js用于区分不同的store,如果你不需要别的store里面的数据,可以使用injectState进行过滤。
injectState(component, key)
key用于筛选store里面的数据,再次声明:如果某个先加载的组件使用providerState往store里面添加的数据,那么后加载的组件使用providerState也是可以拿到这些数据的,所以通过injectState进行过滤你所需要的数据,只有过滤后的数据改变,才会触发对应的组件更新。
const effects = {
changeMenu: (effects, args) => mergeIntoState({currentMenu: args})
}
const initialState = () => ({
active: 'hello'
})
更多api请查看文档:freactal
最初接触状态管理容器的时候直接把接口请求中的数据往store里面丢,其实这是没有必要的,而且会让代码的书写变得十分的繁琐,于是认真思考了一下使用状态管理容器的初衷,总结有以下几点:
使用react开发通常会把组件细化,当组件的层级比较多,数据一层一层往下传递,书写的体验就会变得十分糟糕,在单页应用中,这个缺点会无限放大。
如果有些数据需要在多个组件**享,那么请放在store中。这样无论组件的层级有多深,大家都可以使用this.props拿到。
比如当子孙组件需要更新祖先组件的状态,用于显示一个Modal,那么代码会变成这样:
在祖先组件中定义一个方法:
showModal = (bool) => {
this.setState({show: bool});
}
方法通过层层传递,传入子孙组件中,调用该方法
this.props.showModal(true)
代码变得十分繁琐,也不优雅,不如把这个状态存入store,当store中的数据改变,UI会被更新,兄弟组件之间数据的操作更新UI其实也是同理。
定义store.js
import { mergeIntoState } from 'freactal';
// active为1是云阅读,2是蜗牛
const initialState = () => ({
active: '1',
});
const effects = {
toggleRadio: (effect, args) => mergeIntoState({active: args})
};
export default {
initialState,
effects
};
封装withStore.js
import { provideState, injectState } from 'freactal';
import createLogger from 'freactal-logger';
export default (store, keys) => (statefull) => {
const middleware = [];
if (process.env.NODE_ENV === 'development') {
const logger = createLogger({
collapsed: true
});
middleware.push(logger);
}
return provideState({
...store,
middleware
})(injectState(statefull, keys));
}
UI组件连接store
import store from './store';
import withStore from './withStore';
@withStore(store, ['active'])
class Result extends React.Component {}
react16.3.1已经更新了新的Context API,操作共享数据变得十分方便了,有空可以研究一下,但是它并不能替代状态管理容器,在单页的应用中,复杂的场景下,还是需要它。
接上文,react进行diff比较之后收集到节点更新信息patches,会一次性把变更信息更新,不可打断,这个阶段被称为commit。
首先进入一个beforeCommit节点,最主要的功能是在newNode.$el属性里面创建真实节点,比如div,h1等
做好准备工作之后开始正式commit的。
比如一个简单的移除节点操作:oldNode向上找父节点,通过父节点的api把这个节点移除。
function removeDOM(oldNode) {
let parent = findLatestParentDOM(oldNode)
let child = findLatestChildDOM(oldNode)
parent.$el.removeChild(child.$el)
}
更新节点操作:
newNode里面有一个props属性,通过setAttributes给节点设置新的属性,判断是否有on开头的属性,如果有则给节点绑定事件
function setAttribute(el, prop, val) {
// 处理事件
let isEvent = prop.indexOf('on') === 0
if (isEvent) {
let eventName = props.slice(2).toLowerCase()
el.addEventListener(eventName, val)
} else {
el.setAttribute(prop, val)
}
}
节点移动操作:
寻找newNode的父节点,在进行diff比较的时候会更新newNode的index值,通过这个值进行插入操作
function insertDOM(newNode) {
let parent = findLatestParentDOM(newNode)
let parentDOM = parent && parent.$el
if (!parentDOM) return
let child = findLatestChildDOM(newNode)
let el = child && child.$el
let after = parentDOM.children[newNode.index]
parentDOM.insertBefore(el, after)
}
比较不同的是如果newNode的类型是component,那么newNode.$el = null,不需要进行任何dom操作,因为这不是一个真实的dom节点,而是在diff的时候通过render方法把component里面的真实节点创建出来,再进行dom操作。
const renderer = new WebGLRenderer()
renderer.setSize(window.innerWidth, window.innerHeight)
renderer.setPixelRatio(window.devicePixelRatio)
new WebGLRenderer会在body里面生成一个canvas标签,当然如果你想在某个位置插入canvas可以在指定的dom元素appendChild(renderer.domElement)
setPixelRatio是为了兼容高清屏幕,在高清屏幕上绘图,会出现绘图不清晰的问题,设置setPixelRatio就好了
const scene = new Scene()
scene.background = new Color(0x333333)
首先我们来了解一下three.js的坐标
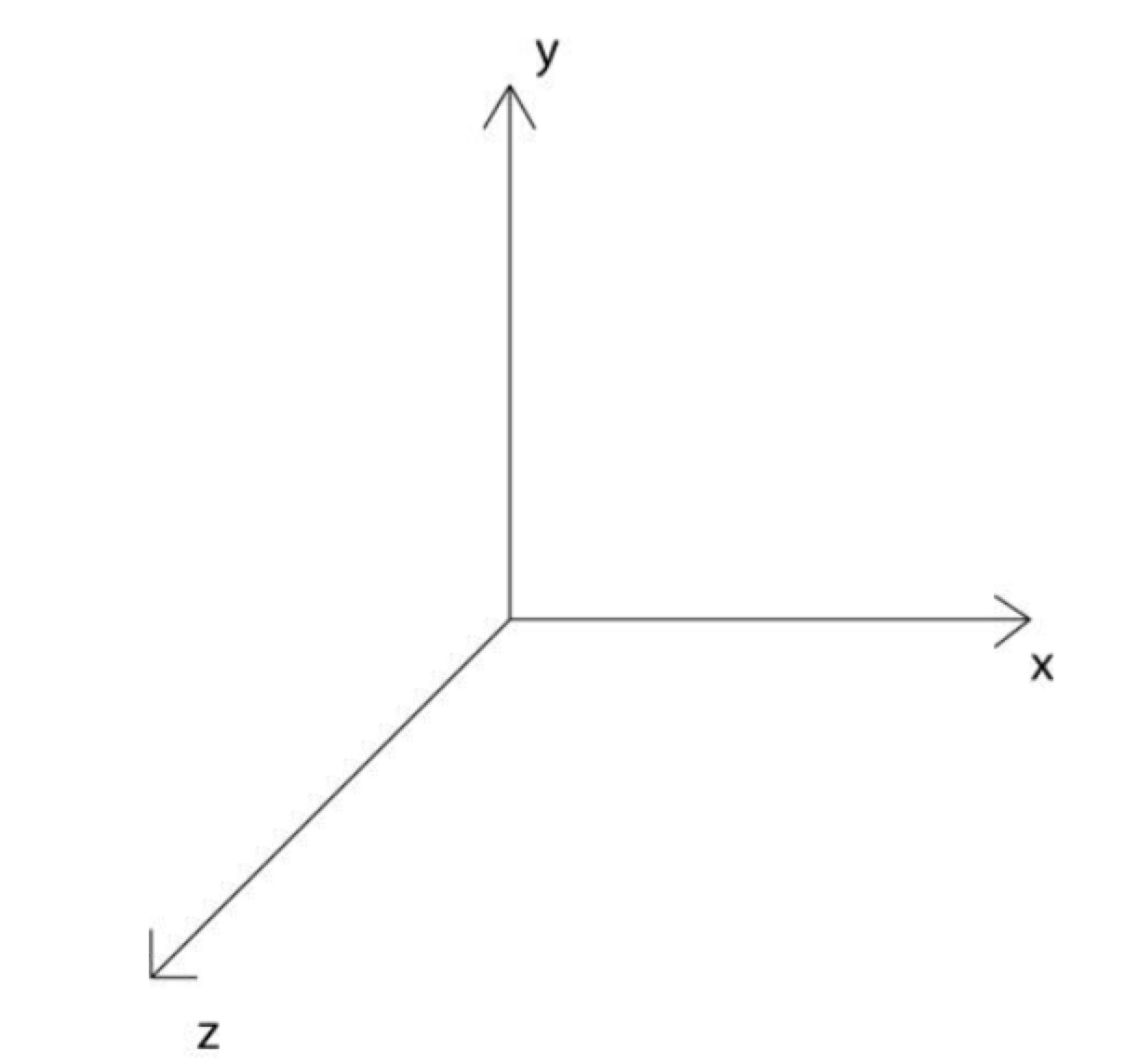
屏幕的中心,就是坐标(0,0,0)
用户所能看到的场景,需要通过照相机来呈现,相当于人的眼睛,照相机分为两种一种是正交投影照相机,一种是透视投影照相机,它们之间最大的区别是透视投影照相机会根据照相机位置的远近,物体会改变大小,更接近于人眼,在这里我们使用透视投影照相机(PerspectiveCamera)。
const camera = new PerspectiveCamera(70, this.options.width/this.options.height, 1, 10000)
camera.position.set(150, 250, 300)
camera.lookAt(new Vector3(0, 0, 0))
this.scene.add(camera)
如同自然界要有光一样,我们要设置光源,才能看到物体。这里我们使用平行光,可参考太阳光。
const light = new DirectionalLight()
light.position.set(0, 20, 20)
this.camera.add(light)
首先,先装一个引人模型的loader
npm i three-obj-loader
把一个.obj格式的3d模型加载进来就好了
const loader = new THREE.OBJLoader()
loader.load('assets/chair.obj', obj => {
obj.traverse(child=> {
if (child instanceof Mesh) {
child.material.side = THREE.DoubleSide
this.scene.add(obj)
}
})
})
首先安装一下这个库
npm i three-orbit-controls
然后
const controls = this.controls = new OrbitControls(this.camera)
controls.maxPolarAngle = 1.5
controls.minPolarAngle = 0.5
controls.rotateSpeed = 5.0
controls.zoomSpeed = 5
controls.panSpeed = 2
controls.onZoom = false
controls.noPan = false
controls.staticMoving = true
controls.dynamicDampingFactor = 0.3
controls.minDistance = 10
controls.maxDistance = 800
window.requestAnimationFrame(this.animate)
this.controls.update()
this.render()
js常用的继承方式有两种:原型链继承和对象冒充继承
function SuperType() {
this.property = true
}
SuperType.prototype.getSuperValue = function() {
return this.property
}
function SubType() {
this.subproperty = false
}
SubType.prototype = new SuperType()
var instance = new SubType()
instance.getSuperValue() // true
缺点: 父类引用类型的属性被子类修改,会影响到父类的值
function SuperType() {
this.colors = ['red', 'blue', 'green'];
}
function SubType() {
SuperType.call(this)
}
var instance = new SubType()
优点:改变子类的值不会影响父类。
缺点: 每次继承都会新开辟内存空间,有点浪费资源
function SuperType() {
this.color = ['red', 'blue']
}
SuperType.prototype.name = 'shen'
function SubType() {
SuperType.call(this)
}
SubType.prototype = new SuperType()
