olifer655 / react Goto Github PK
View Code? Open in Web Editor NEWreact 学习
react 学习













在我们的项目中,我们用下面的方式去引入React:
import * as React from 'react';
export default class App extends React.Component<Props, State> {
render() {
return <h1>Hello {this.props.name}</h1>;
}
}因为我在查阅资料的时候发现很多地方也有下面的方式:
import React from 'react';在我们的项目中,当我直接import React from 'react'这样写的时候,vs code 会报出下面的错误:
Module '"react"' has no default export.
import * as React from 'react' 代替 import React from 'react'?因为React 使用CommonJS 语法(module.exports = ...)而不是 ES Module 语法来导入。
如果你非常想使用import React from 'react',你可以在tsconfig.json 文件中 将allowSyntheticDefaultImports 这是为true, 然后你就可以正常的使用了。
{
"compilerOptions": {
"allowSyntheticDefaultImports": true,
}
}引用:
//foo.js
exports.foo="foo"
//等同于
module.exports.foo="foo"
//bar.js
const { foo } = require('./foo.js')
console.log(foo);//'foo'exports={
foo: 'foo'
}
//bar.js
const { foo } = require('./foo.js')
//若对 exports 重新赋值,则断开了 exports 对 module.exports 的指向,
// reuqire 返回的是 module.exports 对象, 默认为 {}
console.log(foo);//undefined先来看一下,下面这个例子有什么问题?
class App extends React.Component {
state = { search: '' }
handleChange = event => {
/**
* 这是“防抖”函数的简单实现,它会以队列的方式在 250 ms 内调用
* 表达式并取消所有挂起的队列表达式。以这种方式我们可以在用户停止输
* 入时延迟 250 ms 来调用表达式。
*/
clearTimeout(this.timeout);
this.timeout = setTimeout(() => {
this.setState({
search: event.target.value
})
}, 250);
}
render() {
return (
<div>
<input type="text" onChange={this.handleChange} />
{this.state.search ? <p>Search for: {this.state.search}</p> : null}
</div>
)
}
}好,这道题就需要一些解释了。在防抖函数中并没有错误。那么应用会按期望方式运行吗?它会在用户停止输入的 250 ms 之后更新并且渲染字符串“Search for: …”吗?
这里的问题是在 React 中 event 是一个 SyntheticEvent,如果和它的交互被延迟了(例如:通过 setTimeout),事件会被清除并且 .target.value 引用不会再有效。
注意:
如果要以异步方式访问事件属性,应该对事件调用 event.persist() ,这将从池中删除合成事件,并允许> 用户代码保留对事件的引用。
class App extends React.Component {
....
handleChange = event => {
event.persist();
clearTimeout(this.timeout);
this.timeout = setTimeout(() => {
console.log(event.target.value) // 正常了!
this.setState({
search: event.target.value
})
}, 250);
}
render() {
...
}
}listView = list.map((item,index) => {
return (
<p onClick={this.handleClick.bind(this, item.id)} key={item.id}>{item.text}</p>
);
})顺着上面的这个我们再熟悉不过的例子,想一下,假如:list 有 10000 项会怎么样呢?
所以如果DOM上绑定了过多的事件处理函数,整个页面响应以及内存占用可能都会受到影响。React为了避免这类DOM事件滥用,同时屏蔽底层不同浏览器之间的事件系统差异,实现了一个中间层——SyntheticEvent。
React中,如果需要绑定事件,我们常常在jsx中这么写:
<div onClick={this.onClick}>
react事件
</div>原理大致如下:
React并不是将click事件绑在该div的真实DOM上,而是在document处监听所有支持的事件,当事件发生并冒泡至document处时,React将事件内容封装并交由真正的处理函数运行。
以上面的代码为例,整个事件生命周期示意如下:
其中,由于event对象是复用的,事件处理函数执行完后,属性会被清空,所以event的属性无法被异步访问.
SyntheticEvent 对象都具有以下属性:
boolean bubbles // 检测事件是否是冒泡事件
boolean cancelable // 指示事件是否可拥可取消的默认动作
DOMEventTarget currentTarget
boolean defaultPrevented
number eventPhase //返回事件传播的当前阶段
boolean isTrusted
DOMEvent nativeEvent // 原生事件的方法
void preventDefault()
boolean isDefaultPrevented()
void stopPropagation()
boolean isPropagationStopped()
DOMEventTarget target
number timeStamp
string type即使state是同步更新,props也不是。(你只有在父组件重新渲染时才能知道props)
将state的更新延缓到最后批量合并再去渲染对于应用的性能优化是有极大好处的,如果每次的状态改变都去重新渲染真实dom,那么它将带来巨大的性能消耗。
面试官:“react中setState是同步的还是异步?”
我:“异步的,setState不能立马拿到结果。”
面试官:“那什么场景下是异步的,可不可能是同步,什么场景下又是同步的?”
我:“......”
setState并不是真正意义上的异步操作,它只是模拟了异步的行为
为什么这么说。可以通过下面的例子
不是真正意义上的异步操作
class App extends Component {
state = {
count: 0
};
componentDidMount() {
// 生命周期中调用
this.setState({ count: this.state.count + 1 });
console.log("lifecycle: " + this.state.count);
setTimeout(() => {
// setTimeout中调用
this.setState({ count: this.state.count + 1 });
console.log("setTimeout: " + this.state.count);
}, 0);
document.getElementById("div2").addEventListener("click", this.increment2);
}
increment = () => {
// 合成事件中调用
this.setState({ count: this.state.count + 1 });
console.log("react event: " + this.state.count);
};
increment2 = () => {
// 原生事件中调用
this.setState({ count: this.state.count + 1 });
console.log("dom event: " + this.state.count);
};
render() {
return (
<div className="App">
<h2>couont: {this.state.count}</h2>
<div id="div1" onClick={this.increment}>
click me and count+1
</div>
<div id="div2">click me and count+1</div>
</div>
);
}
}探讨前,我们先简单了解下react的事件机制:react为了解决跨平台,兼容性问题,自己封装了一套事件机制,代理了原生的事件,像在jsx中常见的onClick、onChange这些都是合成事件。
那么以上4种方式调用setState(),后面紧接着去取最新的state,按之前讲的异步原理,应该是取不到的。然而,setTimeout中调用以及原生事件中调用的话,是可以立马获取到最新的state的。根本原因在于,setState并不是真正意义上的异步操作,它只是模拟了异步的行为。React中会去维护一个标识(isBatchingUpdates),判断是直接更新还是先暂存state进队列。setTimeout以及原生事件都会直接去更新state,因此可以立即得到最新state。而合成事件和React生命周期函数中,是受React控制的,其会将isBatchingUpdates设置为 true,从而走的是类似异步的那一套。
在 setTimeout 中去 setState 并不算是一个单独的场景,它是随着你外层去决定的,因为你可以在合成事件中 setTimeout ,可以在钩子函数中 setTimeout ,也可以在原生事件setTimeout,但是不管是哪个场景下,基于event loop的模型下, setTimeout 中里去 setState 总能拿到最新的state值。
setState 只在合成事件和钩子函数中是“异步”的,在原生事件和 setTimeout 中都是同步的。setState的“异步”并不是说内部由异步代码实现,其实本身执行的过程和代码都是同步的,只是合成事件和钩子函数的调用顺序在更新之前,导致在合成事件和钩子函数中没法立马拿到更新后的值,形式了所谓的“异步”,当然可以通过第二个参数 setState(partialState, callback) 中的callback拿到更新后的结果。批量更新优化也是建立在“异步”(合成事件、钩子函数)之上的,在原生事件和setTimeout 中不会批量更新,在“异步”中如果对同一个值进行多次 setState , setState 的批量更新策略会对其进行覆盖,取最后一次的执行,如果是同时 setState 多个不同的值,在更新时会对其进行合并批量更新。对于3 可以结合下面的例子:
class App extends React.Component {
state = { val: 0 }
componentDidMount() {
this.setState({ val: this.state.val + 1 })
console.log(this.state.val)
this.setState({ val: this.state.val + 1 })
console.log(this.state.val)
setTimeout(_ => {
this.setState({ val: this.state.val + 1 })
console.log(this.state.val);
this.setState({ val: this.state.val + 1 })
console.log(this.state.val)
}, 0)
}
render() {
return <div>{this.state.val}</div>
}
}结合上面分析的,钩子函数中的 setState 无法立马拿到更新后的值,所以前两次都是输出0,当执行到 setTimeout 里的时候,前面两个state的值已经被更新,由于 setState 批量更新的策略, this.state.val 只对最后一次的生效,为1,而在 setTimmout 中 setState 是可以同步拿到更新结果,所以 setTimeout 中的两次输出2,3,最终结果就为 0, 0, 2, 3 。
想一下,如何将上面的代码中前两次连续 + 1 都执行呢?
class App extends React.Component {
state = { val: 0 }
componentDidMount() {
this.setState((preState) => {
console.log(preState.val) // 0
return { val: preState + 1 }
})
this.setState((preState) => {
console.log(preState.val) // 1
return { val: preState.val + 1 }
})
setTimeout(_ => {
this.setState({ val: this.state.val + 1 })
console.log(this.state.val); // 3
this.setState({ val: this.state.val + 1 })
console.log(this.state.val) // 4
}, 0)
}
render() {
return <div>{this.state.val}</div>
}
}无状态函数式组件形式上表现为一个只带有一个render方法的组件类,并且该组件是无state状态的。具体的创建形式如下:
function HelloComponent(props, /* context */) {
return <div>Hello {props.name}</div>
}
ReactDOM.render(<HelloComponent name="Sebastian" />, mountNode)无状态组件的创建形式使代码的可读性更好,并且减少了大量冗余的代码,精简至只有一个render方法,大大的增强了编写一个组件的便利,除此之外无状态组件还有以下几个显著的特点:
因为组件被精简成一个render方法的函数来实现的,由于是无状态组件,所以无状态组件就不会在有组件实例化的过程,无实例化过程也就不需要分配多余的内存,从而性能得到一定的提升。
无状态组件由于没有实例化过程,所以无法访问组件this中的对象,例如:this.ref、this.state等均不能访问。若想访问就不能使用这种形式来创建组件
因为无状态组件是不需要组件生命周期管理和状态管理,所以底层实现这种形式的组件时是不会实现组件的生命周期方法。所以无状态组件是不能参与组件的各个生命周期管理的。
与无状态组件相比,React.Component是创建有状态的组件,这些组件是要被实例化的,并且可以访问组件的生命周期方法。
react 生命周期
上面这些方法的调用是有次序的,由上而下,也就是说如果你要获取外部数据并加载到组件上,只能在组件"已经"挂载到真实的网页上才能作这事情,其它情况你是加载不到组件的。
由于 React Fiber 在第一阶段是可以被打断重来的,只有第二阶段是不被打断的,防止发生重复请求问题。
context API
如果你仅仅认为是在react 中丢失了执行上下文,就太冤枉react了,其实这是js 本身的问题。函数内部的 this 的值取决于该函数如何被调用
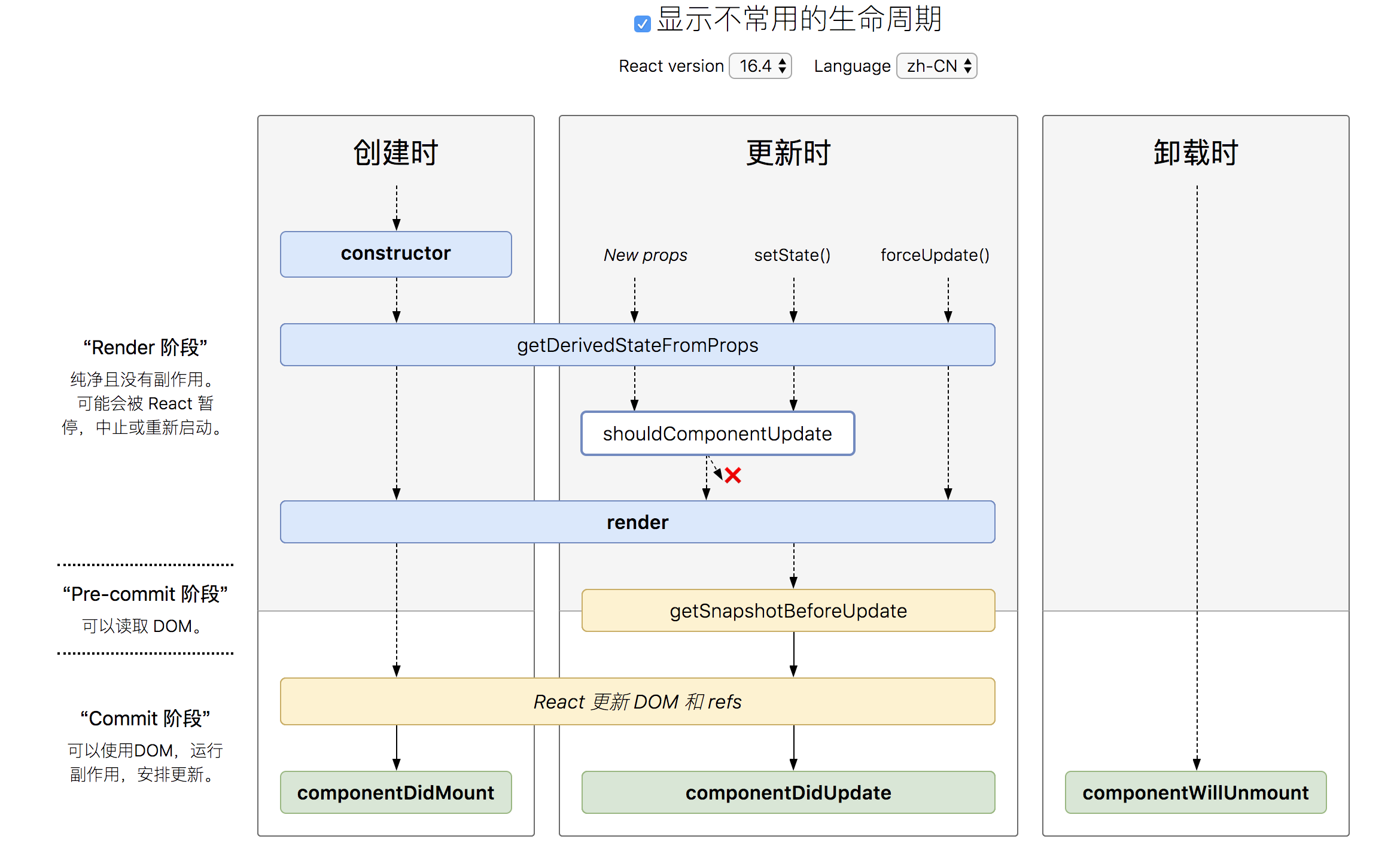
react 16 之前的生命周期图
react 16.4 之后版本的生命周期
为什么我们这里直接跳过 16.0 ~ 16.3 版本,直接说16.4呢?原因是据官方的说法,在新的生命周期
getDerivedStateFromPropsreact 自身考虑失误,在16.4 纠正了这个错误,所以我们直接来谈 16.4, 下文中的16 之后的版本,也指的是 16.4 之后的版本。
通过两张图的对比我们可以看到,react 16 前后版本的差别:
componentWillMount
componentWillReceiveProps ——> getDerivedStateFromProps(nextProps, prevState)
componentWillUpdate
getDerivedStateFromProps是一个静态方法,所以不能在这个函数里面使用this,这个函数有两个参数props和state,分别指接收到的新参数和当前的state对象,这个函数会返回一个对象用来更新当前的state对象,如果不需要更新可以返回null。
react 16 + 生命周期的变化
新增了getDerivedStateFromProps 、getSnapshotBeforeUpdate 、componentDidCatch(捕获报错用的,Suspense的实现原理) 三个生命周期,删除了componentWillMount、componentWillReceiveProps、componentWillUpdate三个生命周期。
在 react 16 中 react 公布了新的API -- Time Slice 和 Suspense.