var instance = new SubType()
用一个对象来描述表单
const schema = {
type: 'object',
properties: {
input1: {
title: '简单输入框',
type: 'string',
required: true,
},
select1: {
title: '单选',
type: 'string',
enum: ['a', 'b', 'c'],
enumNames: ['早', '中', '晚'],
},
},
};
const mapping = {
string: 'input',
}
const widgets = {
input: Input
}
通过映射获取到需要渲染的组件
let widget = getWidgetName(schema, mapping)
const Widget = widgets[widgetName]
使用dom制作表单项
<div>
<label>{title}</label>
<Widget />
</div>
往mapping里面注册映射
{
site: 'Site'
}
往widgets里面增加组件
const widget = {
Site: <Site>
}
hidden: '{{rootValue.select1 === true}}'
如果schema里面有hidden属性,把对应的表单项隐藏就行
if (schema.hidden) {
return null;
}
执行js表达式
Function(str)()
const useForm = props = {
const form = {
setValues,
getValues
}
return form
}
用 async-validator这个库就行
最近开发了一个录取通知书活动,取得了比较好的效果,所以写篇文章总结一下经验,有兴趣的可以点击下方链接,请在移动端打开。
纯css实现方案
大概的代码
.animate .p3_d {
animation: p3D 1s ease-in 0.1s forwards;
}
@keyframes p3D {
0% {
transform: translate3d(24rem, 0, 0);
}
90% {
transform: translate3d(7.2rem, 0, 0);
}
100% {
transform: translate3d(8.2rem, 0, 0);
}
}
可以看到整体的动画效果其实不够灵活,显得呆板,影响动画效果的两个关键因素一个是关键帧(keyframes),一个是动画的过渡效果(transition-timing-function),这里使用的是ease-in,一般好的过渡效果都会用贝塞尔曲线实现(感觉都可以单独写一篇文章讲解贝塞尔曲线对动画的影响了,篇幅原因不做展开)。
个人建议如果设计师能够在这两个关键因素上提供帮助,那么就用css实现,如果不能,可以考虑其他的方案
使用dynamics.js实现
dynamics.js的官网,借助这个库可以实现一些逼真的物理运动动画
const p30 = document.querySelector('.p3_0');
dynamics.animate(p30, { translateX: '1.7rem' }, {
type: dynamics.spring,
frequency: 40,
friction: 200,
duration: 1000,
delay: 0.2
});
可以看到它的使用方式相当简单,要说缺点,个人感觉就是源码用coffee.js写的,这门语言现在基本已经被ts替代了,如果觉得它不能满足需求,想改源码可能比较困难,下面看一下使用dynamics.js实现的效果
其实动画效果就是这样,乍一看实现效果都差不多,但仔细看,它们之间还是会有很多细微的差别,往往就是这些微小的差别,值得我们深入研究,让动画效果显得更加灵动,逼真。
方式1:纯css实现类似的运动(不是随机)
可以参考这个例子,这个例子虽然不是真正的随机运动,但是实现效果也不错,所以做为一个参考的案例也放进来一起比较。
观察optionFloatAniP2Key的实现,可以看到,为了运动效果的平滑,设置了非常多的关键帧,这就非常依赖视觉把关键帧导出给前端,光靠前端自己可能很难实现这么丝滑的动画效果。
方式2:使用js实现随机运动
首先确定选项一开始运动的方向
我们想让选项可以往上下左右随机一个方向开始运动,可以这样实现:
function randomDirection(velocity) {
const isEventNum = Math.floor(Math.random() * 10) % 2;
return isEventNum == 0 ? velocity : -velocity;
}
const velocityX = randomDirection(0.2)
const velocityY = randomDirection(0.2)
这样每个选项一开始就会有[x, y], [-x, y],[x, -y], [-x, -y]四种选择,实现了初始运动方向的随机。
如图所示,红框是选项的运动范围(这里只是为了展示,实际范围会小很多)
如果最大范围是固定的,运动就显得呆板,可以让这个最大范围也随机一下
function randomMax(num) {
return num - Math.floor(Math.random() * num);
}
randomMax(25)
物体运动到最大范围时就让其往反方向运动,并且再次调用函数,更新最大范围的距离。比如第一次运动,物体x轴正方向最大运动范围是elemet.originLeft(originLeft是初始坐标值,这个值一直保持不变) + 25,达到这个坐标位置后,物体往返x轴负方向运动,并且更新最大范围x坐标值,那么下次物体再往x轴正方向运动的时候可能运动到elemet.originLeft + 20的位置就往负方向运动了,这就实现了运动距离的随机。
把随机运动的函数封装好,所有的选项都可以使用。
优势
这种实现方法的好处就是不需要设计师提供支持,毕竟不是每个设计师都能够把自己在AE上做的动画效果导出关键帧。
我们需要做的只是调一下物体运动的速度和最大运动距离即可。
实现方式1:操作dom
一开始我想到可以使用操作dom的方式实现,但是思考了一下,如果开一个定时器,频繁使用transform对dom进行translateX,translateY变换,在dom元素比较多的情况,低端的安卓机子上可能会存在性能问题,为了更好的用户体验,我放弃了这种实现方式。
实现方式2:canvas绘图
canvas绘图的实现方式性能优于操作dom,知道了随机运动的思路,实现起来其实并不难,无非就是调用drawImage()方法绘图,我这里就不再赘述了,只是canvas实现有一定的学习成本,大家可以了解一下,酌情使用。
绘图不清晰
现在的主流手机都采用高清屏,屏幕上的一个点需要用3个像素绘制。为了显示高清页面,我们的活动都使用宽度为1125的3倍图做视觉稿,canvas绘图也需要进行类似的处理,可以参考下面的文章
canvas点击事件处理
canvas绘制的图形不能像dom一样绑定一些点击事件,如果需要对绘制的图形进行交互操作如点击,可以根据点击的坐标进行判断
// 把需要点击的元素存在数组中
let clickElements = [a, b, c, d]
function onClick(clientX, clinetY) {
clickElements.forEach((element) => {
if (
clinetY > element.top
&& clinetY < element.top + element.height
&& clientX > clientX.left
&& clientX < element.left + element.width
) {
// 选中物体,进行一些操作
}
})
}
点击p4页面的选项,会有一个精灵动画,原理是这样的:
ctx.drawImage(image, sx, sy, sWidth, sHeight, dx, dy, dWidth, dHeight)
sx,sy是绘制的x,y坐标,比如第一帧绘制图片中的1区域,第二帧绘制图片中的2区域,以此类推,帧数切换的时候就会产生动画,所以这种效果被称为帧动画。
css的animation steps也是同理。
说到动画效果,不得不提一下lottie-web,通常设计师都会用AE软件制作动画,他们可以把做好的动画导出一份json文件,使用lottie-web执行,就能够完美的还原动画,使用方式也相当的简单:
lottie.loadAnimation({
renderer: 'svg',
loop: false,
autoplay: false,
container: document.querySelector('.p6_a'),
name: 'p6a',
animationData: p6aJson // 设计师导出的json
});
lottie-web能实现的动画效果有:
...等等
基本能满足大部分的动画场景,最大的好处就是能够大量节省开发时间以及和设计师联调的时间。
之前一提起要做动画效果,我想到的就是效果类的实现估计又得花上不少时间进行开发与调试,使用lottie-web确实可以大量提升效率。
这个库的体积也比较mini,只有67kb左右,兼容性也比较好,亲测在安卓4.4版本动画也能运行。
lottie-web的缺点
一些特效类的效果无法实现
点击元素需要切换图片的效果不好实现
lottie-web主要做一些用来展示用的动画,一些需要交互的动画可能要慎重考虑,比如p3页面的选项,点击之后需要切换图片这种就不太好做了。如果元素是纯色的可以实现,比如可以让设计师使用svg代替image,而svg的颜色可以继承父元素,点击元素之后切换颜色是可以做到的。
一些特效类的效果,可以考虑做为背景视频实现,比如第1页的转场
使用视频做动画的好处是效果炫酷,接入成本较低,如果一些动效通过技术手段不好实现,可以考虑做成视频接入,这类动效不能有交互操作,所以一般做为背景。
css实现动画
如果只是一些简单的动画效果,直接用css实现是最方便的。
复杂一点的效果最好让设计师提供keyframes,以及transition-timing-function,如果无法提供,可以考虑其他方案,不然很可能做出来之后要花费比较多的时间与设计师联调动效。
如果在安卓机子出现性能问题,需要优化一下性能,可以用下面两种方式。
// 方式1:
transform: translate3d(0,0,0);
// 方式2:
will-change: auto;
lottie动画
能够完美还原设计师在AE上制作的动画,大幅度节省开发,联调动效时间,常用于展示类型的动画,需要交互的元素酌情使用,大部分场景推荐使用。
js实现动画
利用js的能力可以实现一些使用css不好实现的效果,比如生成随机数,物体重力下落,物体碰撞回弹等物理运动,比如一个篮球运动员在运球,如果能越完美的还原篮球的运动轨迹,动画效果就会显得更真实。
js实现动画可以有2中方式:
帧动画
帧动画实现的效果较为自然,各种效果也都能实现,但受到图片大小的限制,比较适用于小型物体帧数较少的动画,比如题目选项,手势动作等。因为如果帧数过多,图片较大,对手机的渲染有压力。
视频动画
技术上不好实现的特效可以做成视频,但是视频的播放在移动端往往会遇到一些坑,也要考虑视频的大小,按需做预加载,并且在移动端通常需要点击才能播放视频。
移动端虽然使用了rem布局,但还是有某些特殊场景需要进行适配,比如页面在谷歌iphone5模拟器环境中页面下方被截断了一些
在真机上的表现那就更为不堪了。
要适配这种小屏幕的手机,可能我们会想到使用css的媒体查询。通过观察,我们可以看到元素的间距还是挺大的,可以通过调整间距来达到适配的目的。
coding...