React 在16版本之前 DOM 更新的做法是 边 比较DOM结构 边 更新的,如果发现有变化, 则立即做出响应。
下面让我们可以想象这样的例子,

A 节点下面有无数的儿子节点在变化, 恰巧此时我们又在 input 输入的时候,这时,就会造成react 卡在这里,不停的算不停的算,从而整个进程被卡住。
但是现在,我们做到了 Slicing(异步渲染机制), 将「比较」和「更新」分开进行。
比较过程中,(在指定时间段内 猜是16毫秒)当比较完当前节点后,它看看是否还有时间比较下一个节点,如果有的话才会继续比较,如果没有的话,把主线程释放出来,给更紧急的任务;如果真的有更紧急的任务,前面的比较内容会被丢弃。然后等待变化全部结束后,一次性的更新所有内容。
总结一下,react16 的渲染更新分为两个阶段。
第一阶段(reconciliation阶段)比较变化: 这一阶段做的是Fiber的update,然后产出的是effect list(可以想象成将老的View更新到新的状态所需要做的DOM操作的列表)。这一个阶段是没有副作用的,因此这个过程可以被打断,然后恢复执行。
第二阶段(commit阶段 ) 更新不变化,不会别打断。Reconciliation产生的effect list只有在commit之后才会生效,也就是真正应用到DOM中。这一阶段往往不会执行太长时间,因此是同步的,这样也避免了组件内视图层结构和DOM不一致。这样就会带来一个问题:在 react16 之前的版本,经常会有人喜欢在 componentWillMount 时调用 ajax 函数来获取数据,这样造成数据别重复获取。

为了解决这个问题, 就出现了上面的生命周期的变化 --- 废弃 componentWillMount、componentWillReceiveProps、componentWillUpdate 以 getDerivedStateFromProps 取而代之。
上面提到了 getDerivedStateFromProps 是一个静态函数, 之所以把它设置成一个 静态函数 的目的是:react 不希望你在 第一阶段做任何无用的操作,只需专心的做好state 计算方面的事情。
以上本文的主要内容就讲完了,但是前文提到了 Dan 老哥在提出 Time Slice 的同时,还提出了Suspense。下面我们简单介绍一下它。
Suspense 的用法与我们之前书写组件的方式有很大的差异,因为我们知道,在react的render()函数中,异步去fetch数据是没用的,因为异步函数会在下一个JS事件循环中才会进行,此时,已经渲染完毕了。所以拿到数据了也没用。
或者也可以简单的总结为下面的过程:
调用render函数->发现有异步请求->悬停,等待异步请求结果->再渲染展示数据
由此可以看到,我们可以用一种同步的方式去书写代码,就像我们写async/await一样!
看一个Suspense 的例子:
const OtherComponent = React.lazy(() => import('./OtherComponent'));
function MyComponent() {
return (
<div>
<Suspense fallback={<div>Loading...</div>}>
<OtherComponent />
</Suspense>
</div>
);
}在我们的业务场景中,OtherComponent可以代表多个条件渲染组件,我们全部加载完成才取消loding。
只要promise没执行到resolve,suspense都会返回fallback中的loading。
代码简洁,loading可提升至祖先组件,易聚合。相当优雅的解决了条件渲染。
听过这样一个小玩笑,「我这辈子写过的 super(props) 比我想象的要多得多」。不过这也证明了,super的重要性。
class myComponent extends React.Component {
constructor(props) {
super(props);
this.state = { isOn: true };
}
// ...
}当然,class fields proposal 允许我们跳过这个仪式。
class Checkbox extends React.Component {
state = { isOn: true };
// ...
}我们为什么要调用super?能不能不调用它?如果非要调用,如果不传 props 会怎样?还有其它参数吗?让我们来看一下。
在 JavaScript 中,super 指代父类的构造函数。(在我们的案例中,它指向 React.Component 这个实现)
重点在于,在你调用父类构造函数之前,你无法在构造函数中使用 this。JavaScript 不会允许你这么做。
class Checkbox extends React.Component {
constructor(props) {
// 🔴 这时候还不能使用 `this`
super(props);
// ✅ 现在开始可以了
this.state = { isOn: true };
}
// ...
}JavaScript 强制你在使用 this 前运行父类构造函数有一个很好的理由。考虑这样一个类结构:
class Person {
constructor(name) {
this.name = name;
}
}
class PolitePerson extends Person {
constructor(name) {
this.greetColleagues(); // 🔴 这是不允许的,下面会解释原因
super(name);
}
greetColleagues() {
alert('Good morning folks!');
}
}想象一下如果在调用 super 前使用 this 是被允许的。一个月之后。我们或许会改变 greetColleagues 把 person 的 name 加到消息中。
greetColleagues() {
alert('Good morning folks!');
alert('My name is ' + this.name + ', nice to meet you!');
}但我们忘了 �this.greetColleagues() 是在 super() 有机会设置 this.name 之前被调用的。this.name 甚至还没被定义!如你所见,像这样的代码理解起来会很困难。
为了避免这样的陷阱,JavaScript 强制规定,如果你想在构造函数中只用this,就必须先调用 super。让父类做它该做的事!这一限制也适用于定义成类的 React 组件。
constructor(props) {
super(props);
// ✅ 现在可以使用 `this` 了
this.state = { isOn: true };
}这给我们留下了另一个问题:为什么要传 props?
你或许觉得把 props 传进 super 是必要的,这使得基类 React.Component 可以初始化 this.props:
// React 内部
class Component {
constructor(props) {
this.props = props;
// ...
}
}很接近了——事实上,它就是这么做的。
然而,即便在调用 super() 时没有传入 props 参数,你依然能够在 render 和其它方法中访问 this.props。(你要是不相信我,可以自己试一试)这是什么原理?其实 React 在调用你的构造函数之后,马上又给实例设置了一遍 props:
// React 内部
const instance = new YourComponent(props);
instance.props = props;因此,即便你忘了把 props 传入 super(),React 依然会在事后设置它们。这是有理由的。
当 React 添加对 Class 的支持时,它并不是只添加了对 ES6 的支持,而是希望能够支持尽可能广泛的 class 抽象。由于不是很确定 ClojureScript、CoffeeScript、ES6、Fable、Scala.js、TypeScript 或其他解决方案谁更适合用来定义组件,React 对于是否有必要调用 super() 刻意不表态。
那么这是否意味着你可以只写 super() 而不用 super(props)?