// iphone 5
@media only screen
and (min-device-width : 320px)
and (max-device-height : 568px) {
div1 {
margin-top: xxx;
}
}
想法很美好,但是我们的活动需要在各种环境下投放,在安卓原生浏览器中,底部会带有返回,前进等操作的区域,这无疑让屏幕的显示区域变小了,即使是大屏手机,底部的元素也会被截取部分。而且我们也只适配了iphone5这个尺寸的手机,我意识到市面上手机尺寸繁多,如果出现了问题就要专门给这个尺寸的手机写个媒体查询,这并不是一种优雅的方案。
使用flex布局适配
首先我们先来了解一下flex的一些属性
接着观察页面
图中:1,2,3,4部分可以根据屏幕的尺寸进行动态缩小,序号,题目,图片,密封线等元素不要缩小,并且题目选项显示区域作为页面最主要的部分应该随着手机屏幕变大而动态调整。想好了思路之后开始着手实现
// 页面使用flex布局,并且将主轴设置为垂直方向
.page {
display: flex;
flex-direction: column;
width: 100%;
height: 100%;
}
// 图中标识为1的区域使用div填充
.div1 {
flex-basis: 0.95rem;
flex-shrink: 1;
}
// 题目显示区域,默认大小为13.36rem,即使空间不足也不缩小,空间剩余则变大
.content {
flex-shrink: 0;
flex-grow: 1;
flex-basis: 13.36rem;
}
... 其他元素类似
flex-shrink也可以定义缩小的优先级,比如div1的flex-shrink = 1,div2的flex-shrink = 2,则优先缩小div2的高度
flex-basis是一个非常关键的属性,通过flex-basis浏览器可以更准确的给项目分配空间,如果使用高度替代flex-basis,在ios 10.3版本会出现元素无法缩小的情况。
看看最终效果
结合autoprefixer,可以让flex布局有很好的兼容性,下面我们看看使用autoprefixer生成的兼容性代码display: -webkit-box的设备兼容情况
可以看到兼容性已经非常不错了
总结两种方案
由于活动中有好几个视频做为背景,为了给用户更好的观感体验,开发者通常会对视频进行预加载,下面来谈谈进行视频预加载的两种方式。
方式1:提前一个页面加载视频
如果你的页面遵循固定的访问顺序,比如p1 => p2 => p3,你可以考虑在访问p1的时候就先生成p2的video标签,并且给标签添加 preload="auto"属性,以此类推,达到一个预加载的目的。但是这种方式限制比较大。
方式2:提前请求视频资源数据
axios({
method: 'get',
url: 'video url',
responseType: 'blob'
}).then(res => {
const blobUrl = URL.createObjectURL(res)
// 生成video标签,并且设置src = blobUrl
})
blob就是视频的原始数据,通过createObjectURL,我们可以生成一个blob url,然后创建video标签,这样就可以达到一个预加载的目的。
如果觉得还不够保险,还可以监听video标签的canplaythrough事件,当浏览器判断视频可以无需缓冲,能够流畅的播放视频就触发此事件。
this.video.addEventListener('canplaythrough', () => {
callback && callback()
});
试想,活动一开始有一个loading,背后进行视频预加载,加载完毕后正式进入页面,这样的用户体验是比较好的。
这种实现方式可以适用于多种视频播放场景,但值得注意的是如果要请求站外的视频资源,需要处理一下跨域的问题。
视频播放的坑
生成video标签之后需要
this.video.load()
load()方法重置媒体成初始化状态,亲测如果在chrome中视频播放了多次,却没有调用load()方法,可能视频会无法播放,具体原因我还没了解清楚。
在移动端微信浏览器下,如果没有调用load()方法,某些ios手机无法触发canplaythrough事件。
某些安卓手机播放视频之前会黑屏进行解码,可以在视频上面蒙上第一帧图片,监听视频的timeupdate事件,当视频的currentTime属性有值的时候证明视频开始播放了,这时可以把图片隐藏。
伪代码实现,可做参考。
最后给大家推荐一本书《HTML5 Canvas核心技术图形动画与游戏开发》,这本书的教学风格是我喜欢的,首先介绍知识点,然后运用这些知识点做demo,缺点就是代码偏多,知识点讲解不够详细
最近做了一个组件,想发布到npm上,遇到了一些问题,所以记录一下心路历程。
如果你更换了淘宝源,请换回来,否则发布的时候会一直报404。
查看使用源
npm config get registry
使用npm源
npm config set registry https://registry.npmjs.org/
主要的文件放在lib文件夹下
./lib/index.js
export default CountDonw { ...}
./index.js是整个项目的入口文件
module.exports = require(./lib)
我希望组件不仅能通过
npm i CountDown --save
import CountDown from 'CountDown'
的方式使用,而且还能直接把dist.js下下载,通过script的方式使用,这就需要配置一下webpack
./webpack.config.js
output: {
library: 'CountDown',
libraryExport: 'default'
}
这样配置就改变了webpack的打包方式,可以通过script,然后new CountDonw(...)使用了。
在官网上注册一个账号,然后把账号加入注册表
npm adduser
查看当前的用户
npm whoami
执行
npm publish
更改一下package.json里面的version,然后执行
npm publish
Alkaid是一个vscode插件,它提效的核心是提供常用的物料,可以满足多数管理后台开发场景,借助vscode的能力将物料插入工程项目中,以提高开发效率,它具有良好的拓展性,用户可以自主开发物料达到业务功能复用的目的
我们做技术方案之前一般都需要对现有的技术做对比,一方面是开拓视野,一方面是比较它们的优势与劣势,才能够更好的挑选出符合自身业务的技术,并且针对自身的业务需求,对技术进行优化与改进,使其更适合我们的业务开发
如何快速生成一个页面,有些同学可能会想到利用可视化编辑器,配置一下就能够快速创建一个页面,管理后台的实现一般也比较固定,也许是一个可行的方案,仔细思考了一下,可视化编辑器生成页面优点与缺点如下
==优点==
==缺点==
总结:
可视化编辑器更适合非技术人员使用(产品,运营),降低人力投入成本,适合一些功能较为固定的页面开发
我们元气事业部的管理后台相当多
不同的管理后台,功能实现上有差异,比如流量分发管理后台,数据来源很多,有些数据存储在后端数据库中,有些从数据组那边通过es方式获取,还有些则从算法推荐组获取,对于后端来说,他们要做的就是把这些数据收集,做成一个接口返回,让前端处理成自己想要的数据结构
比如表格的树形数据
需要处理成以下结构
data = [
{
xxx,
children: [
{
xxxx,
children: []
}
]
}
]
这些一般都得前端自己处理,这么多管理后台,它们或多或少都有自己独特的开发需求,可视化编辑器灵活性不足,显然无法适用
初学前端时,我挺喜欢开发管理后台的需求,因为可以使用antd提供的UI组件,学习大佬们如何进行组件封装,直到我接了一个需求,开发一个管理后台,里面七八个页面功能都差不多,开发好一个页面之后剩下的就是复制粘贴,对表格列,表单项,接口实现等进行修改,相当繁琐。
开发管理后台的需求,这些很少涉及逻辑的模板代码占比较大,个别后台数据很多,可能会有10 ~ 20列表格,7 ~ 10个搜索条件,以及新建弹窗里面的表单项数量也很多,还会带有一些表单联动的功能,于是我萌生了往工程项目当中插入模板代码的想法
我还想到可以通过接口文档生成模板代码,一般接口文档的response就是表格的每一列,request就是表格的查询条件
听起来很不错吧,经过实践,我总结了插入模板代码方案的一些优缺点
==优点==
==缺点==
总结:
往工程中插入模板代码面向的人群是开发,目的是为了提高开发效率,灵活性与拓展性是其最大的优势,适用于开发过程中需要编写大量模板代码的场景,比如管理后台的需求。
逻辑的处理需要自己实现,当然对于开发来说实现逻辑功能最简单的办法就是自己动手,这也是编程的乐趣所在
经过对比,Alkaid选择了插入模板代码方案,因为其灵活性和拓展性更好,能够满足多种管理后台开发场景
Alkaid的架构设计如下:
简单介绍一下各层级的作用:
存储层
服务层
使用层
总结:
分层的目的是为了解耦,新增或者修改物料,只需使用cli将最新的代码上传到bit.dev,node server 5分钟轮询,Alkaid插件可以使用新版本的物料了
上面介绍了往工程插入模板代码缺点之一就是逻辑实现需要动手开发,vscode插件可以稍微减弱这个缺点,在开发的时候,打开Alkaid插件,选择你想要的物料,配置好以后将代码插入到工程目录,或者光标位置,接着编写一些逻辑,插件的使用与编码是一体的,体验较好
物料配置
物料的源码是一些ejs代码,需要配置的地方用占位符占位,结合接口文档的response就可以把表格的每一列配置好了
搜索项也是利用接口文档的request生成配置,这里就不赘述了,通过接口文档生成的配置项,在Alkaid的配置页面都可以进行二次修改
效果展示
开发管理后台的需求表单是必不可少的功能,antd表单的写法比较繁琐,特别是弹窗表单会经常使用,有时候还带有表单联动以及表单动态增减功能,开发起来难度增加了不少,需要想办法提高效率
我想到的办法是使用json schema提高表单的开发效率,举例:
表单的联动
例子中切换'物料类型'与'安装依赖',都有表单项对其联动
对比这两种写法,使用json schema实现,代码确实简洁了不少(大约减少40%左右的代码),json schema方式实现表单联动,只需要增加hidden属性,判断某个表单项的值即可
hidden: '{{formData.type === "block"}}'
总结:
可能有同学会问:jsonschema代码看不懂,不好维护怎么办?
这个就是我说的学习成本了,其实要读懂json schema代码也很简单,观察几个比较典型的比如Input,Select,Radio,其生成的json schema,对比一下就能找到规律,掌握规律之后读懂并不难,毕竟其本质就是用一个对象的属性描述表单而已
维护方面其实也不用担心,一般json schema都与可视化编辑器配套使用,将json schema导入,即可看到渲染结果
当然,我觉得最好用的还是导出功能,在可视化编辑器里面拖动ui组件,点击按钮就可以导出jsonschema,不需要自己动手编写
Alkaid通过接口文档生成json schema简直不要太开心呢,表单项基本就是接口文档的request,Alkaid内置的可视化编辑可以对生成好的表单项进行二次修改,比如文档定义的imgUrl是string类型,会生成一个Input框,但是后端实际想要的是一个图片的nos地址,这个时候就可以通过可视化编辑器将Input框组件修改成图片上传组件
可以看一下使用的效果
json schema需要一个render才能将其渲染成表单,我选择的是 form-render ,原因是它的概念很少,用法也很简单,我们团队大部分的同学都没接触过json schema,使用一套简单的方案可以降低大家的学习成本,毕竟提效的目的是为了减轻开发负担,并且我仔细阅读了form-render的源码,确定它的实现能够满足我们的业务开发需求才决定使用,并且作为提效方案的主负责人,组内其他成员开发过程中肯定会遇到各种问题,了解其源码实现我才能快速定位并且解决问题
如果有更高的要求,可以尝试 formily,它的性能更好,当然学习成本也相应增加了
以上介绍了带搜索表格,弹窗表单两种场景,但实际开发当中,需求肯定远不止这些,在开发过程当中觉得这个功能有复用的价值都可以在物料仓库封装一个物料,Alkaid提供了配套的工具,alk-cli可以创建物料开发模板,内置的命令可以将物料上传至bit.dev
我们有一个前端工程,其常量,通用方法,业务组件越来越多,大家对于比人封装的功能不熟悉,所以复用率很低,Alkaid内置的jsdoc功能,按照约定的格式书写文档,可以生成文档展示
工程内也有一些svg图标,编辑器无法直接查看,导致同样的图片重复添加
Alkaid还可以方便的查看工程内的所有SVG图片,开发之前先看看工程已有的图片,防止重复添加
它们的用法很简单,只需要在工程的根目录下新建一个配置文件,指定目录即可
alkaid-config.js
[
{
"type": "shared",
"items": [
{
"docPath": "./shared/utils/common/*",
}
],
},
{
"type": "images",
"dirPath": "./shared/icons/svg-icons"
}
]
最后展示一下大家关心的提效数据,我们团队,已经有6名成员使用过Alkaid,在5个管理后台使用Alkaid开发过需求,具体的提效数据与使用者的熟练度有一定的关系,比如我作为Alkaid的作者,提效还是比较明显的
最开始我们也只是想开发一个管理后台提效工具,后来发现利用vscode plugin的能力,可以解决工程开发痛点,于是开发了一些拓展能力,我们前端组内工程还有很多,她们或多或少都会遇到这样那样的问题,Alkaid可以尝试解决
管理后台提效方面,可以做的事情其实还有很多,比如物料的丰富,逻辑编写能否有更好的解决方案,以及工具成熟完善之后可以考虑开源等。
const parser = require('@babel/parser')
function depAnalyse(modulePath) {
// 将代码解析为ast抽象语法树
const ast = parser.parse(code)
}
this.depAnalyse(path.resolve(this.root, this.entry))
function depAnalyse(modulePath) {
...
// 当前模块依赖数组,存放当前模块所有依赖的路径
let dependencies = []
traverse(ast, {
CallExpression(p) {
if (p.node.callee.name === 'require') {
// 修改require
p.node.callee.name = '__webpack_require__'
// 修改当前模块 依赖模块的路径 使用node访问资源必须是'./src/xxx'的形式
let oldValue = p.node.arguments[0].value
oldValue = './' + path.join('src', oldValue)
// 避免window的路径出现 "\"
p.node.arguments[0].value = oldValue.replace(/\\/g, '/')
// 每解析require,就将依赖的模块路径放入dependencies中
dependencies.push(p.node.arguments[0].value)
}
},
})
const sourceCode = generator(ast).code
// 收集依赖
this.modules[modulePathRelative] = sourceCode
// 遍历数组,递归收集依赖
dependencies.forEach((depPath) => {
// 传入模块的绝对路径
this.depAnalyse(path.resolve(this.root, depPath))
})
}
(() => {
var __webpack_modules__ = ({
// 使用模板语法进行遍历 k就是模块ID
<% for (let k in modules) {%>
"<%- k %>":
(function (module, exports, __webpack_require__) {
eval(`<%- modules[k]%>`);
}),
<%}%>
})
var __webpack_module_cache__ = {};
function __webpack_require__(moduleId) {
var cachedModule = __webpack_module_cache__[moduleId]
if (cachedModule !== undefined) {
return cachedModule.exports
}
var module = __webpack_module_cache__[moduleId] = {
exports: {}
}
__webpack_modules__[moduleId].call(module.exports, module, module.exports, __webpack_require__)
return module.exports
}
var __webpack_exports__ = __webpack_require__("<%-entry%>")
})()
通过ejs的render,将收集好的依赖渲染
function emitFile() {
// 将占位符modules替换
let result = ejs.render(template, {
entry: this.entry,
modules: this.modules,
})
let outputPath = path.join(
this.config.output.path,
this.config.output.filename
)
fs.writeFileSync(outputPath, result)
}
这就将文件合并好了
(() => {
var __webpack_modules__ = ({
// 使用模板语法进行遍历 k就是模块ID
"./src/index.js":
(function (module, exports, __webpack_require__) {
eval(`const moduleA = __webpack_require__("./src/moduleA.js");`);
}),
"./src/moduleA.js":
(function (module, exports, __webpack_require__) {
eval(`const moduleB = __webpack_require__("./src/moduleB.js");
console.log('moduleA模块,成功导入' + moduleB.content);
module.exports = {
content: 'moduleA模块'
};`);
}),
"./src/moduleB.js":
(function (module, exports, __webpack_require__) {
eval(`module.exports = {
content: 'MD_B'
};`);
}),
})
var __webpack_module_cache__ = {};
function __webpack_require__(moduleId) {
var cachedModule = __webpack_module_cache__[moduleId]
if (cachedModule !== undefined) {
return cachedModule.exports
}
var module = __webpack_module_cache__[moduleId] = {
exports: {}
}
__webpack_modules__[moduleId].call(module.exports, module, module.exports, __webpack_require__)
return module.exports
}
// 递归执行每个__webpack_modules__的value方法
var __webpack_exports__ = __webpack_require__("./src/index.js")
})()
因为遍历的时候使用倒序遍历
webpack在编译的过程中有一些生命周期,可以在声明周期执行一些plugin,内部实现了一个发布订阅模式,比如我在插件内部订阅了一个完成事件,webpack内部编译完成之后订阅事件就会被触发
等等
了解实现原理是为了更好的理解在使用react hook的疑问,比如:
一步一步实现吧,先定义两个变量
let memorizedState = []
let cursor = 0
function useState (initialValue) {
memorizedState[cursor] = memorizedState[cursor] || initialValue
const currentCursor = cursor
function setState (newState) {
memorizedState[currentCursor] = newState
render()
}
return [memorizedState[cursor++], setState]
}
具体使用
const [count, setCount] = useState(0)
初始化的时候传入一个0把它存入memorizedState,setCount内部通过setState改变组件的状态
function useEffect (callback, depArray) {
const hasNoDeps = !depArray
const deps = memorizedState[cursor]
const hasChangeDeps = deps ? depArray.some((el, i) => el !== deps[i]) : true
if (hasNoDeps || hasChangeDeps) {
callback()
memorizedState[cursor] = depArray
}
cursor++
}
具体使用
useEffect(() => {
console.log(count)
}, [])
每使用一次useEffect都会在memoizedState里面存储一下当前的依赖depArray,当依赖改变的时候才会执行callback
Q:为什么只能在函数最外层调用Hook,不要在循环,条件判断或者子函数中调用?