或许并非如此,因为这依然让人困扰。诚然,React 会在你的构造函数运行之后设置 this.props。但在 super 调用一直到构造函数结束之前,this.props 依然是未定义的。
// React 内部
class Component {
constructor(props) {
this.props = props;
// ...
}
}
// 你的代码
class Button extends React.Component {
constructor(props) {
super(); // 😬 我们忘了传入 props
console.log(props); // ✅ {}
console.log(this.props); // 😬 undefined
}
// ...
}如果这发生在某些从构造函数中调用的函数,调试起来会更加麻烦。这也是为什么我推荐总是使用 super(props) 的写法,即便这是非必要的:
class Button extends React.Component {
constructor(props) {
super(props); // ✅ 我们传了 props
console.log(props); // ✅ {}
console.log(this.props); // ✅ {}
}
// ...
}这样的写法确保了 this.props即便在构造函数返回之前就被设置好了。
换句话说,如果给足够的时间等待返回,也是可以得到的预期的效果的。如下:
constructor(props){
super(props);
setTimeout(() => {
console.log(this.props)
}, 5000) ;
}最后还有一点是 React 的长期用户或许会好奇的。
你或许已经注意到,当你在 Class 中使用 Context API 时(无论是旧版的语法还是 React 16.6 中新增的现代化语法),context 是被作为构造函数的第二个参数传入的。
那么我们为什么不写 super(props, context) 呢?当然我们可以这么做,但 context 的使用频率没那么高,所以这个陷阱影响还没那么大。
伴随着 class fields proposal 的发布,这个问题也就不复存在了。即便不显式调用构造函数,所有参数也会自动传入。这就允许像 state = {} 这样的表达式在必要时可以直接引用 this.props. 或 this.context。
在 Hooks 中,我们甚至都没有 super 或 this。这个话题我们择日再说。
高阶组件是一个函数,能够接受一个简单的组件并返回一个新的组件,高阶组件就是一个没有副作用的纯函数。
高阶组件有以下特点:
const EnhancedComponent = higherOrderComponent(WrappedComponent);组件是将props转化成UI,然而高阶组件将一个组价转化成另外一个组件。
实现高阶组件的方式有以下两种:
TypeScript 是 JS 类型的超集,并支持了泛型、类型、命名空间、枚举等特性,弥补了 JS 在大型应用开发中的不足,那么当 TypeScript 与 React 一起使用会碰撞出怎样的火花呢?接下来让我们一起探索TypeScript 在编写 React 组件中的一些感想。
由于Ryan Dahl 在新项目 Deno 中 使用了TypeScrip,渐渐的TypeScrip也成为了前端的标配之一😢。
笔者所在项目从18.9月开始使用TypeScrip, 到现在也有小半年了,就简单的写一下对 TypeScrip 的看法,有不对的地方欢迎各位指出。
TypeScrip 的编程体验是真的爽啊,当在键盘上敲击.后一系列的提示爽歪歪😊。当然带来爽歪歪的同时也困扰。 首先,强调一些背景,笔者所在的公司不大,很多地方不是很正规,前后端联调时接口文档变化很大,经常出现字段名称约定是a,但实际开发的时候变成了b,类型原本约定的时候string类型,可能一会儿又变成了number类型,增删改字段更是家常便饭,在这样的环境下使用 TypeScrip 无疑给自己找了很大的麻烦,带来的便捷远不及增加的开发量。(针对这点,欢迎大家指出笔者的理解不足)
但是笔者始终认为在相对成熟的团队中使用 TypeScrip 还是很nice的。
下面笔者将在项目中使用 TypeScrip 遇见的问题简单的罗列一下,供大家参考:
一个简单的 TSX 模版如下:
import React from 'react'
import ReactDOM from 'react-dom'
const App = () => {
return (
<div>Hello world</div>
)
}
ReactDOM.render(<App />, document.getElementById('root')上述代码运行时会出现以下错误:
错误原因是由于 React 和 React-dom 并不是使用 TS 进行开发的,所以 TS 不知道 React、 React-dom 的类型,以及该模块导出了什么 。
所以我们需要安装React、 React-dom 类型定义文件。
yarn add @types/react
yarn add @types/react-dom在做异步操作时我们经常使用 async 函数,函数调用时会 return 一个 Promise 对象,可以使用 then 方法添加回调函数。
Promise 是一个泛型类型,T 泛型变量用于确定使用 then 方法时接收的第一个回调函数(onfulfilled)的参数类型。实例:
interface IResponse<T> {
message: string,
result: T,
success: boolean,
}
async function getResponse (): Promise<IResponse<number[]>> {
return {
message: '获取成功',
result: [1, 2, 3],
success: true,
}
}
getResponse()
.then(response => {
console.log(response.result)
})我们首先声明 IResponse 的泛型接口用于定义 response 的类型,通过 T 泛型变量来确定 result 的类型。
然后声明了一个 异步函数getResponse并且将函数返回值的类型定义为 Promise<IResponse<number[]>> 。
最后调用 getResponse 方法会返回一个 promise 类型,通过 then 调用,此时 then 方法接收的第一个回调函数的参数 response 的类型为,{ message: string, result: number[], success: boolean} 。
Promise<T> 实现源码 node_modules/typescript/lib/lib.es5.d.ts。
Event 事件对象类型
常用 Event 事件对象类型:
import { MouseEvent } from 'react'
interface IProps {
onClick (event: MouseEvent<HTMLDivElement>): void,
}imgList: { [key: string]: HTMLImageElement } = {}Context 提供了一个无需为每层组件手动添加 props,就能在组件树间进行数据传递的方法。Context 设计目的是为了共享那些对于一个组件树而言是“全局”的数据,例如当前认证的用户、主题或首选语言。
为当前的 theme 创建一个 context(“light”为默认值)。只有当组件所处的树中没有匹配到 Provider 时,其 defaultValue 参数才会生效。
const ThemeContext = React.createContext('light');<ThemeContext.Provider value={value}>
<div style = {style}>
<Header/>
<Main/>
</div>
</ThemeContext.Provider>class MyClass extends React.Component {
componentDidMount() {
let value = this.context;
/* 在组件挂载完成后,使用 MyContext 组件的值来执行一些有副作用的操作 */
}
componentDidUpdate() {
let value = this.context;
/* ... */
}
componentWillUnmount() {
let value = this.context;
/* ... */
}
render() {
let value = this.context;
/* 基于 MyContext 组件的值进行渲染 */
}
}
MyClass.contextType = ThemeContext;函数组件时, 用Context. ConsumerAPI
function Header() {
return (
<ThemeContext.Consumer>
{
(value) => (
<div
className = "context"
style = {{border: `3px solid ${value.color}`}} >
<p> Header </p>
<Title />
</div>
)
}
</ThemeContext.Consumer>
);
}import React, { useContext } from 'react';
import RouterContext from './RouterContext.js';
export default function Switch(props) {
let routerContext = useContext(RouterContext);
return null;
}import React, { Component } from 'react';
function createContext(initValue) {
let contextValue = initValue;