A:memoizedState数组是按hook定义顺序来放置数据的,如果hook顺序变化,memoizedState并不会感知到
Q:为什么useEffect第二个参数是空数组,就相当于ComponentDidMount,只会执行一次?
A:useEffect遍历第二个参数数组,发现与memoizedState数组中的元素相比并没有改变,所以不会执行callback
Q: 自定义的 Hook 是如何影响使用它的函数组件的?
A:共享同一个 memoizedState,共享同一个顺序
Parcel 使用工作进程启用多核编译,并具有文件系统缓存,即使在重新启动后也可快速重新构建。
先来看一张官网给的数据图片:
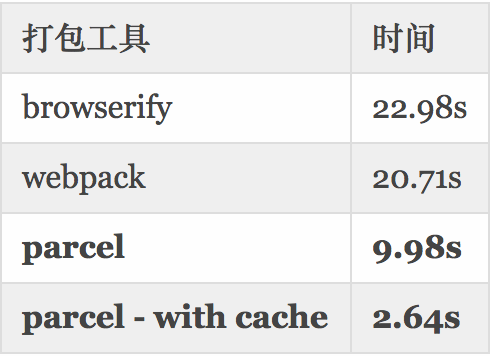
可以看到它的打包速度比其他打包工具快很多。
ParcelJS 本身是 0 配置的,但 HTML、JS 和 CSS 分别是通过 posthtml、babel 和 postcss 处理,可以根据自己的需要配置.babelrc与.postcssrc与.posthtmlrc文件。
举个列子:用Parcel搭建一个react开发环境:
npm install --save react
npm install --save react-dom
npm install --save-dev parcel-bundler
npm install --save-dev babel-preset-env
npm install --save-dev babel-preset-react
然后新建一个.babelrc文件
{
"presets": ["env", "react"]
}
如果想使用预编译处理器,那就更简单了,以sass为例:
npm install node-sass
./index.js
import './style.scss'
执行
parcel index.html
就可以快乐玩耍了!
由于是一个新的打包工具,功能上还有些不完善。
parcel目前还不能用于实际开发,但是如果平时想写个demo,又嫌弃webpack的配置繁琐,开源的脚手架又过于笨重,parcel是一个很好的选择,相信它会越来越好!
最近接了一个seo优化的需求,运用到了phantomjs,它可以说是一个没有ui的webkit浏览器,所以它可以抓取由ajax返回的数据所生成的dom,这是爬虫所需要的。总体优化的思路便是:配置nginx,判断如果是爬虫,则将请求转发到自己配置的web server服务器上,使用phantomjs抓取完整的html并且返回给爬虫。下面一步一步实现这个功能。
不多说,直接上代码。
./spider.js
'use strict'
// 单个资源等待时间,避免资源加载后还需要加载其他资源
var resourceWait = 500
var resourceWaitTimer
// 最大等待时间
var maxWait = 5000
var maxWaitTimer
// 资源计数
var resourceCount = 0
// phantomjs webpage模块
var page = require('webpage').create()
// nodejs系统模块
var system = require('system')
// 从cli中获取第二个参数为目标url
var url = system.args[1]
// 设置phantomjs视窗大小
page.viewportSize = {
width: 1280,
height: 1014
}
var capture = function (errCode) {
// 外部通过stdout获取页面内容
console.log(page.content)
// 清除定定时器
clearTimeout(maxWaitTimer)
// 任务完成,正常退出
phantom.exit(errCode)
}
// 资源请求并计数
page.onResourceRequested = function (req) {
resourceCount++
clearTimeout(resourceWaitTimer)
}
// 资源加载完毕
page.onResourceReceived = function (res) {
// chunk模式的http回包,会多次触发resourceReceived事件,需要判断资源是否已经end
if (res.stage !== 'end') {
return
}
resourceCount--
if (resourceCount === 0) {
// 当页面中全部资源加载完毕后,截取当前渲染出来的html
// 由于onResourceReceived在资源加载完毕就立即被调用了,我们需要给一些时间让js跑解析任务
resourceWaitTimer = setTimeout(capture, resourceWait)
}
}
// 资源加载超时
page.onResourceTimout = function (req) {
resourceCount--
}
// 资源加载失败
page.onResourceError = function (err) {
resourceCount--
}
// 打开页面
page.open(url, function (status) {
if (status !== 'success') {
phantom.exit(1)
} else {
// 当改页面的初始html返回成功后,开启定时器
// 当到达最大时间(默认5秒)的时候,截取渲染出来的html
maxWaitTimer = setTimeout(function () {
capture(2)
}, maxWait)
}
})
每次都要使用terminal,输入命令并指定url,这样显然不够通用,需要配置一个web server,动态抓取html。
./app.js
var express = require('express')
var app = express()
// 引入nodejs的子进程模块
var child_process = require('child_process')
app.get('*', function (req, res) {
// 完整url
var url = req.protocol + '://' + req.hostname + req.originalUrl
// 预渲染后的页面字符串容器
var content = ''
// 开启一个phantomjs子进程
var phantom = child_process.spawn('phantomjs', ['spider.js', url])
// 设置stdout字符编码
phantom.stdout.setEncoding('utf8')
// 监听phantom的stdout, 并拼接起来
phantom.stdout.on('data', function (data) {
content += data.toString()
})
// 监听子进程退出事件
phantom.on('exit', function (code) {
switch (code) {
case 1:
console.log('加载失败')
res.send('加载失败')
break
case 2:
console.log('加载超时:' + url)
res.send(content)
break
default:
res.send(content)
break
}
})
})
app.listen(3000, function () {
console.log('Spider app listening on port 3000!');
})
新建一个phantom.conf文件
# 定义一个Nginx的upstream为spider_server
upstream spider_server {
server localhost:3000;
}
server {
listen 80;
server_name yuedu.163.com;
# 指定一个范围,默认 / 表示全部请求
location / {
proxy_set_header Host $host:$proxy_port;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# 当UA里面含有Baiduspider的时候,流量Nginx以反向代理的形式,将流量传递给spider_server
if ($http_user_agent ~* "Baiduspider|twitterbot|facebookexternalhit|rogerbot|linkedinbot|embedly|quora link preview|showyoubot|outbrain|pinterest|slackbot|vkShare|W3C_Validator|bingbot|Sosospider|Sogou Pic Spider|Googlebot|360Spider") {
proxy_pass http://spider_server;
}
}
}
./ nginx.conf
include phantom.conf
十多年来,我们一直使用 XMLHttpRequest(XHR)来发送异步请求,XHR 很实用,但并不是一个设计优良的 API,在设计上并不符合职责分离原则,输入、输出以及状态都杂糅在同一对象中,使用事件机制来跟踪状态变化。基于事件的模型与最近流行的 Promise 和 generator 异步编程模型不太友好
有别于ajax的事件机制,fetch采用Promise来实现,使我们的代码书写起来更优雅
fetch(url).then(resp => {
if (resp.ok)
...
})
在react的使用中,为了一个ajax把整个jquery引进来值得吗?或许fetch是一个不错的选择!
function Fetch(url, options) {
return fetch(url, {credentials: 'include', ...options})
.then((res) => res.json())
.then(json => json)
.catch((e) => console.log('error', e))
}
再封装一个GET方法
function GET(url, data = {}, options = {}) {
this.send = () => {
const _url = encodeQuery(url, data);
return Fetch(_url, {
method: 'GET',
...options
},)
.then((res) => res)
.catch((err) => {throw err})
}
}
使用起来很简单
new GET('url', {params})
.send()
.then(resp => {
你的操作...
})
然后是POST方法
function POST(url, data = {}, option = {}) {
this.send = () => {
return Fetch(url, {
method: 'POST',
headers: {
"Content-Type": "application/json"
},
body: typeof data === 'object' ? JSON.stringify(data) : data,
...option
})
.then(res => res)
.catch((err) => {throw err})
}
}
使用方法
new POST(url, {params})
.send()
.then()
resful API 还有
其实现于POST方法类似
当然了,如果你想再项目中使用fetch,需要引入一个polyfill,其源码400行左右,不大。
npm i fetch-polyfill --save
import 'fetch-polyfill';
世间安得两全法,不负如来不负卿。
对象浅拷贝只拷贝引用,当被拷贝的对象属性被修改的时候,也会影响原对象属性
var a = {name: 'shen'}
var b= a
b.name = 'kong'
console.log(a.name) // 输出kong
深拷贝从新开辟了一个内存空间,修改拷贝对象的属性,不会对原对象产生影响
var a = {name: 'shen'}
var b = JSON.parse(JSON.stringify(a))
只比较一层,深层次的对象嵌套不比较
function shallowEqual(objA, objB) {
// 过滤一些不是对象的比较
if (Object.is(objA, objB)) return true
if (
typeof objA !== 'object'
|| objA === null
|| typeof objB !== 'object'
|| objB === null
) {
return false
}
const keysA = Object.keys(objA)
const keysB = Object.keys(objB)
if (keysA.length !== keysB.length) return false
for (let i = 0; i < keysA.length; i++) {
// hasOwnProperty判断这个key是否objB也有
if (!objB.hasOwnProperty(keysA[i]) || !Object.is(objB[keysA[i]], objA[keysA[i]])) {
return false
}
}
return true
}
console.log(shallowEqual({name: 'shen', age: 12}, {name: 'shen', age: 13})) // false
react是当下十分流行的一个专注于view层的库,并不是一个完整的mvvc框架。它的出现掩盖了jquery的锋芒,倍受前端大神们的推崇。
早期的jquery核心是操作dom,但是随着现在的应用越来越复杂,频繁的dom操作会让代码变得难以维护,于是就有人提出了可以把状态和视图绑定在一起,当状态改变就更新视图,这样就摆脱了dom操作,早期的backbone就是这么做的。
但是backbone没有解决的问题是性能问题,更新视图的最原始的方式是把之前的dom树移除,插入一个新的dom树,然而操作dom的成本是十分昂贵的,试想一下:如果我只需要改变一下按钮的颜色,就必须生成一颗新的dom树,这不是很浪费性能吗?所以backbone只适合做一些小型的应用。
react的出现解决了这个性能瓶颈,它在更新视图之前,通过比较两颗新旧虚拟dom,找出差异,然后只更新有差异的那一部分dom,实现了既把状态和视图绑定在一起,又保证了性能。
dom元素3个重要的特性是:
js可以用对象来储存这3个属性,从而模拟dom元素
function Element (tagName, props, children) {
this.tagName = tagName
this.props = props
this.children = children
}
Element.prototype.render = function () {
var el = document.createElement(this.tagName) // 根据tagName构建
var props = this.props
for (var propName in props) { // 设置节点的DOM属性
var propValue = props[propName]
el.setAttribute(propName, propValue)
}
var children = this.children || []
children.forEach(function (child) {
var childEl = (child instanceof Element)
? child.render() // 如果子节点也是虚拟DOM,递归构建DOM节点
: document.createTextNode(child) // 如果字符串,只构建文本节点
el.appendChild(childEl)
})
return el
}
可以这样使用
var el = require('./element')
var ul = el('ul', {id: 'list'}, [
el('li', {class: 'item'}, ['Item 1']),
el('li', {class: 'item'}, ['Item 2']),
el('li', {class: 'item'}, ['Item 3'])
])
var ulRoot = ul.render()
document.body.appendChild(ulRoot)
可见通过render方法就可以生成一个真正的dom元素,并且把它插入document。
如果想完整的比较两颗虚拟dom树之间的差别,时间复杂度是 O(n^3) ,这无疑太慢了,是不能运用在开发当中的。由于前端很少会跨级别操作dom,所以diff只会比较同一层级的dom,这样时间复杂度就将为O(n)。
深度优先遍历旧的虚拟dom树,每遍历到一个节点,就和对应的新的虚拟dom树上的节点进行比较。
function diff (oldTree, newTree) {
var index = 0
var patches = {}
dfsWalk(oldTree, newTree, index, patches)
return patches
}
function dfsWalk (oldNode, newNode, index, patches) {
var currentPatch = []
// Node is removed.