class Provider extends Component {
constructor(props) {
super(props);
contextValue = props.value;
}
render() {
contextValue = props.value;
return this.props.children;
}
}
class Consumer extends Component {
render() {
return this.props.children(contextValue);
}
}
return { Provider, Consumer };
}
export default createContext;从本质上将,context共享公共变量的过程。
在开发 React 项目中,有一种场景很常见:从服务器中请求了一个数据结构,这个结构非常复杂,甚至还有一些垃圾字段。这个数据结构一般通过 React 组件的 props 传入组件。而我们在render 的时候需要对这个很复杂的数据结构要做处理,比如过滤一些无用的信息,或者重新组合这个数据结构以便更方便的 render。
来看一下这个例子:
class Example extends PureComponent {
// 当前的过滤文本:
state = {
filterText: ""
};
handleChange = event => {
this.setState({ filterText: event.target.value });
};
render() {
// 在 PureComponent 中,render 方发只有在 state.filterText 和 props.list
// 变化的时候才会重新调用
const filteredList = this.props.list.filter(
item => item.text.includes(this.state.filterText)
)
return (
<Fragment>
<input onChange={this.handleChange} value={this.state.filterText} />
<ul>{filteredList.map(item => <li key={item.id}>{item.text}</li>)}</ul>
</Fragment>
);
}
}在上面这个例子中,filter 这一段代码的逻辑其实就是我们所说的,对 从服务器拿来的数据结构 进行处理的过程。每一次调用 render 方法都会调用 filter 这段逻辑。我们在一个组件中更新其实是比较频繁的,而 filter 的逻辑其实也相当占用CPU资源以及时间。如果每次更新调用 render 方法都要走一次这一段filter的逻辑,其实是非常消耗时间的。这对 App 的性能也会造成影响。
而在实际的开发中,数据结构往往更加复杂,有时候甚至会有多次的循环。有时候组件的更新并不是因为从服务器拿来的这一段数据结构发生变化造成的(组件中的其他部分更新造成的),但是这一段很重的逻辑因为是写在 render 中的,所以不可避免的在每次 render 会调用一次。如果这段逻辑在两次调用的时候,输入参数是一样的,那么输出结果必然一样,所以再次计算是一种十分浪费资源的行为。
那么有没有一种方法可以避免这种行为呢?确实是有的,下面我们介绍一种名为 memoization 的技术,中文翻译叫 “记忆化技术”
记忆化技术
记忆化,顾名思义,就是把函数的调用结果记下来,或者缓存下来。如果下次调用这个函数的时候,输入的参数和上一次的完全一致,那么我们就不需要再次进行计算,而是把上一此的结果直接返回。
看一下维基百科对记忆化的定义:
在计算机科学中,记忆化(英語:memoization而非memorization)是一种提高程序运行速度的优化技术。通过储存大计算量函数的返回值,当这个结果再次被需要时将其从缓存提取,而不用再次计算来节省计算时间。
记忆化是一种典型的时间存储平衡方案。
React 中使用 memoize-one根据 "memoize-one" 的名字可以知道,这个库缓存了一个结果 one, 而不是two 或者其他数字。缓存一次而不是多次,可以节约内存。虽然只有一次,但不失为一个很好的折中方案。
在上一节的 React 的场景中,如果把之前计算的结果缓存起来,这样每次 render 的时候,如果从服务器拿到的数据结构和上一次 render 的时候一样,就可以非常快的把结果渲染出来。这样本来需要O(n),O(n2) 甚至更高复杂度的算法,我们瞬间可以以 O(1) 的效率把结果直接从缓存中读取出来。
说了这么多,我们来看一下这个 memoize-one 到底是怎么用的呢?
安装
$ npm install memoize-one
import memoizeOne from 'memoize-one';
const add = (a, b) => a + b;
const memoizedAdd = memoizeOne(add);
memoizedAdd(1, 2); // 3
memoizedAdd(1, 2); // 3
// Add 函数并没有执行: 前一次执行的结果被返回
memoizedAdd(2, 3); // 5
// Add 函数再次被调用以获得新的结果
memoizedAdd(2, 3); // 5
// Add 函数并没有执行: 前一次执行的结果被返回
memoizedAdd(1, 2); // 3
// Add 函数再次被调用以获得新的结果
// 虽然之前调用过
// 但是不是上一次调用的,所以结果丢失了import memoize from "memoize-one";
class Example extends Component {
// 当前的过滤文本:
state = { filterText: "" };
// 只有在 list 和 filterText 改变的时候才会重新执行 filter 函数
filter = memoize(
(list, filterText) => list.filter(item => item.text.includes(filterText))
);
handleChange = event => {
this.setState({ filterText: event.target.value });
};
render() {
// 计算最新的过滤值. 如果参数没有发生改变
// 之前的一次 render 之后, `memoize-one` 会再次利用上一次的返回结果.
const filteredList = this.filter(this.props.list, this.state.filterText);
return (
<Fragment>
<input onChange={this.handleChange} value={this.state.filterText} />
<ul>{filteredList.map(item => <li key={item.id}>{item.text}</li>)}</ul>
</Fragment>
);
}
}这样,我们就在 React 中实现了记忆化,性能也会得到提升。因为这样可以避免 render 的时候,浪费性地调用复杂的数据处理函数。
那么在 JavaScript 中,记忆化函数 memoize-one 是如何实现的呢?
在前面的代码中,我们并没有看到上一次返回的结果被显式的存在一个缓存变量中。那么究竟是如何实现缓存的呢?其实很简单,缓存技术使用了JavaScript 中的闭包。
本文假定你熟悉 JavaScript 中闭包的概念,如果你不熟悉闭包,可以参考你不知道的JavaScript——作用域与闭包
momoize-one 的源码可以在 GitHub 中查看,源码只有三十几行,非常简单,也很好理解。下面我把源码更简化一下,来介绍这个库实现的原理。
export function memoize (resultFn) {
let lastArgs = []; // 用来存放上一次调用的参数
let lastResult; // 用来缓存上一次的结果
let calledOnce: boolean = false; // 是否调用过,刚开始的时候是false
// 判断两次调用的时候的参数是否相等
// 这里的 `isEqual` 是一个抽象函数,用来判断两个值是否相等
const isNewArgEqualToLast = (newArg, index) => isEqual(newArg, lastArgs[index]);
// 如果上一次的参数和这一次一样,直接返回上一次的结果
const result = function (...newArgs) {
if (
calledOnce &&
newArgs.length === lastArgs.length &&
newArgs.every(isNewArgEqualToLast)
) {
// 如果和上次的参数一致, 直接返回缓存的值
return lastResult;
}
// 如果和上一次的参数不一致,我们需要再次调用原来的函数
calledOnce = true; // 标记为调用过
lastArgs = newArgs; // 重新缓存参数
lastResult = resultFn.apply(this, newArgs); //重新缓存返回值
return lastResult;
}
// 返回闭包函数
return result;
}原理非常简单,可以通过我的注释来理解。
注意,我的代码中有一个 isEqual 的抽象函数,用来判断两次的参数是否一致。因为对相等的理解,不同场景不一样,而且参数有时候是复杂的对象,所以我们不能仅仅通过比较操作符 == 或者 === 来判断。memoize-one 允许用户自定义传入判断是否相等的函数,比如我们可以使用 lodash 的 isEqual 来判断两次参数是否相等。
import memoizeOne from 'memoize-one';
import deepEqual from 'lodash.isEqual';
const identity = x => x;