if (newNode === null) {
// Real DOM node will be removed when perform reordering, so has no needs to do anthings in here
// TextNode content replacing
} else if (_.isString(oldNode) && _.isString(newNode)) {
if (newNode !== oldNode) {
currentPatch.push({ type: patch.TEXT, content: newNode })
}
// Nodes are the same, diff old node's props and children
} else if (
oldNode.tagName === newNode.tagName &&
oldNode.key === newNode.key
) {
// Diff props
var propsPatches = diffProps(oldNode, newNode)
if (propsPatches) {
currentPatch.push({ type: patch.PROPS, props: propsPatches })
}
// Diff children. If the node has a `ignore` property, do not diff children
if (!isIgnoreChildren(newNode)) {
diffChildren(
oldNode.children,
newNode.children,
index,
patches,
currentPatch
)
}
// Nodes are not the same, replace the old node with new node
} else {
currentPatch.push({ type: patch.REPLACE, node: newNode })
}
if (currentPatch.length) {
patches[index] = currentPatch
}
}
diff操作将节点之间的差异记录下来,在patch进行更新,其实本质就是dom操作。
var REPLACE // 重新渲染dom节点
var REORDER // 更新子元素
var PROPS // 更新props
var TEXT // 文本节点,更新内容
function applyPatches (node, currentPatches) {
_.each(currentPatches, function (currentPatch) {
switch (currentPatch.type) {
case REPLACE:
var newNode = (typeof currentPatch.node === 'string')
? document.createTextNode(currentPatch.node)
: currentPatch.node.render()
node.parentNode.replaceChild(newNode, node)
break
case REORDER:
reorderChildren(node, currentPatch.moves)
break
case PROPS:
setProps(node, currentPatch.props)
break
case TEXT:
if (node.textContent) {
node.textContent = currentPatch.content
} else {
// fuck ie
node.nodeValue = currentPatch.content
}
break
default:
throw new Error('Unknown patch type ' + currentPatch.type)
}
})
}
初学react的人可能会有疑惑:人人都说react的虚拟dom快,性能好,但是实际运用的时候发现和原生的操作dom并没有明显的速度上的差异。其实react从来没有说过它比原生的js快,因为最终的本质都是dom操作,只是它的出现改变了前端的编码方式,从繁杂的dom操作过渡到通过状态的改变更新视图。
高阶组件,一个挺起来很高大上的词汇,但是使用起来却是相当简单。
高阶组件是一个函数,传给它一个组件,它返回一个新的组件
const newComponent = higherOrderComponent(OldComponent)
其实现原理
import React, { Component } from 'react'
export default (WrappedComponent, name) => {
class NewComponent extends Component {
constructor () {
super()
this.state = { data: null }
}
componentWillMount () {
let data = localStorage.getItem(name)
this.setState({ data })
}
render () {
return <WrappedComponent data={this.state.data} />
}
}
return NewComponent
}
它其实就是对WrappedComponent组件进行一些封装,比如说有一些公共的数据可以放在高级组件里面处理,然后传递给WrappedComponent,这样WrappedComponent就可以通过this.props拿到了。
这样做的好处是如果有多个组件需要相同的数据,可以把组件传递给高级组件即可。
react是单向数据流,从父组件传入子组件。试想一下,当组件的层级非常的深,数据一层一层传递下去,这将会是一场灾难,react自身提供的解决办法就是使用context!
class Index extends Component {
static childContextTypes = {
themeColor: PropTypes.string
}
constructor () {
super()
this.state = { themeColor: 'red' }
}
getChildContext () {
return { themeColor: this.state.themeColor }
}
render () {
return (
<div>
<Header />
</div>
)
}
}
这样子组件就可以通过this.context拿到了。
class Header extends Component {
static contextTypes = {
themeColor: PropTypes.string
}
render () {
return (
<h1 style={{ color: this.context.themeColor }}>React.js 小书标题</h1>
)
}
}
但是不建议在开发中使用context,因为我们希望组件是一个纯组件,给其传入什么样的数据,它就会显示什么样的UI,当你使用了context,就意味着别人想复用你的组件就必须先定义context,这无疑不是一种优雅的做法。
但是这个功能确实很实用,于是就有人把context的部分抽象出来。形成了react-redux。
这两个方法虽然不常用,但是在某些特定的场景下实用会有一个很好的效果。
进程与线程的概念十分容易混淆,为了加强记忆和方便理解,写一篇博客记录一下
微前端其中一个重要的组成部分是沙箱,我们的沙箱使用shadowDom进行不同应用间的样式隔离,不同的子应用使用不同的fakeWindow,避免全局变量的污染,使用proxy处理document和XMLHttprequest等特殊内容。
对于一些不需要代理的属性,最了一些兜底的操作,所有的设置都在fakeWindow对象上,便于清除。
个项目如果时间比较久远,就会遇到技术栈比较老旧,难以维护的问题,如果继续使用当前的技术栈迭代需求开发所需要的工时就会比较长,也比较容易出bug。
我们有一个管理后台newbackend技术栈比较老旧用的是(react15+antd2xx),使用老技术迭代新功能比较耗时,于是就用微前端技术进行改造,总体的结构图如下:
左侧的菜单栏是主应用,右边的内容区域是子应用,入下图就是newbackend子应用。
切换菜单栏的时候对路由进行匹配,带umi的就是新项目umi-manager,如下图,使用reacthook+antd4.xxx技术栈进行开发,提高开发效率。
使用微前端技术,以左侧菜单栏为主应用,将newbackend-manage与umi-manage两个子应用作为内容区域进行整合,通过路由匹配进行切换,这样设计对于使用这的体验非常友好,切换不同的应用基本无感知,不破坏原有的交互设计,新的页面在umi-manage子应用中进行开发,可以使用新的技术提高开发效率。
我们需要新开发的管理后台数量较多(超过10个),它们的业务相对独立,一般都需要申请独立的部署和运行资源(服务器,部署集群,nginx配置等),后台的使用频率不一定,有些比较低,为每个后台申请独立资源存在浪费,后台的数量比较多,管理起来也比较困难。
首先介绍一下项目架构设计,我们有一些管理后台比如直播,流量分发等,开发好之后进行打包通过脚手架将js,css等资源上传到应用平台,应用平台把资源进行db存储并且提供接口给主应用调用,主应用区分测试环境,线上环境,拿到不同子应用的资源文件在沙箱中运行,子应用发起的接口请求都由node转发到不同的后端服务。
应用平台类似于ndp的功能,接收子应用的资源文件存储到数据库,并标上版本号,可以通过版本号切换进行回滚和上线操作。
通过在主应用点击入口,跳转不同的路由,进入匹配的子应用,比如/live是直播管理后台,/dispatch是流量分发管理后台,这样设计可以把多个管理后台的入口整合到一个页面中,方便管理,只需要将主应用部署到服务器,获取子应用的资源文件放入沙箱SDK中即可运行,避免上文所说的资源浪费,通过应用平台发布和回滚版本可以免去部署集群申请和nginx配置,提高工作效率。
当我们书写react的时候每次都要在js文件中书写这样的代码
import React from 'react'
是不是感到很厌烦,webpack有一个解决的办法,在webpack.config.js里面加入一个plugins
new webpack.ProvidePlugin({
React: 'react'
})
于是我们就不用再引入react了,可以直接这样书写
class Hello extends React.Compoent {}
浏览器会缓存js文件,以提高响应的速度,当我们发布新的版本的时候,可以给js文件加上一个hash值,这样浏览器就会认为它是一个新的文件,就不会从缓存中取了。
new webpack.HashedModuleIdsPlugin()
output: {
filename: '[name].[chunkhash].js',
path: path.resolve(__dirname, 'build/dist'),
hashDigestLength: 8
}
但是在index.html文件中,怎么知道js的hash值呢,可以通过一个插件
new HtmlWebpackPlugin({
template: path.resolve(__dirname, './src/index.html')
})
把react和redux,react-router等公共的模块提取到单独的 vendor chunk 文件中,是比较推荐的做法,这是因为它们很少像本地的源代码那样频繁修改。可以利用客户端的长效缓存机制
entry: {
main: './src/pages/index.js',
vendor: ['react', 'react-router', 'react-dom']
},
new webpack.optimize.CommonsChunkPlugin({
name: ['vendor', 'manifest']
})
当我们修改main.js的时候,vendor的hash值也会发生变化,就达不到缓存的目的了,加入manifest,修改main.js之后,vendor文件的hash不会发生改变。
但是这样会多出一个manifest文件,多一个请求,可以使用一个插件,将其并入html
const InlineManifestWebpackPlugin = require('inline-manifest-webpack-plugin');
new InlineManifestWebpackPlugin({
name: 'webpackManifest'
}),
./html
<%=htmlWebpackPlugin.files.webpackManifest%>
这样manifest文件就并入html中了
在打包的时候,我们希望dist文件夹下没有多余的文件,可以用这个插件,它会清理掉多余的文件
const CleanWebpackPlugin = require('clean-webpack-plugin')
new CleanWebpackPlugin(['build/dev'])
我们会区分开发环境和生产环境,可以用下面这个插件来实现
new webpack.DefinePlugin({
'process.env': {
'NODE_ENV': JSON.stringify('production')
}
})
let MODE = process.env.MODE
下面这个插件会帮你把没有用到的代码剔除,称之为Tree Shaking
const UglifyJSPlugin = require('uglifyjs-webpack-plugin')
new UglifyJSPlugin({
sourceMap: true
})
如果使用react-router-proxy-loader,则希望显示js文件的名字,而不是数字,出bug的时候方便定位js文件,可以使用
output: {
filename: '[name].[chunkhash].js',
chunkFilename: '[name].[chunkhash].js',
}
在output里面指定library和libraryExport可以让js用script的方式引入
output: {
filename: '[name].js',
path: path.resolve(__dirname, 'build/dev'),
library: 'CountDown',
libraryExport: 'default'
}
使用umd让组件可以import引入
output: {
filename: 'index.js',
path: path.resolve(__dirname, 'build/dist'),
library: 'CountDown',
libraryTarget: 'umd'
}
配置多页
entry: {
index: './src/pages/index.js',
room: './room/index.js',
result: './result/index.js'
}
output: {
filename: '[name].js',
path: path.resolve(__dirname, './build/dev')
}
使用moment.js的时候语言包很大,估计300kb左右,可以使用ContextReplacementPlugin只打包中文语言包。
plugins: [
new webpack.ContextReplacementPlugin(
/moment\/locale$/,
/zh-cn/
)
]
解决webpack-dev-server的host错误
devServer: {
disableHostCheck: true
},
taro3以前是编译时,使用babel-parser将taro源码解析成抽象语法树,然后通过babel-types进行一些修改,转换操作,最后通过babel-generate生成对应的目标代码
因为小程序没有dom,为了在小程序端运行React代码,它自己模拟实现了一套DOM、BOM API
TaroElement主要就是实现了模拟dom节点
class TaroElement extends TaroNode {
props
setAttribute(qualifiedName, value) {
this.props[qualifiedName] = value as string
}
addEventListener() {}
}
比如实现模拟document,主要是实现document的一些方法
public createElement (type) {
const element = controlledComponent.has(type)
// 判断是否form类型
const element = controlledComponent.has(type)
? new FormElement()
: new TaroElement()
retrun element
}
class Window extends Events {
navigator = navigator
setTimeout() {}
clearTimeout() {}
}
因为taro的DOM和BOM是自己模拟实现的,所以需要搞一个适配器,将一些方法重写
const hostConfig = {
createInstance() {
// 使用taro-runtime的document
return document.createElement(type)
}
}
搞定了taro-runtime和taro-react之后就差不多了,因为react底层也是调用浏览器的宿主API,这些API runtime都实现了
如果有数据需要临时缓存,并且数据过一段时间就过期,那么使用redis是比较合适的。尤其在性能优化方面,所需要的数据直接从redis里面拿,返回给调用者,这会缩短数据加载的时间。
brew install redis
redis-server
redis-cli
get http://yuedu.163.com/
由于是在node中操作redis,需要安装一个库
npm i redis --save
npm i bluebird --save
下面举个栗子
var redis = require('redis')
var bluebird = require('bluebird')
var config = require('./config')
bluebird.promisifyAll(redis.RedisClient.prototype)
class Cache {
constructor() {
this._init()
}
_init() {
this.client = redis.createClient(config.port, config.host, {no_ready_check: true})
this.client.auth(config.password, function () {
console.log('通过认证!')
})
this.client.on('ready', function (res) {
console.log('ready')
})
this.client.on('error', function (err) {
console.log('Error: ' + err)
})
}
get(key) {
return this.client.getAsync(key)
}
set(key, value) {
return this.client.setAsync(key, value)
}
expire(key) {
return this.client.expire(key, config.expireTime)
}
exit() {
this.client.quit()
}
}
module.exports = new Cache
createClient 的时候一定要加no_ready_check,否则连接远端的redis-server的时候会一直报错。
目前遇到的问题
解决的思路
总体定为vscode插件 + schema可视化 在项目中插入代码的形式
一些概念
用于做组件共享的平台
==它能做什么?,与npm相比有什么优势==
开发一个npm包首先新建一个工程,执行npm init等操作,后续的维护也只能在这个工程里面进行
bit则可以在任意的工程封装组件,比如觉得A工程的CountDown组件可以用于多工程共享,通过export把组件上传到bit dev cloud
在B工程就可以通过npm install的方式安装CountDown组件,如果想对组件进行迭代,也可以通过import的方式下载源码,修改之后打上tag上传至bit dev cloud
总之优点就是十分灵活:在任意工程封装组件,在任意工程维护组件
区块为ejs模板
将ejs模板与nei-ts-hepler结合,生成好代码之后插入到项目中
与直接在bit dev上copy差不多,只是省去了安装的过程,而是由vscode 安装依赖并且将代码插入到光标位置
区块
组件
应该提供的模块文件
实现方式猜想
目的是为了本地通过配置mock数据就能看到区块的效果
因为区块都是在同一个项目中,可以使用同一套构建配置,ejs渲染等....
首先得了解两个基本概念:react 16以前使用的是Stack Reconciler,react 16使用的是Fiber Reconciler。
Stack Reconciler通过递归的形式遍历Virtual DOM,一旦执行不可中断,如果更新任务运行时间过长,就会堵塞布局,动画的运行,可能导致掉帧,他的调用栈如下:
当每秒绘制的帧数(fps)达到60时,页面是流畅的,1s 60 帧,每一帧分到的时间是 1000 / 60 ≈ 16 ms,所以我们书写代码力求不让一帧的工作量超过16ms
一帧内需要完成如下六个步骤:
两帧之间主线程通常会有一小段空闲时间,requestIdleCallback可以在这个空闲期(Idle Period)调用空闲期回调(Idle Callback),执行一些任务
Fiber Reconciler每执行一段时间,都会将控制权交回给浏览器,可以分段执行:
优先级高的任务(如键盘输入)可以打断优先级低的任务(如diff)的执行。
Fiber Reconciler在执行的过程中,会分为2个阶段:
由于阶段一可以打断,某些生命周期可能会执行多次,比如willMount,所以建议一些有副作用的操作比如请求数据,放入didMount中进行
Fiber树本质上是一个链表,它有3个属性:child指向它的子节点,sibling指向它的兄弟节点,return指向它的父节点
const fiber = {
child,
sibling,
return
}
遍历Fiber树的过程为:
通过child遍历子节点,如果没有子节点就通过sibling遍历兄弟点,没有子节点也没有兄弟节点就通过return返回父节点,继续遍历直到没有子节点也没有兄弟节点为止。
用一张图片说明:
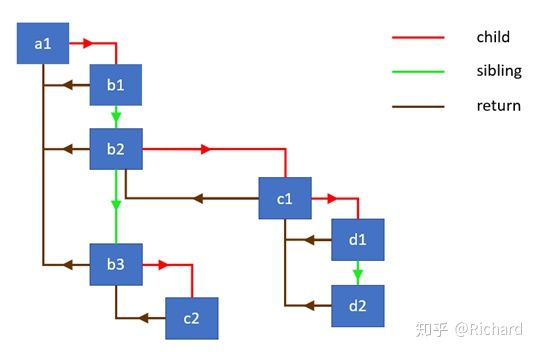
遍历的过程为:
a1 => b1 => b2 => c1 => d1 => d2 => b2 => b3 => c2 => b3 => a1
用代码说明diff中断之后是怎么恢复的
let cursor = newFiber
while (cursor) {
// 判断当前diff是否超时,如果超时则把控制权交给浏览器,执行优先级更高的操作
if (shouldYield()) {
return true
} else {
cursor = performUnitWork(cursor, patches)
}
}
function performUnitWork(fiber, patches) {
if (fiber.$child) return fiber.$child
while (fiber) {
if (fiber.$child) return fiber.$child
fiber = fiber.$parent
if (!fiber) return null
}
}
可以看到在第一个while循环中,得益于fiber数的链表设计,即使diff暂停了,继续循环的时候还是会从当前的节点开始遍历
// 重点
newFiber.oldFiber = oldFiber
performUnitWork(newFiber, patches)
function performUnitWork(fiber, patches) {
let oldFiber = fiber.oldFiber
let oldChildren = oldFiber && oldFiber.children || []
// 对比当前新旧节点
diffFiber(oldFiber, fiber, patches)
// 对比新旧子节点
diffChildren(oldChildren, fiber.children, patches)
}
有一个比较重要的操作,newFiber中存储了旧的节点信息,在进行diff比较的时候两个新旧节点就算更改了顺序,还是比较同一个节点。
举个列子:div下有两个子节点h1和h2,setState之后h1和h2位置进行互换,但是进行diff比较的时候还是新的h1和旧的h1进行比较。
进行diffFiber比较的时候主要比较:
let attrs = diffAttr(oldNode.props, newNode.props)
// 如果props更新,patches则打上更新标记
if (Object.keys(attrs).length > 0) {
patches.push({ type: UPDATE, oldNode, newNode, attrs })
}
// 是否需要移动节点
if (oldNode.index !== newNode.index) {
patches.push({ type: MOVE, oldNode, newNode })
}
diffChildren主要比较新旧子节点的个数,如果新的子节点个数少了,则移除
typeMap.forEach((arr, type) => {
arr.forEach(old => {
patches.push({ type: REMOVE, oldNode: old, })
})
})
schedule主要控制在render阶段是否执行当前任务,如果当前操作比较耗时,则把控制权交回给浏览器,让浏览器执行更高优先级的操作,比如用户输入,动画等。
requestIdleCallback可以在浏览器空闲的时候进行调用。
requestIdleCallback((deadline) => {
let remain = deadline.timeRemaining()// 当前帧剩余可用的空闲时间
}, {timeout: 超时时间})
// 一秒30帧
frameLength = 1000 / 30
function getCurrentTime() {
return +new Date()
}
// 是否需要暂停操作
function shouldYield() {
return getCurrentTime() > frameDeadline
}
frameDeadline = getCurrentTime() + Match.min(remain, frameLength)
执行scheduleWork先获取超时的时间,然后在workLoop循环里面就可以用当前的时间和超时的时间进行比较了(shouldYield)。
还有一个点是当一次diff比较两颗虚拟dom树root和root2,还没比较完毕用户的某些操作又生成了新的虚拟dom树root3,这时候会取消root和root2的比较,哪怕此次diff已经进行了一半,因为此时root2只是中间态,没有必要进行展示了。
react会从头开始进行root和root3的diff。取消diff的操作很简单,用示例说明一下:
let currentRoot // 保存当前diff过程新的根节点,判断是否需要重置diff流程
function diff(oldFiber, newFiber) {
if (currentRoot && currentRoot !== newFiber) {
cancleWork()
}
currentRoot = newFiber // 记录
}
cancleWork无非也就是将循环遍历赋值为null的操作
阅读react的源码是一件相当耗时的工作,因为源码十分庞大,直接阅读性价比较低,建议先看别人造好的轮子,只提取fiber最精华的部分进行阅读,可以节省相当大的时间。对于阅读源码来说,最重要的是了解背后的**,在使用的时候就能避免一些坑,不需要纠结单行代码的实现差异。
webgl可以给用户带来一场体验上的革命,现在一些互联网巨头已经在这个领域有所涉猎,比如腾讯的up2017活动。作为一个有理(zhuang)想(bi)的前端,怎么能不技痒,搞一波事情呢?
three.js是webgl的一个库,封装了各种方法,可以方便的制作3d场景。
const renderer = new WebGLRenderer()
renderer.setSize(window.innerWidth, window.innerHeight)
renderer.setPixelRatio(window.devicePixelRatio)
一般来说,场景没有很复杂的操作,在程序最开始的时候进行实例化,然后将物体添加到场景中即可。
const scene = new Scene()
scene.background = new Color(0x333333)
首先了解一下three.js的坐标.