const defaultMemoization = memoizeOne(identity);
const customMemoization = memoizeOne(identity, deepEqual);
const result1 = defaultMemoization({foo: 'bar'});
const result2 = defaultMemoization({foo: 'bar'});
result1 === result2 // false - 索引不同
const result3 = customMemoization({foo: 'bar'});
const result4 = customMemoization({foo: 'bar'});
result3 === result4 // true - 参数通过 lodash 的 isEqual 判断是相等的摘自:
https://zhuanlan.zhihu.com/p/37913276
https://reactjs.org/blog/2018/06/07/you-probably-dont-need-derived-state.html#what-about-memoization
有这样的一个场景如下图所示,有一组动态数量的input,可以增加和删除和重新排序,数组元素生成的组件用index作为key的值,例如下图生成的ui展示:
{this.state.data.map((v,idx)=><Item key={idx} v={v} />)}
//Item组件render方法
render(){
return <li>{this.props.v} <input type="text"/></li>
}
首先说明的是,若页面中数组内容是固定而不是动态的话,上面的代码也不会有什么问题(。•ˇ‸ˇ•。 但是这不是推荐的做法)。
但是,动态数组导致其渲染的组件就会有问题,从上面图中你也能看出问题:数组动态改变后,页面上input的输入内容跟对应的数组元素顺序不对应。
为什么会这样呢?本文后面会有解释。react初学者对这可能更加迷惑,本文就来跟大家探讨一下react的key用法,
react中的key属性,它是一个特殊的属性,它是出现不是给开发者用的(例如你为一个组件设置key之后不能获取组件的这个key props),而是给react自己用的。
简单来说,react利用key来识别组件,它是一种身份标识标识,就像我们的身份证用来辨识一个人一样。每个key对应一个组件,相同的key react认为是同一个组件,这样后续相同的key对应组件都不会被创建。例如下面代码:
//this.state.users内容
this.state = {
users: [{id:1,name: '张三'}, {id:2, name: '李四'}, {id: 2, name: "王五"}],
....//省略
}
render()
return(
<div>
<h3>用户列表</h3>
{this.state.users.map(u => <div key={u.id}>{u.id}:{u.name}</div>)}
</div>
)
);
上面代码在dom渲染挂载后,用户列表只有张三和李四两个用户,王五并没有展示处理,主要是因为react根据key认为李四和王五是同一个组件,导致第一个被渲染,后续的会被丢弃掉。
这样,有了key属性后,就可以与组件建立了一种对应关系,react根据key来决定是销毁重新创建组件还是更新组件。
key不是用来提升react的性能的,不过用好key对性能是有帮组的。
在项目开发中,key属性的使用场景最多的还是由数组动态创建的子组件的情况,需要为每个子组件添加唯一的key属性值。
那么,为何由数组动态创建的组件必须要用到key属性呢?这跟数组元素的动态性有关。
拿上述用户列表的例子来说,看一下babel对上述代码的转换情况:
// 转换前
const element = (
<div>
<h3>用户列表</h3>
{[<div key={1}>1:张三</div>, <div key={2}>2:李四</div>]}
</div>
);
// 转换后
"use strict";
var element = React.createElement(
"div",
null,
React.createElement("h3",null,"用户列表"),
[
React.createElement("div",{ key: 1 },"1:张三"),
React.createElement("div",{ key: 2 },"2:李四")
]
);
有babel转换后React.createElement中的代码可以看出,其它元素之所以不是必须需要key是因为不管组件的state或者props如何变化,这些元素始终占据着React.createElement固定的位置,这个位置就是天然的key。
而由数组创建的组件可能由于动态的操作导致重新渲染时,子组件的位置发生了变化,例如上面用户列表子组件新增一个用户,上面两个用户的位置可能变化为下面这样:
var element = React.createElement(
"div",
null,
React.createElement("h3",null,"用户列表"),
[
React.createElement("div",{ key: 3 },"1:王五"),
React.createElement("div",{ key: 1 },"2:张三"),
React.createElement("div",{ key: 2 },"3:李四")
]
);
可以看出,数组创建子组件的位置并不固定,动态改变的;这样有了key属性后,react就可以根据key值来判断是否为同一组件。
另外,还有一种比较常见的场景:为一个有复杂繁琐逻辑的组件添加key后,后续操作可以改变该组件的key属性值,从而达到先销毁之前的组件,再重新创建该组件。
上面说到了,由数组创建的子组件必须有key属性,否则的话你可能见到下面这样的warning:
Warning: Each child in an array or iterator should have a unique "key" prop. Check the render method of ServiceInfo. See https://fb.me/react-warning-keys for more information.
可能你会发现,这只是warning而不是error,它不是强制性的,为什么react不强制要求用key而报error呢?其实是强制要求的,只不过react为按要求来默认上帮我们做了,它是以数组的index作为key的。
在list数组中,用key来标识数组创建子组件时,若数组的内容只是作为纯展示,而不涉及到数组的动态变更,其实是可以使用index作为key的。
但是,若涉及到数组的动态变更,例如数组新增元素、删除元素或者重新排序等,这时index作为key会导致展示错误的数据。本文开始引入的例子就是最好的证明。
{this.state.data.map((v,idx)=><Item key={idx} v={v} />)}
// 开始时:['a','b','c']=>
<ul>
<li key="0">a <input type="text"/></li>
<li key="1">b <input type="text"/></li>
<li key="2">c <input type="text"/></li>
</ul>
// 数组重排 -> ['c','b','a'] =>
<ul>
<li key="0">c <input type="text"/></li>
<li key="1">b <input type="text"/></li>
<li key="2">a <input type="text"/></li>
</ul>
上面实例中在数组重新排序后,key对应的实例都没有销毁,而是重新更新。具体更新过程我们拿key=0的元素来说明, 数组重新排序后:
因为组件的children中input组件没有变化,其又与父组件传入的任props没有关联,所以input组件不会更新(即其componentWillReceiveProps方法不会被执行),导致用户输入的值不会变化。
这就是index作为key存在的问题,所以不要使用index作为key。
在数组中生成的每项都要有key属性,并且key的值是一个永久且唯一的值,即稳定唯一。
在理想情况下,在循环一个对象数组时,数组的每一项都会有用于区分其他项的一个键值,相当数据库中主键。这样就可以用该属性值作为key值。但是一般情况下可能是没有这个属性值的,这时就需要我们自己保证。
但是,需要指出的一点是,我们在保证数组每项的唯一的标识时,还需要保证其值的稳定性,不能经常改变。例如下面代码:
{
this.state.data.map(el=><MyComponent key={Math.random()}/>)
}
上面代码中中MyComponent的key值是用Math.random随机生成的,虽然能够保持其唯一性,但是它的值是随机而不是稳定的,在数组动态改变时会导致数组元素中的每项都重新销毁然后重新创建,有一定的性能开销;另外可能导致一些意想不到的问题出现。所以:
key的值要保持稳定且唯一,不能使用random来生成key的值。
所以,在不能使用random随机生成key时,我们可以像下面这样用一个全局的localCounter变量来添加稳定唯一的key值。
var localCounter = 1;
this.data.forEach(el=>{
el.id = localCounter++;
});
//向数组中动态添加�元素时,
function createUser(user) {
return {
...user,
id: localCounter++
}
}
当然除了为数据元素生成的组件要添加key,且key要稳定且唯一之外,还需要注意以下几点:
key属性是添加到自定义的子组件上,而不是子组件内部的顶层的组件上。
//MyComponent
...
render() {//error
<div key={{item.key}}>{{item.name}}</div>
}
...