屏幕的中心,就是坐标(0,0,0)
用户所能看到的场景,需要通过照相机来呈现,相当于人的眼睛,照相机分为两种一种是正交投影照相机,一种是透视投影照相机,它们之间最大的区别是透视投影照相机会根据照相机位置的远近,物体会改变大小,更接近于人眼,在这里我们使用透视投影照相机(PerspectiveCamera)。
const camera = new PerspectiveCamera(70, this.options.width/this.options.height, 1, 10000)
camera.position.set(150, 250, 300)
camera.lookAt(new Vector3(0, 0, 0))
this.scene.add(camera)
如同自然界要有光一样,threejs需要设置光源,才能看到物体。这里使用平行光,可参考太阳光。
const light = new DirectionalLight()
light.position.set(0, 20, 20)
this.camera.add(light)
材质是与渲染效果相关的属性,通过设置材质可以改变物体的颜色,纹理贴图,光照模式等。
使用基本材质(BasicMaterial)的物体,渲染后物体的颜色始终为该材质的颜色,而不会由于光照产生阴影效果,如果没有指定材质的颜色,则颜色是随机的,其构造函数是。
THREE.MeshLambertMaterial(opt)
有时候,我们希望使用图像作为材质。这时候,就需要导入图像作为纹理贴图,并添加到相应的材质中。
const textureLoader = new TextureLoader()
const texture = textureLoader.load(url)
new MeshBasicMaterial({
map: texture,
side: BackSide
})
创建物体需要用到网格(Mesh),网格是由点,线,面等组成的物体,其中几何形状决定了物体顶点位置信息,材质决定了物体的颜色,纹理等信息。
var material = new THREE.MeshLambertMaterial({
color: 0xffff00
});
var geometry = new THREE.CubeGeometry(1, 2, 3);
var mesh = new THREE.Mesh(geometry, material);
scene.add(mesh);
创建网格之后,就可以把它添加到场景中了。

可以想象一下我们在房间内,房间是一个立方体,如果你有生活品味,可能会在房间内贴上壁纸,three.js可以很方便的创建一个立方体,并且给它的周围贴上纹理,让照相机在立方体之中,照相机可以360旋转,就模拟了一个真实的场景。
const path = 'assets/image/'
const format = '.jpg'
const urls = [
`${path}px${format}`, `${path}nx${format}`,
`${path}py${format}`, `${path}ny${format}`,
`${path}pz${format}`, `${path}nz${format}`
]
const materials = []
urls.forEach(url => {
const textureLoader = new TextureLoader()
const texture = textureLoader.load(url)
materials.push(new MeshBasicMaterial({
map: texture,
overdraw: true,
side: BackSide
}))
})
const cube = new Mesh(new CubeGeometry(9000, 9000, 9000), new MeshFaceMaterial(materials))
this.scene.add(cube)
使用three.js创建几何体是十分方便的,但是对于人或者动物这样非常复杂的模型使用几何体组合就非常麻烦了。因此,three.js允许用户导入由3ds max等工具制造的三维模型,并添加到场景中。
let loader = new THREE.OBJLoader();
loader.load('assets/chair.obj', obj => {
obj.traverse(child=> {
if (child instanceof Mesh) {
child.material = new MeshLambertMaterial({
side: DoubleSide
})
this.scene.add(child)
}
}
})
})
用户所能看到的场景都是通过照相机呈现的,通过改变照相机的位置,就可以实现视角的旋转
import initOrbitControls from 'three-orbit-controls'
const controls = this.controls = new OrbitControls(this.camera)
controls.maxPolarAngle = 1.5
controls.minPolarAngle = 0.5
controls.rotateSpeed = 5.0
animate() {
window.requestAnimationFrame(this.animate)
this.controls.update()
this.render()
}
一个3d模型是由点,线,面组成的,可以遍历模型的每一个点,把每一个点转换为几何模型,并且给它贴上纹理,拷贝每一个点的位置,用这些几何模型重新构成一个只有点的模型,这就是粒子效果的基本原理。
initPointSystem(geometry) {
this.points = new Group()
const vertices = []
const texture = new TextureLoader().load('assets/image/dot.png')
geometry.vertices.forEach((o, i) => {
vertices.push(o.clone())
const _geometry = new Geometry()
const pos = vertices[i]
_geometry.vertices.push(new Vector3())
const color = new Color()
color.r = Math.abs(Math.random() * 10)
color.g = Math.abs(Math.random() * 10)
color.b = Math.abs(Math.random() * 10)
const material = new PointsMaterial({
color,
map: texture,
blending: AddEquation,
depthTest: false,
transparent: true
})
let point = new Points(_geometry, material)
point.position.copy(pos)
this.points.add(point)
})
return this.points
}
three.js的点击事件需要借助光线投射器(Raycaster),为了方便理解,请先看一张图:
Raycaster发射一个射线,intersectObject监测射线命中的物体
this.raycaster = new Raycaster()
// 把你要监听点击事件的物体用数组储存起来
this.seats.push(seat)
onTouchStart(event) {
event.preventDefault()
event.clientX = event.touches[0].clientX;
event.clientY = event.touches[0].clientY;
this.onClick(event)
}
onClick(event) {
const mouse = new Vector2()
mouse.x = ( event.clientX / this.renderer.domElement.clientWidth ) * 2 - 1
mouse.y = - ( event.clientY / this.renderer.domElement.clientHeight ) * 2 + 1;
this.raycaster.setFromCamera(mouse, this.camera)
// 检测命中的座位
const intersects = this.raycaster.intersectObjects(this.seats)
if (intersects.length > 0) {
intersects[0].object.material = new MeshLambertMaterial({
color: 0xff0000
})
}
}
着色器分为顶点着色器和片元着色器,用GLSL语言编写,是一种和GPU沟通的的语言,这里只讲如何使用
// 设置物体的质材为着色器质材
let material = new ShaderMaterial({
uniforms: uniforms,
vertexShader: vertext,
fragmentShader: fragment,
transparent: true,
})
虽然在国外的网站,以及国内某些互联网公司已经对webgl有了应用,但是它还属于一个比较新的东西,所以在移动端最低要求为:ios 8,安卓5.0。
seo优化一般有2种方式:一种是服务端渲染。使用这种方式,网站要写2套代码,一套是给普通用户浏览的,一套是用于百度爬虫抓取信息,但是这样维护起来工作量就是double的了,所以试试使用无头浏览器进行seo优化。
与之相对的,无头浏览器进行seo优化维护起来比较方便,只需要书写一套代码,就可以进行多个平台的seo优化。
现在市面上的无头浏览器主要有2种:phantomjs与puppeteer,phantomjs已经不在维护,抓取某些页面的时候会出现无法抓取到数据的bug,并且性能不佳。踩坑过后,弃之,使用puppeteer,发现性能有了小小提升,并且可以准确抓取页面信息。
一个小demo:
const puppeteer = require('puppeteer');
const url = 'https://guofeng.yuedu.163.com/book_reader/9a766e4fd7694375be56f956e3cb9e4f_4/fa956a0a3892452a8b2905d81c48b41c_4';
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.goto(url, {
waitUntil: 'networkidle0'
});
const content = await page.content();
console.log('content', content);
await browser.close();
})
流程图:
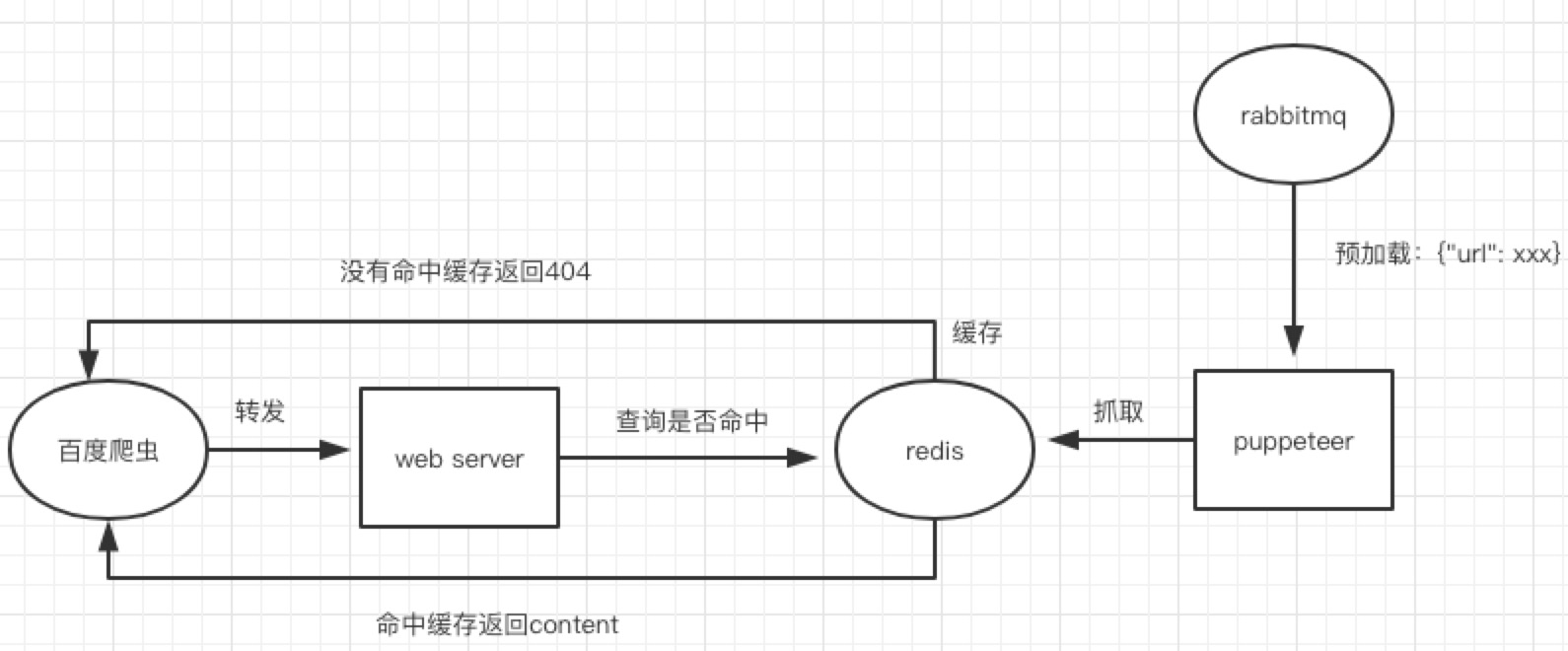
rabbitmq是用来做消息推送的,比如给我推送一个消息{"url": xxx},我就可以抓取url的数据,并且存入redis中。
它有点像观察者模式

publisher会把消息推送给所有订阅过事件的comsumer
使用rabbitmq的好处就是和业务解耦。如果接入不同的平台进行seo,我这边不需要调整代码,给我推送什么消息,我就抓取什么网站的数据。
数据的储存使用redis,有一个库,可以方便的对redis进行操作。
var redis = require("redis"),
client = redis.createClient()
client.set("key", "value")
client.get("key")
client.expire("key", time)
使用redis的好处有:
使用express写的web server
app.get('*', function (req, res) {
let queryParameters = req.query;
let url = queryParameters.url;
if(!url) {
res.status(400).send('url required');
return;
}
cache.get(url, function(err, result) {
if (result) {
res.status(200).send(result)
}
....
})
puppeteer抓取页面还是比较慢的,可以通过禁用image,style请求来提高一下性能。
await page.setRequestInterception(true);
page.on('request', request => {
if (request.resourceType() === 'image' || request.resourceType() === 'stylesheet') {
request.abort();
}
else {
request.continue();
}
});
puppeteer每次launch相当于重新打开一次浏览器,试想一下,如果每次处理请求,都要launch,请求处理完毕之后都要关闭,这无疑是比较耗费时间的。可以把launch之后生成的browser实例存入一个池中,需要的时候从池中索取browser实例,抓取页面完毕之后再把实例放回池里。
这样可以大大提高性能,尤其是处理并发请求的时候,这里需要借助一个库generic-pool。
const genericPool = require('generic-pool');
const factory = {
create: () => puppeteer.launch(...puppeteerArgs).then(instance => {
return instance
}),
destroy: (instance) => {
instance.close()
}
};
const pool = genericPool.createPool(factory, opts);
// 使用资源
pool.acquire()
// 释放资源
pool.release(resource);
...