//right
<MyComponent key={{item.key}}/>
key值的唯一是有范围的,即在数组生成的同级同类型的组件上要保持唯一,而不是所有组件的key都要保持唯一
不仅仅在数组生成组件上,其他地方也可以使用key,主要是react利用key来区分组件的,相同的key表示同一个组件,react不会重新销毁创建组件实例,只可能更新;key不同,react会销毁已有的组件实例,重新创建组件新的实例。
{
this.state.type ?
<div><Son_1/><Son_2/></div>
: <div><Son_2/><Son_1/></div>
}
例如上面代码中,this.state.type的值改变时,原Son_1和Son2组件的实例都将会被销毁,并重新创建Son_1和Son_2组件新的实例,不能继承原来的状态,其实他们只是互换了位置。为了避免这种问题,我们可以给组件加上key。
{
this.state.type ?
<div><Son_1 key="1"/><Son_2 key="2"/></div>
: <div><Son_2 key="2" /><Son_1 key="1"/></div>
}
这样,this.state.type的值改变时,Son_1和Son2组件的实例没有重新创建,react只是将他们互换位置。
React渲染页面分为两个阶段:
现有React一个非常大的问题是调度阶段是不可控的,什么意思?
假如我们更新一个 state,有1000个组件需要更新,每个组件更新需要1ms,那么我们就会有将近1s的时间,主线程被React占着用来调度,这段时间内用户的操作不会得到任何的反馈,只有当 React 中需要同步更新的任务完成后,主线程才被释放。对于这1s内 React 的调度,我们是无能为力的。
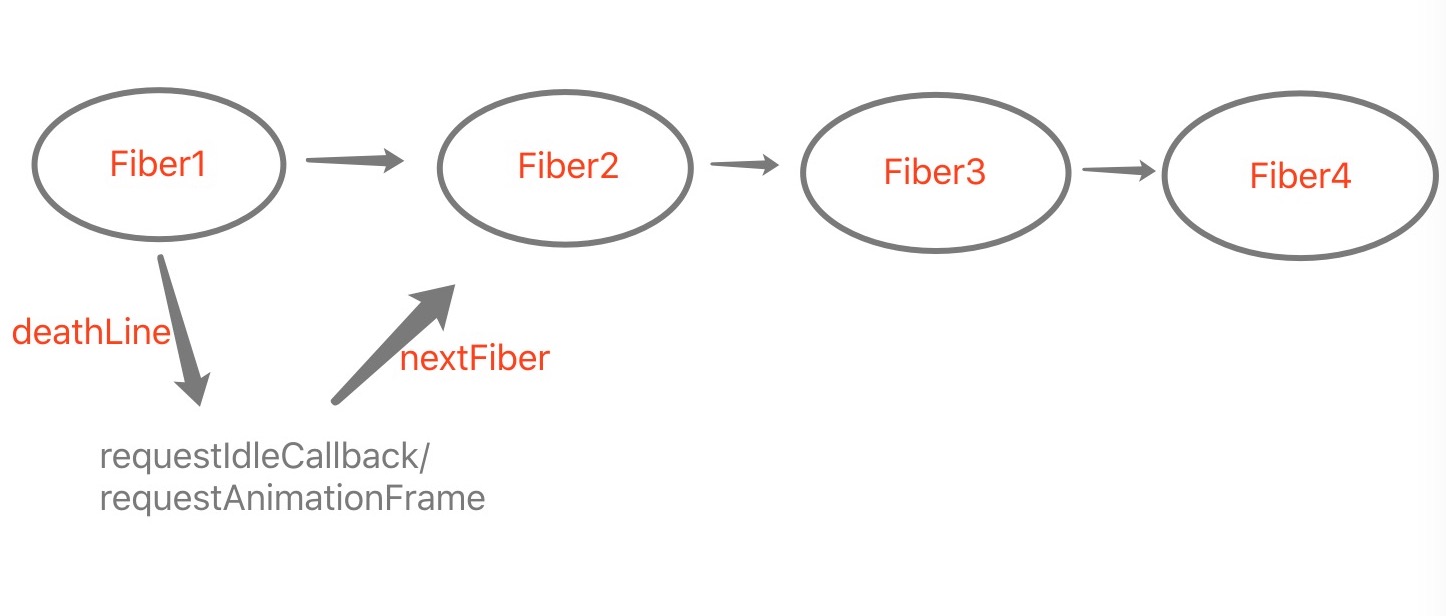
整个调度过程就如下图所示,组件树一旦过大,就会出现浏览器失去响应的情况,用户体验非常差。
Fiber 的中文解释是纤程,是线程的颗粒化的一个概念。也就是说一个线程可以包含多个 Fiber。
Fiber 的出现使大量的同步计算可以被拆解、异步化,使浏览器主线程得以调控。从而使我们得到了以下权限:
把一个耗时长的任务分成很多小片,每一个小片的运行时间很短,虽然总时间依然很长,但是在每个小片执行完之后,都给其他任务一个执行的机会,这样唯一的线程就不会被独占,其他任务依然有运行的机会。
React Fiber 的做法是不使用 Javascript 的栈,而是将需要执行的操作放在自己实现的栈对象上。这样就能在内存中保留栈帧,以便更加灵活的控制调度过程,例如我们可以手动操纵栈帧的调用。这对我们完成调度来说是至关重要。
大致上 Fiber 在调度的时候会执行如下流程:
requestIdleCallback会让一个低优先级的任务在空闲期被调用,而requestAnimationFrame会让一个高优先级的任务在下一个栈帧被调用,从而保证了主线程按照优先级执行Fiber单元。
不同类型的任务会被分配不同的优先级,以下是关于优先级的定义:
module.exports = {
NoWork: 0, // No work is pending.
SynchronousPriority: 1, // For controlled text inputs.
TaskPriority: 2, // Completes at the end of the current tick.
AnimationPriority: 3, // Needs to complete before the next frame.
HighPriority: 4, // Interaction that needs to complete pretty soon to feel responsive.
LowPriority: 5, // Data fetching, or result from updating stores.
OffscreenPriority: 6, // Won't be visible but do the work in case it becomes visible.
};由此我们可以看出Fiber任务的优先级顺序为:
文本框输入 > 本次调度结束需完成的任务 > 动画过渡 > 交互反馈 > 数据更新 > 不会显示但以防将来会显示的任务
支持垂直列表、水平列表、列表之间的移动, 支持鼠标 ,键盘 和触摸 (手机,平板电脑等)
阉割版的react-beautiful-dnd, 如果不需要跨列表,可以使用
使用, 感觉这个人写的很好呢
如下一段最简单的JSX代码:
return (
<div className="parent" onClick="this.isFunction.bind(this)">
<div className="children" > I am children </div>
</div>
)经过babel编译后,变成下面的样子:
return React.createElement('div', {
className: 'parent',
onClick: this.isFunction.bind(this)
}, React.createElement('div', {
className: 'children'
}, " I'm children"))通过观察babel编译后的文件,我们可以发现React 在 当Render函数被调用时 会去调用React.createElement 函数生成 element, createElement一共有三个参数:
type 我们写的标签,比如div、span 等。config 标签中的属性,没有的时候传nullchildren children中可以再次调用React.createElement函数在react 内部,React.createElement() 调用 ReactElement() 去新创建 一个 React element. ReactElement()返回
const element = {
// This tag allows us to uniquely identify this as a React Element
$$typeof: REACT_ELEMENT_TYPE,
// Built-in properties that belong on the element
type: type,
key: key,
ref: ref,
props: props,
// Record the component responsible for creating this element.
_owner: owner, // 当前节点
};Render.createElement 参数中的type直接赋值type,config 中的 key 和 ref 作为重要元素单独拎出来,其余值依次挂在 props 下面。 children 也挂在了 props 下面。
经过 React 内部函数 ReactElement 处理后,我们上面的例子就变成了下面的样子(ReactElement的返回):
{
type: 'div',
props: {
className: 'parent',
onClick: this.isFunction.bind(this),
children: {
type: 'div',
children: 'I am children'
}
}
}值得一提的是,react 内部对 children的处理,有这样一段代码:
// Children can be more than one argument, and those are transferred onto
// the newly allocated props object.
const childrenLength = arguments.length - 2;
if (childrenLength === 1) {
props.children = children;
} else if (childrenLength > 1) {
const childArray = Array(childrenLength);
for (let i = 0; i < childrenLength; i++) {
childArray[i] = arguments[i + 2];
}
props.children = childArray;
}
现在我们有这么一段代码:
<div class="parent">
<Header> I am custom element </Header>
<div>I am dom element</div>
I do not have tags
</div>babel 编译后:
React.createElement(
"div",
{
className: "parent",
},
React.createElement("Header", null, "I am custom element"),
React.createElement("div", null, "I am dom element"),
)根据源码中对children的处理,得到React.createElement的返回如下:
{
type: 'div',
props: {
className: 'parent',
children: [
{
type: function Header,
props: {
children: "I am custom element"
}
},
{
type: 'div',
props: {
children: "I'm dom element"
}
},
I do not have tags
]
}
}通过上面的分析 children 一般分为以下几种类型:
在遇到 react component 时,type 会是一个function 或者 class。react 会先看这个 class 或函数会返回什么样的 Element,并为这个 Element 设置正确的属性。react 会一直不断重复这个过程(有点类似递归),直到没有 “createElement 调用 type 值为 class 或者 function” 的情况。
React 处理这些逻辑的过程就就属于 reconciliation 的一部分,当然完整的 reconciliation 更加复杂,涉及到的层面包括了 diff、render 等。
当我们在使用,ReactDOM.render 或者 setState 的时候,才会被渲染成真实的DOM。

调用setState,组件的state并不会立即改变,setState只是把要修改的状态放入一个队列中,React会优化真正的执行时机,并且React会出于性能原因,可能会将多次setState的状态修改合并成一次状态修改。所以不要依赖当前的State,计算下个State。
// 不建议
this.setState({quantity: this.state.quantity + 1})
// 正确
this.setState((preState, props) => {
counter: preState.quantity + 1;
})// 方法一:将state先赋值给另外的变量,然后使用concat创建新数组
var books = this.state.books;
this.setState({
books: books.concat(['React Guide']);
})
// 方法二:使用preState、concat创建新数组
this.setState(preState => ({
books: preState.books.concat(['React Guide']);
}))
// 方法三:ES6 spread syntax
this.setState(preState => ({
books: [...preState.books, 'React Guide'];
}))// 方法一:将state先赋值给另外的变量,然后使用Object.assign创建新对象
var owner = this.setState.owner;
this.setState({
owner: Object.assign({}, owner, {name: 'Jason'});
})
// 方法二:使用preState、Object.assign创建新对象
this.setState(preState => ({
owner: Object.assign({}, preState.owner, {name: 'Jason'});
}))3.2 使用对象扩展语法
// 方法一:将state先赋值给另外的变量,然后使用对象扩展语法创建新对象
var owner = this.setState.owner;
this.setState({
owner: {...owner, {name: 'Jason'}};
})
// 方法二:使用preState、对象扩展语法创建新对象
this.setState(preState => ({
owner: {...preState.owner, {name: 'Jason'}};
}))总结一下,创建新的状态对象的关键是,避免使用会直接修改原对象的方法,而是使用可以返回一个新对象的方法。
前端文件大类别上分为: html、css、js,那么,为什么我可以在.jsx文件中写html呢?
这个主要功劳归功于babel.
<div class='box' id='content'>
<div class='title'>Hello</div>
<button>Click</button>
</div>由于 JSX 编译后会调用 React.createElement 方法,所以在你的 JSX 代码中必须首先声明 React 变量。
比如,下面两个导入都是必须的,尽管 React 和 CustomButton 都没有在代码中被直接调用。
import React from 'react';
import CustomButton from './CustomButton';
function WarningButton() {
// 返回 React.createElement(CustomButton, {color: 'red'}, null);
return <CustomButton color="red" />;
}每个 DOM 元素的结构都可以用 JavaScript 的对象来表示。你会发现一个 DOM 元素包含的信息其实只有三个:标签名,属性,子元素。
所以其实上面这个 HTML 所有的信息我们都可以用合法的 JavaScript 对象来表示:
{
tag: 'div',
attrs: { className: 'box', id: 'content'},
children: [
{
tag: 'div',
arrts: { className: 'title' },
children: ['Hello']
},
{
tag: 'button',
attrs: null,
children: ['Click']
}
]
}在JSX中,小写标签名称被认为是HTML标签。但是,带小点(属性访问器)的小写标签名不是。
这个方案已经不被 react 官方推荐,而且会在未来的版本中移除。
// 在 render 函数里面
<input type="text" defaultValue="First" ref="first" />;
// 获取 ref
this.refs.first.value;ref 的值是一个函数的时候,那么函数会在虚拟dom转化为真实dom后执行,参数就是此真实dom
// 在 render 函数里面
<input
type="text"
defaultValue="Second"
ref={input => (this.second = input)}
/>;
// 获取 ref
this.second.value;在 react 16.3 中,您将能够使用新的
React.createref()函数使 ref 创建变得更容易。
// 在 class 中声明
third = React.createRef();
// 或者在 constructor 中声明
this.third = React.createRef();
// 在 render 函数中:
<input type="text" defaultValue="Third" ref={this.third} />;
// 获取 ref
this.third.current;
// 获取 input 的 value
this.third.current.value;注意:[email protected] 中使用 this.third.current 取到了值,但是这个 api 目前还不稳定,有的版本是通过 this.third.value 取到 dom 的引用。
import React, { Component } from 'react';
class User extends Component {
constructor(props) {
super(props);
this.userInput = React.createRef();
}
render() {
return <input type="text" defaultValue="user" ref={this.userInput} />;
}
}
class App extends Component {
constructor(props) {
super(props);
this.user = React.createRef();
}
getFocus = (event) => {
this.user.current.userInput.current.focus();
};
render() {
return (
<User ref={this.user} />
<button onClick={this.getFocus}>让User组件获取焦点</button>
)
}
}import React, { Component } from 'react';
function User(props, ref) {
return <input type="text" ref={ref} />;
}
const ForwardedUser = React.forwardRef(User);
export default class Form extends Component {
constructor(props) {
super(props);
this.user = React.createRef();
}
getFocus = (event) => {
this.user.current.focus();
};
render() {
return (
<>
<ForwardedUser ref={this.user} />
<button onClick={this.getFocus}>让User组件获取焦点</button>
</>
);
}
}// 在 class 中声明
hocRef = React.createRef();
// 或者在 constructor 中声明
this.hocRef = React.createRef();
<HOCInstance myRef={el => this.hocRef = el} />2.使用 forwardRef来解决HOC组件传递ref的问题的.
const TargetComponent = React.forwardRef((props, ref) => (
<TargetComponent ref={ref} />
))A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.