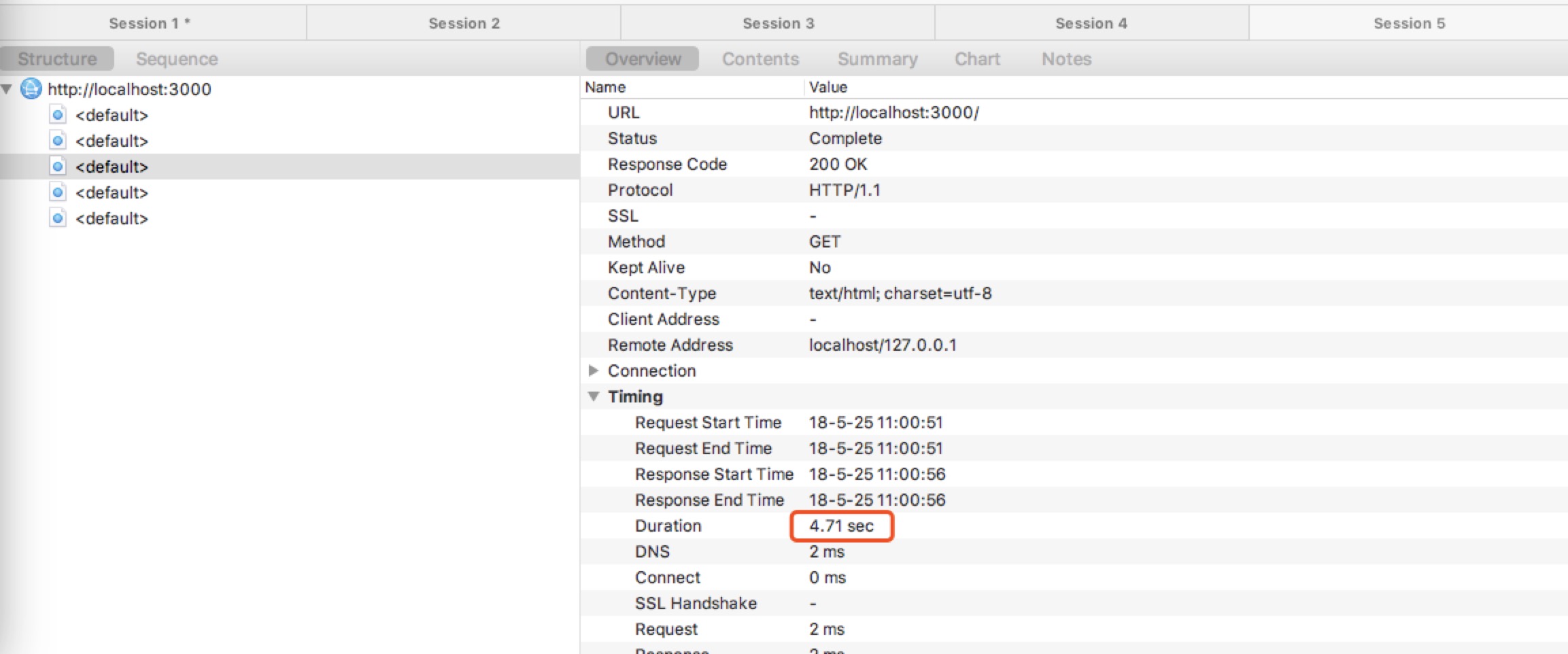
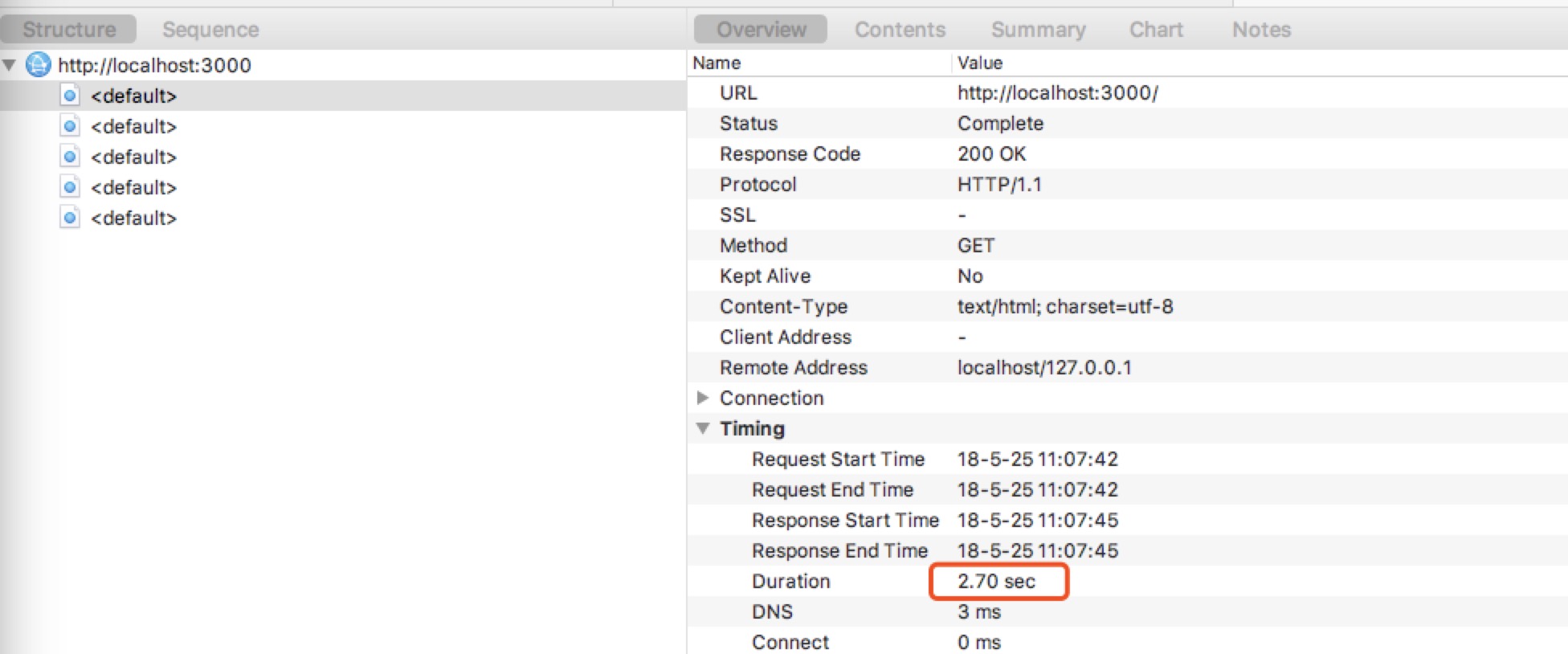
优化结果:
没有使用pool
使用pool
当我们写jsx代码
<div id='oDiv'>123</div>
经过babel转换后可得
import { jsx as _jsx } from 'react/js-runtime'
_jsx('div', {
children: '123',
id: 'oDiv'
})
接下来继续看jsx的实现
export const jsx = (type, config) => {
let key = null
const props = {}
let ref = null
for (const prop in config) {
const val = config[prop]
if (prop === 'key') {
key = '' + val
continue
}
if (prop === 'ref') {
if (val !== undefined) {
ref = val
continue
}
}
if ({}.hasOwnProperty.call(config, prop)) {
props[prop] = val
}
}
return ReactElement(type, key, ref, props)
}
比较简单,就直接上代码吧
const ReactElement = (type, key, ref, props) => {
const element = {
$$typeof: REACT_ELEMENT_TYPE,
type,
key,
ref,
props,
}
retrun element
}
可以看到reactElement返回一个对象,用对象可以很方便的描述一个dom,后续可以用它来创建fiber节点、进行diff比较,以上就是react的runtime。
react的理念是构建快速响应的大型web应用,浏览器每16.6ms刷新一次,期间要执行js、样式布局、样式绘制,如果js执行时间过长,就没有时间进行样式布局和样式绘制了,用户就会直观的感觉到掉帧,卡顿。
为了解决这个问题,react实现了Concurrent Mode,浏览器有一个API叫做requestIdsCallback,它在浏览器闲置的时候执行callback,当然react为了兼容性,自己实现了一个类似的方法,为了方便理解,我们使用这个API做介绍就行。
react的render周期在requestIdsCallback回调中执行,期间如果有优先级更高的操作,比如用户输入,动画等,随时可以把控制权限交还给浏览器,所以render周期是可以被打断的。
为了实现这个能力,react需要构建fiber树,render周期被打断之后,当浏览器闲置下来,还可以继续从被打断的节点继续执行。
class FiberNode {
construtor(tag, props, key) {
// 构成树状结构
this.return = null
this.sibling = null
this.child = null
}
}
灵感来源于downie软件
多个网站执行视频抓取逻辑,而这些逻辑基本相同,首先想到的就是puppeteer,puppeteer默认使用的浏览器是Chromium
Chromium和Chrome有什么区别?
Chrome是基于Chromium的,但谷歌在chrome浏览器中添加了Chromium所缺少的一些专有的、封闭源代码位。具体来说,Google采用了Chromium,然后添加了以下内容
为了保证抓取效果,使用chrome代替Chromium
executablePath: '/usr/bin/google-chrome'
在服务器上下载chrome比较麻烦,因为国内的服务器无法访问境外的下载资源,由于我们还需要抓取youtobe的视频,所以搞了一台香港的云主机
puppeteer抓取信息的方式:
await page.evaluate(() => {
return {
document.getElementsByTagName('video')[0].currentSrc
}
})
fs.createWriteStream(path, name)
遇到blob格式的视频,现在主流的视频网站基本都是这种格式,比如youtobe,b栈等
blob:https://www.youtube.com/d2708fb5-065a-4429-af77-9d67c96fa9c5
它特点是每隔一段时间去拉资源,根据用户的网络情况自动切换清晰度,但是对于我们来说抓取这种链接其实没有作用,因为无法将它转成视频,由于我了解到这种格式的视频对性能有要求,只在pc端支持,所以我想了一个*操作使用手机模式打开,这样就可以获取一个mp4格式的资源了。
await page.emulate(iPhone)
一些网站也对视频抓取做了限制,比如快手做了个滑动验证
种cookie绕开快手网站的滑动验证
await page.setCookie(...)
puppeteer的优缺点
优点:
缺点:
举个抖音列表页的例子
分析返回值,找到里面视频的信息,找到分页的字段返回值有has_more证明有分页,然后看参数,怎么拼接链接,参数里面的max_cursor是上一页最后一个视频的id。
注意_signature的生成
先用puppeteer打开列表页,把请求的参数通过正则匹配都找出来,关闭浏览器
page.on('request', request => {
if (request.resourceType() === 'xhr' && request.url().indexOf('/web/api/v2/aweme/post') > -1) {
....
}
})
在代码中使用递归,发送请求,把每个视频的地址都找出来,抓取出来的网址需要经过一个302跳转,才能得到真正的视频资源地址
const urllib = require('urllib')
在python中urllib是一个自带的url请求库,node也有一个,底层是用node的http或https模块发起请求,封装了一些proxy等功能
抖音做了限制,请求头必须要有ua,才能正常返回,如果条件满足,会返回一个a标签,通过正则选取href属性的内容即为视频资源地址
分析接口的优点是速度快,缺点容易被封
一些防止被封的方式
每隔一段时间从数组中取出一组数据进行抓取,直到数组为空,时间间隔尽量随机,频率固定很容易就能判断是爬虫
const proxies = [
'http://10.122.133.44:3128',
'http://10.172.113.149:3128',
'http://10.172.113.148:3128',
]
把他们放到数组里面,请求接口的时候随机从数组里面取出,这样每次请求接口的时候,ip地址可能都不一样
量级比较大的数据并发抓取
比如这种场景:要下载某个网站下的几万张图片。一个一个下载显然是不合适的,可以考虑并发抓取
const async = require('async')
async.mapLimit(urls, 5, async function(url) {
const response = await fetch(url)
return response.body
}, (err, results) => {
if (err) throw err
// results is now an array of the response bodies
console.log(results)
})
每秒发起5个请求,等待所有请求完成之后继续,容易被封ip,请谨慎使用
有些网站的接口返回值做了加密处理,对于这种接口我们就无法抓取了
举一个豆瓣的例子
const cheerio = require('cheerio')
抓取的信息可能需要写入到csv文件中
const Json2csvParser = require('json2csv').Parser
const iconv = require('iconv-lite')
const encode = iconv.encode(csv, 'utf-8')
fs.writeFile(name, encode)
增量式爬虫
每天开启一个定时器,观察某个分类的标签是否有更新,如果有,则进行抓取,抓取时与数据库的数据进行比对,只抓取新的并且存储
能否结合1和3制作一个通用爬虫
const archiver = require('archiver')
压缩成zip文件,mac和windows都能使用
防止重复打包的md5算法,应用范围比较广,截图工具也有使用
const crypto = require('crypto')
const md5 = crypto.createHash('md5')
let hash = md5.update(Buffer.from(videos)).digest('hex')
服务器上的linux系统没有ui,登录方式无法做得更通用
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.






























{kind=link}
{kind=link}
{kind=link}